









在进行自动抓取某些比较x的网站,例如知乎,微博时,需要登录,才能进行某些操作。
例如在抓取知乎首页,使用requests,肯定是不能获取获取登录后的页面的信息。而使用selenium 中的firefox 进行操作,获取登录后的页面,依旧不能将这个页面上的信息抓取下来。
登录前
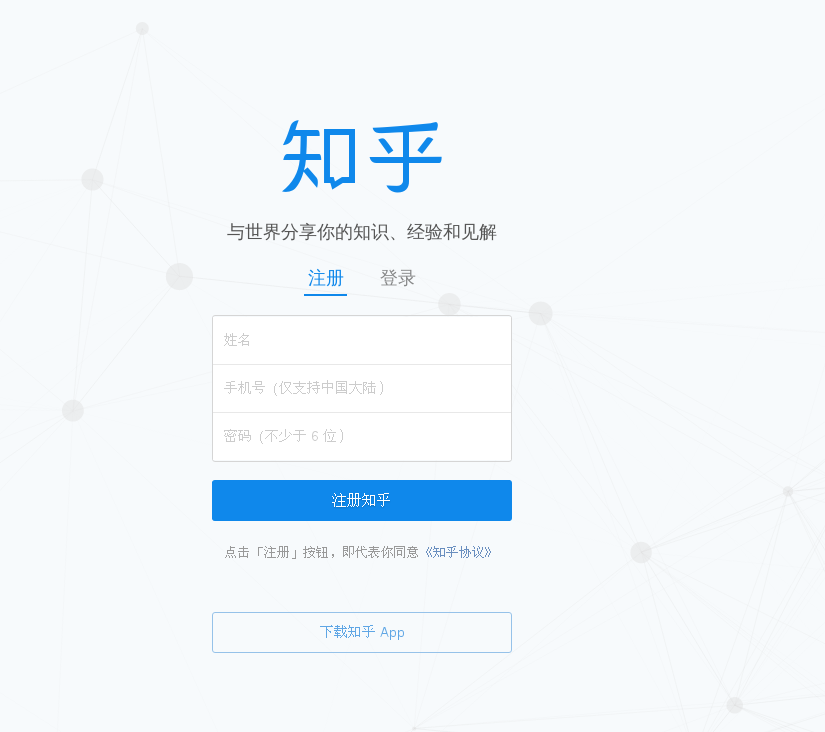
登录后
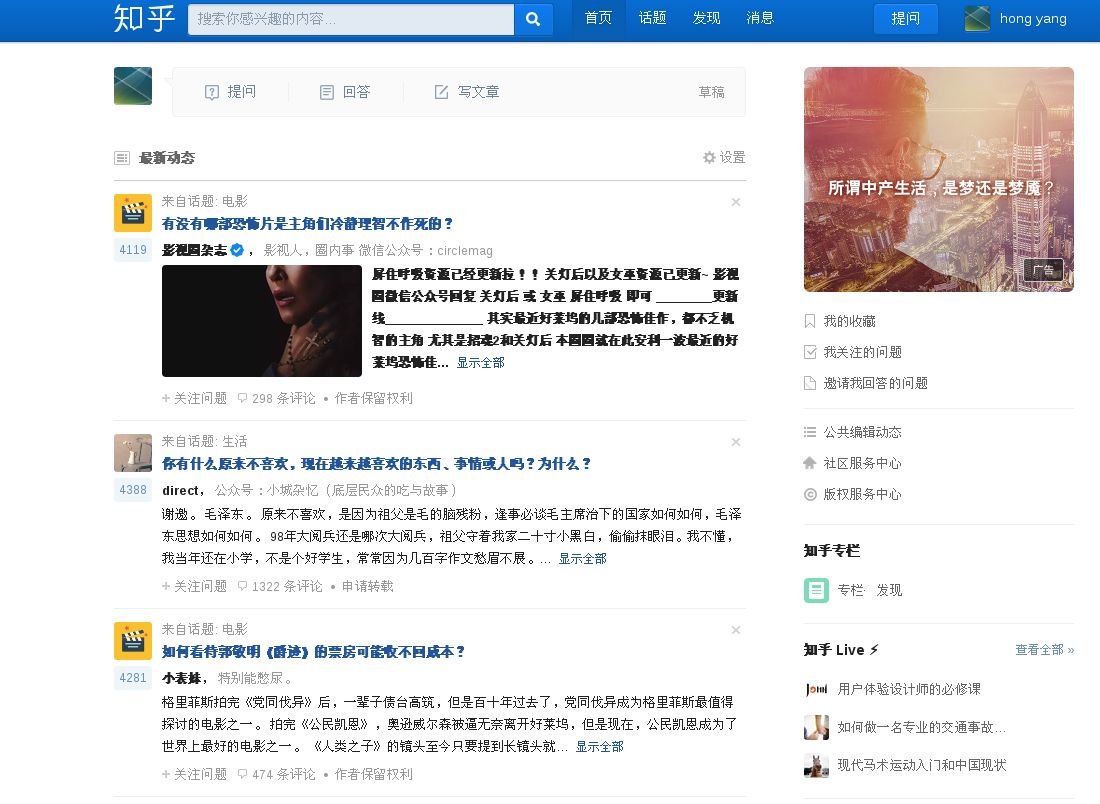
一般有如下方法来解决:
1 抓包获取cookie值
通过在网页浏览器登录网站,然后刷新网页,通过查看源码,查看发送请求的头部信息,查取cookie值,然后在程序中,将cookie赋值给发送请求的cookie参数中。requests中可以实现这一功能。
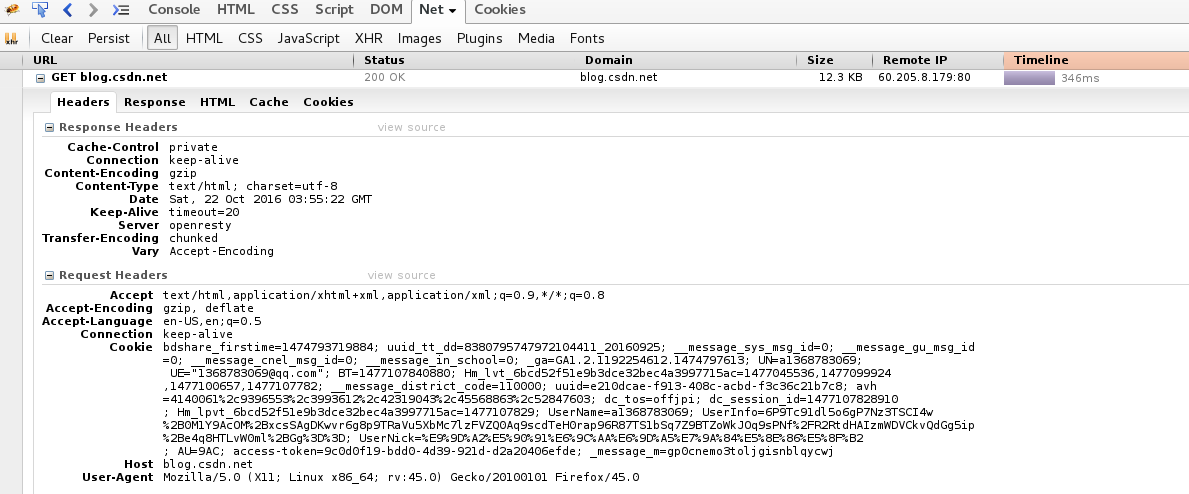
2 模拟登录
利用模拟浏览器的方式登陆,比如ghost.py, selenium等进行操作。程序中,浏览器对象获取用户名框,密码框,输入相应的值,然后点击登录,浏览器对象的一些属性就发生变化,这是可以通过浏览器对象属性返回cookie,返回的cookie可以在后面的请求中使用。
但是,这种模拟登录的方法,在遇到需要验证码登录的时候会很麻烦。
3 手动登录,返回cookie
跟方法 2 类似,同样时基于模拟浏览器的方法。使用 selenium + firefox。
在程序中,调用selenium的firefox对象,使用firefox对象打开网页,程序会调用本地(或者远程,自己定义)的firefox浏览器,并打开登录页面。此时,进行人工在此页面进行登录操作,即输入帐号,密码,验证码,点击登录。完成后,程序中的firefox对象的属性发生变化,此时,返回firefox对象的cookie值,即是我们需要的值。















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









