







 循环神经网络(RNN)是处理序列数据的关键模型,尤其在自然语言处理(NLP)中表现突出,包括语言模型、文本生成、机器翻译和语音识别等应用。
循环神经网络(RNN)是处理序列数据的关键模型,尤其在自然语言处理(NLP)中表现突出,包括语言模型、文本生成、机器翻译和语音识别等应用。
递归神经网络和循环神经网络
- 循环神经网络(recurrent neural network):时间上的展开,处理的是序列结构的信息,是有环图
- 递归神经网络(recursive neural network):空间上的展开,处理的是树状结构的信息,是无环图
- 二者简称都是 RNN,但是一般提到的RNN指的是循环神经网络(recurrent neural network)。
为什么有bp神经网络、CNN、还需要RNN?
- BP神经网络和CNN的输入输出都是互相独立的;但是实际应用中有些场景输出内容和之前的内 容是有关联的。
- RNN引入“记忆”的概念;递归指其每一个元素都执行相同的任务,但是输出依赖于输入和“记忆”
什么是循环神经网络 RNN
我们已经学习了前馈网络的两种结构——bp神经网络和卷积神经网络。这两种结构有一个特点,就是假设输入是一个独立的没有上下文联系的单位。但是对于一些有明显的上下文特征的序列化输入,比如预测视频中下一帧的播放内容,那么很明显这样的输出必须依赖以前的输入, 也就是说网络必须拥有一定的”记忆能力”。为了赋予网络这样的记忆力,一种特殊结构的神经网络——循环神经网络(Recurrent Neural Network)便应运而生了
循环神经网络RNN的应用场景
自然语言处理(NLP)
RNNs已经被在实践中证明对NLP是非常成功的。如词向量表达、语句合法性检查、词性标注等。在RNNs中,目前使用最广泛最成功的模型便是LSTMs(Long Short-Term Memory,长短时记忆模型)模型,该模型通常比vanilla RNNs能够更好地对长短时依赖进行表达,该模型相对于一般的RNNs,只是在隐藏层做了手脚。对于LSTMs,后面会进行详细地介绍。下面对RNNs在NLP中的应用进行简单的介绍。
自然语言处理(NLP)——语言模型与文本生成
给你一个单词序列,我们需要根据前面的单词预测每一个单词的可能性。语言模型能够一个语句正确的可能性,这是机器翻译的一部分,往往可能性越大,语句越正确。另一种应用便是使用生成模型预测下一个单词的概率,从而生成新的文本根据输出概率的采样。语言模型中,典型的输入是单词序列中每个单词的词向量(如 One-hot vector),输出时预测的单词序列。当在对网络进行训练时,如果,那么第步的输出便是下一步的输入。
下面是RNNs中的语言模型和文本生成研究的三篇文章:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
机器翻译
机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。机器翻译如下图所示:

RNN for Machine Translation. Image Source 。下面是关于RNNs中机器翻译研究的三篇文章:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
语音识别
语音识别是指给一段声波的声音信号,预测该声波对应的某种指定源语言的语句以及该语句的概率值。
RNNs中的语音识别研究论文:
图像描述生成
和卷积神经网络(convolutional Neural Networks, CNNs)一样,RNNs已经在对无标图像描述自动生成中得到应用。将CNNs与RNNs结合进行图像描述自动生成。这是一个非常神奇的研究与应用。该组合模型能够根据图像的特征生成描述。如下图所示:

图像描述生成中的深度视觉语义对比. Image Source
文本相似度计算等 。。。。。
循环神经网络 RNN 结构
循环神经网络是一类用于处理序列数据的神经网络,就像卷积神经网络是专门用于处理网格化数据(如一张图像)的神经网络,循环神经网络时专门用于处理序列 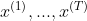 的神经网络。
的神经网络。
同一个神经元在不同时刻的状态构成了RNN神经网络,简化版的RNN结构如下:

循环神经网络的结果相比于卷积神经网络较简单,通常循环神经网络只包含输入层、隐藏层和输出层,加上输入输出层最多也就5层
以样本 ‘我是谁’ 为例,体会一下
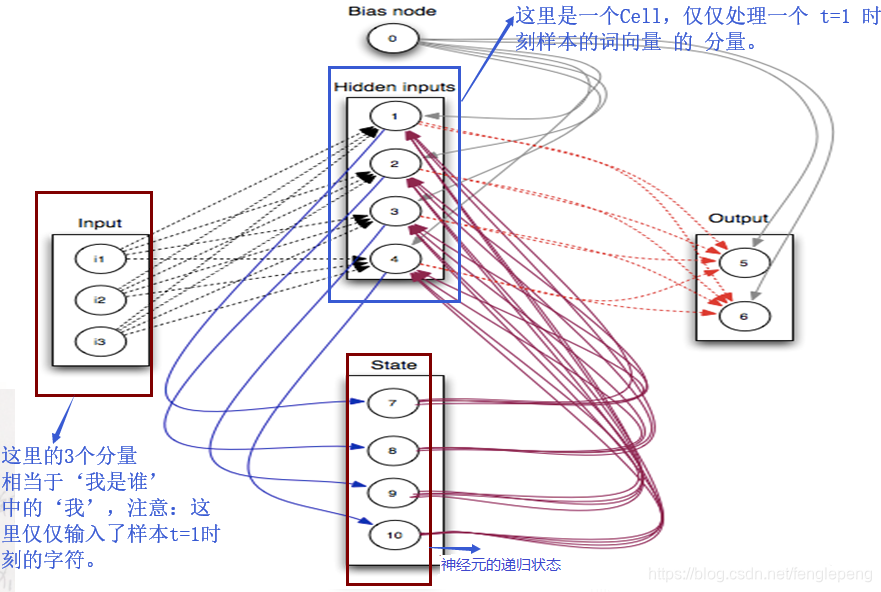
将一个神经元序列按时间展开就可以得到RNN的结构

- 网络某一时刻 t 的输入
 ,和之前介绍的 bp 神经网络的输入一样, 是一个n维向量,不同的是递归网络的输入将是一整个序列,也就是X=[
,和之前介绍的 bp 神经网络的输入一样, 是一个n维向量,不同的是递归网络的输入将是一整个序列,也就是X=[ ,…,
,…, ,,
,, ,…]。对于语言模型,每一个 代表一个词向量,一整个序列就代表一句话
,…]。对于语言模型,每一个 代表一个词向量,一整个序列就代表一句话  代表时刻 t 隐神经元对于线性转换值
代表时刻 t 隐神经元对于线性转换值 是时间 t 处的“记忆”,
是时间 t 处的“记忆”, ,f() 可以是非线性转换函数,比如 tanh 等, 通常我们把 叫做一个细胞,它有两个输出
,f() 可以是非线性转换函数,比如 tanh 等, 通常我们把 叫做一个细胞,它有两个输出 代表时刻t的输出(神经元激活后的输出结果),比如是预测下一个词的话,可能是 sigmoid(softmax) 输出的属于每个候选词的概率,
代表时刻t的输出(神经元激活后的输出结果),比如是预测下一个词的话,可能是 sigmoid(softmax) 输出的属于每个候选词的概率,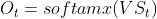
- 输入层到隐藏层直接的权重由U表示,它将我们的原始输入进行抽象作为隐藏层的输入
- 隐藏层到隐藏层的权重W,它是网络的记忆控制者,负责调度记忆。
- 隐藏层到输出层的权重V,从隐藏层学习到的表示将通过它再一次抽象,并作为最终输出
循环神经网络RNN-BPTT
RNN 的训练和 CNN/ANN 训练一样,同样适用 BP算法误差反向传播算法。区别在于:RNN中的参数U\V\W是共享的,并且在随机梯度下降算法中,每一步的输出不仅仅依赖当前步的网络,并且还需要前若干步网络的状态,那么这种BP改版的算法叫做Backpropagation Through Time(BPTT);BPTT算法和BP算法一样,在多层训练过程中(长时依赖<即当前的输出和前面很长的一段序列有关,一般超过10步>),可能产生梯度消失和梯度爆炸的问题。
BPTT和BP算法思路一样,都是求偏导,区别在于需要考虑时间对step的影响。
RNN正向传播阶段
在t=1的时刻,U,V,W都被随机初始化好,h0通常初始化为0,然后进行如下计算:
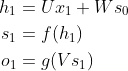
时间就向前推进,此时的状态 h1 作为时刻 t=1 的记忆状态将参与下一次的预测活动,也就是:
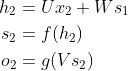
以此类推,可得任意时刻t,神经元的计算过程
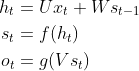
其中 f 可以是 tanh,relu,sigmoid 等激活函数, g 通常是 softmax,也可以是其他。 值得注意的是,我们说循环神经网络拥有记忆能力,而这种能力就是通过 W 将以往的输入状态进行总结,而作为下次输入的辅助,可以这样理解隐藏状态:h=f(现有的输入+过去记忆总结)
RNN反向传播阶段
bp神经网络用到 误差反向传播 方法将输出层的误差总和,对各个权重的梯度 ∇U,∇V,∇W,求偏导数,然后利用梯度下降法更新各个权重。
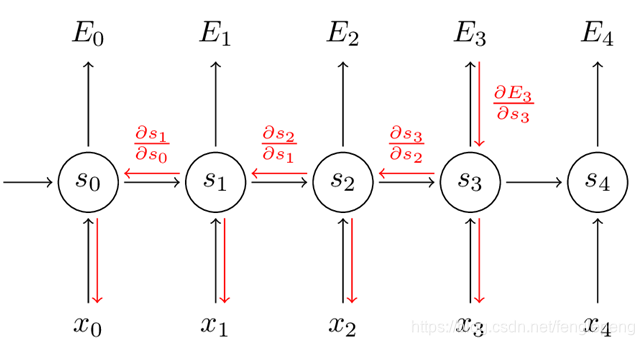
对于每一时刻 t 的 RNN 网络,网络的输出 都会产生一定误差 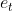 ,误差的损失函数,可以是交叉熵也可以是平方误差等等。那么总的误差为
,误差的损失函数,可以是交叉熵也可以是平方误差等等。那么总的误差为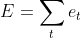 ,我们的目标就是要求取各个权重(U、V、W)对总误差的偏导
,我们的目标就是要求取各个权重(U、V、W)对总误差的偏导
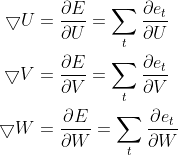
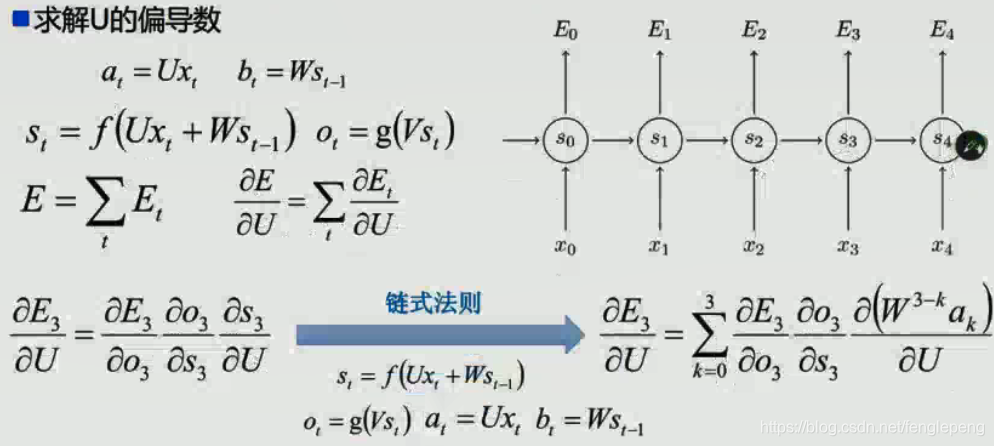
求V的偏导
对于输出  ,任意损失函数,求∇V是非常简单的,我们可以直接求取每个时刻的
,任意损失函数,求∇V是非常简单的,我们可以直接求取每个时刻的 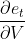 ,由于它不存在和之前的状态依赖,可以直接求导取得,然后简单地求和即可。对于∇W、∇U的计算不能直接求导,需要用链式求导法则。
,由于它不存在和之前的状态依赖,可以直接求导取得,然后简单地求和即可。对于∇W、∇U的计算不能直接求导,需要用链式求导法则。
求w的偏导
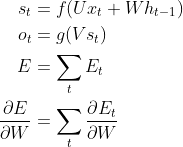

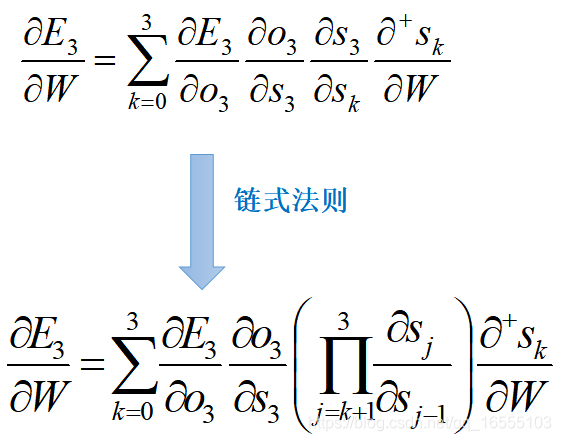
求U的偏导
RNN 缺点
假如 t = 0 时刻的值,到 t = 100 时,由于前面的 W 次数过大,又可能会使其忘记 t = 0 时刻的信息,我们称之为 RNN梯度消失,但是不是真正意思上的消失,因为梯度是累加的过程,不可能为0,只是在某个时刻的梯度太小,忘记了前面时刻的内容
为了克服梯度消失的问题,LSTM和GRU模型便后续被推出了,LSTM和GRU都有特殊的方式存储”记忆”,以前梯度比较大的”记忆”不会像RNN一样马上被抹除,因此可以一定程度上克服梯度消失问题。
另一个简单的技巧 gradient clipping(梯度截取) 可以用来克服梯度爆炸的问题,也就是当你计算的梯度超过阈值c的或者小于阈值−c时候,便把此时的梯度设置成c或−c
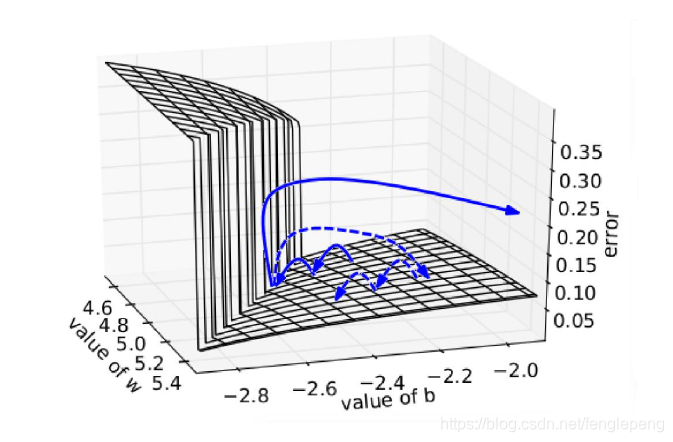
下图所示是RNN的误差平面,可以看到RNN的误差平面要么非常陡峭,要么非常平坦,如果不采取任何措施,当你的参数在某一次更新之后,刚好碰到陡峭的地方,此时梯度变得非常大,那么你的参数更新也会非常大,很容易导致震荡问题。而如果你采取了gradient clipping,那么即使你不幸碰到陡峭的地方,梯度也不会爆炸,因为梯度被限制在某个阈值c
双向RNN Bidirectional RNN
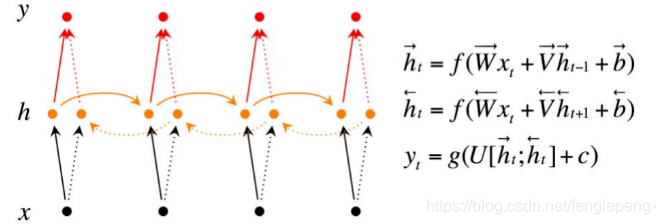
Bidirectional RNN(双向RNN)假设当前t的输出不仅仅和之前的序列有关,并且还与之后的序列有关,例如:预测一个语句中缺失的词语那么需要根据上下文进行预测;Bidirectional RNN是一个相对简单的RNNs,由两个RNNs上下叠加在 一起组成。输出由这两个RNNs的隐藏层的状态决定
或者如下图
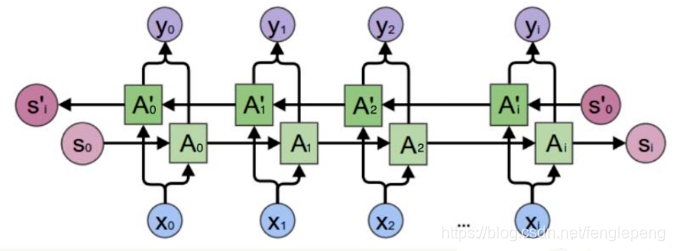
深度双向 RNN
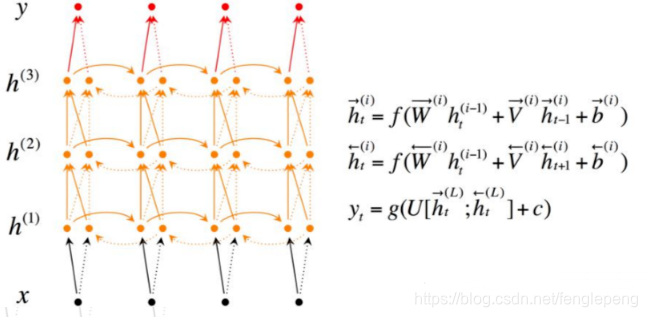
Deep Bidirectional RNN(深度双向RNN)类似Bidirectional RNN,区别在于每个每一步的输入有多层网络,这样的话该网络便具有更加强大的表达能力和学习能力,但是复杂性也提高了,同时需要训练更多的数据。

















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









