







目录
(1)随机存储器(Random Access Memory,RAM )
(2)只读存储器(Read - Only Memory,ROM )
(3)顺序存取存储器(Sequential Access Memory,SAM )
(4)直接存取存储器(Direct Access Memory,DAM )
(5)相联存储器(Associative Memory,AM )
2. CF - LRU(Clean - First LRU)算法
第 3 章 存储器层次结构
【考纲内容】
1.存储器的分类
2.层次化存储器的的基本结构
3.半导体随机存取存储器:SRAM 存储器;DRAM 存储器;Flash 存储器
4.主存储器:DRAM 芯片和内存条;多模块存储器;主存和 CPU 之间的连接
5.外部存储器:磁盘存储器;固态硬盘(SSD)
6.高速缓冲存储器(Cache):Cache 的基本原理;Cache 和主存之间的映射方式;Cache 中主存块的替换算法;Cache 写策略
7.虚拟存储器
(1)虚拟存储器的基本概念
(2)页式虚拟存储器:基本原理,页表,地址转换,TLB(快表)
(3)段式虚拟存储器的基本原理
(4)段页式虚拟存储器的基本原理
【考情统计】
年份
题数及分值 考点
单选题
综合题
总分值
2009
2
1
12
Cache 的基本原理,Cache 和主存之间的映射方式,主存和 CPU 之间的连接,页式虚拟存储器
2010
3
1
18
主存和 CPU 之间的连接,Cache 的基本原理,Cache 和主存之间的映射方式,页式虚拟存储器
2011
2
1
16
存储器的分类,主存和 CPU 之间的连接,Cache 的基本原理,Cache 和主存之间的映射方式,页式虚拟存储器
2012
2
1
14
Flash 存储器,Cache 中主存块的替换算法,多模块存储器,Cache 的基本原理
2013
3
1
15
页式虚拟存储器,Cache 的基本原理,多模块存储器,磁盘存储
2014
2
1
15
主存和 CPU 之间的连接,Cache 的基本原理,磁盘存储器,页式虚拟存储器
2015
3
0
6
Cache 的基本原理,Cache 和主存之间的映射方式,Cache 中主存块的替换算法,磁盘存储器
2016
2
1
17
Cache 中主存块的替换算法,主存和 CPU 之间的连接,页式虚拟存储器,Cache 和主存之间的映射方式,Cache 写策略
2017
2
0
4
主存和 CPU 之间的连接,局部性原理
2018
1
1
17
DRAM 芯片与内存条,Cache 的基本原理,Cache 和主存之间的映射方式,页式虚拟存储器
2019
2
1
11
页式虚拟存储器,Cache 的基本原理,Cache 和主存之间的映射方式,磁盘存储器
2020
1
1
12
页式虚拟存储器,Cache 的基本原理,Cache 和主存之间的映射方式,Cache 中主存块的替换算法,Cache 写策略
2021
2
1
12
主存和 CPU 之间的连接,Cache 的基本原理,页式虚拟存储器,Cache 和主存之间的映射方式
2022
3
0
6
Cache 和主存之间的映射方式,页式虚拟存储器,DRAM 存储器
2023
1
2
25
页式虚拟存储器、Cache 和主存之间的映射方式、主存和 CPU 之间的连接
2024
3
0
6
存储器层次结构、虚拟存储器、虚实地址转换
【考点解读】
存储器是计算机组成原理考试中的重点和难点,从考情统计来看,平均每年会考两道左右的选择题,且几乎每年都考大题。选择题主要考查前五节里细碎繁多的知识点,这就要求我们在学习过程中多加记忆和总结。第六节的 Cache 是本章的重中之重,不仅会在选择题中多次考查,还常与第七节的虚拟存储器结合作为一道综合性的大题,因此对于最后两节的内容需要以完全掌握为目标。
【复习建议】
计算机所需的信息都存在存储器中,因此本章是串联各个章节的枢纽。其中 Cache、虚拟存储器常与操作系统的内存管理章节相结合考查,本章的 3.8 与 3.9 节给出了 CPU 的访存流程和实例,跟着流程完整的过一遍可以帮助复习。主存和 CPU 之间的连接与多模块存储器常与总线和 I/O 系统章节结合考查,其中涉及的概念也比较多。如果对于地址等概念不太清楚,第一次学习会很吃力,但若能在学习知识点之后,在做题时经常回顾概念,那么掌握清楚并不困难。本章的题目总体上呈现较强的套路性,所以一定要充分反思总结、对比分析历年真题的考法,这样在遇到新题时就能够快速知道考查的点与做题方法。为了应对综合应用题,我们会在本章末尾进行详尽的实例分析。在本章学习过程中,可以带着如下问题进行探索和总结,我们也会在章末给出解析。
1.编址和寻址的概念和过程是什么,能否用生活中的例子描述出来?
2.如何计算 Cache 的容量?计算方法与 Cache 不同映射下的地址划分又是什么关系呢?
3.Cache 与虚拟存储器的联系与区别是什么?
4.Cache 与 TLB 的联系与区别是什么?
5.本章我们学习的存储器中有很多都可以用来缓存,能否将这些缓存区分开来?
3.1 存储器概述
3.1.1 存储器的分类
存储器负责存储指令和数据,是计算机系统中的记忆设备。根据存储元件的存储介质、存取方式、断电后信息的可保存性和在计算机系统中的作用的不同,存储器有不同的分类方法。
1.按存储介质分类
存储器可按使用的存储介质划分为半导体存储器、磁表面存储器、磁芯存储器和光存储器。半导体存储器分为双极型(TTL 电路或 ECL 电路)半导体存储器和 MOS 半导体存储器两种。磁表面存储器主要包括磁盘和磁带。磁芯存储器由磁芯(一种微小的磁环)构成,但因为体积过大、功耗过大、工艺复杂,现已被半导体存储器取代。光存储器一般指光盘。
2.按存取方式分类
按存取方式的不同,可将存储器分为随机存储器(RAM)、只读存储器(ROM)、顺序存取存储器、直接存取存储器和相联存储器。
(1)随机存储器(Random Access Memory,RAM )
RAM 全称为随机存取存储器。随机存取是指 CPU 可以对 RAM 的任一单元随机地读写,且对任意单元的读出和写入时间相同,读写任一存储单元的时间与物理地址无关,具有灵活读写的优点。一旦断电,RAM 即失去存储信息。根据存储单元的工作原理不同,RAM 可进一步细分为静态 RAM(SRAM,使用双稳态触发器制成)和动态 RAM(DRAM,使用 MOS 管和电容制成 )。SRAM 多用于制造高速缓冲存储器(Cache)和快表(TLB),DRAM 多用于制造主存。
4.关于存储器的分类,以下选项中正确的是( )。
A. 为加快存取速度,Cache 和 TLB 都可以采用相联储存器制成
B. RAM 是破坏性读取,ROM 是非破坏性读取
C. SRAM 常用作 Cache,DRAM 常用作 TLB
D. 计算机的存储总容量 = Cache 容量 + 主存容量 + 辅存容量4.【参考答案】A
【解析】TLB 和全相联映射的 Cache 都采用相联储存器,A 正确;DRAM 是破坏性读取,SRAM 是非破坏性读取,B 错误;SRAM 常用于制作 Cache 和 TLB,C 错误;计算机的存储总容量≤主存容量 + 辅存容量,D 错误。(2)只读存储器(Read - Only Memory,ROM )
ROM 同样具备随机访问的特性。但是 ROM 中的信息一经写入,之后只能读取,不能再次写入,所以里面的内容固定不变。ROM 在断电以后不会丢失存储信息,所以适合存储各种固定程序和数据,多用于系统程序 BIOS、字符发生器和微程序控制器中的控制存储器。
提示:虽然部分 ROM 无法写入,但是 ROM 的读取过程与 RAM 一样,都是先对 CPU 传过来的地址信号进行译码,然后选定特定的存储单元并读出。
经历了几十年的发展,如今部分种类的 ROM 也具有多次写入的功能(即失去了 “只读” 的特性),如闪存和固态硬盘。且这些 ROM 保持了断电后信息依旧保留下来的优点,但是与 RAM 不同的是它们的写入速度比读取速度慢很多。(3)顺序存取存储器(Sequential Access Memory,SAM )
最常见的顺序存取存储器是磁带。顺序存取存储器在访问数据时,必须顺着存储单元的物理地址顺序,顺次进行访问,即串行访问。好比数据结构中的链表,必须逐元素地往后遍历才能找到需要访问的单元,因而顺序存取存储器的存取时间与存取的物理地址相关。
(4)直接存取存储器(Direct Access Memory,DAM )
最常见的直接存取存储器是磁盘。在访问直接存取存储器时先通过随机访问确定一个较小的存储区域,再在这小区域内顺序查找,存取时间同样与存取的物理地址相关。比如对磁盘的访问就要先找到数据所在的磁道,即随机访问,再在这个磁道上顺次扫描直至找到所需的数据,即串行访问。
(5)相联存储器(Associative Memory,AM )
相联存储器也称按内容访问存储器(Content Addressed Memory,CAM),是根据内容特征检索其存储位置的存储器,即按照内容寻址,其效率更高,但造价也更贵。在虚拟存储器中使用的 TLB 就是一种相联存储器。
5.相联存储器是按( )进行寻址的存储器。
A. 地址指定方式
B. 堆栈指定方式
C. 内容指定方式和堆栈存储方式相结合
D. 内容指定方式和地址指定方式相结合5.【参考答案】D
【解析】相联存储器既可以按照地址寻址也可以按照内容寻址,故 D 正确。3.按断电后信息的可保存性分类
按照断电后存储器中的数据能否保留下来,可将存储器划分为易失性存储器和非易失性存储器。易失性存储器在断电后存储信息消失,如 RAM。非易失性存储器在断电后存储信息依旧保留,如 ROM、磁盘、磁带、光盘。
1.下面存储器为永久性(非易失性)存储器的是( )。
A. DRAM 和 Cache
B. SRAM 和硬盘
C. U 盘和 Cache
D. ROM 和外存1.【参考答案】D
【解析】SRAM 与 DRAM 都是易失性存储器,排除 A、B;Cache 由 SRAM 制成,故也有易失性,排除 C;D 中 ROM 与外存均有非易失性,选 D。此外存储器的读出方式可分为破坏性读出和非破坏读出。破坏性读出即所读信息在读出后若不加恢复,则存储器存储的信息会丢失,所以需要读出后恢复存储信息,比如磁芯存储器和 DRAM 的读出方式属于破坏性读出,其中 DRAM 属于此读出方式的原因将在本章第三节讨论。非破坏读出即读出存储器的内容时不会丢失信息,因而就不需恢复数据,比如 SRAM、ROM、磁盘、磁带、光盘。
2.下面有关存储器的说法中,正确的是( )。
A. SRAM 是非易失性存储器,DRAM 是易失性存储器
B. 辅存是按顺序访问的存储器,主存一般是按随机存取方式访问的存储器
C. 辅存是非易失性存储器,主存是易失性存储器
D. RAM 和 ROM 都可用作 Cache2.【参考答案】C
【解析】SRAM 与 DRAM 都是易失性存储器,A 错;辅存与存取关系没有必然的联系,可顺序访问也可随机存取,B 错;主存由 DRAM 制成,故是易失性存储器,C 正确;Cache 由 SRAM 制成,不是 ROM,D 错。4.按存储器在计算机系统中的作用分类
存储器的分类如图 3.1 所示。根据在计算机中的作用的可划分为:高速缓冲存储器、主存储器和辅助存储器。
(1)高速缓冲存储器(Cache )
简称高速缓存,目前多由 SRAM 组成。位于主存和 CPU 之间,具有速度快、价格高、容量小的特点。Cache 的存取速度可与 CPU 相匹配,利用 Cache 临时存放 CPU 正在使用的指令和数据可提高 CPU 的处理速度。现代计算机一般将 Cache 集成在 CPU 中,一些中高档的 CPU 甚至拥有多级缓存。
(2)主存储器
简称主存,又称内存,目前多由 DRAM 组成。具有速度较快、价格较高、容量较小的特点。主存放着计算机运行中实时需要的程序与数据。
3.关于 SRAM 和 DRAM 的特点,以下选项不正确的是( )。
I. SRAM 不需要刷新,而 DRAM 需要刷新,因此 DRAM 的功耗更高
II. DRAM 比 SRAM 集成度更高,因此读写速度也更快
III. SRAM 是易失性存储器,而 DRAM 是非易失性存储器
IV. Cache 由 SRAM 构成,主存由 DRAM 构成
A. II、III 和 IV
B. I、III 和 IV
C. I、II 和 III
D. I、II、III 和 IV3.【参考答案】D
【解析】I 错误,SRAM 的结构复杂,功耗更高;II 错误,SRAM 的读写速度更快;III 错误,两种都是易失性存储器;IV 错误,主存由 DRAM 和 ROM 共同构成。3.以下选项中,不正确的是( )。
A. 随机存储器和只读存储器不可以统一编址
B. 在访问随机存储器时,访问时间与存储单元的物理位置无关
C. 随机存储器 RAM 芯片可随机存取信息,掉电后信息会丢失
D. 只读存储器 ROM 芯片可随机存取信息,掉电后信息不会丢失3.【参考答案】A
【解析】主存由 RAM 和 ROM 构成,两者统一编址,A 错;B 描述的是随机访问特性,对;RAM 芯片具有随机访问特性和易失性,C 对;ROM 芯片具有随机访问特性和非易失性,D 对。(3)辅助存储器
简称辅存,又称外存,其构成取决于其具体采用的存储介质。辅存速度慢、容量大、价格低。辅存放着计算机运行时后备的程序与数据。目前大多用磁盘存储器作为辅存,辅存的内容需要调入主存后才能被 CPU 访问。
3.1.2 存储器的主要性能指标
1.存储容量
指存储器所能存放的存储单元的总位数。计算公式为:
存储容量 = 存储单元位数 × 存储单元个数
其中存储单元位数通常由编址方式决定,编址方式常为按字节编址或按字长编址。存储单元个数是存储器能存放的存储单元的数量。提示:在存储器中拥有许多用半导体或磁芯等材料制成的存储元。一个存储元存储一位 0 或 1,若干个存储元构成一个存储单元,许多的存储单元构成存储器。如按字节编址,即 8 位 bit 构成一个存储单元,一个地址单元存了 8bit 即 1B 的信息。
2.存储速度
存取时间(Ta):又称访问时间。存取时间指从存储器接收到读(或写)的命令,到从存储器读出(或写入)信息所需要的时间。
存取周期(Tm):存取周期指连续启动两次独立的读或写操作(如连续的两次读操作)相隔的最短时间,即在连续读(或写)过程中,本次读(或写)操作开始到下一次读(或写)操作开始的时间间隔。
主存带宽(Bm):又称数据传输率。主存带宽是处理器可以从主存读取数据或将数据存储到主存的最大速率。
数据传输率 = 数据的宽度 ÷ 存取周期,若存取周期为 250ns,每次读出 16 位,则该存储器的数据传送率为:(16÷8)B÷(250×10−9)s=8×106B/s。这里注意存取时间与存取周期的区别。在完成了一次读写操作之后,不能立即进行下一次访问。这是由于存储器中读出放大器、驱动电路等都有一段稳定恢复时间。如图 3.2 所示,从一次存储开始到下一次存储开始的时间为存取周期,其由存取时间和恢复时间组成。
7.连续两次启动同一存储器所需的最小时间间隔称为( )。
A. 存取周期
B. 存取时间
C. 主存带宽
D. 访问时间7.【参考答案】A
【解析】存取时间:从存储器接收到读(或写)命令到从存储器读出(或写入)信息的时间。
主存带宽:处理器可以从主存读取数据或将数据存储到主存的最大速率。
访问时间:存取时间的别名。3.1.3 习题精编
1.下面存储器为永久性存储器的是( )。
A. DRAM 和 Cache
B. SRAM 和硬盘
C. U 盘和 Cache
D. ROM 和外存1.【参考答案】D
【解析】SRAM 与 DRAM 都是易失性存储器,排除 A、B;Cache 由 SRAM 制成,故也有易失性,排除 C;D 中 ROM 与外存均有非易失性,选 D。2.下面有关存储器的说法中,正确的是( )。
A. SRAM 是非易失性存储器,DRAM 是易失性存储器
B. 辅存是按顺序访问的存储器,主存一般是按随机存取方式访问的存储器
C. 辅存是非易失性存储器,主存是易失性存储器
D. RAM 和 ROM 都可用作 Cache2.【参考答案】C
【解析】SRAM 与 DRAM 都是易失性存储器,A 错;辅存与存取关系没有必然的联系,可顺序访问也可随机存取,B 错;主存由 DRAM 制成,故是易失性存储器,C 正确;Cache 由 SRAM 制成,不是 ROM,D 错。3.以下选项中,不正确的是( )。
A. 随机存储器和只读存储器不可以统一编址
B. 在访问随机存储器时,访问时间与存储单元的物理位置无关
C. 随机存储器 RAM 芯片可随机存取信息,掉电后信息会丢失
D. 只读存储器 ROM 芯片可随机存取信息,掉电后信息不会丢失3.【参考答案】A
【解析】主存由 RAM 和 ROM 构成,两者统一编址,A 错;B 描述的是随机访问特性,对;RAM 芯片具有随机访问特性和易失性,C 对;ROM 芯片具有随机访问特性和非易失性,D 对。4.关于存储器的分类,以下选项中正确的是( )。
A. 为加快存取速度,Cache 和 TLB 都可以采用相联储存器制成
B. RAM 是破坏性读取,ROM 是非破坏性读取
C. SRAM 常用作 Cache,DRAM 常用作 TLB
D. 计算机的存储总容量 = Cache 容量 + 主存容量 + 辅存容量4.【参考答案】A
【解析】TLB 和全相联映射的 Cache 都采用相联储存器,A 正确;DRAM 是破坏性读取,SRAM 是非破坏性读取,B 错误;SRAM 常用于制作 Cache 和 TLB,C 错误;计算机的存储总容量≤主存容量 + 辅存容量,D 错误。5.相联存储器是按( )进行寻址的存储器。
A. 地址指定方式
B. 堆栈指定方式
C. 内容指定方式和堆栈存储方式相结合
D. 内容指定方式和地址指定方式相结合5.【参考答案】D
【解析】相联存储器既可以按照地址寻址也可以按照内容寻址,故 D 正确。6.设某台机器的存储容量为 512MB,其机器字长为 32 位。若按字编址,则其可寻址的单元个数为( )。
A. 64M
B. 64MB
C. 128M
D. 128MB6.【参考答案】C
【解析】机器字长 32 位 = 4B,表示一地址单元大小要 4B,所以有 512MB/4B = 128M 个地址单元。7.连续两次启动同一存储器所需的最小时间间隔称为( )。
A. 存取周期
B. 存取时间
C. 主存带宽
D. 访问时间7.【参考答案】A
【解析】存取时间:从存储器接收到读(或写)命令到从存储器读出(或写入)信息的时间。
主存带宽:处理器可以从主存读取数据或将数据存储到主存的最大速率。
访问时间:存取时间的别名。8.某计算机字长 16 位,它的存储容量是 128KB,若按字编址,那么它的寻址范围是( )。
A. 64K
B. 32K
C. 64KB
D. 32KB8.【参考答案】A
【解析】字长 16 位 = 2B,即一个地址单元可以放 2 个字节,总容量为 128KB,需要 64K 个地址单元,所以寻址范围是 64K。3.2 存储器层次结构
因为任何一类存储器都难以同时满足大容量、高速度和低成本的要求。因此,在计算机中把各种不同容量和不同存取速度的存储器按一定的结构有机地组织在一起,就形成了层次化的存储器体系结构。程序和数据按不同的层次存放在各级存储器中,使得整个存储系统整体上获得了大容量、高速度和低成本的特性。存储器层次化结构之所以能获得这样的综合效果,原因在于充分利用了局部性原理。
3.2.1 局部性原理
局部性原理可进一步分为时间局部性和空间局部性。
时间局部性:指某个数据项在被访问之后可能很快再次被访问的特性。好比你去图书馆查阅书籍,刚查阅了一本唐朔飞的《计算机组成原理》,那不久的将来你可能再次查阅它。
空间局部性:指某个数据项在被访问之后,与其地址相近的数据项可能很快被访问的特性。好比你刚刚在图书馆查阅了唐朔飞的《计算机组成原理》,你可能不久之后想查阅白中英的《计算机组成原理》或者王爽的《汇编语言》。因为图书馆通常将主题相同的书放在同一个书架上以提高空间定位效率,所以这些计算机相关的书籍往往就位于唐书所在的书架上。
对于指令而言,因为指令中存在大量的循环结构,导致同一条指令短时间内可能会多次运行,所以指令有时间局部性;同时指令往往也是顺序执行,所以指令有空间局部性。对于数据而言,同一个变量可能会短时间内被多次调用(例如循环体里面的变量),即数据有时间局部性;同时许多数据常以数组等连续结构存储,它们被存放在相邻的位置里,且常在一段时间内被顺次访问,所以这类数据具有空间局部性。
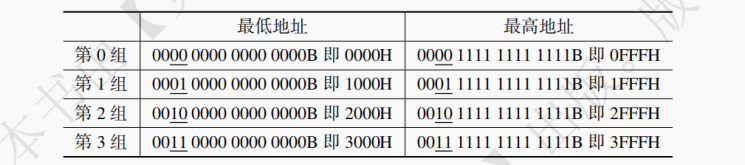
例如,考虑以下代码在内存中对数组 a [N][M] 的遍历顺序:
void visitArray (int a[N][M]) { int sum = 0; for (int i = 0; i < N; ++i) for (int j = 0; j < M; ++j) sum += a[i][j]; return sum; }在这段代码中,变量 sum 会在运行过程中被反复访问,具有很好的时间局部性。数组 a 中的每个单元在程序执行中仅仅被访问 1 次,故不具备时间局部性。但是每个单元的邻近存储单元也会被访问,故对数组 a 的访问具有良好的空间局部性;for 语句代码无论是自身还是邻近的指令(这里特指循环体里面的那行求和指令)都会在短时间内被高频访问,所以 for 语句具有良好的时间局部性和空间局部性。
对比以下代码与上述代码对数组进行访问时的区别:
int visitArray (int a[N][M]) { int sum = 0; for (int j = 0; j < M; ++j) for (int i = 0; i < N; ++i) sum += a[i][j]; return sum; }从实际运行情况看,前者的时间效率远好于后者。数组 a [N][M] 在主存的存放如图 3.3 所示,前者在主存中对数组 a 的访问顺序为:a [0][0]、a [0][1]~a [0][M-1]、a [1][0]、a [1][1]~a [N-1][M-1]。程序中连续访问的数组元素在主存中也是相邻的,故具有较好的空间局部性;后者首次被访问的是 a [0][0],之后就变成了 a [1][0],中间横跨了 M 个数组元素(a [0][1]~a [0][M-1]),如此往复对数组 a 的访问都横跨了若干个数组元素,所以后者的代码空间局部性差,实际运行效率也低于前者。
提示:默认情况下数组都是基于行优先的方式在主存中存储。在列优先的情况下,数组按照 a [0][0],a [1][0],a [2][0] 这样的形式存储,这时后者代码效果更好一些。在后面章节中,可以了解到数据在主存的存放是以块的形式,读取数据时也会将该数据所在的一块都读进来。正是因为前者代码在读取一个数据后,后面的数据也在同一块中一并被读出,所以只用读一块的时间就访问了相邻的数据。后者代码很可能因为连续访问的数据不在同一块,而导致每次访问数组都需要重新读取一块数据,继而导致了效率低下,但是当 M 较小时也有 a [i][0] 与 a [i+1][0] 在同一块的可能。
因此,在评价一段程序的局部性特性时可以参考如下原则:
(1)对相同变量有重复访问的程序有良好的时间局部性。
(2)对于具有步长为 k 且有引用模式的程序,步长越小,程序具有越好的空间局部性。
(3)循环体一般具有良好的时间局部性和空间局部性,循环体越小,循环迭代次数越多,局部性越好。
3.2.2 层次化存储器的基本结构
利用局部性原理,可以将计算机存储器组织成层次化存储器。层次化存储器由不同速度和容量的多级存储器构成。各级存储器越靠近 CPU,则容量越小、价格越高、速度越快、被 CPU 访问频次越高;反过来越是远离 CPU,则容量越大、价格越低、速度越慢、被 CPU 访问频次越低。数据一般只在相邻两层之间复制传送。但是特别地,CPU 可以和主存直接交换信息。
CPU 执行指令时,需要的操作数多数来自寄存器。如果寄存器没有 CPU 想要的数据(即 “未命中”)时,则需通过存储器读写数据。CPU 先访问低一层的 Cache;如果 Cache 未命中,则访问更低一层的主存;如果主存里也没有,则访问更低一层的辅存。最后,从辅存中读出操作数并送到主存,然后从主存送到 Cache,再送到寄存器和 CPU。此外,本层次的内容通常是低一层次的副本(即较高层存储器有的数据,较低层通常也有)。
如图 3.4 所示,目前主流的层次化存储器一般由 5 级存储器构成。正是因为局部性原理,通过合理的设计,可以将每层的未命中率降到很低,从而在相邻两层存储器间,使得速度向较高层靠近(即速度更快)的同时,让容量和价格向较低层靠近(容量更大,价格更低)。因此通过存储器的层次化结构,可以实现大容量、高速度和低成本的要求。
缓存 - 主存层次主要解决 CPU 和主存速度不匹配的问题。主存和缓存之间的数据交换是由硬件自动完成的,对任何的程序员都是透明的(“透明” 是指计算机中某个部件,它是客观存在的,对计算机的工作发挥着重要的作用,但是对于这个部件编程者无需关注其内部实现,则称之为该部件对用户透明)。主存 - 辅存层次主要解决存储系统的容量问题。硬件和操作系统共同完成主存和辅存之间的数据交换,该过程对应用程序员是透明的。
提示:在 408 考查范围内,需要区分系统程序员和应用程序员的概念。系统程序员是编写诸如操作系统、编译程序等各种系统软件的人员。应用程序员是指利用计算机及所配的系统软件支持来编写解决具体应用问题的程序员。计算机的 Cache、存储器地址寄存器(MAR)和存储器数据寄存器(MDR)等,无论是对系统程序员,还是对应用程序员都是透明的。虚拟存储器、“启动 I/O” 指令等,对系统程序员是不透明的,而对应用程序员却是透明的。
3.2.3 习题精编
1.对于下列代码,以下哪种改变使其具有更好的局部性( )。
int i, j, k, sum = 0; for(i = 0; i < N; i++) for(j = 0; j < N; j++) for(k = 0; k < N; k++) sum += a[k][j][i];A. 将第 2 行与第 3 行互换
B. 将第 2 行与第 4 行互换
C. 将第 5 行改为:sum += a [i][k][j];
D. 将第 5 行改为:sum += a [j][i][k];1.**【参考答案】**B
**【解析】** 最好的局部性即完全按地址存放顺序访问数组。B 改完后对数组 a 的访问为顺序访问,依次访问地址上连续的元素,故有更好的空间局部性。2.关于这段代码中体现出的时间局部性和空间局部性,以下说法中正确的是( )。
int get_sum(int arr[N]){ int i; int sum = 0; for(i = 0; i < N; i++) sum += arr[i]; return sum; }A. 对于变量 i 和 sum 的访问体现出较好的时间局部性,对数组 arr 的访问仅体现出空间局部性
B. 对于变量 i 和 sum 的访问体现出了较好的空间局部性
C. 对于变量 i、sum 的访问体现出了较好的时间局部性,对数组 arr 的访问体现出了较好的时间和空间局部性
D. 对于变量 i、sum 和数组 arr 的访问体现出了较好的空间局部性2.**【参考答案】**A
**【解析】**i 和 sum 经常被访问,体现出较好的时间局部性。arr 中的每个单元在程序执行中仅仅被访问 1 次,故不具备时间局部性;但每个单元的邻近存储单元也会被访问,故体现了较好的空间局部性,本题选 A。3.以下哪种存储器与 CPU 没有直接数据通路( )。
A. 内存
B. Cache
C. 硬盘
D. 寄存器3.**【参考答案】**C
**【解析】** 外存数据需要先调入内存,才能被 CPU 直接访问,故选 C。此外还可以观察存储器的层次结构得出结论。4.层次化存储器结构的设计依据的原理是( )。
A. 存储器周期性
B. 存储器强制性
C. 访问局部性
D. 容量实效性4.**【参考答案】**C
**【解析】** 根据局部性原理设计的存储器层次化结构,能提高每层命中率,从而在相邻两层存储器间,使得速度向较高层靠近的同时,让容量和价格向较低层靠近。5.CPU 可直接由地址访问的存储器是 ( )。
A. 虚拟存储器
B. 磁盘存储器
C. 磁带存储器
D. 主存储器5.**【参考答案】**D
**【解析】** 根据存储器的层次结构,能与 CPU 相互传输信息的只有 Cache 和主存,故选 D。此外还可以观察存储器的层次结构得出结论。6.对于下列三个函数,数组按行优先的方式存储,均在相同条件下运行。请你结合局部性原理对其运行效率进行排序,并说明原因。
typedef struct{ int row[3]; int col[3]; } point; point a[10]; // 初始化 point 数组的函数,按列优先访问 row 和 col 数组 void init1(point *a, int n) { int i, j; // 外层循环控制列索引 j(0~2) for(j = 0; j < 3; j++) { // 先初始化所有 point 的 row[j] 元素(按行遍历) for(i = 0; i < n; i++) a[i].row[j] = 0; // 访问模式:a[0].row[j] → a[1].row[j] → ... → a[n-1].row[j] // 再初始化所有 point 的 col[j] 元素(按行遍历) for(i = 0; i < n; i++) a[i].col[j] = 0; // 访问模式:a[0].col[j] → a[1].col[j] → ... → a[n-1].col[j] } // 内存访问顺序:row[0] 全量 → col[0] 全量 → row[1] 全量 → col[1] 全量 → ... } // 初始化 point 数组的函数,按行优先访问每个 point 的 row 和 col 数组 void init2(point *a, int n) { int i, j; // 外层循环控制行索引 i(0~n-1) for(i = 0; i < n; i++) { // 先初始化当前 point 的 row 数组(连续 3 个元素) for(j = 0; j < 3; j++) a[i].row[j] = 0; // 访问模式:a[i].row[0] → a[i].row[1] → a[i].row[2] // 再初始化当前 point 的 col 数组(连续 3 个元素) for(j = 0; j < 3; j++) a[i].col[j] = 0; // 访问模式:a[i].col[0] → a[i].col[1] → a[i].col[2] } // 内存访问顺序:a[0].row 全量 → a[0].col 全量 → a[1].row 全量 → a[1].col 全量 → ... } // 初始化 point 数组的函数,按行优先交替访问 row 和 col 的相同索引元素 void init3(point *a, int n) { int i, j; // 外层循环控制行索引 i(0~n-1) for(i = 0; i < n; i++) { // 内层循环控制列索引 j(0~2),每次处理 row 和 col 的同一列 for(j = 0; j < 3; j++) { a[i].row[j] = 0; // 访问当前 point 的 row[j] a[i].col[j] = 0; // 立即访问当前 point 的 col[j] } // 内存访问顺序:a[i].row[0] → a[i].col[0] → a[i].row[1] → a[i].col[1] → ... } }6.**【参考答案】**init2 > init3 > init1,init2 的访问在物理上完全是连续的,拥有更好的空间局部性;init3 对于结构体 point 本身的访问不符合空间局部性要求,但对于 point 数组来说满足局部性;init1 不仅对于数组还是结构体,都不满足空间局部性。
三个函数的运行效率排序为:init2 > init3 > init1,具体分析如下:
数据布局与访问模式
point 结构体包含两个数组 row[3] 和 col[3],按行优先存储时,内存布局为:
a[0].row[0], a[0].row[1], a[0].row[2], a[0].col[0], a[0].col[1], a[0].col[2],
a[1].row[0], a[1].row[1], ..., a[9].col[2]
各函数局部性分析
//init1 for(j = 0; j < 3; j++){ for(i = 0; i < n; i++) a[i].row[j] = 0; // 访问 row[j] 所有元素 for(i = 0; i < n; i++) a[i].col[j] = 0; // 访问 col[j] 所有元素 }空间局部性差:
先访问所有 row[j](如 a[0].row[0], a[1].row[0], ...),再访问所有 col[j]。
每次访问跳跃步长为 sizeof(point)(24 字节),导致频繁缓存失效。
时间局部性差:同一结构体的 row 和 col 被分开处理,无法利用缓存行预取。
//init2 for(i = 0; i < n; i++){ for(j = 0; j < 3; j++) a[i].row[j] = 0; // 访问 a[i] 的 row 数组 for(j = 0; j < 3; j++) a[i].col[j] = 0; // 访问 a[i] 的 col 数组 }空间局部性最优:
先访问 a[i] 的 row 数组(连续 3 个元素),再访问 col 数组(连续 3 个元素)。
内存访问完全连续(步长为 4 字节),充分利用缓存行预取。
时间局部性好:同一结构体的 row 和 col 被连续处理,减少缓存失效。
//init3 for(i = 0; i < n; i++){ for(j = 0; j < 3; j++){ a[i].row[j] = 0; // 访问 a[i] 的 row[j] a[i].col[j] = 0; // 访问 a[i] 的 col[j] } }空间局部性中等:
访问顺序为 a[i].row[0], a[i].col[0], a[i].row[1], a[i].col[1], ...。
每次在 row 和 col 之间跳跃 3*sizeof(int)(12 字节),缓存行利用率约 50%。
时间局部性较好:同一结构体的 row[j] 和 col[j] 被连续访问,但整体跨度大于 init2。
效率排序原因
init2:内存访问完全连续,充分利用缓存行预取,缓存命中率最高。
init3:访问跨度较小,但交替访问 row 和 col,缓存行利用率低于 init2。
init1:访问跳跃步长最大,频繁跨缓存行访问,缓存失效最多。
结论
在数据按行优先存储的情况下,init2 通过连续访问同一结构体的所有成员,实现了最优的空间局部性,因此运行效率最高。
3.2.4 真题演练
7.【2017】某 C 语言程序段如下,下列关于数组 a 的访问局部性的描述中,正确的是 ( )。
// 外层循环:遍历数组 a 的前 10 个元素(i 从 0 到 9) for (i = 0; i <= 9; i++) { // 重置临时变量 temp 为 1,用于计算当前轮次的阶乘或累积乘积 temp = 1; // 内层循环:计算数组 a 中前 i+1 个元素的累积乘积(从 a[0] 到 a[i]) for(j = 0; j <= i; j++) temp *= a[j]; // 累积乘积:temp = temp * a[j] // 将当前轮次的累积乘积累加到总和 sum 中 sum += temp; }A. 时间局部性和空间局部性皆有
B. 无时间局部性,有空间局部性
C. 有时间局部性,无空间局部性
D. 时间局部性和空间局部性皆无7.【参考答案】A
【解析】 数组 a 的元素在访问中不仅单个元素自己会在短时间内被访问多次,且相邻元素在不久的将来也将被多次访问,故数组 a 既具有时间局部性也具有空间3.3 半导体随机存储器
3.3.1 半导体存储芯片的基本结构
1.基本结构
如图 3.5 所示,一个半导体存储器的基本结构包括存储矩阵、译码驱动电路、读写电路和控制电路,此外半导体存储器还与地址线、数据线、片选线和读写控制线相接。
(1) 存储矩阵是存储单元的集合,负责存储数据,是半导体存储器的核心部分。
1.关于半导体存储器的组织,以下选项中不正确的是( )。
A. 同一个存储器中,每个存储单元的宽度可以不同
B. 所谓 “编址” 是指给每个存储单元一个编号
C. 存储器的核心部分是存储阵列,由若干存储单元构成
D. 每个存储单元由若干个存储元件构成,每个存储元件存放一个 0 或 1 的比特位1.【参考答案】A
【解析】存储单元的宽度即存储器数据线的宽度,对于同一个存储器来说是确定的,A 错。(2) 译码驱动电路与地址线相接,负责将 CPU 传来的地址信号翻译成对特定存储单元的选择信号,选定待访问的特定存储单元。
(3) 读写电路与数据线相接,负责将待写入的数据写入存储矩阵,或者从存储矩阵读出数据。
(4) 控制电路负责控制存储器进行读操作或者写操作。
(5) 数据线是双向的,负责传输待读出的数据或者待写入的数据。地址线是单向的,负责将待访问的存储器地址传入译码器中。读写控制线是单向的,负责传输 CPU 向存储器下达的读 / 写命令。片选线是单向的,负责选定需要访问的存储器芯片。2.译码驱动方式
译码驱动负责将 CPU 传来的地址信号翻译成对特定存储单元的选择信号,选定待访问的特定存储单元。具体的方法有两种:线选法和重合法。
(1) 线选法(单译码)
在这种方式中,地址译码器只有一个。例如,地址输入线引脚数 n = 4,经地址译码器译码,可译出2^4=16个状态,分别对应 16 个字地址。其中 0000 对应第 0 行共 8 个存储单元,0001 对应第 1 行共 8 个存储单元,……,1111 对应第 15 行共 8 个存储单元。通过 n 个地址引脚可定义一个大小为2^n字的地址空间,即译码器的输入端为 n 根引脚的情况下,其输出端的引脚数为2^n个。因此线选法的缺点是译码后输出端的线数量过多,故只适用于容量小的静态存储器。
(2) 重合法(双译码)
为了节省驱动电路和解决线选法存在的缺陷,可以使用重合法。重合法的原理就是类似笛卡尔坐标系,实数对(X,Y)能够唯一确定 1 个存储单元,实数对中的 X 由行地址译码驱动来译码,Y 由列地址译码驱动译码。使用重合法,在译码器的输入端为 n 根引脚的情况下,其输出端的引脚数只需要
个。这种方法适用于大容量的动态存储器局部性。
3.3.2 SRAM
全称静态随机存取存储器(Static Random Access Memory)。SRAM 的每个存储元由一个双稳态触发器构成,而一个双稳态触发器需要 6 个 MOS 管。所以 SRAM 的单位面积能容纳的存储元数较 DRAM 小(集成度小),且功耗更高。“静态” 是指这种存储器只要保持通电,里面储存的数据就可以恒常保持(即不需时常刷新),也不会因为读操作而使状态发生改变,故 SRAM 的读出不是破坏性读出。但是断电时 SRAM 同样会丢失数据,所以是一种易失性存储器。破坏性读出和易失性都是指数据的丢失,破坏性读出体现在工作中读数据后,易失性体现在断电后。SRAM 多用于制作 Cache。
3.关于 SRAM 和 DRAM 的特点,以下选项不正确的是( )。
I. SRAM 不需要刷新,而 DRAM 需要刷新,因此 DRAM 的功耗更高
II. DRAM 比 SRAM 集成度更高,因此读写速度也更快
III. SRAM 是易失性存储器,而 DRAM 是非易失性存储器
IV. Cache 由 SRAM 构成,主存由 DRAM 构成
A. II、III 和 IV
B. I、III 和 IV
C. I、II 和 III
D. I、II、III 和 IV3.【参考答案】D
【解析】I 错误,SRAM 的结构复杂,功耗更高;II 错误,SRAM 的读写速度更快;III 错误,两种都是易失性存储器;IV 错误,主存由 DRAM 和 ROM 共同构成。3.3.3 DRAM
1. DRAM 的工作原理
全称动态随机存取存储器(Dynamic Random Access Memory)。DRAM 的每个存储元通常仅由 1 个电容和 1 个 MOS 管构成,所以 DRAM 的集成度高于 SRAM,且功耗更小。DRAM 中某个电容存储的电荷数达到或超过阈值时,该电容所在存储元表示 1,否则表示 0。因为栅极电容上的电荷会随着时间的推移泄漏掉,导致数据丢失,故每隔一定的时间必须向栅极电容补充一次电荷。这个过程称为 “刷新”,因此 DRAM 被称为 “动态” 存储器。DRAM 与 SRAM 一样,会在断电时失去数据。此外,DRAM 的读取过程也会让电容的电荷泄漏掉,所以 DRAM 的读出为破坏性读出,需要在读出后恢复被读出的电容上的电荷,这个过程称作 “再生”。
提示:尽管都是恢复数据,但是刷新过程与再生过程并不同。刷新以行为单位,逐行顺序地恢复数据。再生仅恢复被读出的那个单元的数据。
DRAM 一般使用行列地址复用技术,而 SRAM 一般使用行列独立技术。
提示:所谓行列地址复用技术,即使用重合法时分先后两次将存储矩阵的行地址和列地址传入译码驱动电路,从而可以将地址线的数量减半;行列独立技术即一次性传递整个访问地址,地址线数量不减半。DRAM 之所以采取地址复用技术,是因为 DRAM 的大小较 SRAM 大很多,所以引入行列地址复用技术能有效减少芯片引脚数目。
如图 3.8 为 16×8 的 DRAM 芯片,其内部存储单元呈 4 行 4 列结构。一个存储单元存放 8 位数据,故数据线线数为 8。又因其为行列地址复用,所以传送地址时,先传送 2 位地址决定是哪一行,再传送 2 位地址决定是哪一列,以此来寻址。
【例 3-1】某存储器由若干 16M×8 位的 DRAM 芯片构成,该 DRAM 芯片的地址线和数据线各是多少?
答:16M×8bit 的 DRAM 芯片,其中 16M = 2²⁴ ,又因为 DRAM 采取地址复用技术,所以地址线引脚数减半,为 12 个。8 位的数据线引脚数为 8 个。所以有地址线 12 条和数据线 8 条。2. DRAM 刷新
因为电容会漏电,所以 DRAM 的单个存储单元必须时常刷新,否则会因漏电发生数据丢失。刷新的过程相当于以行为单位,对 DRAM 中该行的全体电容先读取一次数据再写入一次数据。因为 DRAM 电容中的电荷会因漏电而不断损失,最终在 10 - 64ms 后丢失存储的数据,为避免数据的丢失,每一行的刷新时间间隔必须不超过 2ms。
10.下列关于存储器的叙述正确的是( )。
I. 动态存储器是利用电容电荷来存储信息的,需要周期性逐个刷新每一个存储单元
II. FLASH 具有不易失特性,所以它是 ROM 且无法更新存储单元
III. DRAM 是动态存储器,采用随机存取方式,存取地址需分两次送入
A. I
B. I、II
C. II、III
D. III10.【参考答案】D
【解析】动态存储器按行刷新存储信息而非逐个刷新,I 错误;FLASH 可以在断电的情况下长期保存信息,并且可以反复擦除与重写,II 错误;DRAM 采用地址复用技术,分两次逐个传送行选通与列选通信息,III 正确。由于刷新是个 “假读” 的过程,所以刷新一行的时间与存储周期等长。此外,同一行先后相邻 2 次刷新的时间间隔称为刷新周期。DRAM 有 3 种刷新方式:集中、分散和异步。
(1) 集中刷新
在允许的最大刷新间隔 (如 2ms) 内,按照存储芯片容量的大小,在若干个读写周期之后,集中安排若干个读写周期用于刷新操作,刷新时停止读写操作。这一段时间内主存无法进行正常的读写操作,故被称为 “死时间”,又称为访存 “死区”。
如图 3.10 为 16 行的 DRAM,每刷新一行用时 0.5μs,而每次集中刷新相隔 2ms。所以 2ms 内有 2ms/0.5μs = 4000 个正常的读写周期,其后 16 个周期被用于给 16 行每行刷新一次,此时 CPU 无法对 DRAM 进行读写操作。前 4000 - 16 = 3984 个周期作为存储周期,用于 CPU 对 DRAM 的正常读写操作。故死时间长度为 16×0.5μs = 8μs,死时间率为 8/(2×10³) = 0.4%。(2) 分散刷新
将每一个存储周期分为两段,前一段正常读写(时长为原来的一个存储周期),后一段时间刷新主存(时长为刷新一行的时间)。这么做可以完全避免死时间,但是新的存储周期比原来的存储周期长,降低了 DRAM 的读写性能。此外刷新过于频繁,尤其是当存储容量比较小的情况下,没有充分利用所允许的最大刷新间隔(2ms)。假设新的存储周期为 1μs,而 DRAM 一共有 16 行,那么只用了 16μs 就完整地刷新了一次 DRAM,刷新过于频繁。
(3) 异步刷新
结合上述两种方式,使得在一个刷新周期内每一行被刷新且仅刷新一次。若刷新周期为 2ms,则相邻两行的刷新时间的间隔就是 2ms/(行数) 。假设每刷新一行为 0.5μs,一共有 16 行,则每隔 2/16 = 0.125ms 就刷新下一行的 DRAM 存储单元(若已到最后一行则回归第 0 行进行刷新操作)。这样并没有降低死时间占总体时间的占比,但是死时间不再聚集分布,因此死时间可以认为是 0.5μs,与上例中集中刷新下的 8μs 相比有很大的进步。
3. DRAM 的读写信号时序
图 3.13 是 DRAM 芯片读写信号时序示意图。其中
为行选通信号(
自身不传输行地址,而是在其低电平时声明当前地址线的信号为行地址)。
为列选通信号(同上,在其低电平时声明当前地址线的信号为列地址)。第三行为地址线,负责先传输行地址,再传输列地址。
为读写控制信号,高电平时确定 DRAM 芯片应采取读操作,低电平时为采取写操作。第五行是数据线,负责传出已读出的数据或者传入预写入的数据(在图中根据是读还是写分别被标为 Dout 和 Din )。
读周期中,CPU 与主存间发送的信号必须满足一定的顺序关系,否则无法正常的完成读写操作。
(1) 在
(2)
(3)
(4) 在
(5) 每次读操作以后必须对被读的单元进行一次写操作,以恢复因读出而被破坏的数据。
在写周期中,
(1)
(2) 待写入数据在4. SDRAM
现代计算机的主存通常是基于 SDRAM(synchronous DRAM)(同步动态随机存取存储器)芯片技术的。与传统 DRAM 和 CPU 之间使用异步方式传输数据不同,SDRAM 和 CPU 之间使用同步方式传输数据,其读写受系统时钟控制,且支持突发传送方式。只需给出一批数据的首地址,之后按地址顺序读写,就可以从行缓冲器中传输地址连续的多个单元的数据。
SDRAM 内部的工作方式寄存器可以设置传输数据的长度(即突发长度,burst lengths,BL),以及收到读命令到开始传送数据的延迟时间(即 CAS 时延,CAS latency,CL)。SDRAM 芯片的工作过程大致如下。
(1) 在 CLK 时钟上升沿片选信号与行地址选通信号
(2) 经过一段延时 tRCD(RAS to CAS delay),列选通信号
(3) 对于读操作,再经过一个 CAS 时延,输出数据开始有效,之后的每个时钟都有一个或者多个数据持续从总线上传输,直到传送完突发长度 BL 设定的所有数据。对于写操作,则没有 CAS 延时而直接开始写入。
因为只有读操作有 CL,所以 CL 又可以称为读取潜伏期(Read Latency,RL)。tRCD 和 CL 都以时钟周期 TCR 为单位。3.3.4 只读存储器
与 RAM 不同,只读存储器(ROM)中的数据一经写入就不轻易改变,即使断电也不失去信息,属于非易失性存储器。此外尽管 ROM 的写入受限制,但 ROM 同 RAM 一样采取随机存取的访问方式。
根据制作工艺的不同,ROM 可分为掩模编程的只读存储器(MROM)、可编程的只读存储器(PROM)、可擦除可编程的只读存储器(EPROM)、电可擦除可编程的只读存储器(EEPROM)、闪速存储器(Flash Memory)和固态硬盘(Solid State Drive)。MROM(Mask ROM):在制造过程中,将数据以一特制掩模(Mask)烧录于线路中。这种存储器一旦由生产厂家制造完毕,用户就无法修改。优点是存储内容固定,掉电后信息仍然存在,可靠性高。缺点是信息一次写入(制造)后就不能修改。
8.下列存储芯片无法多次写入信息的是( )。
A. RAM
B. MROM
C. FLASH
D. EEPROM8.【参考答案】B
【解析】只有 ROM 存在无法多次写入的存储器,排除 RAM。MROM 是 ROM 的一种,全称掩模式只读存储器。其信息由厂商按用户要求在生产过程中直接写入的,写入后无法修改其中内容,因此只可写入 1 次,无法多次写入。PROM(Programmable ROM):允许用户通过专用的设备(编程器)一次性写入自己所需要的信息,其一般可编程一次,PROM 存储器出厂时各个存储单元皆为 1,或皆为 0。用户使用时,可以使用编程的方法在 PROM 中存储所需要的数据。
EPROM(Erasable Programmable ROM):是一种以读为主的可写可读的存储器。是一种便于用户根据需要来写入,并能把已写入的内容擦去后再改写的 ROM。其存储的信息可以由用户自行加电编写,也可以利用紫外线光源或脉冲电流等方法先将原存的信息擦除,然后用写入器重新写入新的信息。
15.【2011】下列各类存储器中,不采用随机存取方式的是( )。
A. EPROM
B. CD - ROM
C. DRAM
D. SRAM15.【参考答案】B
【解析】EPROM 属于 ROM;DRAM 和 SRAM 属于 RAM。而 ROM 和 RAM 都是随机读写的,所以 EPROM、DRAM、SRAM 都可随机读写,CDROM 属于只读光盘存储器,使用串行存取,不属于 ROM,无法随机存取,可以联系我们生活中使用光盘的例子。EEPROM(Electrically Erasable Programmable ROM):随时可写入而无须擦除原先内容的存储器,其写操作比读操作时间要长得多,EEPROM 把不易丢失数据和修改灵活的优点组合起来,修改时只需使用普通的控制、地址和数据总线。
提示:ROM 中名字带 E 的种类均可再次写入,因为 E 代表 “Erasable”(“可擦写的”)。闪速存储器(Flash Memory):简称闪存,是英特尔公司在 90 年代中期发明的一种高密度、非易失性的读 / 写半导体存储器。它既有 EEPROM 的特点(断电时不失去数据),又有 RAM 的特点(可以擦写,可以随机读写),因而其存储特性相当于硬盘。不过闪存读取数据时一般以块而非字节为基本单位。主要用于计算机与其他数字产品间交换传输数据,如储存卡与 U 盘。
固态硬盘(Solid State Drive):又称固态驱动器,简称 SSD,是用固态电子存储芯片阵列制成的硬盘。是基于闪速存储器制作出来的。关于固态硬盘的细节介绍见本章第 5 节。
提示:闪存与固态硬盘均属于广义上的 ROM,但又没有保留 ROM “只读” 的特性。
3.3.5 习题精编
1.关于半导体存储器的组织,以下选项中不正确的是( )。
A. 同一个存储器中,每个存储单元的宽度可以不同
B. 所谓 “编址” 是指给每个存储单元一个编号
C. 存储器的核心部分是存储阵列,由若干存储单元构成
D. 每个存储单元由若干个存储元件构成,每个存储元件存放一个 0 或 1 的比特位1.【参考答案】A
【解析】存储单元的宽度即存储器数据线的宽度,对于同一个存储器来说是确定的,A 错。2.某 1024K×32 位的存储器由若干片 128K×16 位的 SRAM 芯片构成,每次读写 4 字节数据。若存储器按字节编址,则该存储器的地址线和数据线分别有( )条。
A. 20,8
B. 22,8
C. 20,32
D. 22,322.【参考答案】C
【解析】题目中 SRAM 的容量为干扰项,只需根据其组成的存储器计算即可。按字节编址,1024K=2^20,log2 2^20=20,即地址线有 20 条。每次读写 4B 数据,数据线有 4×8=32 条。故本题选 C。
2.答案:C
解析:
1.地址线数量计算
1.已知该存储器按字节编址,总容量为1024K×32位。因为1024K=2^10×2^10=2^20 ,这里的2^20表示存储单元的数量。
2.地址线的作用是对存储单元进行寻址,有多少个存储单元就需要多少位二进制数来表示其地址,所以地址线的数量取决于存储单元的个数。n位地址线能表示的地址空间为2^n ,这里n=20 ,即地址线有20条。
2.数据线数量计算
1.题目中明确说明每次读写4字节数据,而1字节等于8位,那么4字节就是4×8=32位。
2.数据线的作用是传输数据,其数量与每次读写的数据位数相同,所以数据线有32条。
综上,该存储器的地址线有20条,数据线有32条 ,答案选 C。
3.关于 SRAM 和 DRAM 的特点,以下选项不正确的是( )。
I. SRAM 不需要刷新,而 DRAM 需要刷新,因此 DRAM 的功耗更高
II. DRAM 比 SRAM 集成度更高,因此读写速度也更快
III. SRAM 是易失性存储器,而 DRAM 是非易失性存储器
IV. Cache 由 SRAM 构成,主存由 DRAM 构成
A. II、III 和 IV
B. I、III 和 IV
C. I、II 和 III
D. I、II、III 和 IV3.【参考答案】D
【解析】I 错误,SRAM 的结构复杂,功耗更高;II 错误,SRAM 的读写速度更快;III 错误,两种都是易失性存储器;IV 错误,主存由 DRAM 和 ROM 共同构成。4.DRAM 具有破坏性读出的特性,需要定时刷新,因此被称为动态随机存储器。以下选项中不正确的是( )。
A. 刷新是以行为单位的
B. 刷新是为了给 DRAM 存储单元中的存储电容重新充电
C. 刷新是通过对存储单元进行 “读但不输出数据”,即 “假读” 的操作来实现的
D. DRAM 内部设有专门的刷新电路,不会影响到 CPU 的正常访存4.【参考答案】D
【解析】D 错误,刷新也是一个读取的过程,会和 CPU 的访存冲突,所以会有 “死时间”;刷新指每隔一定的时间必须向栅极电容补充一次电荷,并以行为单位,对 DRAM 中该行的全体电容先读取一次数据再写入一次数据,故 A、B、C 均为正确描述。5.对于某存储芯片,假定动态刷新间隔为 2ms,读写周期和刷新周期均为 0.2μs,该芯片中包含 128 行,每个刷新周期可以完成 1 行存储单元的刷新,如果该芯片采用异步刷新方式工作,那么其读写周期和刷新周期安排为( )。
A. 3999 次读写周期后,安排一次刷新操作
B. 2000 次读写周期后,安排一次刷新操作
C. 128 次读写周期后,安排一次刷新操作
D. 64 次读写周期后,安排一次刷新操作5.【参考答案】D
【解析】2ms/128行=12.625μs/行,所以最大每隔 15.625μs 就需要刷新一行,15.625/0.2=78.125 次读写操作,即最多 78 次读写操作就要一次刷新,本题符合的选项只有 D 选项。6.关于 RAM 和 ROM 芯片,以下选项不正确的是( )。
A. ROM 和 RAM 都采用随机访问方式进行读写
B. RAM 是可读可写存储器,ROM 是只读存储器
C. 系统的主存由 RAM 和 ROM 组成
D. 系统的主存都用 DRAM 芯片实现6.【参考答案】D
【解析】系统的主存可由 RAM 和 ROM 组成,故 C 正确,D 错误,RAM 为随机存取存储器,ROM 为只读存储器,都可随机访问,故 A、B 均为正确描述。7.关于半导体存储器的特点,以下选项不正确的是( )。
A. ROM 芯片采用随机存取方式进行读写
B. ROM 芯片属于半导体随机存储器芯片
C. SRAM 是半导体静态随机访问存储器,可用作 Cache 和 TLB
D. DRAM 是半导体动态随机访问存储器,可用作主存7.【参考答案】B
【解析】ROM 芯片属于只读存储器芯片,故 B 错误,ROM 可随机存取,SRAM 由于速度更快,价格昂贵,常用作 Cache 和 TLB,DRAM 速度偏慢,价格便宜,常用作主存,故 A、C、D 均为正确描述。8.下列存储芯片无法多次写入信息的是( )。
A. RAM
B. MROM
C. FLASH
D. EEPROM8.【参考答案】B
【解析】只有 ROM 存在无法多次写入的存储器,排除 RAM。MROM 是 ROM 的一种,全称掩模式只读存储器。其信息由厂商按用户要求在生产过程中直接写入的,写入后无法修改其中内容,因此只可写入 1 次,无法多次写入。9.以下对半导体存储器的叙述正确的是( )。
A. Flash 存储器功耗低,集成度高,读写速度一样快,目前得到了广泛使用
B. SRAM 是易失性半导体存储器,需要刷新,用作 Cache
C. DRAM 集成度高、功耗低,用作主存
D. EEPROM 是一种需要通过紫外线擦除的存储器9.【参考答案】C
【解析】Flash 存储器写操作之前需要先擦除,所以读要比写快,对于大多数存储器来说,读一般都比写快,A 选项错误;SRAM 存储器不需要刷新,DRAM 才需要刷新,B 选项错误;C 选项为关于 DRAM 的正确描述,正确;EEPROM 是一种需要通过电擦除的存储器,UVEPROM 才是紫外线擦除存储器,D 选项错误。10.下列关于存储器的叙述正确的是( )。
I. 动态存储器是利用电容电荷来存储信息的,需要周期性逐个刷新每一个存储单元
II. FLASH 具有不易失特性,所以它是 ROM 且无法更新存储单元
III. DRAM 是动态存储器,采用随机存取方式,存取地址需分两次送入
A. I
B. I、II
C. II、III
D. III10.【参考答案】D
【解析】动态存储器按行刷新存储信息而非逐个刷新,I 错误;FLASH 可以在断电的情况下长期保存信息,并且可以反复擦除与重写,II 错误;DRAM 采用地址复用技术,分两次逐个传送行选通与列选通信息,III 正确。11.SRAM 芯片的引脚类型有电源线、接地线、地址线、数据线、片选线和读写控制线。求除去电源和接地端外,一个容量为 16K×8 位的 SRAM 芯片的引脚数量最少为( )条。
A. 22
B. 23
C. 24
D. 2511.【参考答案】C
【解析】16K=2^14,即地址线 14 条。8 位即数据线 8 条。一条片选线。因为是 “最少”,所以读写控制线选一条,共 24 条。12.存储容量为 16K×4 位的 DRAM 芯片,其地址引脚和数据引脚数各是( )。
A. 7,1
B. 7,4
C. 14,1
D. 14,412.【参考答案】B
【解析】DRAM 行列地址复用,16K=2^14,14/2=7 个地址引脚;数据引脚 = 位数 = 4 个,故 B 为正确答案。13.一个 8K×8 位的存储器由 1K×4 位的 DRAM 芯片组成。该 DRAM 内部结构为 64×64 的形式,若最大刷新间隔为 2ms,存取周期为 0.2μs,请回答以下问题:
(1) 使用集中刷新方式时,死时间率是多少?
(2) 使用分散刷新方式时,若刷新周期为 2μs,则刷新完整一次 DRAM 的时间是多少?
(3) 使用分散刷新和集中刷新相结合的方式时,每相邻两行的刷新间隔为多少?13.【参考答案】
(1) DRAM 按行刷新,共 64 行,存储周期为 0.2μs,所以需要集中 12.8μs 刷新,此时间为死时间,故死时间率为 (12.8μs/2ms)×100%=0.64%。
(2) 分散刷新即每个刷新周期刷新一行,完整刷新一遍需要 2μs×64=128μs。
(3) 分散刷新和集中刷新相结合即异步刷新,将最大刷新间隔平均到每一行,即 2ms/64=31.25μs。3.3.6 真题演练
14.【2010】下列有关 RAM 和 ROM 的叙述中,正确的是( )。
I. RAM 是易失性存储器,ROM 是非易失性存储器
II. RAM 和 ROM 都采用随机存取方式进行信息访问
III. RAM 和 ROM 都可用作 Cache
IV. RAM 和 ROM 都需要进行刷新
A. 仅 I 和 II
B. 仅 II 和 III
C. 仅 I、II 和 IV
D. 仅 II、III 和 IV14.【参考答案】A
【解析】RAM 是断电会失去数据,而 ROM 断电不失去数据,故 I 正确;尽管部分 ROM 对写入有限制,但是 ROM 和 RAM 一样采取随机存取的访问方式,故 II 正确;ROM 和 DRAM 不适合用于制作 Cache,Cache 一般由 SRAM 制作,III 错误;SRAM 和 ROM 不需时常刷新,说法太绝对,IV 错误。15.【2011】下列各类存储器中,不采用随机存取方式的是( )。
A. EPROM
B. CD - ROM
C. DRAM
D. SRAM15.【参考答案】B
【解析】EPROM 属于 ROM;DRAM 和 SRAM 属于 RAM。而 ROM 和 RAM 都是随机读写的,所以 EPROM、DRAM、SRAM 都可随机读写,CDROM 属于只读光盘存储器,使用串行存取,不属于 ROM,无法随机存取,可以联系我们生活中使用光盘的例子。16.【2012】下列关于闪存(Flash Memory)的叙述中,错误的是( )。
A. 信息可读可写,并且读、写速度一样快
B. 存储元由 MOS 管组成,是一种半导体存储器
C. 掉电后信息不丢失,是一种非易失性存储器
D. 采用随机访问方式,可替代计算机外部存储器16.【参考答案】A
【解析】闪存作为 ROM 的一种,其读操作速度要大于写操作速度,A 错误;无论是 ROM 还是 RAM,都需要使用 MOS 管制作存储单元,B 说法正确;闪存是 ROM 的一种,所以断电不会失去数据,C 说法正确;闪存作为 ROM 的一种,与 RAM 一样采取随机读写的方式,且闪存可多次擦写,因而在功能上类似于磁盘和光盘,所以可以用于替代外存储器,D 说法正确。17.【2014】某容量为 256MB 的存储器由若干 4M×8 位的 DRAM 芯片构成,该 DRAM 芯片的地址引脚和数据引脚总数是( )。
A. 19
B. 22
C. 30
D. 3617.【参考答案】A
【解析】题目问的是 4M×8 位的 DRAM 芯片引脚,而 256MB 属于误导项,在解题过程中没有被使用;4M×8bit 的 DRAM 芯片,其中 4M=2^22,又因为 DRAM 采取地址复用技术,所以地址线引脚数减半,为 11 个,而数据线引脚数为 8 个,所以总共 19 根引脚。18.【2015】下列存储器中,在工作期间需要周期性刷新的是( )。
A. SRAM
B. SDRAM
C. ROM
D. FLASH18.【参考答案】B
【解析】在我们所需掌握的存储器中,DRAM 因栅极电容上的电荷会随着时间的推移泄漏掉,导致数据丢失,所以需要周期性刷新。SDRAM 全称同步动态随机存储器,是一种有同步接口的 DRAM,故选 B。19.【2018】假定 DRAM 芯片中存储阵列的行数为 r、列数为 c,对于一个 2K×1 位的 DRAM 芯片,为保证其地址引脚数最少,并尽量减少刷新开销,则 r、c 的取值分别是( )。
A. 2048、1
B. 64、32
C. 32、64
D. 1、204819.【参考答案】C
【解析】四个选项都满足 2K×1 位的 DRAM 芯片要求,因为采取地址复用技术,所以不能让行数和列数相差过多,A、D 所需地址线多于 B、C 选项,故排除 A、D 选项。DRAM 按行刷新,为了让刷新次数不过于频繁,尽量减少刷新开销,所以尽可能使行数少,选 C。3.4 主存储器
3.4.1 主存储器的组成和基本操作
主存储器由 DRAM 和 ROM 构成。
在主存储器中,最核心的部件就是存储体。存储体由存储单元构成,存储单元中的存储元拥有 2 种稳态,可存储 0 或 1 两种信息。为了区分这些存储单元,必须给每个存储单元编号(即编址)。存储单元的编址可以按字节进行编址(1 个地址对应 8 个存储元),也可以按字进行编址。对于主存储器中的 DRAM 而言,一般采取地址复用技术以减少地址引脚数。
当 CPU 要读取主存储器的数据时,CPU 将预访问的主存地址传入 MAR,并让 MAR 将地址通过地址总线传入主存的译码器。同时 CPU 通过读写控制线向主存的控制电路发出读信号。主存收到读信号后,通过译码驱动将地址信号转变为选择信号,选定存储单元并读出数据到数据总线上并传送给 MDR。
提示:MAR 为主存地址寄存器,用来存放指令或数据的主存地址。MDR 为主存数据寄存器,用来存放即将写入或读出的数据。关于 MAR 和 MDR,详见第 5 章内容。
当 CPU 要向主存储器写入数据时,CPU 将预写入的主存地址传入 MAR,并让 MAR 将地址通过地址总线传入主存的译码器。同时 CPU 通过读写控制线向主存的控制电路发出写信号。然后 CPU 将欲写入的数据传入 MDR,并让 MDR 将数据通过数据总线传入主存的读写电路。主存收到写信号后,通过译码驱动将地址信号转变为选择信号,选定存储单元并将数据写入该存储单元。
如图 3.15 为 8×8 位的存储器,MAR 的位数与地址线的宽度相同,决定了地址空间的大小。图中 MAR 的位数为 3 位,则地址空间为 0 ~ 2³ - 1。MDR 的位数与数据线的宽度相同,决定了每次最多可存取的数据大小。图中 MDR 为 8 位,则一次可最多存取 1 字节的内容。当 MAR 的位数为 A 位,MDR 的位数为 B 位时,地址空间的大小最大为 2ᴬ×B 位。
3.4.2 主存与 CPU 的连接
由于单个存储芯片的容量有限,主存储器往往必须由多个存储芯片组合而成(即芯片拓展)。除此之外还要通过合理的排线,解决主存与 CPU 的连接问题。
要组成一个主存,首先要考虑选取合适的 DRAM 芯片,然后再将这些 DRAM 芯片合理地连接起来。根据所需主存储器的总容量和单个存储芯片的容量,就可以计算出需要的芯片数,即需要的芯片个数 = 总容量 / 单片容量。
例如:存储器容量为 8K×8bit,若选用 1K×4bit 的存储芯片,则总容量为 8K×8 = 64Kbit,单片容量为 1K×4 = 4Kbit,总片数为 64K/4K = 16 片。1.CPU 与主存连接的一般流程
(1)合理选择存储芯片
制作主存的存储芯片分为 DRAM 和 ROM。前者一般预留给用户,后者则存储各种固定程序和数据。
(2)地址线的连接
CPU 的地址线引脚数往往高于存储芯片的地址线引脚数,所以将地址线的低位引脚与存储芯片相接,用于传递字选信号。而高位则与译码器相接,用于生成片选信号。
(3)数据线的连接
如果 CPU 与存储芯片的数据线引脚数相同,则可直接连接,否则要根据位拓展或者字位拓展的要求连接。
(4)读写控制线的连接
若读写控制线为 1 根,则可直接连接;若分读控制线和写控制线,则按功能分别直接连接。
(5)片选线的连接
将译码器输出端通过片选线与每个存储芯片的 CS 端相接即可。芯片的拓展分为位拓展、字拓展、字位拓展。
2.位拓展
位拓展是指仅在位数方向上拓展(加大存储字长),而芯片的地址空间大小和存储器的地址空间大小是一致的。在位拓展中,各存储芯片的地址线、片选线和读写线相应地并联起来,数据线则分别单独列出。
【例 3 - 2】用 4K×2bit 的 DRAM 芯片设计一个 4K×8bit 的存储器。
答:第一步:合理选择存储芯片,这种情况下,需要 4K×8/(4K×2) = 4 个 DRAM 芯片。CPU 拥有 12 根地址线(2¹² = 4K),8 根数据线。而 DRAM 芯片拥有 12 根地址线和 2 根数据线。在连接时如图 3.16 所示:
第二步:地址线的连接,4 个 DRAM 芯片的 12 根地址线引脚 A₀ ~ A₁₁ 按编号的不同分别合并在一起,与 CPU 的 A₀ ~ A₁₁ 分别相接。
第三步:数据线的连接,4 个 DRAM 芯片的一共 8 个数据线引脚独立地与 D₀ ~ D₇ 相接。
第四步:读写控制线的连接,4 个 DRAM 芯片的片选信号 CS 分别并联在一起,与 CPU 的 CS 相接。读写信号 WE 分别并联在一起,与 CPU 的 WE 相接。
第五步:片选线的连接,本例无需连接片选线。3.字拓展
字拓展是指仅在字数方向上拓展(加大地址空间的大小),而不加大存储单元的字长。在字拓展中,各存储芯片的数据线、地址线、片选线和读写线相应地并联起来,由片选线区分芯片。
【例 3 - 3】用 4K×8bit 的 DRAM 芯片设计一个 16K×8bit 的存储器。
答:第一步:合理选择存储芯片,这种情况下,需要 16K×8/(4K×8) = 4 个 DRAM 芯片。CPU 拥有 14 根地址线(2¹⁴ = 16K),8 根数据线。而 DRAM 芯片拥有 12 根地址线和 8 根数据线。在连接时如图 3.17 所示:
第二步:地址线的连接,4 个 DRAM 芯片的 12 根地址线引脚 A₀ ~ A₁₁ 按编号分别并联在一起,与 CPU 的 A₀ ~ A₁₁ 分别相接。
第三步:数据线的连接,4 个 DRAM 芯片的 8 根数据线引脚 D₀ ~ D₇ 按编号分别并联在一起,与 CPU 的 D₀ ~ D₇ 分别相接。
第四步:读写控制线的连接,4 个 DRAM 芯片的读写信号 WE 分别并联在一起,与 CPU 的 WE 相接。
第五步:片选线的连接,CPU 的 A₁₃,A₁₂ 与一个 2 - 4 译码器的输入端相接。地址译码器的 4 个输出端分别与 4 个 DRAM 芯片的 CS 端相接。A₁₃ = 0,A₁₂ = 0 时,选择第 0 片 DRAM 芯片;A₁₃ = 0,A₁₂ = 1 时,选择第 1 片;A₁₃ = 1,A₁₂ = 0 时,选择第 2 片;A₁₃ = 1,A₁₂ = 1 时,选择第 3 片。
提示:片选过程可由译码器来实现,其可将 n 个输入变为 2ⁿ 个输出。可以注意到片选信号的四个取值 00、01、10、11 分别对应十进制的 0、1、2、3,与被选择的 DRAM 芯片的编号等同。如译码器左端信号为 10,右端就仅有 2 号端口会输出 1,代表选中的是 2 号芯片。在同一时间内 4 个芯片中只能有一个芯片被选中。4 个芯片的地址分配如下:
可见,地址低 12 位决定了片内地址,更高的 2 位决定了选择哪片 DRAM 芯片。4.字位拓展
现实中可能既要位拓展又要字拓展,即同时增加单个存储单元大小和存储芯片的地址空间大小。
【例 3 - 4】用 4K×4bit 的 DRAM 芯片设计一个 16K×8bit 的存储器。答:第一步:合理选择存储芯片,这种情况下,需要 16K×8/(4K×4)=8 个 DRAM 芯片。CPU 拥有 14 根地址线(2^14=16K),8 根数据线。而 DRAM 芯片拥有 12 根地址线和 4 根数据线。在连接时如图 3.18 所示:
第二步:地址线的连接,8 个 DRAM 芯片的 12 根地址线引脚 A0~A11 按编号分别并联在一起,与 CPU 的 A0~A11 分别相接。
第三步:数据线的连接,8 个 DRAM 芯片分为 4 组,每组 2 个 DRAM 芯片。每组的一个 DRAM 芯片的 4 根数据线引脚连接 D3~D7,另一个的 4 根数据线引脚连接 D4~D7。
第四步:读写控制线的连接,8 个 DRAM 芯片的读写信号 WE 分为 4 组并联在一起,与 CPU 的 WE 相接,每次会有一组信号选通(即选中 8 位数据)。
第五步:片选线的连接,CPU 的 A13,A12 与一个 2 - 4 译码器的输入端相接。地址译码器的 4 个输出端与 4 组 DRAM 芯片的 CS 端分别相接。A13=0,A12=0 时,选择第 0 组的两个 DRAM 芯片;A13=0,A12=1 时,选择第 1 组的两个 DRAM 芯片;A13=1,A12=0 时,选择第 2 组的两个 DRAM 芯片;A13=1,A12=1 时,选择第 3 组的两个 DRAM 芯片。
在同一时间内 4 组芯片中只能有一组芯片被选中。4 组芯片的地址分配如下:
可见,地址低 12 位决定了片内地址,更高的 2 位决定了选择哪组 DRAM 芯片。
5.地址分配与片选
CPU 在访存时需要经历片选(选定具体的 DRAM 芯片)和字选(在选定的 DRAM 芯片中找到具体的片内地址)的过程。其中字选比较简单:如果 DRAM 芯片的存储单元数为 2N 个,则传入的地址的低 N 位即为片内地址。而片选则有两种不同的办法:线选法和译码片选法。
(1) 线选法
线选法中,除去用于字选的低位后,得到的高位用于片选。其中第 i 位为 0,其余位为 1 时,选定第 i 位为目标存储芯片。
假设 1 个主存由 4 个 4K×8bit 的 DRAM 字拓展而成。那么在线选法中,地址的低 12 位(A11~A0)用于字选。高 4 位用于片选,其中 A15A14A13A12=1110 时,选定第 0 片;A15A14A13A12=1101 时,选定第 1 片。如此类推。
线选法无需译码器,但是这样生成的地址空间不连续,构成了一定程度的浪费。
提示:此处线选法是为了片选,译码驱动处的线选法是为了将地址信号翻译成选择信号。
(2) 译码片选法
译码片选法中,除去用于字选的低位后,得到的高位用于片选。将高位的若干位信号视作二进制数,并换算得到要访问的目标存储芯片的编号。
假设 1 个主存由 4 个 4K×8bit 的 DRAM 字拓展而成。那么在线选法中,地址的低 12 位(A11~A0)用于字选。高 log24=2 位用于片选,其中 A13A12=00 时,选定第 0 片;A13A12=01 时,选定第 1 片;A13A12=10 时,选定第 2 片;A13A12=11 时,选定第 3 片。可以注意到 00、01、10、11 如果视作二进制数,则恰好可换算成十进制下的 0、1、2、3。
译码片选法需要译码器,但是充分利用了地址空间。3.4.3 多模块存储器
由于 CPU 和主存所使用的半导体器件工艺不同,两者在速度上存在着极大的差异,需要尽可能提升主存的读写速度,从而提升两者间数据传输的效率。多模块存储器就是一种硬件上提高主存读写速度的改进方案。
多模块存储器是一种空间并行技术,根据不同的编址方式,多模块存储器分为连续编址和交叉编址两种结构。单体多字存储器是连续编址的多模块存储器,多体并行存储器是交叉编址的多模块存储器。1. 单体多字存储器
如下图所示,单体多字存储器中,每个存储单元存储多个字。当数据读出时将一个存储单元的所有 m 个字同时读出,因而也就要求单体多字存储器的数据线宽度为 m 个字。因为一个存储周期内读出的数据为原来的 m 倍,相当于单字的存储周期被压缩到了原来的 1/m 倍。当指令与数据连续存放,且不能有过多的跳转指令时,单体多字存储器才能有效地提高主存的读写速度,否则该方法的提升效果不明显。
2. 多体并行存储器
多体并行存储器里拥有多个模块,每个模块拥有相同的容量与速度,且每一个模块拥有自己的存储体、地址寄存器 MAR、数据寄存器 MDR、译码驱动、读写电路和控制电路(其实就是单个主存芯片应拥有的所有部件)。每个模块都是一个独立的存储器。多体并行存储器又分为高位交叉存储器和低位交叉存储器。
(1) 高位交叉存储器
高位交叉编址的多模块主存储器中,主存地址的高位确定选定哪一模块,低位选定模块内的内部地址,地址在模块内连续。这种编址方式也因此被称为连续编址方式。以图 3.19 为例,存储器共有 4 个模块 M0~M3(图中有 4 个模块不代表高位交叉存储器的模块数都是 4),若每个模块有 m 个单元,则 M0 的地址范围为 0~m-1,M1 的地址范围为 m~2m-1,M2 的地址范围为 2m~3m-1,M3 的地址范围为 3m~4m-1。如果 m 的大小等于 2 的 k 次方,那么访问地址的低 k 位决定了模块内地址,剩下的高位决定了选定哪个模块。因为高位决定了要访问哪个模块,所以得名 “高位交叉存储器”。
如图 3.19 所示,假设访问地址为 0,1,2,3 的这 4 个存储单元,则访问过程中都将访问 M0,但 M0 只有一个读写控制电路,导致 4 次访问必须串行地访问(即时间上先后地顺次一个一个访问),而其他模块(M1~M3)并没有在此过程中发挥作用,因而并没有提升主存的读写速度。对于高位交叉编址的多模块主存储器,各存储模块不能并行工作,当一个模块全部访问完才能访问下一个模块。
(2) 低位交叉存储器
低位交叉编址的多模块主存储器中,主存地址的低位确定选定哪一模块,高位选定模块的内部地址。因为低位决定了要访问哪个模块,所以得名 “低位交叉存储器”,有时也将这种编址方式直接称为交叉编址方式。对于拥有 m 个模块的低位交叉存储器而言,如果访问地址为 i 的存储单元,那么该存储单元位于第 i%m 个模块。如果 m 的大小等于 2 的 k 次方,那么访问地址的二进制表示的低 k 位决定了选定哪一模块,剩下的高位决定了模块内地址。如图 3.20 所示为一个模块数 m=4=2^2 的低位交叉存储器,现访问地址 1011B,那么根据低 2 位的 11(二进制的 11 等于十进制的 3)即可确定该访问第 3 号模块(M3,第 4 个模块)。如图 3.20 所示,假设对这个 m = 4 的低位交叉存储器访问地址为 0,1,2,3 的这 4 个存储单元,则访问过程中刚好分别访问 M₀、M₁、M₂、M₃ 。若每个模块一次读写的位数等于存储器总线的数据位数,则以一个总线传送周期 r 为时间间隔按流水线式的顺次访问,这种访问方式称为轮流启动。访问流程如图 3.21 所示。
提示:总线传送周期通常指的是 CPU 完成一次访问主存或 I/O 端口操作所需要的时间,总线传送的具体内容会在第 6 章讲述。
对于低位交叉存储器而言,假设需要顺序地访问一段主存地址。为了能让流水线式的访存过程正常的持续下去,模块数 m、总线传送周期 r,存储周期 T 必须满足 m ≥ T/r。否则会如图 3.22 这样,在模块数为 3 时不满足 m 的最低要求,因为同一时刻单个模块无法同时进行两次访存过程而冲突,导致无法彻底流水线化地访存。
同样是顺序地访问一段字数为 n 的主存空间,高位交叉存储器或者一般的主存储器因为此时只能串行访问,所以每个字的访问时间需要 1 个存储周期 T,即总时间等于 nT;而低位交叉存储器因为面对这种情形,能够流水线化地访存。所以第 1 个字访问需要等待一个存储周期 T,然后每等待一个总线传送周期 r 就能送下一个字,所以总时间等于 T+(n - 1) r。
低位交叉存储器可能遇到冲突的问题。比如一个模块数 m = 4 的低位交叉存储器,假设连续先后访问 1 号地址和 5 号地址,因为它们都位于 1 % 4 = 5 % 4 = 1 号模块中,而且两次访存是相邻的,所以会发生冲突,只能等待 1 号地址访问结束再访问 5 号地址。一段访存的过程中某两次访存会发生冲突的条件是:这两次访存过程将访问相同的模块且两次访问间进行了不到 [T/r - 1] 个访存过程。
【例 3-5】某计算机存储器总线宽度为 8 位,主存采用 8 体低位交叉存储模式,工作时 1/8 个存储周期启动一个体。若每个体的存储字长为 8 位,存储周期为 200ns,则该主存能提供的最大带宽是多少?
答:由于 8 体低位交叉存储每 1/8 个存储周期启动一个体,合起来刚好一个存储周期,所以当带宽最大时,8 体低位交叉存储能彻底流水线化。存储器总线宽度为 8 位即 1B,则每次从主存读出的数据为 1B,一个周期能读 8 个存储体,所以主存能提供的最大带宽为 (1B×8)/200ns = 40MBps。
如果存储器总线的数据位数等于所有存储模块一次并行读写的总位数,那么可以使用同时启动的访问方式。对于例 3 - 5,如果总线宽度改为 64 位,而 8 个存储体一共可以提供 64 位的数据,正好构成了一个总线传输单位,则可以同时启动 8 个体进行并行读写,即同时读写 64 位数据。3.4.4 内存条和内存条插槽
受材料和技术的原因,一个芯片的容量有限,通常将多个存储器芯片扩展到一个主存模块上,即我们生活中常见的内存条。
内存条插槽即存储器总线。内存条存储的信息通过其引脚和内存条插槽连接到主板,再连接到北桥芯片或者 CPU 芯片。为了加快访存速度,通常有多条存储器总线同时传输数据。我们常见的有双通道内存插槽,支持两条总线同时传输数据,其传输带宽也是单通道的两倍。此外,还有三通道、四通道的内存插槽,其总线传输带宽能够分别提高到单通道的 3 倍和 4 倍。一般使用相同颜色的内存条插槽即可实现多通道。若一计算机上有两个绿色和两个黄色的插槽,当要插入两条内存条时,若插入两个同色槽,即可实现双通道使得传输带宽大一倍;否则,就不会增大传输带宽。3.4.5 习题精编
1.某计算机的主存容量大小为 128KB。
(1) 若按字节编址,则 MAR 和 MDR 的位数分别是( )。
(2) 若按字编址,1 字 = 2 字节,则 MAR 和 MDR 的位数分别是( )。
A. 17,8,16,16 B. 16,16,16,16 C. 16,8,17,8, D. 17,16,16,81.【参考答案】A
【解析】(1) 按字节编址,128KB = 128K×8 位,128K = 2¹⁷,即地址线有 17 条,MAR 是 17 位;按字节编址,字节为 8 位,即数据线有 8 条,MDR 是 8 位。
(2) 按字编址,128KB = 64K×16 位,64K = 2¹⁶,即地址线有 16 条,MAR 是 16 位;按字编址,一个字包含两个字节,共 16 位,即数据线有 16 条,MDR 是 16 位。2.已知计算机主存由 RAM 和 ROM 共同构成,两者统一编址。某计算机的物理地址为 20 位,按字节编址,ROM 区的地址为 00000H - 0BFFFH,其余空间均使用 8K×8 位的 RAM 芯片填充,则需要( )个这样的 RAM 芯片。
A. 61 B. 62 C. 122 D. 1232.【参考答案】C
【解析】RAM 区为 0C000H 到 FFFFFH,空间大小为 FFFFFH - 0C000H + 1H = F4000H,即 RAM 区的寻址空间大小为 15×16⁴ + 4×16³ = 61×2¹⁴,所需芯片的个数为 61×2¹⁴/8K = 122。3.假设某 CPU 上的地址引脚数为 24,数据引脚数为 32。若用 256K×16 位的 RAM 芯片组成该机的主存储器,则最多需要( )片这样的存储芯片。
A. 64 B. 128 C. 256 D. 5123.【参考答案】B
【解析】地址引脚数为 24,数据引脚数为 32,即为 2²⁴×32 位,需要 (2²⁴×32)/(256K×16) = 128 个 256K×16 位的芯片。4.若内存地址 A000H - B7FFH 的区间用 6 块 RAM 构成,已知存储字长为 16 位且按字节编址,则可以使用的 RAM 芯片规格为( )。
A. 512×32 位 B. 2048×16 位 C. 2048×8 位 D. 512×16 位4.【参考答案】C
【解析】内存地址大小 B7FFH - A000H + 1H = 1800H = 6K,已知存储字长 16 位,A 为 32 位,故 A 排除;按字节编址,即有 6K×2B = 12KB 的空间,12KB/6 = 2KB = 2K×8 位 = 1K×16 位,故该内存由 6 片 2048×8 位组成。5.假设某 32K×32 位的存储器由若干 4K×8 位的芯片组成,以地址总线的高位作为片选,则加在各存储芯片上的片选线是( )。
A. A14 - A0 B. A11 - A0 C. A14 - A12 D. A14 - A115.【参考答案】C
【解析】32K = 2¹⁵,即地址线 15 位,A14 到 A0。4K = 2¹²,即地址线 12 位,A11 到 A0,所以低 12 位 A11 - A0 是加在各存储芯片上的地址线,剩下的高 3 位 A14 - A12 是作为片选线。6.假设一个 64K×8 位的存储器,由若干个 8K×8 位的存储芯片组成。若芯片内各单元连续编址,则地址 BA3DH 所在芯片的最小地址为( )。
A. A000H B. B000H C. 0000H D. 000DH6.【参考答案】A
【解析】BA3DH 即 1011 1010 0011 1101,64K/8K = 2³,即地址的高 3 位 101 为片选线,最小地址即剩下的低 13 位全 0,为 1010 0000 0000 0000 即 A000H。7.当片选信号为 110 的时候,存储器内的一个 8K×8 位的存储芯片被选定,则该芯片在存储器中的首末地址为( )。
A. D000H,DFFFH B. 0000H,1FFFH C. C000H,DFFFH D. 0000H,FFFFH7.【参考答案】C
【解析】8K = 2¹³,地址线低位共 13 位,已知片选号 110 为 3 位,所以共 16 位。首地址低 13 位全 0 为 1100 0000 0000 0000 即 C000H,末地址低 13 位全 1 为 1101 1111 1111 1111 即 DFFFH。8.某容量为 128KB 的存储器由若干 8K×8 位的芯片扩展而成,若其存储字长为 16 位且内存按字编址,则地址 BC2FH 所在芯片的首地址为( )。
A. 8000H B. B000H C. A000H D. F000H8.【参考答案】C
【解析】存储字长为 16 位且内存按字编址,即 128KB = 64K×16bit,64K = 2¹⁶,即地址为 16 位。8K = 2¹³,即 13 位。高 16 - 13 = 3 位片选线。BC2FH = 1011 1100 0010 1111 前三位 101 是片选线,故首地址为 1010 0000 0000 0000 即 A000H。9.一个容量为 128KB 的 SRAM 芯片按字长 32 位编址,其地址范围可从 0000H 到( )。
A. 3FFFH B. 7FFFH C. 7FFFFH D. 3FFFFH9.【参考答案】B
【解析】128KB = 2¹⁷⁺³bit,按字编址且字长 32bit,故需要 128KB/32bit = 2²⁰⁻⁵个地址单元,所以最大地址为 2¹⁵ - 1 = 7FFFH。10.关于单体多字存储器,以下选项中不正确的是( )。
A. 单体多字存储器主要解决主存容量太小的问题
B. 单体多字存储器中,每个存储单元存储多个字
C. 指令与数据的连续存放有利于单体多字存储器提高主存的读写速度
D. 过多的跳转指令会严重影响单体多字存储器的工作效率10.【参考答案】A
【解析】A 选项单体多字存储器主要解决访存速度的问题,并没有解决主存容量太小的问题。单体多字存储器中,每个存储单元不止存储 1 个字,而是存储多个字,B 对;当指令与数据连续存放,且没有过多的跳转指令时,单体多字存储器能有效地提高主存的读写速度,C、D 对。11.关于存储系统,以下选项中正确的是( )。
A. 信息按边界存储的含义是存储单元的地址必须是整数
B. 单体多字存储器是交叉编址的多模块存储器
C. 在交叉编址的多模块存储器中,当连续的 n 次访存操作作用于不同的存储体时,该存储器的存取带宽是单体存储器的 n 倍
D. 可以采用增加 Cache 容量的方法提高存储系统的存储容量11.【参考答案】C
【解析】A 选项信息按边界存储的含义是存储单元的地址必须是存储字长的整数倍;B 选项单体多字存储器是连续编址的多模块存储器;D 选项 Cache 存的只是主存内容的副本,不算入总存储量大小。C 选项为正确描述,在完全流水线情况下,可以在一个周期内访问所有存储体。12.关于多模块存储器,以下选项中正确的是( )。
A. 高位交叉存储器有效的利用了程序的局部性原理
B. 多体并行存储器里拥有多个模块,每个模块都有自己的读写控制电路
C. 高位交叉存储器是连续编址的多模块存储器,无法提高存取效率
D. 低位 n 体交叉存储器的存取效率一定是单体存储器的 n 倍12.【参考答案】B
【解析】A 选项高位交叉存储器没有利用局部性原理;C 选项高位交叉存储器是交叉编址的多模块存储器,其无法提高存储效率的原因是没有遵循局部性原理;D 选项低位 n 体交叉存储器的存取效率不一定是单体存储器的 n 倍,只有在完全流水线情况下才是 n 倍;B 选项为正确描述,每个模块都有自己的读写控制电路。13.某低位交叉存储器有 4 个模块,存储周期为 200ns,存储字长为 16 位,按字编址,其每个体的容量是 64K×16 位。若总线传输周期为 50ns,该存诸器读取的平均速度为( )。
A. 2×10⁸bit/s B. 3.2×10⁸bit/s C. 2×10⁷bit/s D. 3.2×10⁷bit/s13.【参考答案】B
【解析】每个体的容量是 64K×16 位且存储字长为 16 位,在流水线情况下,无论连续多少个字平均速度都是一样的,即一个传输周期就可以传输一个模块,速度为 16bit/50ns = 3.2×10⁸bit/s。14.一个八体低位交叉存储器,每个存储体的容量为 256M×64 位,若每个体的存储周期为 80ns,那么该存储器能提供的最大带宽是( )。
A. 426.67MB/S B. 800MB/S C. 213.33MB/S D. 400MB/S14.【参考答案】B
【解析】八体低位交叉存储器最大带宽时即完全流水线化,一个周期可访问 8 个存储体。每个存储体的容量为 256M×64 位,一个存储体一次传输 64 位数据即 8B,带宽为 8B×8/80ns = 800MB/s。15.采用四体并行低位交叉存储器,设每个体的存储容量为 32K×16 位,存取周期为 400ns,在下述说法中( )是正确的。
A. 在 0.1μs 内,存储器可向 CPU 提供 64 位二进制信息
B. 在 0.1μs 内,每个体可向 CPU 提供 16 位二进制信息
C. 在 0.4μs 内,存储器可向 CPU 提供 64 位二进制信息
D. 在 0.4μs 内,每个体可向 CPU 提供 32 位二进制信息15.【参考答案】C
【解析】由于是四体并行低位交叉编址,所以可采用流水线方式,一个存取周期内依次对四个存储器进行存取,由于存储容量为 32K×16 位,所以总线带宽为 16 位,每次传送 16 位二进制信息。因此当连续存取时,每过 100ns,存储器中的一个体就可传送 16 位二进制信息,400ns 就可传送 64 位二进制信息,而非每个体都在 100ns 内传送 16 位二进制,B 错 C 对。16.下列有关存储器的描述中,正确答案是( )。
A. Cache 的功能由硬件实现
B. 访问外存储器的请求是由 CPU 发出的
C. Cache 与主存统一编址,即主存空间的某一部分属于 Cache
D. 多体交叉存储主要解决扩充容量的问题16.【参考答案】A
【解析】访问内存储器的请求是由 CPU 发出的。而访问外存储器的请求通常由操作系统或其他硬件设备(如 DMA 控制器)发出。由于外存储器速率与 CPU 不匹配,所以 CPU 不能直接访问外存,而是先将外存储器数据调入内存再访问,B 选项错误;Cache 内存储的是主存空间部分内容的副本,不算入主存空间,C 选项错误;低位交叉编址的目的是提高单次访存速度,高位交叉编址在两模块能独立并行工作时也能提高访存速度,D 选项错误。17.设 CPU 共有 12 根地址线,8 根数据线。可用存储芯片有:2K×8 位的 ROM,4K×4 位的 ROM,512×8 位的 RAM。现将主存地址空间的 000H - 7FFH 划为系统程序区,800H - FFFH 划为用户程序区。请回答以下问题:
(1) 系统程序区需要选用什么芯片?用户程序区需要选用什么芯片?各需要多少个?
(2) 写出每个芯片所能表示的主存地址范围。17.【参考答案】
(1) 系统程序区选 ROM,空间大小为 2K×8 位,需要 1 个 2K×8 位的 ROM(4K×4 位 ROM 超过空间大小)。用户程序区选 RAM,空间大小为 2K×8 位,需要 4×1 个 512×8 位的 RAM。
(2) 2K×8 位 ROM:0000 0000 0000 ~ 0111 1111 1111
512×8 位 RAM:1000 0000 0000 ~ 1001 1111 1111
512×8 位 RAM:1010 0000 0000 ~ 1011 1111 1111
512×8 位 RAM:1100 0000 0000 ~ 1101 1111 1111
512×8 位 RAM:1110 0000 0000 ~ 1111 1111 111118.某 32 位计算机,CPU 地址总线 36 位,数据总线 32 位,存储器按字编址。请回答下列问题:
(1) 该机最大主存容量为多少字节?
(2) CPU 中的 MAR 和 MDR 分别为多少位?
(3) 现有若干个 1M×4 位的 DRAM 芯片,用于形成该机 512 M×32 位的 RAM 存储区域,共需要多少片 DRAM 芯片?18.【参考答案】
(1) 最大容量即为数据线和地址线能满足多大容量,数据线 32 位 = 4B,地址线 36 位即寻址单元有 2³⁶个,故容量 2³⁶×4B = 256GB。
(2) MAR 存放地址,已知地址线 36 位,故 MAR 有 36 位;MDR 存放数据,已知数据线 32 位,故 MDR 有 32 位。
(3) 芯片数量 = (512M×32 位)/(1M×4 位) = 4096 片。19.用若干 8K×8 位的 RAM 设计 8 位字长,容量 32K×8 位的 RAM,说明设计思路并画出电路图。
19.【参考答案】第一步:选择存储芯片,8K×8 位的 RAM 组成 32K×8 位的 RAM,需要字拓展,需要 32K/8K = 4 个芯片,
第二步:连接地址线,4 个 RAM 芯片的 log₂8K = 13 根地址线引脚 A₀ ~ A₁₂按编号分别并联在一起,与 CPU 的 A₀ ~ A₁₂分别相接。
第三步:连接数据线,4 个 RAM 芯片的 8 根数据线引脚 D₀ ~ D₇按编号分别并联在一起,与 CPU 的 D₀ ~ D₇分别相接。
第四步:连接读写控制线,4 个 RAM 芯片的读写信号 WE 一起并联与 CPU 的 WE 相接。
第五步:片选线的连接,CPU 的 A₁₄,A₁₃与一个 2 - 4 译码器的输入端相接。地址译码器的 4 个输出端与 4 个 DRAM 芯片的 CS 端分别相接。A₁₄ = 0,A₁₃ = 0 时,选择第 0 片 DRAM 芯片;A₁₄ = 0,A₁₃ = 1 时,选择第 1 片;A₁₄ = 1,A₁₃ = 0 时,选择第 2 片;A₁₄ = 1,A₁₃ = 1 时,选择第 3 片。电路图如下所示:
20.在低位四体交叉存储器中,某段时间内,CPU 访问地址序列依次为(均为十进制):14,13,27,2,16,48,15,30,22,13,12,8,3。请问在访问哪些地址时会发生体冲突?
20.【参考答案】对于拥有 m 个模块的低位交叉存储器而言,如果访问地址为 i 的存储单元,那么该存储单元位于第 i% m 个模块。得出此地址序列的体号依次为:2,1,3,2,0,0,3,2,2,1,0,0,3。在临近 4 的次序列中访问同一个模块即为冲突,故访问 2,48,22,8 时发生冲突。
21.在 32 位计算机中有一个八模块存储器中,每个的模块按字编址,存取周期为 200ns。数据总线一次传输一个字,且传输周期为 25ns。当存储器采用高位交叉方式和低位交叉方式时,读取前八个字的带宽分别是多少?
21.【参考答案】高位交叉方式:八个模块一轮可以传输 32bit×8 = 32B。高位交叉循环一遍需要 200ns×8 = 1600ns,带宽 32B/1600ns = 2×10⁷B/s。
低位交叉方式:循环一遍即前八个字,需要 200ns + 7×25ns = 375ns,带宽 32B/375ns = 8.5×10⁷B/s。3.4.6 真题演练
22.【2009】某计算机主存容量为 64KB,其中 ROM 区为 4KB,其余为 RAM 区,按字节编址。现要用 2K×8 位的 ROM 芯片和 4K×4 位的 RAM 芯片来设计该存储器,则需要上述规格的 ROM 芯片数和 RAM 芯片数分别是( )。
A. 1,15 B. 2,15 C. 1,30 D. 2,3022.【参考答案】D
【解析】本题考查了主存储器芯片的拓展,64KB 的空间中 ROM 区占用了 4KB,那么剩下的 64 - 4 = 60KB 就是 RAM 区。然后利用公式:芯片数 = 总容量 /(单个芯片容量)。分别计算得需要 (4KB)/(2KB) = 2 个 ROM 芯片以及 (60KB)/(4K×4b) = 30 个 RAM 芯片。23.【2010】假定用若干 2K×4 位的芯片组成一个 8K×8 位的存储器,则地址 0B1FH 所在芯片的最小地址是( )。
A. 0000H B. 0600H C. 0700H D. 0800H23.【参考答案】D
【解析】因为 DRAM 芯片的位数字数都不符合要求,因此需要字位拓展,8 个 2K×4bit 的 DRAM 芯片先两两组合,组合成 4 组,每组容量为 2K×8bit,然后采取译码片选法,可知地址空间的低 log₂2048 = 11 位为片内地址,相邻的高 log₂4 = 2 位确定了组选信号,0B1FH = 0000 1011 0001 1111B,其中组选信号为 01B,故 0B1FH 所在组的地址空间为 0000 1000 0000 0000B 到 0000 1111 1111 1111B 之间,故本组最小地址为 0000 1000 0000 0000B,即 0800H。24.【2011】某计算机存储器按字节编址,主存地址空间大小为 64MB,现用 4M×8 位的 RAM 芯片组成 32MB 的主存储器,则存储器地址寄存器 MAR 的位数至少是( )。
A. 22 位 B. 23 位 C. 25 位 D. 26 位24.【参考答案】D
【解析】MAR 的位数与物理内存的大小无关,只与地址空间的大小有关,需要能存放所有的地址。故 MAR 的位数为 log₂(64×2²⁰) = 26bit。25.【2015】某计算机使用 4 体交叉编址存储器,假定存储器总线上出现的主存地址(十进制)序列为 8005,8006,8007,8008,8001,8002,8003,8004,8000,可能发生访存冲突的地址对是( )。
A. 8004 和 8008 B. 8002 和 8007 C. 8001 和 8008 D. 8000 和 800425.【参考答案】D
【解析】体号 = 地址 %4(模块数),得出访问次序如下表所示
在访问 8004 之前,均可无冲突的访问四个模块,且一共花费 3 个周期。8004 后访问 8000,两者相邻且都在 0 号模块中,故发生冲突,8000 需在周期 T + 3 时再去 0 号模块访问。
26.【2016】某存储器容量为 64KB,按字节编址,地址 4000H~5FFFH 为 ROM 区,其余为 RAM 区。若采用 8K×4 位的 SRAM 芯片进行设计,则需要该芯片的数量是( )。
A. 7 B. 8 C. 14 D. 1626.【参考答案】C
【解析】地址范围共 5FFFH - 4000H + 1 = 2000H,即 2¹³ = 8KB。所以 ROM 区大小为 8KB,RAM 区大小为 64 - 8 = 56KB。所以需要的 SRAM 芯片数为 56KB/(8K×4bit) = 14 个。27.【2017】某计算机主存按字节编址,由 4 个 64M×8 位的 DRAM 芯片采用交叉编址方式构成,并与宽度为 32 位的存储器总线相连,主存每次最多读写 32 位数据。若 double 型变量 x 的主存地址为 804 001AH,则读取 x 需要的存储周期是( )。
A. 1 B. 2 C. 3 D. 427.【参考答案】C
【解析】一个 double 型变量占用 8 字节,4 个 DRAM 芯片采取低位交叉存储,则低 log₂4 = 2 位确定了 DRAM 的块号,804 001AH 的低 2 位为 10,则这 8 个存储地址低 2 位为 10,11,00,01,10,11,00,01。由于存储器总线宽度等于 4 个 DRAM 芯片一次并行读写的总位数,所以采用同时启动的访问方式,其中前 2 个,中 4 个,后 2 个分别为一轮访存周期,故需要 3 轮访存周期。
28.【2021】某计算机的存储器总线中有 24 位地址线和 32 位数据线,按字编址,字长为 32 位。如果 00 0000H~3F FFFF H 为 RAM 区,那么需要 512K×8 位的 RAM 芯片数为( )。
A. 8 B. 16 C. 32 D. 6428.【参考答案】C
【解析】3FFFFFH - 000000H + 1H = 400000H = 2²²B,按字编址,故总大小为 2²²×4B。而单个 DRAM 芯片大小为 2¹⁹B。所以总共需要 2²²×4B/(2¹⁹B) = 32 片。3.5 外存储器
外存储器是指主存以外的存储装置,又称为辅助存储器(辅存)。在存储器的层次化结构中,外存储器位于主存储器的下一层,且 CPU 无法直接访问外存储器,需要通过主存实现对外存的读写。常见外存储器有硬盘存储器、磁盘阵列、光盘存储器等。本节重点介绍磁盘、光盘和固态硬盘。
3.5.1 磁盘存储器
简称磁盘。磁盘是计算机重要的存储介质,可以存储大量的二进制数据。早期计算机使用的磁盘是软磁盘(Floppy Disk,简称软盘),如今常用的磁盘是硬磁盘(Hard disk,简称硬盘)。磁盘具有存储量大、价格低廉、断电后数据依旧能够保留、读出为非破坏性读出等优点,但同时具有速度慢、对工作环境要求较高、机械结构复杂等缺点。
1.磁盘存储器的结构与存储原理
磁盘存储器的结构包括磁盘控制器、磁盘驱动器和盘片。其数据交互关系如图 3.23 所示。
(1)磁盘控制器
磁盘控制器是 CPU(通过总线连接)与磁盘驱动器之间的接口。负责接收 CPU 发来的命令,将其转换成磁盘驱动器的控制命令(读或写),并实现 CPU 和驱动器之间的数据格式转换。
(2)磁盘驱动器
负责接收磁盘控制器的控制命令,并控制磁头组件和盘片组件进行读写操作。
(3)盘片
由硬质铝合金材料制成。如图3.24所示,一个硬盘存储器拥有一个或多个盘片,磁介质均匀分布在一些同心圆上,每个同心圆形成一个盘面的磁道。相邻磁道间的物理距离称为道距。为了方便地查找数据在磁道中的位置,同时还按照相对圆心的角度把每张磁盘分成很多扇区。通常每个磁道拥有数量相同的扇区,每个扇区存放存储容量相同的数据块。此外,不同盘片上半径同为一个特定值的所有磁道构成一个柱面。
提示:从靠近圆心到远离圆心,每个磁道的物理长度越来越长,但是每个磁道存储的数据量相同,所以磁道的位密度(单位长度所能存储的数据大小)逐渐变小。
磁盘的读写原理:磁头和磁性记录介质相对运动时,通过电磁转换完成读 / 写操作。2.磁盘存储器的性能指标
(1)存储密度
指单位长度或单位面积磁层表面所存储的二进制的信息量。对于磁表面存储器,常用道密度和位密度表示。单个磁盘的道距为定值。
道密度(TPI):磁盘半径方向单位长度包含的磁道数。
位密度(BPI):单位长度所能存储的数据大小。
2.下列选项中,可以提高磁盘的存储容量的是 ( )。
A. 加快磁盘转速
B. 提高磁头移动速度
C. 增加磁盘 Cache
D. 增加位密度2.【参考答案】D
【解析】 加快磁盘转速与提高磁头移动速度可以提高磁盘运行效率,不能增加磁盘存储容量,A、B 选项错误;磁盘 Cache 为在主存中开辟的一个缓冲空间,解决主存与磁盘工作速度不匹配的问题,实际上存储的是磁盘中数据的副本,并不能增加磁盘存储容量,C 选项错误;位密度为单位长度上能存储的二进制信息数量,增加位密度即可增加单位长度上的存储信息数量,即增加磁盘的存储容量,D 选项正确。拓展:如前所述,随着磁道半径大小的增大,位密度逐渐下降。而因为每个磁道的存储容量大小相同,所以道密度随着磁道半径大小的增大而不变。
(2)存储容量
指磁盘存储器所能存储的二进制信息总量,有格式化容量和非格式化容量两个指标。
格式化容量:指按照某种特定的记录格式所能存储的信息总量,也就是用户真正可以使用的容量。
非格式化容量:是磁记录表面可以利用的磁化单元总数。
格式化容量 = 面数 × 道数(每面)× 扇区数(每道)× 字节数(每扇区)
非格式化容量 = 面数 × 道数(每面)× 每个磁道的容量格式化容量为用户真实可用的容量,非格式化容量为磁表面所有可利用的空间,因此格式化容量小于非格式化容量。
4.假设某磁盘具有 16 个盘片和 8192 个柱面,每磁道有 512 个扇区,每个扇区有 512 字节,则该磁盘的总容量为 ( )。
A. 32MB
B. 32GB
C. 16MB
D. 16GB4.【参考答案】B
【解析】 8192 个柱面即 8192 个磁道,16 个盘片 ×8192 个磁道 / 盘面 ×512 个扇区 / 磁道 ×512 字节 / 扇区 = 32GB。(3)磁盘存取时间
寻道时间:把读写磁头移动到目标磁道上所需的时间。
1.磁盘转速提高一倍,则 ( )。
A. 寻道时间缩小一半
B. 存取速度也提高一倍
C. 平均查找时间缩小一倍
D. 不影响磁盘传输速率1.【参考答案】C
【解析】 磁盘存取的步骤为:启动磁头 + 寻道、旋转延迟 (查找时间)、传输数据,转速提高一倍则寻道时间不变,A 错误;存取速度需要看所有步骤的时间,虽然会提高,但不会提高一倍,B 错误;平均查找 (旋转延迟) 为旋转半圈的时间,因此时间也会相应缩小一倍,C 正确;转速提高则传输速率也会提高,D 错误。平均寻道时间:所有寻道时间的平均值。
等待时间(旋转延迟):磁头等待所需读写的区段旋转到它的下方所需要的时间。
平均等待时间:一般以磁盘旋转半周所需的时间为准。
平均寻址时间 = 平均寻道时间 + 平均等待时间
平均存取时间 = 平均寻址时间 + 数据传输时间(4)数据传输率
磁表面存储器在单位时间内与主机传送数据的位数或字节数。计算公式为:
Dr=n×N
其中:n 为转速,单位为转 / 秒;N 为磁道的容量,单位为字节 / 磁道。Dr单位为:字节 / 秒。一转等价于一个刺刀,即r等价于转,每个磁道有n个扇区,即n/磁道=n/r
7.假定某一磁盘的转速为 6000RPM(转 / 分),平均寻道时间为 5ms,平均数据传输率为 4MB/s,不考虑排队时间。那么读一个 512B 扇区的平均时间大约为 ( )。
A. 5.125ms
B. 10.125ms
C. 15.125ms
D. 20.125ms7.【参考答案】B
【解析】 6000 转 / 分 = 100 转 / 秒,一转 10ms,平均等待时间为半转 5ms,数据传输时间 = 512B/4MB/s = 0.5KB/4MB/s = 0.125ms。时间 = 平均等待时间 + 数据传输时间 + 平均寻道时间 = 10.125ms,故选 B。5.假设某磁盘的每磁道有 512 个扇区,每个扇区有 512 字节。已知该磁盘转速为 9600RPM,则其最大数据传输率为 ( )。
A. 2400MB/s
B. 9600KB/s
C. 40MB/s
D. 256KB/s5.【参考答案】C
【解析】 磁盘转速 9600RPM/60 = 160r/s,160r/s×512 个扇区 /r×512B / 扇区 = 40MB/s。3.已知硬盘的传输速率为 10MB/s,磁盘转速为 9600RPM,磁盘控制器延时 1.5ms,平均寻道时间为 10.5ms,则该硬盘写 2KB 数据的时间为 ( )。
A. 13.825ms
B. 15.125ms
C. 15.325ms
D. 18.45ms3.【参考答案】C
【解析】 磁盘转速 9600RPM/60 = 160r/s,每转一圈的时间为 1000/160 = 6.25ms,平均旋转等待时间为 6.25/2 = 3.125ms;传输时间为 2KB/(10MB/s) = 0.2ms;延迟时间 1.5ms,平均寻道时间 10.5ms,总时间 = 延迟时间 + 平均寻道时间 + 平均旋转等待时间 + 传输时间 = 15.325ms。(5)误码率
是衡量磁表面存储器出错概率的参数。误码率 =出错信息位数/读出的总信息位数
(6)相关公式计算
格式化容量 = 面数 × 道数(每面)× 扇区数(每道)× 字节数(每扇区)
非格式化容量 = 面数 × 道数(每面)× 每个磁道的容量平均寻址时间 = 平均寻道时间 + 平均等待时间
平均存取时间 = 平均寻址时间 + 数据传输时间总时间 = 延迟时间 + 平均寻址时间 + 传输时间
总时间 = 延迟时间 + 平均寻道时间 + 平均旋转等待时间 + 传输时间
平均存取时间 = 平均寻道时间 + 平均等待时间 + 数据传输时间
一个磁道容量 = 周长 × 位密度
一转能传输一个磁道
平均等待时间为转半圈的时间
重点:1.磁盘转速->每转一圈的时间->每转半圈的时间(即平均旋转等待周期)
3.磁盘存储器的地址结构
磁盘在寻址时,先确定应访问哪个磁盘组(磁盘驱动器),再确定应访问该磁盘组中的哪个柱面(寻道),再确定应该访问的盘面,最后确定扇区(等待时间)。地址结构如下所示。
假设每个磁道有 16 个扇区,一共 8 个盘面,每个磁盘 128 个磁道,一共 4 个磁盘组。则磁盘地址的低 4 位为扇区号,相邻的高 3 位为盘面号,再高的 7 位为柱面号,最高的 2 位为磁盘组号。
【例 3-6】现有一个磁盘,其内半径为R1=1.0cm,外半径为R2=5.0cm,径向磁道密度为N=600条 /mm(即每条磁道是不同半径的同心圆),每个磁道分成 8192 个扇区,每个扇区可以记录 128 个字节。求:
(1) 该磁盘一个单面的格式化容量有多大?
(2) 假设某辅存一共 4 个磁盘组,每个磁盘组有 8 个盘面,每个盘面的参数与上述相同,则磁盘的地址结构是如何划分的?
(3) 已知该磁盘转速为 9600RPM,则其最大数据传输率是多少?
答:(1) 容量 = 面数 × 道数 / 面 × 扇区数 / 道 × 字节数 / 扇区 =1×(50−10)mm×600条 /mm×8192×128B =24×10^3MB。
(2) 4 个磁盘组需要 2 位地址,每个磁盘组 8 个盘面需要 3 位地址,一个盘面有24×10^3个磁道,至少需要 15 位地址,一个磁道 8192 个扇区需要 13 位地址,所以地址划分如图 3.26:
(3) 磁盘转速 9600RPM (9600 转 / 分钟)=160r/s,最大数据传输率 = 160r/s×8192 扇区 / 转 ×128B / 扇区 = 160MB/s。
3.5.2 磁盘阵列
磁盘阵列(Redundant Arrays of Independent Disks,RAID),有 “独立磁盘构成的具有冗余能力的阵列” 之意,其实就是用多个独立的磁盘组合形成一个大的磁盘系统,从而实现比单块磁盘更好的存储性能和更高的可靠性。
磁盘阵列可分为 RAID0~RAID5,其中 0 ~ 5 并不代表技术的差异或优劣,而是代表架构与功能的不同。1.RAID0
条带化存储磁盘阵列:RAID0 是一种简单的、无数据校验的数据条带化技术。实际上并不是一种真正的 RAID,因为它并不提供任何形式的冗余策略。RAID0 将所在磁盘条带化后组成大容量的存储空间,将连续的数据分散存储在所有磁盘中,在系统有数据请求时并行访问多个磁盘。由于可以并发执行 I/O 操作,总线带宽得到充分利用。再加上不需要进行数据校验,RAID0 的性能在所有 RAID 等级中是最高的。理论上讲,一个由 n 块磁盘组成的 RAID0,它的读写性能是单个磁盘性能的 n 倍,但由于总线带宽等多种因素的限制,实际的性能提升低于理论值。
8.下列磁盘阵列模式中,没有容错功能的是 ( )。
A. RAID0
B. RAID1
C. RAID3
D. RAID58.【参考答案】A
【解析】 RAID0 是一种无数据校验的数据条带化技术,不提供任何形式的冗余策略,故选 A。6.以下选项不正确的是 ( )。
A. RAID 通过冗余技术提高磁盘的磁记录密度和磁盘利用率
B. 硬盘和 U 盘格式化后容量会变小
C. U 盘和 SSD 都是基于闪存的存储技术,都属于只读存储器
D. 计算磁盘的存取时间时,“寻道时间” 和 “旋转等待时间” 的计算通常取其平均值6.【参考答案】A
【解析】 RAID 的冗余技术降低了磁盘的磁记录密度和磁盘利用率,A 错误;格式化容量小于非格式化容量,B 正确;U 盘和 SSD 都是 ROM 的一种,C 正确;寻道时间和旋转等待时间常用平均值,即移动一半磁道的时间和转半圈的时间,D 正确。2.RAID1
镜像存储磁盘阵列:RAID1 是磁盘阵列中单位成本最高的一种方式。因为它的原理是在往磁盘写数据的时候,将同一份数据无差别地写两份到磁盘,分别写到工作磁盘和镜像磁盘,那么它的实际空间使用率只有 50% 了,两块磁盘当做一块用,这是一种比较昂贵的方案。
3.RAID2
带海明码校验的磁盘阵列:RAID2 使用海明码来提供错误检查及恢复。
4.RAID3
位奇偶校验码磁盘阵列:这种校验码与 RAID2 采取的海明码不同,只能查错不能纠错。RAID3 是位奇偶校验码磁盘阵列,奇偶校验位只在奇偶校验盘上。
10.以下正确的叙述是 ( )。
A. RAID0 采用镜像盘
B. RAID1 无冗余
C. RAID2 采用 CRC 校验
D. RAID3 采用奇偶校验10.【参考答案】D
【解析】 RAID0 无冗余信息,没有采用镜像盘,只是将数据分散存储在各个磁盘中从而实现并发 I/O,A 选项错误;RAID1 采用镜像盘,牺牲 50% 的存储空间来实现数据保护,B 选项错误;RAID2 采用海明码校验,C 选项错误;D 选项正确。9.下面关于 RAID(Redundant Array of Inexpensive Disks)的说法中错误的是 ( )。
A. RAID0 没有容错能力,但其提高了磁盘的访问速度
B. RAID1 实现了磁盘镜像,磁盘的利用率降低了一半
C. RAID3 采用字节级别的奇偶校验实现容错,奇偶校验位交叉分布在阵列中的各个磁盘中
D. RAID5 采用区块级别的奇偶校验实现容错,奇偶校验位交叉分布在阵列中的各个磁盘中9.【参考答案】C
【解析】 RAID0 能使两个请求并行执行,提高了访问速度,A 正确;RAID1 将同一个信息映射到两个不同磁盘上,利用率减半,B 正确;RAID5 是分布式奇偶校验的独立磁盘结构,奇偶校验位交叉分布在阵列中的各个磁盘中,D 正确;RAID3 是位奇偶校验码磁盘阵列,奇偶校验位只在奇偶校验盘上,C 错误。5.RAID4
块奇偶校验码磁盘阵列:RAID4 和 RAID3 很像,不同的是,它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘。
6.RAID5
分布式奇偶校验的独立磁盘结构。
16.【2013】下列选项中,用于提高 RAID 可靠性的措施有 ( )。
I. 磁盘镜像
II. 条带化
III. 奇偶校验
IV. 增加 Cache 机制
A. 仅 I、II
B. 仅 I、III
C. 仅 I、III、IV
D. 仅 II、III、IV16.【参考答案】B
【解析】 RAID1 是采用磁盘镜像的措施,RAID3 采用位奇偶校验的措施,RAID4 采用块奇偶校验的措施,RAID5 采用分布式奇偶校验的措施。故 I 和 III 可以提高 RAID 可靠性。3.5.3 光存储器
光存储是由光盘表面的介质影响的,光盘上有凹凸不平的小坑,光照射到上面有不同的反射,再转化为 0、1 的数字信号以完成读取。
根据读写操作时所用的介质,可划分为第一代光存储技术和第二代光存储技术。前者使用非磁性介质,制作出的光盘不可再次擦写;后者使用磁性介质,可以再次擦写。
根据光盘的功能与性能,可将光盘划分为只读型光盘、只写一次型光盘和可擦写光盘。前两者采用热作用(物理或化学变化)写入数据,后者采取热磁效应写入数据。只读型光盘只可以由厂家生产时写入一次;只写一次型光盘可以由用户自行写入,但同样只可写入一次;可擦写光盘可多次读写。3.5.4 固态硬盘
1. 固态硬盘的基本原理
固态硬盘(Solid State Drive,简称 SSD)是一种使用固态存储芯片(通常是闪存存储器)来存储数据的存储设备。其读写单位是 512B~4KB 大小的页,不过闪存的擦除操作是按照 32~128 页大小的块来操作的。写入数据前必须要先擦除整个块,而不能直接覆盖。擦除整个块后,块内所有的页均可直接写入一次。SSD 常用作外存而不是主存。固态硬盘的擦除是以块为单位,读写是以页为单位。
12.关于 SSD 的特点,以下说法不正确的是 ( )。
A. 固态硬盘的读写是以页为单位的
B. 固态硬盘的擦除是以页为单位的
C. 由于固态硬盘在写入时需要擦除,所以固态硬盘的写入比读取要慢很多
D. 由于固态硬盘的写入次数有限,为延长使用寿命,一般引入磨损均衡12.【参考答案】B
【解析】 固态硬盘的擦除是以块为单位,读写是以页为单位,B 错误,A 正确;固态硬盘的写入比读取要慢,是因为在写入时需要擦除,且写入次数有限,否则该块就会因磨损而无法再次写入,故 C、D 均为 SSD 的正确描述。固态硬盘的基本结构如图 3.29 所示。一个固态硬盘包括一个或多个闪存芯片和闪存翻译层,其中闪存芯片相当于磁盘的机械驱动器,闪存翻译层相当于磁盘的磁盘控制器。
固态硬盘的写入比读取要慢,这是因为固态硬盘在写入时需要擦除,且试图对一个已经装有数据的页写入时,需要将该页所在块中所有已写入数据的页复制到新块中,才能对该页进行写入。
11.关于 SSD 的特点,以下说法不正确的是 ( )。
A. 读写性能明显高于磁盘
B. 读写速度较快,常用作主存
C. 写入次数有限,需要考虑磨损
D. 基于闪存的存储技术11.【参考答案】B
【解析】 SSD 常用作外存而不是主存,故 B 错误;固态硬盘相比机械硬盘,优点是启动,读取时间快,但写入次数有限,否则盘块就会因磨损而无法再次写入,故 A、C、D 均正确。固态硬盘相比机械硬盘,优点是启动快、读取时间快、能够直接读取资料、不会影响读取时间、抗摔性能很强。但是固态硬盘中的一个块的写入次数不能过多,一般不超过 10 万次,否则该块就会因磨损而无法再次写入,因此固态硬盘引入了磨损均衡。其目的是避免数据重复在某个空间写入,以保证各个存储区域内磨损程度基本一致,从而延长固态硬盘寿命。
2. CF - LRU(Clean - First LRU)算法
现代计算机大多采用 SSD 作为外存,但是考虑到 SSD 读快写慢以及写入次数有限,于是有人提出了 CF - LRU(Clean - First LRU)算法。这是一种基于 SSD 的页面置换算法,该算法兼顾了命中率和缓存替换给闪存带来的开销。dirty 页面是指被修改过,即内容与外存数据不一致的页面;clean 页面是指没有被修改过,即内容与外存数据一致的页面。
算法工作原理:
(1) 该算法将缓存链表分为 working 区和 clean - first 区两部分,如图 3.30 所示。设 w 为窗口大小,则靠近 LRU 端的 w 个页面属于 clean - first 区,其余页面属于 working 区。
(2) 命中的页面会被从链表中取出,放在链表的第一位,即图中的 MRU 端;若未命中,则需要淘汰页面。
(3) 在选择淘汰页面时,算法优先选择 clean - first 区靠近 LRU 端的 clean 页面换出。
(4) 若 clean - first 区没有 clean 页面,则选择 clean - first 区靠近 LRU 端的 dirty 页面换出,并将页面内容写回 SSD。提示:LRU替换方法在计算机中十分常见,本节主要是为了将LRU与SSD相结合,相关内容了解即可。
【例 3-7】 根据 SSD 的 CF - LRU 算法,回答以下问题:
(1) 假设采用 CF - LRU 算法且窗口大小为 3,内存中最多容纳 6 个页面。若链表的初始状态为 2D→3C→1D→7D→8C→4D,访问序列为 P3(读)P9(读)P10(读写)P3(读)P4(读)P11(读写)P9(读)P3(读),请回答总共的写回次数和命中次数。
(2) 若将 (1) 中的窗口大小从 3 改成 4,总共的写回次数和命中次数如何?
(3) 注意到 (2) 中的写回次数比 (1) 中的少,窗口增大有利于减少写回次数。但是窗口是否越大越好,为什么?答:
(1) 访问情况如下表所示。
共写回 3 次,命中 3 次。
(2) 访问情况如下表所示。
共写回 2 次,命中 2 次。
(3) 窗口增大确实会减少写回次数,但是也会减小命中率。CF - LRU 算法本质上是用降低命中率为代价来减少写回次数。
3.5.5 习题精编
1.磁盘转速提高一倍,则 ( )。
A. 寻道时间缩小一半
B. 存取速度也提高一倍
C. 平均查找时间缩小一倍
D. 不影响磁盘传输速率1.【参考答案】C
【解析】 磁盘存取的步骤为:启动磁头 + 寻道、旋转延迟 (查找时间)、传输数据,转速提高一倍则寻道时间不变,A 错误;存取速度需要看所有步骤的时间,虽然会提高,但不会提高一倍,B 错误;平均查找 (旋转延迟) 为旋转半圈的时间,因此时间也会相应缩小一倍,C 正确;转速提高则传输速率也会提高,D 错误。2.下列选项中,可以提高磁盘的存储容量的是 ( )。
A. 加快磁盘转速
B. 提高磁头移动速度
C. 增加磁盘 Cache
D. 增加位密度2.【参考答案】D
【解析】 加快磁盘转速与提高磁头移动速度可以提高磁盘运行效率,不能增加磁盘存储容量,A、B 选项错误;磁盘 Cache 为在主存中开辟的一个缓冲空间,解决主存与磁盘工作速度不匹配的问题,实际上存储的是磁盘中数据的副本,并不能增加磁盘存储容量,C 选项错误;位密度为单位长度上能存储的二进制信息数量,增加位密度即可增加单位长度上的存储信息数量,即增加磁盘的存储容量,D 选项正确。3.已知硬盘的传输速率为 10MB/s,磁盘转速为 9600RPM,磁盘控制器延时 1.5ms,平均寻道时间为 10.5ms,则该硬盘写 2KB 数据的时间为 ( )。
A. 13.825ms
B. 15.125ms
C. 15.325ms
D. 18.45ms3.【参考答案】C
【解析】 磁盘转速 9600RPM/60 = 160r/s,每转一圈的时间为 1000/160 = 6.25ms,平均旋转等待时间为 6.25/2 = 3.125ms;传输时间为 2KB/(10MB/s) = 0.2ms;延迟时间 1.5ms,平均寻道时间 10.5ms,总时间 = 延迟时间 + 平均寻道时间 + 平均旋转等待时间 + 传输时间 = 15.325ms。4.假设某磁盘具有 16 个盘片和 8192 个柱面,每磁道有 512 个扇区,每个扇区有 512 字节,则该磁盘的总容量为 ( )。
A. 32MB
B. 32GB
C. 16MB
D. 16GB4.【参考答案】B
【解析】 8192 个柱面即 8192 个磁道,16 个盘片 ×8192 个磁道 / 盘面 ×512 个扇区 / 磁道 ×512 字节 / 扇区 = 32GB。5.假设某磁盘的每磁道有 512 个扇区,每个扇区有 512 字节。已知该磁盘转速为 9600RPM,则其最大数据传输率为 ( )。
A. 2400MB/s
B. 9600KB/s
C. 40MB/s
D. 256KB/s5.【参考答案】C
【解析】 磁盘转速 9600RPM/60 = 160r/s,160r/s×512 个扇区 /r×512B / 扇区 = 40MB/s。6.以下选项不正确的是 ( )。
A. RAID 通过冗余技术提高磁盘的磁记录密度和磁盘利用率
B. 硬盘和 U 盘格式化后容量会变小
C. U 盘和 SSD 都是基于闪存的存储技术,都属于只读存储器
D. 计算磁盘的存取时间时,“寻道时间” 和 “旋转等待时间” 的计算通常取其平均值6.【参考答案】A
【解析】 RAID 的冗余技术降低了磁盘的磁记录密度和磁盘利用率,A 错误;格式化容量小于非格式化容量,B 正确;U 盘和 SSD 都是 ROM 的一种,C 正确;寻道时间和旋转等待时间常用平均值,即移动一半磁道的时间和转半圈的时间,D 正确。7.假定某一磁盘的转速为 6000RPM(转 / 分),平均寻道时间为 5ms,平均数据传输率为 4MB/s,不考虑排队时间。那么读一个 512B 扇区的平均时间大约为 ( )。
A. 5.125ms
B. 10.125ms
C. 15.125ms
D. 20.125ms7.【参考答案】B
【解析】 6000 转 / 分 = 100 转 / 秒,一转 10ms,平均等待时间为半转 5ms,数据传输时间 = 512B/4MB/s = 0.5KB/4MB/s = 0.125ms。时间 = 平均等待时间 + 数据传输时间 + 平均寻道时间 = 10.125ms,故选 B。8.下列磁盘阵列模式中,没有容错功能的是 ( )。
A. RAID0
B. RAID1
C. RAID3
D. RAID58.【参考答案】A
【解析】 RAID0 是一种无数据校验的数据条带化技术,不提供任何形式的冗余策略,故选 A。9.下面关于 RAID(Redundant Array of Inexpensive Disks)的说法中错误的是 ( )。
A. RAID0 没有容错能力,但其提高了磁盘的访问速度
B. RAID1 实现了磁盘镜像,磁盘的利用率降低了一半
C. RAID3 采用字节级别的奇偶校验实现容错,奇偶校验位交叉分布在阵列中的各个磁盘中
D. RAID5 采用区块级别的奇偶校验实现容错,奇偶校验位交叉分布在阵列中的各个磁盘中9.【参考答案】C
【解析】 RAID0 能使两个请求并行执行,提高了访问速度,A 正确;RAID1 将同一个信息映射到两个不同磁盘上,利用率减半,B 正确;RAID5 是分布式奇偶校验的独立磁盘结构,奇偶校验位交叉分布在阵列中的各个磁盘中,D 正确;RAID3 是位奇偶校验码磁盘阵列,奇偶校验位只在奇偶校验盘上,C 错误。10.以下正确的叙述是 ( )。
A. RAID0 采用镜像盘
B. RAID1 无冗余
C. RAID2 采用 CRC 校验
D. RAID3 采用奇偶校验10.【参考答案】D
【解析】 RAID0 无冗余信息,没有采用镜像盘,只是将数据分散存储在各个磁盘中从而实现并发 I/O,A 选项错误;RAID1 采用镜像盘,牺牲 50% 的存储空间来实现数据保护,B 选项错误;RAID2 采用海明码校验,C 选项错误;D 选项正确。11.关于 SSD 的特点,以下说法不正确的是 ( )。
A. 读写性能明显高于磁盘
B. 读写速度较快,常用作主存
C. 写入次数有限,需要考虑磨损
D. 基于闪存的存储技术11.【参考答案】B
【解析】 SSD 常用作外存而不是主存,故 B 错误;固态硬盘相比机械硬盘,优点是启动,读取时间快,但写入次数有限,否则盘块就会因磨损而无法再次写入,故 A、C、D 均正确。12.关于 SSD 的特点,以下说法不正确的是 ( )。
A. 固态硬盘的读写是以页为单位的
B. 固态硬盘的擦除是以页为单位的
C. 由于固态硬盘在写入时需要擦除,所以固态硬盘的写入比读取要慢很多
D. 由于固态硬盘的写入次数有限,为延长使用寿命,一般引入磨损均衡12.【参考答案】B
【解析】 固态硬盘的擦除是以块为单位,读写是以页为单位,B 错误,A 正确;固态硬盘的写入比读取要慢,是因为在写入时需要擦除,且写入次数有限,否则该块就会因磨损而无法再次写入,故 C、D 均为 SSD 的正确描述。13.某磁盘有 6 个盘面,转速为 12000 转 / 分钟,共有 200 道磁道,最小磁道直径为 100mm,道密度为 10tpm,每道记录信息 4KB。
(1) 磁盘的存储容量是多少?
(2) 磁盘的数据传输率是多少?
(3) 假定每个扇区的容量为 512B,每个磁道有 10 个扇区,平均寻道时间为 5ms,磁盘的平均存取时间是多少?13.【参考答案】
(1) 6 个记录面信息容量 = 6× 每道记录信息 4KB× 磁道数 200 = 4800KB。
(2) Dr=n×N=4KB×200r/s=800KB/s。
(3) 平均存取时间 = 平均寻道时间 + 平均等待时间 + 数据传输时间;平均等待时间为转半圈的时间,200r/s 即转一圈 5ms,半圈 2.5ms;数据传输时间为扫过一个扇区的时间 = 一转 5ms/10 个扇区 = 0.5ms;平均存取时间 = 2.5ms + 5ms + 0.5ms = 8ms。14.磁盘有 10 个面,每面有 220 道,内层磁道周长 70cm,位密度 400 位 /cm,转速 12000 转 / 分,问:
(1) 磁盘存储容量是多少?
(2) 数据传输率是多少?14.【参考答案】
(1) 一个磁道容量 = 周长 × 位密度 = 70cm×400 位 /cm = 28000 位 = 3500B,容量 = 10×220×3500B = 7700000B。
(2) 12000 转 / 分 = 200 转 / 秒,一转能传输一个磁道,一个磁道容量 3500B,数据传输率 = 3500B / 道 ×200 道 /s = 700000B/s。3.5.6 真题演练
15.【2013】某磁盘的转速为 10000 转 / 分,平均寻道时间是 6ms,磁盘传输速率是 20MB/s,磁盘控制器延迟为 0.2ms,读取一个 4KB 的扇区所需的平均时间约为 ( )。
A. 9ms
B. 9.4ms
C. 12ms
D. 12.4ms15.【参考答案】B
【解析】 10000 转 / 分即转一圈的时间为 6ms,平均等待时间为转半圈的时间,即 3ms。磁盘传输速率是 20MB/s,读 4KB 需要 4KB/(20MB/s) = 0.2ms。平均寻找时间 = 平均等待时间 + 平均寻道时间 + 延迟 + 数据传输时间 = 3ms + 6ms + 0.2ms + 0.2ms = 9.4ms。16.【2013】下列选项中,用于提高 RAID 可靠性的措施有 ( )。
I. 磁盘镜像
II. 条带化
III. 奇偶校验
IV. 增加 Cache 机制
A. 仅 I、II
B. 仅 I、III
C. 仅 I、III、IV
D. 仅 II、III、IV16.【参考答案】B
【解析】 RAID1 是采用磁盘镜像的措施,RAID3 采用位奇偶校验的措施,RAID4 采用块奇偶校验的措施,RAID5 采用分布式奇偶校验的措施。故 I 和 III 可以提高 RAID 可靠性。17.【2015】若磁盘转速为 7200 转 / 分,平均寻道时间为 8ms,每个磁道包含 1000 个扇区,则访问一个扇区的平均存取时间大约是 ( )。
A. 8.1ms
B. 12.2ms
C. 16.3ms
D. 20.5ms17.【参考答案】B
【解析】 7200 转 / 分即转一圈的时间为 8.33ms,平均等待时间为转半圈的时间,即 4.17ms。每个磁道包含 1000 个扇区且一个磁道占用一圈,则传输一个扇区数据的时间为转 1/1000 圈,传输时间为 0.008ms。平均寻找时间 = 平均等待时间 + 平均寻道时间 + 传输时间 = 4.17ms + 8ms + 0.008ms = 12.2ms (四舍五入)。18.【2019】下列关于磁盘存储器的叙述中,错误的是 ( )。
A. 磁盘的格式化容量比非格式化容量小
B. 扇区中包含数据、地址和校验等信息
C. 磁盘存储器的最小读写单位为一个字节
D. 磁盘存储器由磁盘控制器、磁盘驱动器和盘片组成18.【参考答案】C
【解析】 磁盘以扇区为最小读写单位,故 C 错误。格式化容量为用户真实可用的容量,非格式化容量为磁表面所有可利用的空间,因此格式化容量小于非格式化容量,A 正确。B 和 D 为扇区和磁盘组成的基本信息,均正确。3.6 Cache
现代计算机在发展的过程中,主存储器存取速度一直比中央处理器操作速度慢得多,这种速度的不匹配使得 CPU 无法充分发挥其性能,所以高速缓冲存储器 Cache 就成为现代计算机存储系统中不可缺少的组成部分。Cache 由 SRAM 组成,如今大多直接集成在 CPU 中。
3.6.1 Cache 的基本工作原理
Cache 在存储器的层次化结构中位于 CPU 和主存之间,用来存放一段时间内被频繁访问的主存信息的副本。根据程序的局部性原理,这段时间内 CPU 所需的信息基本都可在 Cache 里找到,便不需访问主存。Cache 拥有比主存更快的访问速度,因此使用 Cache 作主存的缓存能显著提高访存速度。
1. Cache 的基本结构与运作流程
图 3.31 为 Cache 的基本结构。Cache 和主存都被分成若干个大小相等的块(也称作行),两者间以块为单位交换数据。Cache 的容量远小于主存,且 Cache 的内容都是主存信息的副本,主存中的数据并不一定在 Cache 中。CPU 在访存时,先查看 Cache 中是否有需要的主存信息,有则直接访问 Cache(称为 Cache 命中);否则(称为 Cache 未命中)访问主存,并将信息更新到 Cache 中。
在 CPU 访问主存时,先根据映射方式找到该数据地址的对应 Cache 块。未命中时,若 Cache 块为空,则需要把未命中的数据从主存读入 Cache。若 Cache 块已被其他数据占用,那么需根据替换策略将 Cache 中的某块调出,以腾出空间供新数据存储。
提示:在 Cache 里,块指的是与主存交换的信息量大小单位,Cache 块大小与主存块大小保持一致;行指的是 Cache 的容器里的单位,一行能存储一块信息量,此外还有其他辅助位信息。因为在 Cache 里一行总是存储一个块的信息,故 Cache 行等同于 Cache 块,“行” 和 “块” 在描述 Cache 时的意思是相同的。2. Cache - 主存层次的平均访问时间
在一个存储系统中,Cache 命中次数占总存取次数的百分比为命中率 p。访问一次 Cache 的时间为缓存存取时间Tc,访问一次主存的时间为主存存取时间Tm。系统在访存时,会先访问 Cache,如果 Cache 命中,则耗时为Tc,否则还要访问一次主存,此时时间为Tm+Tc。
则 CPU 在 Cache - 主存层次的平均访问时间Ta为:
Ta=p×Tc+(1−p)×(Tc+Tm)=Tc+(1−p)×Tm
Cache - 主存的效率为Tc/Ta。
由于程序访问的局部性特点,Cache 的命中率可以达到很高,接近于 1。因此,虽然Tm>Tc,但最终的平均访问时间Ta仍可接近 Cache 的访问时间Tc。3. Cache 的辅助位
Cache 的每一个行不仅要存储对应的主存块的数据,同时需要附设若干个辅助位。辅助位包括 Tag 位、有效位、脏位、LRU 标记位等,其中 Tag 位和有效位是任何 Cache 所必需的。脏位仅当 Cache 采取写回法时才需附设,LRU 标记位仅当 Cache 采取 LRU 替换策略时才需附设。
1.标记(Tag)位:大小取决于地址映射策略。因为 Cache 的总块数远小于主存的块数,所以存在多个主存块均可对应相同的 Cache 块的情况。通过设立 Tag 位可以区分当前 Cache 块具体对应了哪一个主存块。
2.有效位:大小为每块 1bit。有效位用来表明该 Cache 存储块中的数据是否有效,因为有时候 Cache 中的数据是无效的,例如,在初始时刻 Cache 应该是空的,其中的内容是无意义的。有效位为 1 时该 Cache 块的数据有效,反之为 0 则为无效数据。
3.脏位:大小为每块 1bit。仅当 Cache 采取写回法(后面介绍)时才需要附设。脏位为 1 时,说明该 Cache 块已经被 CPU 写入过,与对应主存的数据不再相同。反之为 0 则说明未被写入,与对应的主存数据相同。
4.LRU 标记位:大小为每块log2(组内 Cache 块数) bit。仅当 Cache 采取 LRU 替换策略(后面介绍)时才需要附设。
一行 Cache 的内容包括辅助位和 Cache 块数据,其组成为图 3.32 所示。
4. Cache 的选择
(1)Cache 命中率的影响因素
1.Cache 容量:选择较大容量的 Cache 可能提高 Cache 的命中率,但也会对 Cache 的运行效率造成影响。
2.Cache 块:Cache 块不是越大越好或越小越好,需要选择合适的大小。Cache 块很大时,好处是这一块发生冲突替换的可能性就小,更能利用空间的局部性,使得命中率更高;坏处是一旦发生替换,改动写入的内容就越多,造成更大的开销。Cache 块很小时,好处是替换代价比较小;坏处是命中率会很低。
1.下列对 Cache 的表述中,通常是正确的是( )。
I. 指令 Cache 往往比数据 Cache 具备更强的空间局部性
II. 由于空间局部性,增加 Cache 块大小通常会导致更高的命中率
III. 写回 Cache 的写操作少于写直达 Cache
A. III
B. I、II
C. II、III
D. I、II 和 III
1.【参考答案】 D
【解析】 指令通常为连续存储,指令 Cache 比数据 Cache 具备更强的空间局部性,I 正确;由于程序的空间局部性,同一内存块中的数据利用率比较高,增加块大小时,Cache 的命中率会升高,但是当块过大时,会有更多暂时不会被访问的数据进入 Cache 中,导致命中率开始下降,因此本题的 “通常” 说法是准确的,II 正确;写回法只在 Cache 块被换出时才会检查是否需要进行写操作,写直达法每次 Cache 中数据被修改时都需要进行写操作,因此 III 正确。3.映射方法:本节将学习三种映射方法,同一个 Cache 采用不同的映射方法命中率也会有所不同。总的来说,对于特定的某块主存,其能映射到的 Cache 块越多,冲突的可能性就越小,命中率也就越高。
(2)分离 Cache
分离 Cache是指将数据和指令分开,分别存储在数据 Cache 和指令 Cache 中。数据和指令放在一起的 Cache 称为联合 Cache。在流水线控制方式下,为了防止取指过程和执行过程发生冲突,需要将数据 Cache 和指令 Cache 分开。
(3)多级 Cache
除了本节所讲的单级 Cache 外,现在越来越多的计算机开始使用多级 Cache。常用的多级 Cache 为 L1 Cache 和 L2 Cache。要访问主存信息时,先访问 L1 Cache,若缺失再访问 L2 Cache,此时的缺失损失为访问 L2 Cache 的时间而不是访问主存的时间,因此加快了访存速度。不过 L2 Cache 仍缺失时,需要访问主存并将信息同时写入两个 Cache,这时便造成了更大的损失开销。L1 Cache 更关注速度,一般使用分离 Cache,L2 Cache 更关注命中率。多级 Cache 有全局缺失率的概念,指访问所有 Cache 都没有命中的概率。
3.6.2 Cache 和主存的映射方式
Cache 块中的信息取自主存中的某个块。在将主存块复制到 Cache 块时,主存块和 Cache 块之间必须遵循一定的映射规则。根据对应的映射规则能够知道 Cache 块的位置,在 CPU 寻找 Cache 块的过程中,便可快速找到要访问的数据。地址映射的方法有如下 3 种:
1. 直接映射
直接映射的基本思想是把主存的每一块映射到固定且唯一的 Cache 块中,其映射关系如下:
Cache 块号 = 主存块号 % Cache 总块数
直接映射地址结构如图 3.33 所示。当 Cache 有2^M块,每块大小为2^N字节时,则访存地址的低 N 位为块内地址,中间 M 位为 Cache 块号,剩下的高位为标记位,用于判断该 Cache 块对应哪一个主存块。
直接映射的映射关系如图 3.34 所示。主存中的块有且仅有一个对应的 Cache 块,若该 Cache 块存储的不是该主存块的数据,则该主存块不在 Cache 中。在直接映射下,一行就是一块,Cache 块号就是 Cache 行号。
访存过程如图 3.35 所示。先计算中间 M 位的数值,获得 Cache 块号,进而核对 Tag 位是否吻合。若吻合且有效位为 1,则命中,然后 CPU 对 Cache 进行读写操作。若未命中,则需要将待访问的主存块调入 Cache 中,同时将主存块数据送给 CPU。
直接映射的优点是实现简单,地址变换速度快。但命中率较低,会产生频繁地调进调出。直接映射适合大容量 Cache。
2. 全相联映射
如图 3.36 所示,全相联映射的基本思想是一个主存块可装入 Cache 任意一块中。全相联映射方式下,只要有空闲 Cache 块,就不会发生冲突,因而块冲突概率低于直接映射。全相联映射的特点是任意主存块可对应任意 Cache 块。
全相联映射地址结构如图 3.37 所示。全相联映射下,假设每个 Cache 块大小为2^N字节,则访存地址的低 N 位为块内地址,剩下的全体高位构成标记位。
访存过程如下:顺次检查每一个 Cache 行,若标记位与访存地址吻合且有效位为 1,则进行读写操作;如果均不合条件则未命中,将需要访问的主存块调入 Cache 中,必要时换出旧 Cache 块(即启动替换策略选择要替换的旧 Cache 块),同时将需要的数据送入 CPU。
采取全相联映射的 Cache 需要使用价格昂贵的相联存储器,是一种独立于主存之外的特殊存储器类型,可以当成特殊的寄存器。相联存储器既可以按照地址寻址也可以按照内容寻址(通常是某些字段)。后续在虚拟存储器中学习的 TLB 也使用了相联存储器。
全相联映射的优点是命中率高。但其生产需要用到价格高昂的相联存储器,且地址变换速度较慢。全相联映射适用于小容量 Cache。
14.在同一个 Cache 里,有 3 种映射方式可以采用,总体上发生冲突概率最小的是( )。
A. 直接映射
B. 全相联映射
C. 组相联映射
D. 都一样
14.【参考答案】 B
【解析】 直接映射映射到唯一一行,组相联映射映射到一组里的若干行,全相联映射映射到整个 Cache 所有行,映射到的行越多发生冲突概率越小,故发生冲突的概率全相联映射 < 组相联映射 < 直接映射。3. 组相联映射
组相联映射方式结合了直接映射方式和全相联映射方式的优点。如图 3.38 所示,组相联映射的主要思想是:将 Cache 所有2^K块分成2^M个大小相等的组,每组有2^(K−M)块(每组拥有的块数又称作路数,比如 4 路组相联就是每个组拥有 4 个 Cache 块)。
组相联映射方式下,每个主存块被映射到 Cache 固定组中的任意一块,即组相联采用组间直接映射、组内全相联映射的方式,映射关系如下:
Cache 组号 = 主存块号 % Cache 组数组相联映射地址结构如图 3.39 所示。当 Cache 有2^M组,每块大小为2^N字节时,则访存地址的低 N 位为块内地址,中间 M 位为组号,剩下的高位作为 Tag 位。
访存过程如下:先计算出中间 M 位的数值,获知对应的 Cache 组号,进而核对这个组里是否有一行 Tag 位吻合且有效位为 1。若 Tag 位吻合且有效位为 1,则命中,然后 CPU 对 Cache 进行读写操作。若未命中,则将需要访问的主存块调入 Cache 中。若调入时该组已满,则启动替换策略,同时把待读取数据送入 CPU。
采用 2 路组相联映射 cache 的硬件线路如图 3.40 所示。从图中可以看出组相联映射的 cache 的比较器个数与路数相同,比较器的位数等于 Tag 位数。
对于组相联映射,当 Cache 的组数为 1 时,变为全相联映射;当每组只有一个 Cache 行时,则变为直接映射。组相联映射综合了直接映射与全相联映射的优点,既保证了地址映射的速度,也保证了命中率。
【例 3-8】某计算机按字节编址,主存大小为 2MB,Cache 能存储 4KB 的信息,Cache 块大小为 4B。
(1) 在直接映射关系下,设计主存的地址格式。
(2) 在全相联映射关系下,设计主存的地址格式。
(3) 在四路组相联映射关系下,设计主存的地址格式。
答:Cache 块大小 4B,则块内地址 2 位(22=4),Cache 块数 = Cache 信息总数 / Cache 块大小 = 1K(210)。主存大小 2MB,则地址结构总长度 21 位(221=2M)。
(1) 块内地址 2 位,Cache 块号 10 位,其余均为标记位,标记位为 21 - 10 - 2 = 9 位(也可以由主存大小 2MB/Cache 大小 4KB 得出 )。
(2) 块内地址 2 位,其余均为标记位,标记位为 21 - 2 = 19 位。
(3) 块内地址 2 位,四路组一共有 1K/4 = 256 组,组号需要 8 位(28=256),其余均为标记位,标记位为 21 - 8 - 2 = 11 位。
拓展:考生有没有思考过,为什么 Cache 的地址划分里要将索引(行号、组号)划在地址结构的中间位置呢?这是因为主存上连续的块的地址高位是一样的(参考高位交叉方式),若把索引划分在主存地址的高位,这样就会造成连续块会被映射到 Cache 的同一块,从而导致在追求良好的局部性的同时,相邻块会被频繁换入换出,降低 Cache 的命中率。
3.6.3 Cache 中主存块的替换算法
由于 Cache 的容量远小于主存的容量,所以经常要把某一 Cache 块替换出去,腾出空间给新访问的主存块,这个过程称为替换。对于直接映射,一旦发生替换,则被替换块唯一;但是对于全相联映射和组相联映射,就需要在若干块中选择合适的一块替换出去。这个替换块的选择策略就叫替换策略,也叫替换算法,替换操作完全是通过硬件方式实现的。
常用的替换算法有先进先出算法(First - In - First - Out,FIFO)、最近最少用算法(Least - Recently Used,LRU)、最不经常用算法(Least - Frequently Used,LFU)和随机替换算法等。1.先进先出算法
FIFO 算法的基本思想是:把现有若干 Cache 块中装入时间最早的那个 Cache 块替换出去。算法实现起来简单,但因为没有遵循程序的局部性原理(较早装入的 Cache 块可能正被高频访问),所以效果往往较差。
2.最近最少用算法
LRU 算法的基本思想是:把现有若干 Cache 块中近期最少被访问的那个 Cache 块替换出去。该算法遵循了程序的局部性原理,但是缺点是属于堆栈类算法,算法时间开销大。
如果 Cache 采取 LRU 算法,则必须为每个 Cache 块引入 LRU 替换位,每块的 LRU 替换位的大小为log2(组内 Cache 块数) bit。比如在一个四路组相联的 Cache 里采取 LRU 算法,就需要 2bit 的 LRU 位(log24=2)。3.最不经常用算法
LFU 算法的基本思想是:把现有若干 Cache 块中被引用次数最少的那个 Cache 块替换出去。其与 LRU 类似,两者都需要结合 Cache 块的使用情况进行判断。
4.随机替换算法
从候选的 Cache 块中随机选取一个淘汰,与使用情况无关。与先进先出算法一样并不遵循程序的局部性原理。
【例 3-9】假设有一个块数为 4 的 Cache,采取全相联映射。起初 Cache 中内容为空,接下来 CPU 连续访问了以下主存块(均为十进制):1,2,3,4,1,5,1,3,2,3。试描述 Cache 采取以下替换策略时的访问情况,并计算命中率:
(1) 先进先出算法
(2) 最近最少用算法
答:(1) 如表 3.2 所示,当 Cache 中有空间时,直接放入;无空间时,把最早进入的块替换掉。一共访问十次,仅第 5 次和第 8 次命中,因此命中率为 20%。
(2) 如表 3.3 所示,当 Cache 中有空间时,直接放入;无空间时,把最久未被访问的块替换掉。一共访问十次,第 5、7、8、10 次命中,因此命中率为 40%。
3.6.4 Cache 的一致性问题
Cache 的内容应是主存内容的副本。但是 CPU 对 Cache 的写操作会导致 Cache 与主存数据不一致,从而引发了 Cache 的一致性问题。
解决 Cache 一致性问题的关键是处理好写操作。针对命中,有两种写操作方式:1.全写法(write through)
又称直写法。全写法的基本做法是:写操作时,若写命中,则同时写 Cache 和主存。该方法的实现较为简单,同时能够随时保持主存数据的正确性。缺点是增加了访存次数,降低了 Cache 的效率。此外需要引入写缓冲,CPU 在将数据写入 Cache 的同时也写入写缓冲,然后由写缓冲将需要写入的数据写回主存。写缓冲是一个 FIFO 队列,将对主存的写请求排成队列,顺次完成。当写请求过多时,可能会引发写缓冲的溢出。
2.写回法(write back )
写回法的基本做法是:当 CPU 执行写操作时,若写命中,则信息只被写入 Cache 而不被写入主存。直到该 Cache 块被替换出去时,才将数据写回主存。这种方法有潜在的数据不一致的问题,但减少了访存次数,提升了效率。因此采取写回法的 Cache 应给每个 Cache 块附设 1bit 的脏位,刚载入的 Cache 块其脏位设为 0,当 CPU 修改该 Cache 块后脏位改为 1。在该 Cache 块替换出去时,若脏位为 1,则需要写回主存。写回法可以提高系统的性能,减少写操作的次数,但其实现方法也更复杂。
1.下列对 Cache 的表述中,通常是正确的是( )。
I. 指令 Cache 往往比数据 Cache 具备更强的空间局部性
II. 由于空间局部性,增加 Cache 块大小通常会导致更高的命中率
III. 写回 Cache 的写操作少于写直达 Cache
A. III
B. I、II
C. II、III
D. I、II 和 III
1.【参考答案】 D
【解析】 指令通常为连续存储,指令 Cache 比数据 Cache 具备更强的空间局部性,I 正确;由于程序的空间局部性,同一内存块中的数据利用率比较高,增加块大小时,Cache 的命中率会升高,但是当块过大时,会有更多暂时不会被访问的数据进入 Cache 中,导致命中率开始下降,因此本题的 “通常” 说法是准确的,II 正确;写回法只在 Cache 块被换出时才会检查是否需要进行写操作,写直达法每次 Cache 中数据被修改时都需要进行写操作,因此 III 正确。当写不命中时,有写分配法与非写分配法:
1.写分配法(write allocate)
写分配法的基本做法是:在写回主存后,把写入过的主存块调入 Cache 中。调入过程会带来时间上的开销,但更好地遵循了程序的局部性原理。一般与写回法相结合使用。2.非写分配法(not write allocate)
非写分配法的基本做法是:写回主存后,不把写入过的主存块调入 Cache 中。节约了调入主存块引发的时间开销,但是并不遵循程序的局部性原理。一般与全写法相结合使用。
【例 3 - 10】假定主存地址为 32 位,按字节编址,主存和 Cache 之间采用直接映射方式,主存块大小为 8 个字,每字 32 位,采用写回 (Write Back) 方式,Cache 能存放 8K 字数
据,则 Cache 的总容量是多少?
答:块大小为:每块 8 个字 × 每字 32 位 ÷8 位 = 32B。按字节编址,所以块内地址占log232=5位。Cache 共有 8K 字数据,一行有 8 个字,故共有 1K 行,所以 Cache 行号占位log21K=10位。主存地址共 32 位,减去 Cache 行号 10 位和块内地址 5 位,每行 Cache 块的标记位占用 32 - 10 - 5 = 17 位,此外每行 Cache 占用 1 位有效位和 1 位脏位 (因为是写回法)。所以每个 Cache 行的辅助位是 17 + 1 + 1 = 19 位,Cache 总容量为 1K×(19 + 32×8) bit = 275Kb。3.6.5 习题精编
1.下列对 Cache 的表述中,通常是正确的是( )。
I. 指令 Cache 往往比数据 Cache 具备更强的空间局部性
II. 由于空间局部性,增加 Cache 块大小通常会导致更高的命中率
III. 写回 Cache 的写操作少于写直达 Cache
A. III
B. I、II
C. II、III
D. I、II 和 III
1.【参考答案】 D
【解析】 指令通常为连续存储,指令 Cache 比数据 Cache 具备更强的空间局部性,I 正确;由于程序的空间局部性,同一内存块中的数据利用率比较高,增加块大小时,Cache 的命中率会升高,但是当块过大时,会有更多暂时不会被访问的数据进入 Cache 中,导致命中率开始下降,因此本题的 “通常” 说法是准确的,II 正确;写回法只在 Cache 块被换出时才会检查是否需要进行写操作,写直达法每次 Cache 中数据被修改时都需要进行写操作,因此 III 正确。2.下面关于计算机 Cache 的论述中,正确的是( )。
A. Cache 位于主辅存之间,缓存辅存数据
B. Cache 替换时的单位为字节
C. 无论何时,Cache 中的信息一定与主存中的信息一致
D. Cache 的命中率必须很高,一般要达到 90% 以上
2.【参考答案】 D
【解析】 Cache 位于 CPU 和主存之间,缓存主存数据,A 错误;Cache 替换的单位为块,B 错误;Cache 用写回法时与主存中的信息不一定一致,C 错误;Cache 只有命中率高时才能充分发挥作用,D 正确。3.下列场景下,Cache 的作用发挥较好的是( )。
A. 不含有过多的中断操作
B. 访问的数据大多在外存中
C. 有大量循环语句和数组顺序访问
D. 各指令相关度不高
3.【参考答案】 C
【解析】 中断操作与 Cache 无关,A 错误;访问的数据大多在内存中,B 错误;指令相关度高才能有更好的局部性,D 错误;C 使程序有更好的局部性,故正确。4.设 CPU 发送指令和数据地址到存储器需 1 个时钟周期,存储器收到 CPU 信息到传出数据需 7 个时钟周期,总线上每传送 1 次数据需 1 个时钟周期。若 Cache 块大小为 32B,存取宽度和总线宽度都为 4B,则读一次 Cache 块至少要( )个时钟周期。
A. 40
B. 64
C. 72
D. 160
4.【参考答案】 C
【解析】 CPU 发送指令和数据地址需要 1 个时钟周期,存储器发数据需要 7 个时钟周期,总线传输 4B 数据需要 1 个时钟周期,共 9 个时钟周期,9×32B/4B = 72 个时钟周期。5.Cache 采用全相联映射方式,共 16 行,能存放 8MB 的数据,主存容量为 128MB。Cache 的读写时间为 5ns,主存读写时间为 100ns,平均访问时间为 6ns,则 Cache 的命中率为( )。
A. 99%
B. 98%
C. 97%
D. 96%
5.【参考答案】 A
【解析】 平均访问时间Ta=p×Tc+(1−p)×(Tc+Tm)=Tc+(1−p)×Tm,已知 Cache 的读写时间为 5ns,主存读写时间为 100ns,平均访问时间为 6ns,带入等式为6ns=5ns+(1−p)×100ns,求得p=1−1/100=99%。6.在 CPU 执行一段程序的过程中,共访存 1000 次,其中 Cache 命中 950 次。设 Cache 存取周期为 10ns,主存存取周期为 120ns,则 Cache - 主存系统的效率是( )。
A. 62%
B. 62.5%
C. 90%
D. 90.5%
6.【参考答案】 B
【解析】 效率 = Cache 时间 / 平均访问时间,平均访问时间= 95%×10+5%×(120+10)=16ns,效率 = 10ns/16ns=62.5%。
7.假设 Cache 的读写速度是主存的 10 倍,命中率为 90%,则使用 Cache 能使存储器的读写速度提高( )倍。
A. 9
B. 10
C. 1.19
D. 5
7.【参考答案】 D
【解析】 设主存访问时间为 1,平均访问时间 = 0.1×0.9+(1+0.1)×0.1=0.2,提高了1/0.2=5倍。8.Cache 的存储时间是 50ns,主存的存储时间是 800ns,若平均访问时间不超过 70ns,则 Cache 的命中率至少为( )。
A. 99%
B. 97.5%
C. 95.5%
D. 90%
8.【参考答案】 B
【解析】 设命中率为p,70=50×p+850×(1−p),解得p=780/800=97.5%。9.以下方法中对于提高 Cache 命中率没有效果的是( )。
A. 增加 Cache 容量
B. 增加主存容量
C. 对程序优化编译
D. 采用合适的地址映像方式
9.【参考答案】 B
【解析】 增加 Cache 容量可以减少冲突,增加命中次数,A 选项正确;增加主存容量会导致有更多的数据不能命中,即命中率下降,B 选项错误;对程序优化编译与采用合适的地址映像方式可以更好的利用空间局部性,增加命中率,C、D 选项正确。10.一台计算机有两级 Cache,在访问中依次通过两级 Cache,某程序在执行过程中访存 1000 次,其中访问第 1 级 Cache 时有 40 次不命中,接着再通过第 2 级 Cache,仍然有 10 次不命中,则总命中率是( )。
A. 99%
B. 90%
C. 96%
D. 75%
10.【参考答案】 A
【解析】 当第 1 级 Cache 未命中时,才会去访问第 2 级 Cache。当 2 级 Cache 都不命中时,才算不命中。
【解法一】 ① 第 1 级 Cache 不命中率为:100040=0.04;② 第 2 级 Cache 的 40 次访问中,有 10 次未命中,则第 2 级 Cache 的不命中率为:4010=0.25。则访问 Cache 的不命中率为:0.04×0.25=0.01,则总的命中率为:(1−0.01)×100%=99%。
【解法二】 ① 第 1 级 Cache 命中次数:1000−40=960次;② 第 2 级 Cache 对于第 1 级 Cache 未命中的部分,命中次数:40−10=30次。所以总命中次数为:960+30=990。总命中率 = 总命中次数 / 总访问次数 = 990/1000=99%。
【提示】 两级 Cache 说法比较新颖,初次接触可能感觉比较陌生,容易出错。但编者认为,此类题目代表了 408 未来的考察方向:死记硬背没用了,在掌握基础原理的基础上要会推理,灵活运用。11.某计算机主存地址 32 位,按字节编址,采用二级 Cache,L1 为数据 Cache,L2 为指令 Cache。主存块大小 64B,Cache 与主存为直接映射方式,采用写回法和随机替换策略,每个 Cache 都有 64 行,两个 Cache 大小与映射方式均相同。此二级 Cache 的容量至少有( )。
A. 8512B
B. 8544B
C. 8512bit
D. 8544bit
11.【参考答案】 B
【解析】 直接映射将 32 位主存地址分为标记、行号和块内地址。Cache 有 64 行,故行号 6 位;块大小 64B,故块内地址 6 位,所以地址划分为 20 位标记 + 6 位行号 + 6 位块内地址。每行都有有效位和脏位(写回法),故容量 =2×64×(1+1+20+64×8)=68352bit=8544B。12.某计算机主存地址 32 位,按字节编址,Cache 与主存为全相联映射方式。主存块大小为 4B,采用写回法 (Write Back) 和随机替换策略,则能存放 64KB 数据的 Cache 的总容量至少有( )位。
A. 512K
B. 1024K
C. 2048K
D. 64K
12.【参考答案】 B
【解析】 Cache 共有行行,需要有效位和脏位(写回法)两位辅助位,块内地址 4B 需要 2 位,因是全相联映射,需要32−2位标记位,故容量 =16K×(1+1+30+4×8)=16K×64=1024K。13.Cache 采用 8 路组相联映射方式,共有 64 块。若主存有 16K 块,按字节编址,主存块大小为 256B,则 Cache 标记的位数为( )。
A. 7
B. 8
C. 10
D. 11
13.【参考答案】 D
【解析】 64 块的 8 路组相联共有 8 组,故组号为 3 位;主存容量为16K×256B,位数为14+8=22位,22 位主存地址 - 3 位组号 - 8 位块内地址 = 11 位。14.在同一个 Cache 里,有 3 种映射方式可以采用,总体上发生冲突概率最小的是( )。
A. 直接映射
B. 全相联映射
C. 组相联映射
D. 都一样
14.【参考答案】 B
【解析】 直接映射映射到唯一一行,组相联映射映射到一组里的若干行,全相联映射映射到整个 Cache 所有行,映射到的行越多发生冲突概率越小,故发生冲突的概率全相联映射 < 组相联映射 < 直接映射。15.若主存按字节编址,主存块大小为 32B,Cache 共有 64 行,主存和 Cache 间采用直接映射方式,编号都从 0 开始。则主存第 2123 号单元(十进制)对应的 Cache 行号是( )。
A. 0
B. 1
C. 2
D. 3
15.【参考答案】 C
【解析】 2123 是主存的第2123/32=66块,由于 Cache 为直接映射且共有 64 行,故行号为66%64=2。16.某计算机 Cache 容量为 1KB,采用 4 路组相联映射方式,主存容量为 1MB,每个主存块大小为 32 字节,按字节编址。若 CPU 访问主存地址 819A7H 单元且 Cache 命中,则该单元位于 Cache 组号是( )。
A. 2
B. 5
C. 10
D. 13
16.【参考答案】 B
【解析】 主存容量 1MB,故主存地址有 20 位,Cache 共 32 行且 4 路组相联映射,故共 8 组。主存地址划分为标记、组号、块内地址三部分,主存地址 20 位 = 12 位标记 + 3 位组号 + 5 位块内地址,A7H=10100111B,故组号101B=5。17.假设在一个 Cache 中共有 M 块,每 K 块组成一个组,那么以下叙述正确的是( )。
A. 如果 K = 1,则该 Cache 是直接映射 Cache
B. 如果 K = 1,则该 Cache 是全相联映射 Cache
C. 如果 K = M,则该 Cache 是直接映射 Cache
D. 如果 K > 1 且 K < M,那么这是 M / K - 路的组相联映射 Cache
17.【参考答案】 A
【解析】 K=1即一组一块,即每个主存块都有唯一对应的 Cache 块,为直接映射,故 A 正确,B 错误;K=M,即所有主存块都映射一个组内,为全相联映射,C 错误;D 选项说法错误,应为K−路组相联。18.一个八路组相联 Cache 共有 64 块,主存共有 8192 块,每块 64 个字节,按字节编址,那么主存地址的标记 x、组号 y 和块内地址 z 分别是( )。
A. x = 4,y = 3,z = 6
B. x = 1,y = 6,z = 6
C. x = 10,y = 3,z = 6
D. x = 7,y = 6,z = 6
18.【参考答案】 C
【解析】 由于分为 8 组,所以组号y为3(23=8)。块大小 64B,所以块内地址z为6(26=64)。主存共 8192 块且块大小为 64B,则主存地址一共 19 位(log28192+log264=13+6=19),所以标记位x=19−3−6=10。19.命中率高且电路实现简单的 Cache 与内存映射方式的是( )。
A. 全相联映射
B. 直接映射
C. 组相联映射
D. 哈希映射
19.【参考答案】 C
【解析】 电路最简单的映射方式是直接映射,且速度快,但是容易冲突,命中率相对较低。全相联映射更为灵活,块的利用率高,不容易冲突,但是电路实现更为困难。组相联则是拥有了两者的优点,命中率高且电路相对简单。20.保持 Cache 块大小和数量不变的前提下,将 Cache 相联度提高一倍,可能会发生的是( )。
I. 减少 Cache 访问时间
II. 增加 Cache 块偏移量需要的位数
III. 减少索引需要的位数
A. I
B. II、III
C. I、II
D. II、III
20.【参考答案】 B
【解析】 Cache 访问时间是固定的,不会因为映射方式而改变,I 错误;由于块大小不变,因此块偏移量所需位数不变,II 错误;相联度为每组内的路数,相联度提高则组数减少,即组号所需位数减少,从而 III 正确。21.组相联映射和全相联映射通常适合于( )。
A. 小容量 Cache
B. 大容量 Cache
C. 小容量 ROM
D. 大容量 ROM
21.【参考答案】 A
【解析】 组相联映射组内也属于全相联,全相联的硬件电路成本较高,只适合小容量 Cache 使用,全相联为 Cache 概念,Cache 为 SRAM,与 ROM 无关,所以本题答案为 A。22.假设有一个块数为 4 的 Cache,采取全相联映射。起初 Cache 中内容为空,接下来 CPU 连续访问了以下主存块(均为十进制):1,2,3,4,5,4,2,3,5,1。当 Cache 采取 LRU 替换策略时,命中率为( )。
A. 20%
B. 30%
C. 40%
D. 50%
22.【参考答案】 C
【解析】 LRU 将最久未被访问的块替换,可以发现在第 6 次访问 4、第 7 次访问 2、第 8 次访问 3 和第 9 次访问 5 时命中,命中四次,命中率为4/10=40%。23.在不同情况下,需要采用适合的 Cache 写策略。(1) 主要运行访问密集型应用,其中包含写操作。(2) 安全性要求很高,不允许有任何数据不一致的情况发生。这两种情况中,更适合的写策略分别是( )。
A. 写回法,全写法
B. 全写法,写回法
C. 写回法,写回法
D. 全写法,全写法
23.【参考答案】 A
【解析】 (1) 写操作比较密集,写回法速度更快,更满足密集型应用的要求。(2) 全写法每次均写入主存和 Cache,能够保持数据的一致。24.关于 Cache 的全写法(写直达法)和写回法这两种写策略,以下说法正确的是( )。
I. 采用写回法时,只有在第一次写入 Cache 时需要写入主存
II. 采用全写法时,写命中时则同时写 Cache 和辅存
III. 采用写回法时,每块 Cache 都需要多加一位辅助位
A. 仅 I、III
B. 仅 II
C. 仅 III
D. I、II 和 III
24.【参考答案】 C
【解析】 III 正确;II 写命中时不写辅存而是主存;I 写入主存不在第一次写入时,而在换出时。25.写直达法可以有效地保持主存和 Cache 一致性,但是写操作将花费大量的时间,这个问题的一种解决方法是( )。
A. 采用写回机制
B. 采用写缓冲
C. 采用 victim Cache
D. 采用组相联映射
25.【参考答案】 B
【解析】 由于 CPU 与主存运行速度不匹配,所以 CPU 对主存的写操作会花费 CPU 很多时间。写回机制可以减少 CPU 写主存次数,从而达到减少 CPU 花费时间的目的,但是存在 Cache 与主存不一致的隐患,A 错;写缓冲机制为当采用写直达法时,在 CPU 与主存之间设立一个与 CPU 运行速度匹配的高速存储器,CPU 将要修改的内容写入其中,之后可以继续自己的工作,由存储控制器负责将其中的内容写入主存,无需占用 CPU 时间,从而达到减少 CPU 在写操作上花费时间的目的,B 对;victim Cache 的原理为将被换出的 Cache 块储存在一个高速的全相联 Cache 中,从而使下次访问该块时能够快速获取,该机制与减少写操作的目的无关,C 错;组相联映射是解决 Cache 硬件成本与性能的策略,与减少写操作的目的无关,D 错。26.某 16 位计算机存储器按字节编址,主存容量为 16MB,Cache 容量为 32KB,采用 4 路组相联映射方式。Cache 和主存间的块大小为 32B,请回答下列问题:
(1) 为了实现映射,主存地址应划分为哪几个字段?各字段长度分别为多少位?
(2) CPU 访问主存单元 053070H 时,可能命中的 Cache 组号是多少?所命中的 Cache 行标记字段的值是多少?
(3) 若 int 型一维数组 A 存放在主存单元 000050H 开始的连续的 4KB 空间中,CPU 依次读出数组 A 中的所有元素,此时 Cache 的命中率是多少?
(4) 相对于全写法写策略,简述写回法写策略的优点。
26.【参考答案】
(1) 组相联映射将主存划分为标记、组号和块内地址三部分。主存16MB=24位,Cache 容量32KB,块大小32B即块内地址5位,共1K行且4行一组共256组,256组 = 8位组号,Cache 标记24位主存 - 8位组号 - 5位块内地址 = 11位。
(2) 053070H=000001010011000001110000B,组号10000011B=131,Cache 标记000001010011。
(3) 000050H=000000000000000001010000B,组号0000000010B=2且不是从该块首部开始,所以占据了4KB/32B+1=129块,共4KB/4B=1K个元素,每块首部元素共 129 个未命中,(1K−129)/1K≈87.4%
(4) 写回法每次只写入 Cache,只有换出时写回主存,能明显地减少访存次数,以此提升了效率。27.设某 32 位计算机存储器按字节编址,主存容量为 16MB,Cache 的容量为 16KB,每块为 16 个字。已知 Cache 速度是主存速度的 5 倍,现要设计一个 2 路组相联的 Cache,请回答下列问题:
(1) 写出主存地址字段中各段的位数。
(2) 设 Cache 的初始为空,主存依次从 0,1,2,…,159 号字中读出 160 个字(一次读出一个字),按此次序重复读 5 次,系统的效率是多少?
(3) 该 Cache 采用 LRU 替换算法和写回法,一行 Cache 需要多少辅助位?
27.【参考答案】
(1) 一字32位 = 4B,主存容量16MB,即主存地址有24位。每块64B=6位,Cache 有16KB/64B=256行,2行一组共有128组,故组号7位。Cache 标记 = 24位主存地址 - 7位组号 - 6位块内地址 = 11位。
(2) 效率 = Cache 时间 / 平均访问时间,一块能放 16 个字,当一个字不命中时会把其所在块的 16 个字放入 Cache;由于共 160 个字不超过 Cache 容量且连续存放,所以不会覆盖之前的字。共读了 800 次,只有第一遍的 10 块开头未命中,所以命中率 = 790/800=98.75%。设 Cache 时间为t,平均访问时间 = t+0.0125×5t=1.0625t,效率 = 1/1.0625=94%
(3) 一组 2 块,LRU 位为log22=1位,有效位要 1 位,写回法要 1 位脏位,加上 Cache 标记位 11 位,共 14 位辅助位。28.设 32 位计算机的主存容量为 1GB,存储器按字节编址,Cache 容量 32KB,每块 32B,Cache 按照 4 路组相联方式组织。请回答下列问题:(1) 写出访问 Cache 时,主存的地址格式划分。
(2) 假设 CPU 访问主存地址 234567H,请说明该地址对应的组号和块内地址。
(3) 若 Cache 的每一行 (块) 有 1 位有效位,1 位修改位,不考虑替换位,则计算 Cache 存储器的总容量。
28.【参考答案】
(1) 主存容量1GB=230B,即主存地址有30位,Cache 行数 = 32KB/32B=1K,4行一组共256组,故组号有8位,块大小32B故块内地址5位,标记位 = 30位主存地址 - 8位组号 - 5位块内地址 = 17位。
(2) 234567H=001000110100010101100111B,组号00101011B=43,块内地址00111B。
(3) 容量 = 辅助位 × 行数 + 数据,已知数据为32KB,辅助位 = Cache 标记 + 1位有效位 + 1位修改位 = 19位,容量 = 19bit×1K+32KB=34.375KB。29.一个直接映射的 Cache 有 128 个字块,主机内存包含 16K 个字块,每个块有 16 个字,访问 Cache 的时间是 10ns,填充一个 Cache 字块的时间是 200ns,Cache 的初始状态为空。
(1) 如果按字寻址,请定义主存地址字段格式,给出各字段的位宽。
(2) CPU 从主存中依次读取位置 16~210 的字,循环读取 10 次,则访问 Cache 的命中率是多少?
(3) 10 次循环中,CPU 平均每次循环读取的时间是多少?
29.【参考答案】
(1) Cache 直接映射,其主存地址分为标记、行号、块内地址三部分。每个块有16个字且按字寻址,块内地址为log216=4位。Cache 共有128个块,则行号为log2128=7位。主存有16K个块,再加上块内地址4位,则主存地址共有log216K+4=18位,标记位为18−7−4=7位。主存地址格式如下:
| 标记 7 位 | Cache 行号 7 位 | 块内地址 4 位 |
(2) Cache 中每个块16个字,则地址为16的字位于第1块的第0个字,故16 - 210位置的字分别位于 Cache 的第1 - 13块。Cache 的初始状态为空,第一次循环时先访问位置为16的字,未命中,接着 Cache 会把位置16后的16个字全部放入 Cache 中,所以17 - 31的字命中。因此16、32、48、64、⋯ 、208位置的字均未命中,共13次,其他位置均命中。后面的循环由于16 - 210位置的字都已在 Cache 中,所以全都命中。故 Cache 的命中率为1−13/(195×10)=99.3%。
(3) 第一次循环 Cache 需要写入13个块,Cache 命中195−13=182次,故第一次循环时间为(200ns+10ns)×13+10ns×182=4550ns。剩下9次循环每次都访问 Cache 195次,时间为195×10ns×9=17550ns。所以10次循环的平均时间一共为(4550ns+17550ns)/10=2210ns。30.某高级语言语句 “for (i = 0 ; i < N ; i++) sum = sum + a [i];”,其中 N = 100,假定数组 a 中每个元素都是 int 类型,依次连续存放在首地址为 0x0000 0800 的内存区域中,sizeof (int)=4。运行上述代码的处理器带有一个数据区容量为 64KB 的 data Cache,其主存块大小为 256B,采用直接映射、随机替换和直写 (Write Through) 方式;可寻址的最大主存地址空间为 4GB,配置的主存容量为 2GB,按字节编址。请回答下列问题:
(1) 主存地址至少占几位?
(2) data Cache 共有多少行?主存地址如何划分?
(3) 数组 a 占用几个主存块?所存放的主存块号分别是什么?
(4) 在访问数组 a 的过程中数据的缺失率为多少?
30.【参考答案】
(1) 可寻址最大主存地址空间是4GB,所以主存地址至少log2(4G)=32位。
(2) Cache 数据区容量64KB,一块256B,故行数为64K/256=256。主存地址共32位,一块256B,故块内地址log2(256)=8位,一共256行,故行号log2(256)=8位,剩下32−8−8=16位为标记位。主存地址格式如下:
| 标记 16 位 | Cache 行号 8 位 | 块内地址 8 位 |
(3) 数组a占用100×4B=400B。需要400B/256B=1.5625,向上取整共2块。数组a的开始地址是00000800H/256=8,刚好是第8块的开始位置,所以数组a存放的主存块号为8和9。
(4) 代码中数组a的100个元素被访问且仅访问一次,且其占用了2块,所以只有在访问每块第一个元素时未命中,接着整块内容都会被调入 Cache 中,所以一共有两次未命中,缺失率为2%。31.以下是计算两个向量点积的程序段:
float dotproduct(float x[8],float y[8]){ // 函数定义:计算两个长度为8的浮点数数组的点积 // 输入:两个float数组x和y,每个数组包含8个元素 // 输出:两个数组的点积,结果为float类型 float sum = 0.0; // 初始化累加器变量sum,用于存储点积结果 int i; // 声明循环控制变量i for(i = 0; i < 8; i++) // 循环8次,依次处理数组中的每个元素 // i从0递增到7,对应数组的8个索引位置 sum += x[i] * y[i]; // 核心计算逻辑: // 1. 取出x数组和y数组中当前索引i对应的元素 // 2. 将这两个元素相乘 // 3. 将乘积累加到sum变量中 return sum; // 返回累加结果,即两个数组的点积 }请回答下列问题:
(1) 访问数组 x 和 y 的时间局部性和空间局部性如何?
(2) 假定数据 Cache 采用直接映射方式,数据区容量为 32 字节,每个主存块大小为 16 字节;编译器将变量 sum 和 i 分配在寄存器中,数组 x 存放在 0000 0040H 开始的 32 字节的连续存储区中,数组 y 则紧跟在 x 后进行存放。该程序数据访问的命中率是多少?要求说明每次访问时 Cache 的命中情况。
(3) 将上述 (2) 中的数据 Cache 改用 2 - 路组相联映射方式,Cache 采用 LRU 替换策略,块大小改为 8 字节,其他条件不变。则该程序数据访问的命中率是多少?
(4) 在上述 (2) 中条件不变的情况下,将数组 x 定义为 float [12],则数据访问的命中率是多少?31.【参考答案】
(1) 由于数组按行优先存储,所以空间局部性较好,每个元素只被访问一次,所以时间局部性较差。
(2) 由于每个主存块为16字节,则每个块可以存储4个 float 数组元素。直接映射方式,一共32/16=2行,行号1位为32位地址中的倒数第5位,起始地址00000040H位于一个块的起始位置。由于数组x需要占用物理地址中的连续的2块,因此分别对应 Cache 中的0、1行,数组y紧随其后,也对应0、1行,因此循环内的语句执行时,依次访问x与y数组的同一位置元素,将会导致 Cache 同一块中的内容不停地在x数组与y数组之间切换,比如计算到x[1]×y[1]时,原本 Cache 第0行存放的是y[0]至y[3]元素,需要先将x[0]至x[3]换入,再将y[0]至y[3]换入,因此每次访问都不会命中,命中率为0%。
(3) 二路组相联,块大小为8字节,共有2组。其他条件不变,则每个块可以存储两个数组元素,x[0] - x[1]、x[2] - x[3]依次对应0、1组以此类推,y[0] - y[1]、y[2] - y[3]也依次对应0、1组,每组可以同时容纳两个数组相同位置的两个元素,比如x[0]、x[1]和y[0]、y[1]可以分别换入到0组的0路、1路中,访问0号元素时未命中,访问1号元素均可以命中,因此命中率是50%。
(4) 数组x的大小将占据3个 Cache 块的大小,数组y占据2个。x数组中三个块对应的 Cache 行号分别为0、1、0,实际程序不会访问8 - 11号元素,y数组中两个块对应的 Cache 行号是1、0,访问同一位置的元素时,两个数组占据的 Cache 行号不冲突,则访问数组x和数组y的第0、4号元素不命中(共4次),其余的元素可以命中,命中率为12/16×100%=75%。3.6.6 真题演练
32.【2009】某计算机的 Cache 共有 16 块,采用 2 路组相联映射方式 (即每组 2 块)。每个主存块大小为 32B,按字节编址。主存 129 号单元所在主存块应装入到的 Cache 组号是( )。
A. 0
B. 1
C. 4
D. 632.【参考答案】 C
【解析】 本题考查了组相联映射的地址结构。因为 Cache 一共16行,采取二路组相联,所以有16/2=8组。Cache 块大小为32B,所以物理地址的二进制表达下的低log232=5位为块内地址,中log28=3位确定了组号,129=10000001B,可知组号为100B,即为4。33.【2009】假设某计算机的存储系统由 Cache 和主存组成,某程序执行过程中访存 1000 次,其中访问 Cache 缺失(未命中)50 次,则 Cache 的命中率是( )。
A. 5%
B. 9.5%
C. 50%
D. 95%33.【参考答案】 D
【解析】 Cache 命中率 = Cache 命中次数 / 总访问次数,总访问次数为1000次,Cache 缺失50次,则剩下950次为 Cache 命中,故命中率为950/1000×100%=95%。34.【2012】假设某计算机按字编址,Cache 有 4 个行,Cache 和主存之间交换的块大小为 1 个字。若 Cache 的内容初始为空,采用 2 路组相联映射方式和 LRU 替换策略。访问的主存地址依次为 0,4,8,2,0,6,8,6,4,8 时,命中 Cache 的次数是( )。
A. 1
B. 2
C. 3
D. 434.【参考答案】 C
【解析】 读入过程如下图所示。本题在命制过程中并非采取计算机组成原理(唐朔飞)书中描述的映射方式,而是参考蒋本珊的计组教材,因而引发分歧,考生了解其过程即可。
| 访问地址 | 0|4|8|2|0|6|8|6|4|8|
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| 第 0 组第 0 块 | 0|4|4|8|8|0|0|8|4| |
| 第 0 组第 1 块 | 0|4|8|8|0|0|8|4|8| |
| 第 1 组第 2 块 | | | | |2|2|2|2|2| |
| 第 1 组第 3 块 | | | |2|2|6|6|6|6| |35.【2014】采用指令 Cache 与数据 Cache 分离的主要目的是( )。
A. 降低 Cache 的缺失损失
B. 提高 Cache 的命中率
C. 降低 CPU 平均访存时间
D. 减少指令流水线资源冲突35.【参考答案】 D
【解析】 引入指令 Cache 与数据 Cache 的分离是为避免资源冲突。五级指令流水线中,IF 和 MEM 都会访问 Cache。但 IF 访问 Cache 是取指令,MEM 访问内存时会从 Cache 内取数据。当前指令的 MEM 和后续指令的 IF 同时在流水线上执行,会发生同时访问 Cache 的冲突(资源冲突)。若将指令 Cache 和数据 Cache 分开就能同时访问两者,不会产生冲突。引入多级 Cache 结构是为了降低单级 Cache 结构下 Cache 缺失的时间代价。36.【2015】假定主存地址是 32 位,按字节编址,主存和 Cache 之间采用直接映射方式,主存块大小为 4 个字,每字 32 位,采用回写 (Write Back) 方式,则能存放 4K 字数据的 Cache 的总容量的位数至少是( )。
A. 146K
B. 147K
C. 148K
D. 158K36.【参考答案】 C
【解析】 块大小为16B,所以块内地址占log216=4位,Cache 一共有1K行,所以 Cache 行号占log21K=10位。因为采取了直接映射方式,每个 Cache 块的 Tag 位占用32−10−4=18位,此外每个 Cache 占用1位有效位和1位脏位(因为是写回法)。所以每个 Cache 行的辅助位是18+1+1=20位,Cache 总容量为1K×(20+128)=148K。37.【2016】有如下 C 语言程序段,若数组 a 及变量 k 均为 int 型,int 型数据占 4B,数据 Cache 采用直接映射方式、数据区大小为 1KB、块大小为 16B,该程序段执行前 Cache 为空,则该程序段执行过程中访问数组 a 的 Cache 缺失率约为( )。
for (k = 0; k < 1000; k++) a[k] = a[k] + 32;A. 1.25%
B. 2.5%
C. 12.5%
D. 25%37.【参考答案】 C
【解析】 由块大小可知每个 Cache 块可存放4个数组元素,a[k]=a[k]+32分别要一次读和一次写,总共8次。而 Cache 缺失发生在第一次读过程中,所以缺失率等于1/8,即12.5%。38. 【2021】若计算机主存地址为 32 位,按字节编址,Cache 数据区大小为 32KB,主存块大小为 32B,采用直接映射方式和回写 (Write Back) 策略,则 Cache 行的位数至少是( )。
A. 270
B. 274
C. 258
D. 25738.【参考答案】A
【解析】根据题意,Cache 数据区大小为 32KB,主存块大小为 32B,Cache 数据区块数 = 数据区大小 / 块大小 = 32KB/32B = 1K = 1024 块,物理地址的低 log232=5 位为块内地址,log21024=10 位为块号,剩下高 32 - 5 - 10 = 17 为 Tag 位,每块 Cache 块拥有 17 位的 Tag 位。再加上 1 位脏位 (写回法),1 位有效位,所以单块 Cache 的位数大小为 32×8+17+1+1=275 位。
39. 【2019】某计算机的主存地址空间大小为 256MB,按字节编址。指令 Cache 和数据 Cache 分离,均有 8 个 Cache 行,每个 Cache 行大小为 64B,数据 Cache 采用直接映射方式。现有两个功能相同的程序 A 和 B,其伪代码如下:
程序 A:int a[256][256]; ... int sum_array1() { int i,j,sum=0; for(i=0;i<256;i++) for(j=0;j<256;j++) sum += a[i][j]; return sum; }程序 B:
int a[256][256]; ... int sum_array2() { int i,j,sum=0; for(j=0;j<256;j++) for(i=0;i<256;i++) sum += a[i][j]; return sum; }假定 int 类型数据用 32 位补码表示,程序编译时 i、j、sum 均分配在寄存器中,数组 a 按行优先方式存放,其首地址为 320 (十进制数)。请回答下列问题,要求说明理由或给出计算过程。
(1) 若不考虑用于 Cache 一致性维护和替换算法的控制位,则数据 Cache 的总容量为多少?
(2) 数组元素 a [0][31] 和 a [1][1] 各自所在的主存块对应的 Cache 行号分别是多少 (Cache 行号从 0 开始)?
(3) 程序 A 和 B 的数据访问命中率各是多少?哪个程序的执行时间更短?39.【参考答案】
(1) Cache 的容量包括存储矩阵和辅助位,存储矩阵的容量为 8×64=512B。辅助位包括有效位,Tag 位,一致性辅助位和替换算法辅助位。题目指出一致性辅助位和替换算法辅助位不需考虑,故考虑有效位和 Tag 位,有效位每 Cache 行 1bit,故总共 1×8/8=1B。主存空间大小为 256MB,故物理地址长度为 log2(256×220)=28 位,其中行号占用了 log28=3 位,块内地址占用了 log264=6 位,故每个 Cache 行的 Tag 位为 28 - 3 - 6 = 19 位,所有行的 Tag 位总大小为 19×8/8=19B。故 Cache 总容量为 512 + 1 + 19 = 532B。(1 分) 关于 Cache 容量的计算,可详见章末总结。
(2) 题目规定单个 int 型变量的大小为 32bit,即 4B,所以对于变量 a [i][j],其物理地址在行优先方式下为 320 + 4×(256i + j),具体到 a [0][31] 和 a [1][1] 分别计算得其物理地址为 444 和 1348,转写成二进制后,其低 log264=6 位为块内地址,中 log28=3 位为块号,分别计算得块号为 110B 和 101B,故组号分别为 6 和 5。(2 分)
(3) 程序 A 中,循环体内一共访问了 256×256=216 次主存,访问了 216×4/64=212 个 Cache 块。每次缺失仅在第一次访问该 Cache 块时发生,所以命中率为 (216−212)/216=93.75%。程序 B 中,每次访问 Cache 块都不命中,命中率为 0。因此,A 程序命中率更高,执行时间也更短。40. 【2012】假定某计算机的 CPU 主频为 80MHz,CPI 为 4,平均每条指令访存 1.5 次,主存与 Cache 之间交换的块大小为 16B,Cache 的命中率为 99%,存储器总线宽带为 32 位。请回答下列问题:
(1) 该计算机的 MIPS 数是多少?平均每秒 Cache 缺失的次数是多少?在不考虑 DMA 传送的情况下,主存带宽至少达到多少才能满足 CPU 的访存要求?
(2) 假定在 Cache 缺失的情况下访问主存时,存在 0.0005% 的缺页率,则 CPU 平均每秒产生多少次缺页异常?若页面大小为 4KB,每次缺页都需要访问磁盘,访问磁盘时 DMA 传送采用周期挪用方式,磁盘 I/O 接口的数据缓冲寄存器为 32 位,则磁盘 I/O 接口平均每秒发出的 DMA 请求次数至少是多少?
(3) CPU 和 DMA 控制器同时要求使用存储器总线时,哪个优先级更高?为什么?
(4) 为了提高性能,主存采用 4 体低位交叉存储模式,工作时每 1/4 个存储周期启动一个体。若每个体的存储周期为 50ns,则该主存能提供的最大带宽是多少?40.【参考答案】
(1) MIPS 等于单位时间内执行的百万指令数,CPU 一秒经过 80 百万个周期,而执行一个指令平均要 4 个周期,故 CPU 一秒平均能执行 20 百万个指令,即 MIPS 数等于 20。(1 分) CPU 一秒平均执行 20 百万个指令,每个指令平均要 1.5 次访存,故一秒内 CPU 访存 20×1.5=30 万次。因为 Cache 命中率为 99%,所以 30 万次访存中有 1% 为 Cache 不命中 (需要访问主存),即每秒 Cache 缺失访问主存次数为 30M×0.01=300K 次。(1 分) 每次 Cache 缺失至少要读取一个主存块,故主存带宽至少 300K×16B/s=4.8MBps。(2 分)(注意区分 MBps 与 Mbps 的区别)
(2) 每秒 300K 次 Cache 缺失 (访问主存),其中有 300K×0.0005%=1.5 次缺页。一个页面大小为 4KB,而磁盘单次能送出 32bit = 4B,故每次缺页需要请求 DMA 4KB/4B=1024 次,故每秒需要 DMA 请求 1024×1.5=1536 次。(2 分)
(3) 针对地,如果 I/O 请求被搁置过久,则可能 I/O 端口的数据会消失,所以 I/O 的存储器总线要求优先级更高。(1 分) DMA 请求作为 I/O 请求的一种,其优先级必然高于 CPU。(1 分)
(4) 当 4 体低位交叉存储器彻底流水线化以后,其单次均摊的存储周期变为原来的 1/4。而每次从主存读出的数据大小为 32bit = 4B,所以主存能提供的最大带宽为 4B/(50ns/4)=320MBps。(2 分)41. 【2013】某 32 位计算机,CPU 主频为 800MHz,Cache 命中时的 CPI 为 4,Cache 块大小为 32 字节;主存采用 8 体交叉存储方式,每个体的存储字长为 32 位、存储周期为 40ns;存储器总线宽度为 32 位,总线时钟频率为 200MHz,支持突发传送总线事务。每次读突发传送总线事务的过程包括:送首地址和命令、存储器准备数据、传送数据。每次突发传送 32 字节,传送地址或 32 位数据均需要一个总线时钟周期。请回答下列问题,要求给出理由或计算过程。
(1) CPU 和总线的时钟周期各为多少?总线的带宽(即最大数据传输率)为多少?
(2) Cache 缺失时,需要用几个读突发传送总线事务来完成一个主存块的读取?
(3) 存储器总线完成一次读突发传送总线事务所需的时间是多少?
(4) 若程序 BP 执行过程中,共执行了 100 条指令,平均每条指令需进行 1.2 次访存,Cache 缺失率为 5%,不考虑替换等开销,则 BP 的 CPU 执行时间是多少?41.【参考答案】
(1) CPU 时钟周期是主频的倒数,即 1/800MHz=1.25ns;(1 分) 总线时钟周期是总线频率倒数 1/200MHz=5ns。(1 分) 存储器总线宽度为 32bit = 4B,故总线带宽为 4B×200MHz=800MBps。(1 分)
(2) 因为 Cache 块大小为 32B,刚好等于一个突发读写操作能传输的数据的大小,所以一个突发读写操作即可完成 Cache 块的读入。(1 分)
(3) 先用 5ns 传输地址信号,之后需要启动第一个存储体 (耗时 40ns),并每隔 5ns 启动下一个存储体 (剩下 7 个),外加一个总线周期传输数据,所以总耗时为 5ns+40ns+7×5ns+5ns=85ns。(2 分)
(4) 执行时间 = Cache 命中时耗时 + Cache 未命中时读写耗时 = 指令条数 ×CPI× 时钟周期 × 命中率 + 访存次数 × 缺失率 × 缺失损失。代入得 Cache 命中时耗时为 100×4×1.25ns=500ns,Cache 未命中时读写耗时 1.2×100×5%×85ns=510ns,总时间是 500+510=1010ns。(2 分)42. 【2014】假设对于计算机 M 和程序 P 的机器代码,M 采用页式虚拟存储管理;P 开始执行时,(R1)=(R2)=0,(R6)=1000,其机器代码已调入主存但不在 Cache 中;数组 A 未调入主存,且所有数组元素均不存磁盘同一个扇区。并存储在磁盘同一个扇区。请回答下列问题并说明理由。
编号
地址
机器代码
汇编代码
注释
1
08048100H
00022080H
loops:sl R4,R2,2
(R2)<< 2 → R4
2
08048104H
00083020H
add R4,R4,R3
(R4)+(R3)→ R4
3
08048108H
83850000H
load R5,0(R4)
((R4)+0)→ R5
4
0804810CH
00250820H
add R1,R1,R5
(R1)+(R5)→ R1
5
08048110H
20420001H
add R2,R2,1
(R2)+1 → R2
6
08048114H
1446FFFAH
bnc R2,R6,loop
if(R2)!=(R6) goto loop
(1) P 执行结束时,R2 的内容是多少?
(2) M 的指令 Cache 和数据 Cache 分离。若指令 Cache 共有 16 行,Cache 和主存交换的块大小为 32 字节,则其数据区的容量是多少?若仅考虑程序段 P 的执行,则指令 Cache 的命中率为多少?
(3) P 在执行过程中,哪条指令的执行可能发生溢出异常?哪条指令的执行可能产生缺页异常?对于数组 A 的访问,需要读磁盘和 TLB 至少各多少次?
42.【参考答案】
(1) R2 存放 i,内容起初是 0,R6 内容为 1000,之后每次加 1 地递增,递增至等于 R6 后跳出循环,故最终 R2 的内容为 1000。(1 分)
(2) Cache 一共 16 行 (块),每块的数据区大小为 32B,故总大小为 16×32=512B。(1 分)log232=5,所以低 5 位为块内地址。循环体中的 6 条指令的地址除低 5 位外都相同,所以这 6 条指令都在同一 Cache 块中,所以一经装入 Cache 就再也不会缺失。一共访问了 6×1000=6000 次指令 Cache,而其中仅第一次访问时 Cache 缺失,故命中率为 5999/6000=99.98%。(2 分)
(3) 当 A [i] 中的值很大时,相加后可能超出范围,所以 4 号指令可能会发生定点数上溢。而 2 号指令与 5 号指令中的数都在已知范围内,不会超出定点数的表达范围。(2 分) 只有在访问内存的时候才有可能缺页,所以 3 号指令可能发生缺页异常。(1 分) 数组 A 中的所有元素均位于同一页,所以访问过程中仅仅需要在第一次时从辅存中调入主存。(1 分) 而 TLB 的访问次数包括第一次未找到 A [0],A [0] 放入后再重新查找一次,共计 2 次,以及剩下的 999 个数组元素的 999 次访存 (每次访存都要访问 TLB 一次),故总共 1001 次访问 TLB。(2 分)43.【2020】假定主存地址为 32 位,按字节编址,指令 Cache 和数据 Cache 与主存之间均采用 8 路组相联映射方式,直写 (Write Through) 写策略和 LRU 替换算法,主存块大小为 64B,数据区容量各为 32KB. 开始时 Cache 均为空。请回答下列问题:
(1) Cache 每一行中标记 (Tag)、LRU 位各占几位?是否有修改位?
(2) 有如下 C 语言程序段:for (k = 0; k < 1024; k++) s[k] = 2 * s[k];若数组 s 及其变量 k 均为 int 型,int 型数据占 4B,变量 k 分配在寄存器中,数组 s 在主存中的起始地址为 0080 00C0H,则该程序段执行过程中,访问数组 s 的数据 Cache 缺失次数为多少?
(3) 若 CPU 最先开始的访问操作是读取主存单元 0001 0003H 中的指令,简要说明从 Cache 中访问该指令的过程,包括 Cache 缺失处理过程。43.【参考答案】
(1) 主存块大小为 64B,所以块内地址占 log264=6 位,Cache 组数为 32KB/(64B×8)=64=26 组,采取 8 路组相联,所以每组有 64÷8=8 块,所以主存地址的高 32 - 6 - 6 = 20 位为 Tag 位,LRU 位为每块 log28=3 位;因为采取直写法 (全写法),所以不需要附设脏位。
(2) 008000C0H 的二进制表示下的低 6 位均为 0,所以这个地址位于一个主存块的起始地址,s 数组占用了 1024×4B/64B=64 个主存块,执行程序时,总是在开始读取一个新的 Cache 块时发生 Cache 缺失,所以一共缺失了 64 次。
(3) 00010003H 对应的二进制代码为:00000000000000010000000000000011B。根据第一小问分析的地址结构,从右边开始计数,第 1~6 位是块内地址 (00 0011),第 7~12 位是 Cache 组号 (0000 00),第 13~32 位是 Tag 位 (0000 0000 0000 0001 0000)。组号为 0,初始时,Cache 为空,访问会缺失。将缺失的主存块存入 Cache 第 0 组中 (组内任意一行),并同时修改 LRU 位和有效位,将 Cache 该行标记设置为:0000 0000 0000 0001 0000,再根据块内地址 (00 0011) 读取内容。3.7 虚拟存储器
主存的存储容量由于成本和工艺的原因受到种种限制,无法做得足够大。另一方面,系统程序和应用程序要求主存容量越来越大,这就产生了矛盾。我们之所以能用 4G 的主存打开一个 20G 的游戏,就是因为计算机使用了虚拟存储器,使得这些数据看似全部存进了主存里,能够随时访问这 20G 的空间,有效解决了编程空间受限的问题。同时虚拟存储器还可以使程序在设计时不用受到物理地址大小的制约。此外,现代操作系统都支持多道程序运行,因此必须让这些进程安全地共享主存。
提示:在 408 考试中,虚拟存储器常与 Cache 结合进行考察,考生需掌握从虚拟地址到取出主存信息的过程。更为详细的虚拟存储器内容,详见《操作系统》中的内存管理章节。
3.7.1 虚拟存储器的基本概念
虚拟存储器由主存储器和联机工作的辅助存储器(通常为磁盘存储器)共同组成,这两个存储器在硬件和系统软件的共同管理下工作,因此虚拟存储器处于层次化存储系统的主存-外存层。对于应用程序员,可以把它们看作是一个单一的存储器。用户编程的地址称为虚拟地址或逻辑地址,实际的主存单元地址称为实地址或物理地址。虚拟存储器可以在发生地址越界或者访问越权的情况时进行存储访问的异常处理,从而让多道程序安全地共享主存,还可以使计算机具有不小于外存的容量和接近于主存的速度,与此同时降低了成本。
在虚拟存储器中,系统需要的指令与数据会先送入磁盘,然后操作系统将当前需要的指令与数据换入主存中,剩下暂不使用的留在磁盘中。
程序运行时,CPU 通过虚地址访问主存,然后由辅助硬件找出虚拟地址和实地址之间的对应关系(即地址映射),并判断这个虚拟地址指示的存储单元内容是否已装入主存。如果已在主存中,则直接访问主存相关位置;如果不在主存中,则将数据从外存中换入主存中。如果换入时发现主存已满,则需要依照一定策略(即替换策略)将主存中特定数据换出到外存以供新数据换入主存。虚拟地址空间的大小一般由系统的编址范围决定。
Cache 是主存的缓存,使用 Cache 的目的是为了提升访问主存的速度,使用虚拟存储器的目的是为了扩展主存的空间。类似的,可以把 DRAM 构成的主存看成是磁盘存储器的缓存。因此,要实现虚拟存储器,也必须考虑交换块(即页面)大小问题、映射问题、替换问题、一致性问题等。
4.采用虚拟存储器的主要目的是( )
A. 提高主存存取速度
B. 提高外存存取速度
C. 扩大主存使用空间
D. 扩大主存存储空间4.【参考答案】C
【解析】虚拟存储器由于使用了虚拟地址,扩大了主存的空间,但没有提高任何访问速度。
DRAM 比 SRAM 大约慢 10 倍,而磁盘比 DRAM 大约慢 100000 多倍。因此,虚拟存储器每次主存未命中时(又称 “缺页”)的时间代价远大于 Cache 未命中。所以一般将页面大小设置得足够大,一般为 4KB 或 8KB 等。因为缺页处理代价大,所以虚拟存储器中一般采取全相联映射。此外磁盘读写速度很慢,故一般采取写回法。
由于虚拟存储器采取全相联映射,所以与 Cache 一样,虚拟存储器必须有办法将虚拟地址映射到物理上的主存地址或者磁盘地址。据此可将虚拟存储器分成 3 种不同类型:页式、段式和段页式。
3.7.2 页式虚拟存储器
1.页式虚拟存储器
在页式虚拟存储系统中,主存储器和虚拟地址空间都被划分成大小相等的页面,外存和主存之间按页面为单位交换信息。通常把虚拟地址空间中的页面称为虚拟页或虚页;主存空间中的页面被称为物理页或实页。虚页与实页的大小相等且都取 2 的整数幂个字(假设为 2^N 个字),虚拟地址的低 N 位划分为页内地址,剩下的高位划分为虚页号;物理地址低 N 位划分为页内地址,剩下的高位划分为实页号。虚拟地址到物理地址的转化过程中,页内地址不变,而将虚页号转化成对应的实页号。
每个进程拥有一个页表,放在主存,虚拟地址到物理地址的变换便是由页表实现的。页表的一行称为页表项,一个页表项对应了一个虚页到实页的映射。每个页表项包含了该虚页对应的实页号,以及一些控制字段:装入位(有效位)、修改位、替换控制位及其他保护位等。其中装入位确定待访问页面是否在主存中。修改位相当于 Cache 的脏位,由于虚拟存储器总采取写回法,故页表项必须包含修改位。替换位与虚存采取的替换策略有关。其他保护位与防止地址越界和访问越权等有关。
如图 3.41 所示:当 CPU 使用虚拟地址进行访存时,先根据页表基址寄存器(PTBR)在主存中找到当前进程的页表,然后根据欲访问的虚拟地址的虚页号找到页表中对应的页表项。如果页表项中的装入位为 1,则将虚页号转换成页表项中实页号,并将实页号与自己的页内地址相拼接形成物理地址,然后访问主存;若装入位为 0,则说明待访问页面不在主存中,需要操作系统进行缺页处理。
页式虚拟存储器的每页长度是固定的,页表的建立很方便,新页的调入也容易实现。但是程序的大小不可能刚好是页大小的整数倍,所以最后的一页平均会有半页空间浪费掉了,形成了内部碎片。同时,页不是逻辑上独立的实体,使程序的处理、保护和共享都比较麻烦。
提示:内部碎片处于操作系统分配的用于装载某一进程的主存区域内部或页面内部的存储区域。外部碎片指的是还没有被分配出去的主存空闲区域(不属于任何进程),由于空间过小无法满足进程的需求。
2.快表(TLB)
使用虚拟存储器时,由于要先去主存中访问页表,每次访存都至少要额外地访问主存 1 次,导致访存的时间效率下降。为此引入了快表(TLB)。TLB 利用局部性原理,将一段时间内最常用的若干页表项存储下来。当 CPU 访存时,会先在 TLB 中寻找欲访问的页表项,若找到(即 TLB 命中)则直接映射生成物理地址,否则回到主存中查询页表(相对于快表,将主存中的页表称为慢表),在查询到了页表项之后将该项换入 TLB 中。如果 TLB 相应位置满了,则需启动 TLB 的替换策略。
TLB 由 SRAM 构成,其工作原理类似于 Cache。TLB 表项由 TLB 标记和页表表项内容组成,一般采用全相联或组相联的映射方式。全相联映射下,TLB 标记就是对应表项的虚拟页号;组相联映射下,虚拟页号高位为 TLB 标记,低位为组号。不同的是快表的设立是为了加快虚拟地址转换成物理地址的速度,而 Cache 的设立是为了加快 CPU 的访存速度。此外,TLB 含有的页表项只占整个页表的一小部分,所以页表不命中时,TLB 必然不命中。而对于 Cache 而言,Cache 存储的指令或数据只占整个主存的一小部分,且页表未命中时意味着欲访问的信息不在主存里,所以页表不命中时,Cache 必然不命中。
2.下述有关 Cache 与虚拟存储器的说法中错误有( )。
I. 一次访存时,页表不命中,则 Cache 一定也不命中
II. Cache 不命中的损失要大于页表不命中的损失
III. Cache 和 TLB 缺失后的处理都可以由硬件完成
IV. 虚拟存储器的容量可以大于主存和辅存的容量之和
A. I 和 IV
B. III 和 IV
C. II 和 IV
D. I、II 和 IV2.【参考答案】C
【解析】II 页表不命中的损失要大于 Cache 不命中的损失,因为页一般远大于块大小,且缺页要从辅存存取数据,比 Cache 不命中时从主存存取数据要慢;IV 虚拟存储器的容量小于等于主存和辅存的容量之和。如表 3.5 所示,TLB、页表和 Cache 有 5 种可能的命中组合和 3 种不可能的命中组合。其中 TLB 缺失既可由硬件也可由软件处理,缺页处理由软件处理,Cache 缺失由硬件处理。这里的软件处理是由操作系统通过专门的异常处理程序来实现。
表 3.5 所有的缺失组合
序号
TLB
页表
Cache
情况是否存在
1
命中
命中
命中
存在,TLB 命中则页一定命中,在主存就可能在 Cache 中
2
命中
命中
未命中
存在,TLB 命中则页一定命中,在主存但可能不在 Cache 中
3
未命中
命中
命中
存在,TLB 缺失但页可能命中,在主存就可能在 Cache 中
4
未命中
命中
未命中
存在,TLB 缺失但页可能命中,在主存但可能不在 Cache 中
5
未命中
未命中
未命中
存在,TLB 缺失则页可能缺失,不在主存和 Cache 中
6
命中
未命中
未命中
不存在,页缺失,说明不在主存,TLB 中一定没有该页表项
7
命中
未命中
命中
不存在,页缺失,说明不在主存,TLB 中一定没有该页表项
8
未命中
未命中
命中
不存在,页缺失,说明不在主存,Cache 中一定也没有该信息
表格中序号 1 情况访存时无需访问主存;序号 2 和序号 3 情况访存时需要访问 1 次主存;序号 4 情况访存时需要访问 2 次主存;序号 5 情况访存时至少要访问 2 次主存,因为缺页中断至少要访问一次辅存。
18.【2010】下列命中组合情况中,一次访存过程中不可能发生的是( )。
A. TLB 未命中,Cache 未命中,Page 未命中
B. TLB 未命中,Cache 命中,Page 命中
C. TLB 命中,Cache 未命中,Page 命中
D. TLB 命中,Cache 命中,Page 未命中18.【参考答案】D
【解析】当页面未命中时,Cache 和 TLB 均不可能命中。可参考知识点 3.7 中表 3.5。
3.页式虚拟存储器下 CPU 访存过程
如图 3.42,展示了在全相联 TLB 和二路组相联 Cache 下 CPU 传入的虚拟地址经地址翻译后转化成物理地址并取出数据的过程。
在此结构下,获得虚拟地址后,取出高位的虚拟页号,先比较 TLB 的标记,查找是否在 TLB 中命中。若命中,则取出其页框号,也就是物理地址的物理页号,从而与页内地址组合形成真正的物理地址。若未命中,则在主存的页表中查找,若该项在页表中且装入位为 1,则其后的页框号有效,取出页框号即可形成物理地址;若装入位为 0 或该项不存在则表明该页面不在主存中,需要进行缺页处理操作,将位于外存的数据读入主存中并更新 TLB 和页表。通过以上操作,便将虚拟地址中的虚拟页号转换成物理页号以形成物理地址。接着就是上一节所讲的内容,根据具体的物理地址在 Cache 和主存里访问数据。
3.7.3 段式虚拟存储器
在段式虚拟存储系统中,段是根据程序的逻辑结构进行划分的,每个段的长度因程序而异,虚拟地址由段号和段内地址组成。操作系统为每个进程分配了一个段表,段表的一行称为段表项,该进程的每个段都对应一个段表项。每个段表项拥有该段在主存中的始地址(即段首址)和段长度以及控制字段(装入位等)。
如图 3.43 所示,当 CPU 需要访存时,CPU 先找到当前进程的段表,然后根据欲访问的虚拟地址确定段号,并找到段号对应的段表项。如果段表项中的装入位为 1 且段内地址未超过段长度,则将段首址与段内地址相加得到物理地址,然后访问主存;若装入位为 1 但段内地址超过了段长度,则触发越界异常;若装入位为 0,则说明待访问的段不在主存中,需要操作系统进行缺段处理。
不同于页表的每一页都是固定大小,段本身是程序的逻辑结构所决定的一些独立部分,因而每段不必相同,而分页对程序员来说是透明的,程序员编写程序时不需知道程序将如何分页。分段对程序员来说是不透明的;
段是逻辑上独立的实体,使程序的处理、保护和共享都比较简单。但段的长度各不相同,起点终点不确定,故段与段之间易产生较小的、无法充分利用的主存空间,即形成了外部碎片。
3.7.4 段页式虚拟存储器
在段页式虚拟存储器中,程序按模块分段,段内再分页。相同于段式虚拟存储器,操作系统为每个进程分配了一个段表,段表中每个表项对应一个段,不同的是每个段表项中包含的是一个指向该段的页表起始位置的指针,以及段其他的控制和存储保护信息。每个段拥有一个页表,由页表指明该段各页在主存中的位置以及是否装入,修改等状态信息。
当 CPU 需要访存时,CPU 先找到当前进程的段表,然后根据欲访问的虚拟地址确定段号,并找到段号对应的段表项。段表项给出了该段的页表,CPU 从虚拟地址中提取出虚页号,并从页表中找到页号对应的页表项,并得到实页号。然后实页号与页内地址拼接得到物理地址。
段页式虚拟存储器兼有分页式和分段式存储管理的优点:程序的调入调出按页进行,又可以按段实现共享和保护。但其在地址映射过程中需要多次访问主存,同时存在内部碎片和外部碎片。
3.7.5 习题精编
1.下述有关虚拟存储器的说法中错误的是( )。
A. 虚拟存储器的目的是为了给每个用户提供独立的、比较大的编程空间
B. 根据虚拟地址访存时,至少要访问两次主存
C. 用户在虚拟存储器系统中的编程空间一般都大于实际空间
D. 虚拟存储器对应用程序员是透明的1.【参考答案】B
【解析】虚拟存储器的页表或段表在主存中,但若有 TLB 和 Cache 时,在命中的情况下可以不访问主存,故 B 说法错误;虚拟存储器的容量一般为主存和辅存的容量之和,故 A、C 说法正确;虚拟存储器对系统程序员不透明,对应用程序员透明,D 说法正确。2.下述有关 Cache 与虚拟存储器的说法中错误有( )。
I. 一次访存时,页表不命中,则 Cache 一定也不命中
II. Cache 不命中的损失要大于页表不命中的损失
III. Cache 和 TLB 缺失后的处理都可以由硬件完成
IV. 虚拟存储器的容量可以大于主存和辅存的容量之和
A. I 和 IV
B. III 和 IV
C. II 和 IV
D. I、II 和 IV2.【参考答案】C
【解析】II 页表不命中的损失要大于 Cache 不命中的损失,因为页一般远大于块大小,且缺页要从辅存存取数据,比 Cache 不命中时从主存存取数据要慢;IV 虚拟存储器的容量小于等于主存和辅存的容量之和。3.下列说法中,错误的是( )
I. 虚拟存储器的容量不能超过虚拟地址的表示范围
II. 虚拟存储器加快了计算机的访存速度
III. 缺页处理发生在存储器的主存与辅存层次之间
IV. 虚拟地址的长度一般小于物理地址的长度
A. 仅 II
B. 仅 II 和 IV
C. III 和 IV
D. II 和 IV3.【参考答案】D
【解析】II 错误,虚拟存储器由于存在地址翻译的过程,因此不会加快访存速度,但是虚拟地址的长度一般都大于物理地址的长度,增大了容量,IV 错误;虚拟存储器的地址为虚拟地址,需要在虚拟地址的表示范围内,I 正确;缺页说明所需内容不在主存中而在外存中,需要去外存访问放入主存,III 正确。
4.采用虚拟存储器的主要目的是( )
A. 提高主存存取速度
B. 提高外存存取速度
C. 扩大主存使用空间
D. 扩大主存存储空间4.【参考答案】C
【解析】虚拟存储器由于使用了虚拟地址,扩大了主存的空间,但没有提高任何访问速度。
5.下列有关页式虚拟存储器的说法中正确的是( )。
A. 页面的大小由程序的逻辑结构所决定
B. 所有页面的大小都是相同的
C. 可以把一些常用的页表项放入 Cache 中
D. 程序运行前要将其全部放入主存中5.【参考答案】B
【解析】页面大小均是操作系统固定的,段大小由程序的逻辑结构所决定,故 A 说法错误;常用的页表项放入 TLB 中,故 C 说法错误;只把要使用的部分放入主存中,故 D 说法错误;页面大小是固定的,段大小不是固定的,B 正确。
6.某页式虚拟存储系统的虚拟地址为 32 位,按字节编址,一页的大小为 4KB,每个页表项为 64 位,则该页表的总容量为( )。
A. 4KB
B. 8KB
C. 4MB
D. 8MB6.【参考答案】D
【解析】虚拟地址为 32 位,即虚拟存储器有 4GB 的容量,4GB/4KB=1M个页表项,64bit×1M=64M=8MB。
7.以下是有关 TLB 的叙述,其中错误的是( )。
A. TLB 由 SRAM 构成
B. TLB 存放的是当前进程的常用页表项
C. TLB 命中时,Cache 也一定命中
D. TLB 称为快表,页表称为慢表7.【参考答案】C
【解析】TLB 为快表,由 SRAM 制成,根据局部性原理存放常用页表内容,以加快地址翻译的速度,故 A、B、D 正确。TLB 命中与 Cache 没有必然的联系,TLB 命中则页面必命中,因为 TLB 存的是页表的副本。
8.下列关于 Cache 与 TLB 的描述中,说法正确的是( )。
A. TLB 存放的是主存信息的副本
B. Cache 存放的是页表内容的副本
C. 一次访存过程中,访问 Cache 的时间早于访问 TLB 的时间
D. TLB 和 Cache 都加快了访存速度8.【参考答案】D
【解析】TLB 存的是页表的副本,Cache 存的是主存的副本,A、B 说法相反;要先经过虚拟存储器的地址翻译过程再去主存寻址,故 TLB 要早于 Cache。TLB 与 Cache 都利用了局部性原理,提高了访问速度。
9.下列命中组合情况中,一次访存过程中不可能发生的是( )。
A. TLB 未命中,Cache 未命中,Page 命中
B. TLB 未命中,Cache 命中,Page 命中
C. TLB 未命中,Cache 未命中,Page 未命中
D. TLB 未命中,Cache 命中,Page 未命中9.【参考答案】D
【解析】D 不存在,页缺失,说明信息不在主存,Cache 存的是主存信息的副本,即 Cache 内容是主存内容的子集,故 Cache 一定也没有该信息。
10.在主存地址空间大小为 16MB 的计算机中,虚拟地址空间大小为 256MB,采用页式存储管理,按字节编址。若页面大小为 64KB,TLB 采用全相联映射,其内容如下所示。
则虚拟地址 0BACC63H 的页框号是( )。
A. 1AH
B. 06H
C. TLB 缺失
D. 缺页10.【参考答案】C
【解析】主存地址空间大小为 16MB 即主存地址有 24 位,虚拟地址空间大小为 256MB 即虚存地址有 28 位。页面大小 64KB 即 16 位,虚页号 = 28 位虚拟地址 - 16 位页内地址 = 12 位,0BACC63H 的高 12 位为虚页号 0BAH,查 TLB 表的找到 0BAH,但其有效位为 0,说明不在 TLB 中,需要在页表中查找。
11.假定页表有一个控制位 C,用来表示对应页面是否可在 Cache 缓存。C = 1 表示可在 Cache 缓存,C = 0 表示不可在 Cache 缓存。以下关于虚实地址转换时对 C 进行相关处理的描述,其中错误的是( )。
A. 若装入位为 0,则无需考虑 C 的取值如何
B. 若修改位为 1,则不管 C 原来的值如何都将其清 0
C. 若 C = 0,则根据转换后的地址直接访问主存
D. 若 C = 1,则根据转换后的地址先到 Cache 中进行访问11.【参考答案】B
【解析】A 装入位为 0 表示不在主存中,故也一定不在 Cache 中,无需考虑 C;C 选项中C=0表示一定不在 Cache,故无需访问 Cache;D 选择中C=1表示可能在 Cache 中,故要先在 Cache 中查找。B 选项表示该页表项被修改过,对应的 Cache 块也会更改,故不能都清 0,要根据新 Cache 块来决定。
12.TLB,Page,Cache 这三项的缺失(Miss)、命中(Hit)组合中可以存在的为( )。
A. TLB 命中,Page 缺失,Cache 缺失
B. TLB 命中,Page 命中,Cache 缺失
C. TLB 命中,Page 缺失,Cache 命中
D. TLB 缺失,Page 缺失,Cache 命中12.【参考答案】B
【解析】TLB 命中时,Page 一定命中,Cache 可命中可不命中,故 B 存在,A、C 错误。Page 不命中时,Cache 页一定不命中,故 D 错误。
13.以下虚拟存储器中,以页为单位与主存交换信息的是( )。
I. 页式虚拟存储器
II. 段式虚拟存储器
III. 段页式虚拟存储器
A. 仅 I
B. 仅 III
C. 仅 I,III
D. I,II,III13.【参考答案】C
【解析】页式虚拟存储器以页为单位,段式虚拟存储器以段为单位,段页式虚拟存储器中程序按模块分段,段内再分页,故最后与主存交换时是以页为单位。
14.某虚拟存储系统的虚拟地址为 36 位,物理地址为 32 位,页大小 8KB,按字节编址。每个页表项都有脏位、有效位 2 个标记位共 2 位。已知当页表项大小为 1B 的倍数时能充分利用空间,请设计系统为每个进程分配的页表大小。
14.【参考答案】
页大小8KB=2^13B,所以该虚拟存储器有2^36B/8KB=2^23页。物理地址有 32 位,页内地址 13 位,故有32−13=19位物理页号。每个页表项 = 有效位 + 脏位 + 物理页号=1+1+19=21位。若以字节为单位,则需是 8 的倍数,比 21 大的最小的 8 的倍数是 24,所以页表项大小应为 24 位,即 3B。页表大小 = 页数 × 页表项=2^23页 ×3B = 24MB。
15.某计算机虚拟地址空间为 16MB,物理地址 20 位,页大小 4KB,按字节编址。下表为 TLB 内容,请根据图表内容回答以下问题:
(1) 虚拟地址可以划分成哪些字段?每个字段长度是多少?
(2) TLB 都有哪些映射方式?此计算机采用什么映射方式?
(3) 现要访问虚拟地址 549023H,01335FH,43B256H,TLB 是否命中?若命中,物理地址是多少?15.【参考答案】
(1) 虚拟地址空间为 16MB 即虚拟地址有 24 位,页大小 4KB 即页内地址 12 位,故虚页号 = 虚拟地址 24 位 - 页内地址 12 位 = 12 位。
(2) 直接映射、全相联映射和组相联映射;图中 TLB 标记位 12 位,与虚页号一样,说明没有将标记位划分出组号,故为全相联映射。
(3) 549023H:虚页号 549H,存在但有效位为 0,TLB 未命中;01335FH:虚页号 013H,存在且有效位为 1,TLB 命中,取页框号 34H,与页内地址 35FH 结合成物理地址 3435FH;43B256H:虚页号 43BH,不存在,TLB 未命中。16.某计算机按字节编址,页大小为 64KB,主存块大小 4KB。以下为 TLB 表和 Cache 表部分内容,均截取了从头开始的数据。请根据图表内容回答以下问题:
(1) 已知 TLB 有 32 行,该 TLB 采用什么映射方式?根据 TLB 映射方式划分虚页号。
(2) 虚拟存储器容量为多少?物理地址长度是多少?
(3) 已知该 Cache 不是组相联映射,则 Cache 采用什么映射方式?根据 Cache 映射方式划分物理地址。
(4) 描述根据虚拟地址 1230 1ABCH 读出其所在主存块的过程。
16.【参考答案】
(1) TLB 共 32 行,TLB 表为 2 路组,共有32/2=16组,组号 4 位,由 TLB 表可知 TLB 标记有 12 位,虚页号由 TLB 标记和组号组成,故虚页号 16 位。
(2) 页内地址 16 位,虚页号 16 位,故虚拟地址为虚页号 16 位 + 页内地址 16 位 = 32 位,虚拟存储器容量232=4GB,TLB 后面页框号 12 位,物理地址为页框号 12 位 + 页内地址 16 位 = 28 位。
(3) 物理地址 28 位,块大小4KB=12位,由 Cache 表可知 Cache 标记位 8 位,故物理地址划分成 3 部分,其中有标记、块内地址,全相联映射只划分两部分,故只能是直接映射,还有 8 位为行号。
(4) 虚拟地址 12301ABCH 的虚页号为 1230H,组号为 0,在 TLB 第 0 组,TLB 标记 123H,命中,页框号 120H。物理地址 1201ABCH,Cache 标记 12H,Cache 行号 01H,命中,根据块内地址取出数据块内容。17.某计算机有 30 位虚拟地址和 28 位物理地址,页面大小为 16KB,采用一级页表,访问页表时间为 5ns。Cache 采用直接映射,能存储 64KB 的数据,块大小为 4B,访问 Cache 时间为 5ns,主存访问时间为 50ns。访问次序为:访问页表→访问 Cache→访问内存。
(1) 已知虚拟页表有脏位 1 位,有效位 1 位,则页表大小为多少?
(2) Cache 标志位,索引位,块内地址各为多少位?
(3) 计算一次 Cache 命中访问时间,Cache 失效访问时间;当命中率为 90%,平均访问时间为多少?
(4) 系统进程切换时以下操作是否需要,请说明原因:①清除 Cache 有效位;②将已经调入页表清空。17.【参考答案】
(1) 虚拟页表标记位为 1 位脏位和 1 位有效位共 2 位,页面大小 16KB,则页内地址为 14 位,虚拟页号为30−14=16位,因此虚拟页表需要216行,每行包括脏位、有效位、页框号 14 位,共 16 位即 2B(虚页号是隐含的),所以页表大小为2B×216=217B=128KB。
(2) 块大小 4B,则块内地址为 2 位,Cache 共有64KB/4B=214行,因此索引位(行号)为 14 位,标记位=28−14−2=12位。
(3) 一次 Cache 访问时间 = 访问页表时间 + 访问 Cache 时间=5ns+5ns=10ns,一次 Cache 失效访问时间 = 访问页表时间 + 访问 Cache 时间 + 访问主存时间=5ns+5ns+50ns=60ns。已知命中率为 90%,则平均访问时间=10×90%+60×10%=15ns。
(4) ①不需要,因为 Cache 使用的是物理地址,不同进程间共用一套物理地址,无歧义产生。
②需要,因为不同进程使用不同的虚拟地址映射,所以需要重新调入页表。3.7.6 真题演练
18.【2010】下列命中组合情况中,一次访存过程中不可能发生的是( )。
A. TLB 未命中,Cache 未命中,Page 未命中
B. TLB 未命中,Cache 命中,Page 命中
C. TLB 命中,Cache 未命中,Page 命中
D. TLB 命中,Cache 命中,Page 未命中18.【参考答案】D
【解析】当页面未命中时,Cache 和 TLB 均不可能命中。可参考知识点 3.7 中表 3.5。
19.【2013】某计算机主存地址空间大小为 256MB,按字节编址。虚拟地址空间大小为 4GB,采用页式存储管理,页面大小为 4KB,TLB(快表)采用全相联映射,有 4 个页表项,内容如下表所示。则对虚拟地址 03FF180H 进行虚实地址转换的结果是( )。
A. 015 3180H
B. 003 5180H
C. TLB 缺失
D. 缺页19.【参考答案】A
【解析】页面大小为4KB=2^12B,所以虚拟地址的二进制低 12 位(即十六进制低 3 位)为页内地址,高位为虚页号。虚拟地址大小一共 32 位(4GB=2^32)所以虚页号 20 位,为 03FFFH,在快表中的第 4 行命中(虚页号相同且有效位为 1)。实页号为 0153H,替换得目标物理地址为 0153180H。
20.【2015】假定编译器将语句 “x = x + 3;” 转换为指令 “add xaddr, 3”,其中,xaddr 是 x 对应的存储单元地址。若执行该指令的计算机采用页式虚拟存储管理方式,并配有相应的 TLB,且 Cache 使用直写(Write Through)方式,则完成该指令功能需要访问主存的次数至少是( )。
A. 0
B. 1
C. 2
D. 320.【参考答案】B
【解析】该指令执行过程中,先需读取一次该地址的数值,经 add 修改后写回主存。如果读的过程中 TLB 命中且 Cache 命中,则读取过程需要 0 次访存,写的过程中因为采取全写法,需要同时写入 Cache 和主存,所以访问主存一次,对主存进行一次写操作。
21.【2019】下列关于缺页处理的叙述中,错误的是( )。
A. 缺页是在地址转换时 CPU 检测到的一种异常
B. 缺页处理由操作系统提供的缺页处理程序来完成
C. 缺页处理程序根据页故障地址从外存读入所缺失的页
D. 缺页处理完成后回到发生缺页的指令的下一条指令执行21.【参考答案】D
【解析】明显的,CPU 当前指令需要特定的数据因而缺页中断,在缺页中断后,应该将页表缺失的数据传给 CPU,供 CPU 继续执行当前指令,故 D 错误。其余三项都是缺页的正确表述。
22.【2020】下列关于 TLB 和 Cache 的叙述中,错误的是( )。
A. 命中率都与程序局部性有关
B. 缺失后都需要去访问主存
C. 缺失处理都可以由硬件实现
D. 都由 DRAM 存储器组成22.【参考答案】D
【解析】Cache 和 TLB 都可以由 SRAM 制成,其中 TLB 还可以由相联存储器制成,DRAM 主要用于制作内存。D 选项错误。A. 选项,两者都利用了空间局部性和时间局部性;B. 选项,Cache 缺失后直接访问主存对应信息,TLB 缺失后访问主存中的页表;C. 选项,Cache 和 TLB 的缺失都是由硬件完成。
23.【2009】请求分页管理系统中,假设某进程的页表内容见下表。
页面大小为 4KB,一次内存的访问时间为 100ns,一次快表(TLB)的访问时间为 10ns,处理一次缺页的平均时间为108ns (已含更新 TLB 和页表的时间),进程的驻留集大小固定为 2,采用最近最少使用置换算法(LRU)和局部淘汰策略。假设:①TLB 初始为空;②地址转换时先访问 TLB,若 TLB 未命中,则再访问页表(忽略访问页表的 Cache 更新时间);③有效位为 0 表示页面不在内存中,产生缺页中断,缺页中断处理后,返回到产生缺页中断的指令处重新执行。设有虚地址访问序列 2362H、1565H、2A5AH,请回答:
(1) 依次访问上述三个虚地址,各需多少时间?给出计算过程。
(2) 基于上述访问序列,虚地址 1565H 的物理地址是多少?请说明理由。23.【参考答案】
(1) 先分析虚拟地址的结构,因为一个页面大小为 4KB,所以虚拟地址的二进制表达下的低log2(4×2^10)=12位为页内地址,剩下的高位为虚页号。
第一次访存 2362H 时,首先进行虚拟地址到物理地址的转换。先截取高位得知虚页号为 2,查 TLB 花了 10ns,TLB 为空故未命中。再查页表访存一次花了 100ns,查慢表的页号为 2 的页表项,发现有效位为 1,故页表命中。将 2 号虚页更新进 TLB 中,同时换算得到实页号并得到物理地址。再根据物理地址成功访存(再次花了 100ns),所以总共花了10+100+100=210ns。(2 分,若算上调页时间,给 1 分)
第二次访存 1565H 时,先得到虚页号为 1,查 TLB 花了 10ns 且未命中,查主存里的慢表花了 100ns 且有效位为 0,故未命中,发生缺页中断。处理缺页中断花了108ns,这其中根据 LRU 算法将 0 号虚页占用的实页转让给 1 号虚页,并在 TLB 中加入 1 号虚页的信息。然后再次访问 TLB 以转换虚页号成实页号,因为 TLB 已经拥有了 1 号虚页的信息,所以 TLB 命中(花了 10ns)。然后访问主存,花了 100ns。所以总共花了10+100+10^8+10+100=100000220ns的时间。(2 分)
第三次访存 25A5H 时,先得到虚页号为 2,因为 2 号虚页的信息已经在 TLB 中,故 TLB 命中(花了 10ns),然后访存成功(花了 100ns)。故总共花了10+100=110ns。(2 分)
(2) 访问虚拟地址 1565H 时,因为 1 号虚页已被导入主存,且 1 号虚页抢占了原来 0 号虚页对应的实页,故现在 1 号虚页的实页号为 101H,与 1565H 的二进制表达的低 12 位相结合得到 101565H。(2 分)24.【2011】某计算机存储器按字节编址,虚拟(逻辑)地址空间大小为 16MB,主存(物理)地址空间大小为 1MB,页面大小为 4KB;Cache 采用直接映射方式,共 8 行;主存与 Cache 之间交换的块大小为 32B。系统运行到某一时刻时,页表的部分内容和 Cache 的部分内容分别如下表所示,表中页框号及标记字段的内容为十六进制形式。
请回答下列问题:
(1) 虚拟地址共几位,哪几位表示虚页号?物理地址共几位,哪几位表示页框号(物理页号)?
(2) 使用物理地址访问 Cache 时,物理地址应划分成哪几个字段?要求说明每个字段的位数及在物理地址中的位置。
(3) 虚拟地址 001C60H 所在的页面是否在主存中?若在主存中,则该虚拟地址对应的物理地址是什么?访问该地址时是否 Cache 命中?要求说明理由。
(4) 假定为该机配置一个四路组相联的 TLB 共可存放 8 个页表项,若其当前内容(十六进制)如题下表所示,则此时虚拟地址 024BACH 所在的页面是否存在主存中?要求说明理由。24.【参考答案】
(1)16MB=2^24B,所以虚拟地址位数为 24 位,页面大小为4KB=2^12B,所以低 12 位为页内地址,高24−12=12位为虚页号;(1 分) 物理地址低 12 位为页内地址,高20−12=8位为实页号。(1 分)
(2) 块大小为32=2^5B,所以块内地址占物理地址低 5 位,Cache 共 8 行,所以行号占log28=3位,剩下高20−5−3=12位为 Tag 位。(每个字段 1 分,共 3 分)
(3) 在主存中。(1 分) 虚拟地址高 12 位即虚页号,为 001H。查页表得一个页表项的虚页号为 001H 且有效位为 1。(1 分) 故页表命中并得到实页号为 04H,组合得到物理地址 04C60H。(1 分) 物理地址的低 8 位中的高 3 位为 Cache 行号,计算得为第 3 行。查 Cache 发现 Tag 位不吻合,所以 Cache 未命中。(2 分)
(4) TLB 采取 4 路组相联,一共 8 行,所以有 2 组。所以虚页号的低 1 位为 TLB 组号,高12−1=11位为 TLB 标记号。现根据虚拟地址的高 12 位的最低一位,知 TLB 组号为 0。(1 分) 同时根据虚拟地址的高 11 位知 TLB 标记号为 012H,进一步查询发现 0 组里存在一个块,其有效位为 1 且标记号为 012H,故 TLB 命中。(1 分)25.【2016】某计算机采用页式虚拟存储管理方式,按字节编址,虚拟地址为 32 位,物理地址为 24 位,页大小为 8KB;TLB 采用全相联映射;Cache 数据区大小为 64KB,按 2 路组相联方式组,主存块大小为 64B。存储访问过程的示意图如下。
请回答下列问题:
(1) 图中字段 A~G 的位数各是多少?TLB 标记字段 B 中存放的是什么信息?
(2) 将块号为 4099 的主存块装入到 Cache 中时,所映射的 Cache 组号是多少?对应的 H 字段内容是什么?
(3) Cache 缺失处理的时间开销大还是缺页处理的时间开销大?为什么?
(4) 为什么 Cache 可以采用直写策略,而修改页面内容时总是采用回写策略?25.【参考答案】
(1) 页大小为8KB=2^13B,所以D=13,易得出A=B=32−13=19,C=24−13=11。主存块大小为 64B,所以G=log264=6。Cache 数据区一共大小为 64KB,一个 Cache 块为 64B,所以总共64KB/64B=1024行,因为采取 2 路组相联,所以有1024/2=512组,所以组号F=log2512=9。E=24−9−6=9。B 存放的是虚页号。(各 1 分,共 8 分)
(2) Cache 块号由低 9 位的组号和高位的 Tag 位组成,将 4099 写成二进制 00 0001 0000 0000 0011B,所以组号等于 000000011B = 3。(1 分) 剩下的 H 字段内容为 000001000B。(1 分)
(3) Cache 缺失的代价小,缺页引发的代价大。(1 分) 因为 Cache 缺失只需访问主存,而缺页需要访问辅存。(1 分)
(4) Cache 采用直写法是同时写到 cache 和主存,而修改页面内容的话采用直写法是同时写到主存和磁盘,写磁盘的速度和写主存的速度相比,会慢很多,所以修改页面内容写回磁盘的话,采用写回策略比价合适。而 Cache 的写策略,因为写主存较快,所以可以采用直写策略。(2 分)26.【2018】某计算机采用页式虚拟存储管理方式,按字节编址。CPU 进行存储访问的过程如下图所示。
请回答下列问题:
(1) 主存物理地址占多少位?
(2) TLB 采用什么映射方式?TLB 用 SRAM 还是 DRAM 实现?
(3) Cache 采用什么映射方式?若 Cache 采用 LRU 替换算法和回写(Write Back)策略,则 Cache 每行中除数据 Data、Tag 和有效位外,还应有哪些附加位?Cache 总容量是多少?Cache 中有效位的作用是什么?
(4) 若 CPU 给出的虚拟地址为 0008 C040H,则对应的物理地址是多少?是否在 Cache 命中?说明理由,若 CPU 给出的虚拟地址为 0007 C260H,则该地址所在主存块映射到的 Cache 组号是多少?26.【参考答案】
(1) 访问 Cache 时需提供物理地址,故图中与 Cache 直接相连的结构必为物理地址,观察可知物理地址的位数是20+3+5=28位。
(2) TLB 中只有比较器,没有映射规则,所以必然为全相联映射,而全相联映射所需的相联存储器由 SRAM 制成。
(3) 因为有 2 路比较结构,且每路的 Cache 块数大于 1,所以为 2 路组相联映射,Cache 组号为 3 位,所以有23=8组。即有8×2=16个 Cache 块,每个 Cache 块拥有 20 位 Tag 位,1 位有效位,1 位脏位(因为是写回法),1 位 LRU 替换位(因为每组有 2 个 Cache 块)和2^5=32B的存储区域。所以总大小为16×(20+1+1+1+32×8)/8=558B。Cache 有效位的作用是指出对应的 Cache 行中的信息是否有效。
(4) 因为虚拟地址的二进制表示下低 12 位为页内地址,高位为虚页号,所以 0008C040H 中的 040H 为页内地址,0008CH 为虚页号,查 TLB 知对应的实页号为 0040H,所以物理地址为 0040040H;物理地址的低 5 位为 Cache 块内地址,中 3 位为组号,所以 0040040H 的对应的组号为 2,查组号为 2 的 Cache 组,发现虽然有 Tag 位对应的 Cache 行,但是有效位为 0,所以 Cache 不命中;虚拟地址的低 12 位不会因为地址映射而改变,而这低 12 位中的低 8 位的高 3 位为 Cache 组号,所以计算得为 3。27.【2019】若计算机 M 的主存地址为 32 位,采用分页存储管理方式,页大小为 4KB,则第 1 行 push 指令和第 30 行 ret 指令是否在同一页中 (说明理由)? 若指令 Cache 有 64 行,采用 4 路组相联映射方式,主存块大小为 64B,则 32 位主存地址中,哪几位表示块内地址?哪几位表示 Cache 组号?哪几位表示标记(Tag)信息?读取第 16 行 call 指令时,只可能在指令 Cache 的哪一组命中 (说明理由)?
27.【参考答案】
(1) 因为页面大小为 4KB,所以虚拟地址的低log24096=12位为页内地址,高32−12=20位为虚页号,因为这些地址的虚页号相同,所以均位于同一页中。
(2) 主存块大小为 64B,所以低log264=6位为块内地址,Cache 有 64 行,四路组相联,故有64/4=16组,组号占中log216=4位,剩下的高32−4−6=22位为 Tag 位。
(3) 因为低 12 位为页内地址,所以低 12 位 025H 在虚拟地址到物理地址的地址转换过程中不变,0000 0010 0101B 的低 10 位的高 4 位为组号,经计算可知组号为 0。28.【2021】假设计算机 M 的主存地址为 24 位,按字节编址;采用分页存储管理方式,虚拟地址为 30 位,页大小为 4KB;TLB 采用 2 路组相联方式和 LRU 替换策略,共 8 组。请回答下列问题:
(1) 虚拟地址中哪几位表示虚页号?哪几位表示页内地址?
(2) 已知访问 TLB 时虚页号高位部分用作 TLB 标记,低位部分用作 TLB 组号,M 的虚拟地址中哪几位是 TLB 标记?哪几位是 TLB 组号?
(3) 假设 TLB 初始时为空,访问的虚页号依次为 10,12,16,7,26,4,12 和 20,在此过程中,哪一个虚页号对应的 TLB 表项被替换?说明理由。
(4) 若将 M 中的虚拟地址位数增加到 32 位,则 TLB 表项的位数增加几位?28.【参考答案】
(1) 页面大小为 4KB,log24K=12,所以虚拟地址低 12 位为页内地址,高30−12=18页为虚页号。
(2) 一共 8 组,所以虚页号的低log28=3位为 TLB 组号,高18−3=15位为 TLB 标记号。
(3) TLB 组号 = 虚页号 % TLB 组数,也就是 TLB 组号为虚页号的低 3 位,如此可知映射到的 TLB 组号为 2,4,0,7,2,4,4,4,因为 TLB 为 2 路组相联,第 4 号组大于 2 次,所以只有第 4 号组可能存在替换现象,第 4 号组顺序为 12,4,12,20,加之 TLB 采取 LRU 替换算法,第 2 次访问 12 时命中,组内为 12,4,在访问 20 时,由于 12 刚被访问过,所以替换 4。
(4) 虚拟地址由虚拟块号和块内地址组成,虚拟地址的位数增加而其他参数不增加的情况下,只会引发虚拟块号增加,TLB 表项对应标记 Tag 和物理块号,标记 Tag 等于虚拟块号,所以虚拟地址增加到 32 位时,每个 TLB 块的 TLB 标记位增加 2 位,表项位数增加 2 位。3.8 从虚拟地址到主存数据
3.8.1 CPU 访存流程
从 CPU 给出一个虚拟地址开始,需要经历虚拟地址转换成物理地址和根据物理地址访问信息这两个过程,分别对应了虚拟存储器和 Cache 的工作流程。
整个访存的流程如图 3.44 所示。
首先进行将虚拟地址转换成物理地址的地址翻译过程。将虚拟地址划分成虚页号(虚拟页号)和页内地址两部分,再根据 TLB 的映射方式,从虚页号中取出 TLB 标记,以此在 TLB 中查找是否存在有该虚页号的 TLB 行。
(1)若存在,则为 TLB 命中,取出该 TLB 行中的实页号(物理页号)。
(2)若不存在,则为 TLB 未命中,直接在位于主存中的页表中查找。根据页表访问情况再做具体处理。
(3)若页表中存有该页表项且有效位为 1,则直接取出该页表项中的实页号。
(4)若页表中存在该页表项但有效位为 0,或者页表中不存在该页表项,则进行缺页处理,从外存读出一页到主存,并更新页表和 TLB。
将上述步骤中找到的实页号与页内地址拼接,形成访问内存所需的物理地址。接着需要根据物理地址在主存中访问信息。
先将物理地址根据 Cache 的映射方式进行划分,取出标记位,在 Cache 对应行里查找标记位是否一致。(1)若一致且有效,则直接取出该行数据块内容,按块内地址找到需要的信息。
(2)若不一致或有效位不为 1,则表明不在 Cache 中,需要在主存中找到该物理地址的信息,并通过替换将块写入 Cache 中。
替换时,若 Cache 中能够存放该地址的 Cache 行空闲,则直接写入 Cache 中,否则需要替换现有内容。3.8.2 CPU 访存实例
1.已知条件拆解
根据以下条件进行分析:
某计算机存储器按字节编址,虚拟(逻辑)地址空间大小为 16MB,主存(物理)地址空间大小为 1MB,页面大小为 4KB;Cache 采用 4 路组相联映射方式,共 4 组;主存与 Cache 之间交换的块大小为 32B;TLB 采用 2 路组相联映射方式,共 4 组。
(1)“存储器按字节编址”,即一个地址元能存放 1B 的信息,后续计算地址长度时,应把地址空间大小除以 1B,得出需要的地址单元数量。
(2)“虚拟(逻辑)地址空间大小为 16MB”,则虚拟地址长度应能存放 16MB/1B = 16M 个单元,组成 16M 个单元需要log2(16M)=24位,所以虚拟地址长度为 24 位。
(3)“主存(物理)地址空间大小为 1MB”,方法同 2),物理地址长度为log2(1M)=20位。
(4)“页面大小为 4KB”,因按字节编址,所以页内地址长度为log2(4K)=12位。
(5)“Cache 采用 4 路组相联映射方式”,根据映射方式,物理地址可以划分为 Cache 标记、组号、块内地址 3 部分。“共 4 组”,则组号长度为log24=2位,并可得出 Cache 一共有4×4=16行。
(6)“主存与 Cache 之间交换的块大小为 32B”,即一个 Cache 块大小为 32B,因按字节编址,一块存放 32B/1B = 32 个单元的信息,故块内地址长度为log2(32)=5位。
(7)“TLB 采用 2 路组相联映射方式,共 4 组”,根据映射方式,虚拟页号可以划分为 TLB 标记、组号 2 部分。“共 4 组”,则组号长度为log24=2位,并且还可得出 TLB 一共有2×4=8行。
(8)虚拟地址划分为虚页号和页内地址两部分,求出页内地址长度和虚拟地址长度,相减便能得出虚页号长度为24−12=12位。
(9)Cache 标记位长度为 20 位物理地址 - 2 位组号 - 5 位块内地址 = 13 位。TLB 标记位长度为 12 位虚拟页号 - 2 位组号 = 10 位。
(10)信息中涉及到了 TLB 和 Cache,表明在虚实转换过程中要先访问 TLB,在物理寻址过程中要先访问 Cache。
以上为条件中得知的所有信息。根据题意,先获得地址在各个过程中的划分情况,接着就可以根据具体数据和要求进行过程分析。
2. 过程分析
存储器信息如图 3.45 所示。
接下来根据图中数据,依次访问虚拟地址 051C60H、00CBACH、02B2CBH、00602DH 的信息。
提示:为了表示方便,图中的各表只有有效位信息。但需要注意 Cache 还会根据替换策略和一致性问题,添加脏位和 LRU 位等信息。
页式虚拟存储器将虚拟地址划分如下:
虚拟页号 12 位
页内地址 12 位
TLB 将虚拟页号划分如下:
TLB 标记 10 位
组号 2 位
Cache 将物理地址划分如下:
Cache 标记 13 位
组号 2 位
块内地址 5 位
(1) 访问虚拟地址 051C60H
(a)将虚拟地址根据进行划分:
得到虚页号 051H 和页内地址 C60H。(b)根据 TLB 映射方式,将虚拟页号 051H 进行划分:
得到 TLB 标记 00 0001 0100B 即 014H,TLB 组号为 1。(c)在 TLB 表中找到第 1 组,第 1 组的第 2 块标记为 014H,且有效位为 1,即为 TLB 命中。取其后的页框号 04H,将其与页内地址拼接,形成物理地址 04C60H。
(d)根据 Cache 映射方式,将物理地址 04C60H 进行划分:
得到 Cache 标记 0 0000 1001 1000B 即 0098H,Cache 组号为 3,块内地址为 0。(e)在 Cache 中找到第 3 组,第 3 组的第 4 块标记为 0098H,且有效位为 1,即为 Cache 命中。取其后的数据块内容,按块内地址即可找到所需的信息。
(2) 访问虚拟地址 00CBACH
(a)将虚拟地址根据进行划分:
得到虚页号 00CH 和页内地址 BACH。(b)根据 TLB 映射方式,将虚拟页号 00CH 进行划分:
得到 TLB 标记 00 0000 0011B 即 003H,TLB 组号为 0。(c)在 TLB 表中找到第 0 组,第 0 组的第 2 块标记为 003H,但有效位为 0,即 TLB 未命中。
(d)在主存中找到页表开始位置,根据其虚页号 00CH 找到对应的页表项,有效位为 1,则取其后的页框号 1CH,将其与页内地址拼接,形成物理地址 1CBACH。
(e)根据 Cache 映射方式,将物理地址 1CBACH 进行划分:
得到 Cache 标记 0 0011 1001 0111B 即 0397H,Cache 组号为 1,块内地址为 12。(f)在 Cache 中找到第 1 组,第 1 组的第 1 块标记为 0397H,且有效位为 1,即为 Cache 命中。取其后的数据块内容,按块内地址即可找到我们所需的信息。
(3) 访问虚拟地址 02B2CBH
(a)将虚拟地址根据进行划分:
得到虚页号 02BH 和页内地址 2CBH。(b)根据 TLB 映射方式,将虚拟页号 02BH 进行划分:
得到 TLB 标记 000 0000 1010B 即 00AH,TLB 组号为 3。(c)在 TLB 表中找到第 3 组,第 3 组的第 1 块标记为 00AH,且有效位为 1,即为 TLB 命中。取其后的页框号 0DH,将其与页内地址拼接,形成物理地址 0D2CBH。
(d)根据 Cache 映射方式,将物理地址 0D2CBH 进行划分:
得到 Cache 标记 0 0001 1100 0101B 即 01A5H,Cache 组号为 2,块内地址为 11。(e)第 2 组的第 3 块标记为 01A5H,且有效位为 1,即为 Cache 命中。取其后的数据块内容,按块内地址即可找到所需的信息。
(4) 访问虚拟地址 00602DH
(a) 将虚拟地址根据进行划分:
得到虚拟页号 006H 和页内地址 02DH。
(b) 根据 TLB 映射方式,将虚拟页号 006H 进行划分:
得到 TLB 标记 00 0000 0001B 即 001H,TLB 组号为 2。
(c) 在 TLB 表中找到第 2 组,第 2 组中未找到标记为 001H 的行,即为 TLB 未命中。
(d) 在主存中找到页表开始位置,根据其虚页号 006H 找到对应的页表项,有效位为 0,说明不在主存中,产生缺页中断。
(5) TLB 使用全相联映射方式
TLB 使用全相联映射方式时,虚页号全部划分为标记位,利用了全相联存储器可以按内容寻址的特性。在本题条件下,TLB 的全相联映射结构如图 3.46,可将本图替换图 3.45 的 TLB 部分自行分析其流程。
(6) Cache 使用全相联映射方式
Cache 使用全相联映射方式时,物理地址全部划分为标记和块内地址两部分,是利用了全相联存储器可以按内容寻址的特性。在本题条件下,Cache 的全相联映射结构如图 3.47,可将本图替换图 3.45 的 Cache 部分自行分析其流程。
(7) Cache 使用直接映射方式
Cache 使用直接映射方式时,物理地址全部划分为标记、行号和块内地址三部分。在查找时,可以根据行号直接确定要查找的 Cache 块所在位置。在本题条件下,Cache 的直接映射结构如图 3.48,可将本图替换图 3.45 的 Cache 部分自行分析其流程。
3.9 章末总结
本章先根据存储器的分类了解了都有哪些存储器,根据不同的分类方法有很多种不同类的存储器。
按照局部性原理,根据 “在计算机系统中的作用” 分类的存储器组成了类似金字塔的层次结构,从结构中了解其相互关系,接下来重点讲述了金字塔中的主存、外存和 Cache。按存取方式分类的存储器主要为 ROM 和 RAM,对于 RAM 详细介绍了 SRAM 与 DRAM 并对比分析,同时介绍了各种 ROM,常用的一系列存储器几乎都由这些 ROM 和 RAM 组成。
在了解主存的基本结构和与 CPU 的连接方式后,本章重点介绍了位拓展、字拓展、字节拓展这三种方法,实现了主存的拓展。为了提高主存的访问速度,引出多模块存储器,并对比分析了其中的高位交叉方式和低位交叉方式。
在外存储器中,磁盘存储器最为常用,本章介绍了磁盘的一系列性能指标。其次磁盘阵列、光存储器与固态硬盘也是生活中常见的外存储器。
为了加快 CPU 对主存的访问速度,根据局部性原理设计出了 Cache,用来存储主存的副本。从其工作原理出发,理解了 CPU 是如何在有 Cache 的情况下访问主存的。然后又讲述了直接映射、全相联映射和组相联映射这三种 Cache 与主存的映射方式,以及 Cache 因为需要换入换出而产生的替换算法和一致性问题。
此外,也讲述了虚拟存储器。先介绍为什么会有虚拟存储器,然后讲述了页式、段式、段页式三类虚拟存储器。其中页式虚拟存储器是本章的重点内容,其与 TLB 的使用通常与 Cache 进行联系,在章末也通过实例详细讲述从虚拟地址到取出主存数据的过程。
下面是对于本章开篇问题的解答。1.编址和寻址的概念和过程
若把物理内存比作成一层的教学楼,里面有排列整齐的教室,为了能快速找到每一个教室,编址就是给每个教室加一个号码,比如 112 教室。而寻址就是根据教室号找到教室的过程。
但是实际内存可以存很多单元,就相当于教室太多,一般每 8 个教室给一个号码,这种方式就类似于按字节编址。当通过这个号码寻址时,就可以找到这 8 个教室了。而按字寻址是指按照计算机字大小给号码,也就是常说的 32 位计算机和 64 位计算机,若为 32 位字长,就是每 32 个教室给一个号码。
如图 3.49 是某主存所存的信息,左侧 08048100H 为地址,里面 00H 为该地址所存的信息,一般由 2 进制或者 16 进制表示,可见其存储的大小是 2 位 16 进制,即 1B。按字节寻找时,取出其信息 00H 即可,按 32 位字寻址时,需要取出 08048100H~08048103H 连续 4 块的信息,然后再按照大端或小端的方式将这 4 块信息结合成需要的信息。
2. Cache 容量
(1) Cache 容量计算
Cache 每行实际存储的内容都是各项标记位和 Cache 块内数据。因此,关于 Cache 容量的计算,需要先分析都有什么标记项,如常见的有效位、脏位、LRU 位和 Tag 位。接着再计算 Cache 块大小,通常可以用块内地址长度计算得出。得出一行的长度后再乘以总行数,就可以得出 Cache 总容量了。
(2) Cache 容量与地址划分关系
在得到主存地址后,通过对其进行地址划分得到标记位和块内地址的划分长度,以此可以计算实际 Cache 行的标记位和数据大小。具体关系如图 3.50 所示。
3.Cache 与虚拟存储器的联系与区别
(1) 联系
(a) 都是为了提高计算机存储器的性能。
(b) 都把信息分成块,并当作存储和传输信息的基本单位。
(c) 都利用了局部性原理。都将部分数据放进速度更快的存储器中,且 Cache 和 TLB 有类似的映射方式。
(d) 命中时会提高效率,不命中时也会有对应的处理方法。
(2) 区别
(a) Cache 提高了访存的速度,虚拟存储器增大了主存的容量。
(b) Cache 以块为单位,虚拟存储器可以分页和分段,页大小一般都远大于块大小。
(c) Cache 位于 CPU 和主存中间,虚拟存储器位于主存和辅存之间。
(d) 由于主存与辅存的速度差距比 CPU 和主存的速度差距更大,虚拟存储器不命中时的代价也更大。4.Cache 与 TLB 的联系与区别
(1) 联系
(a) 层次相同。在存储器层次结构中,都属于高速缓冲存储器,处于 CPU 和主存之间。
(b) 硬件构成相同。本质都是处理器内部的一小块高速 SRAM 芯片,用于缓存。在采用全相联映射或组相联映射的情况下会使用相联存储器以加快存取速度。
(c) 映射方式相同。虽然书中只详细介绍了 Cache 的映射方式,但是 TLB 和 Cache 一样都可以采用直接映射、全相联映射和组相联映射这三种映射方式。
(d) 某种意义上讲,TLB 本质上也是 Cache,不过是只作为页表的 Cache。
(2) 区别
(a) 大小不同。Cache 用于缓存内存中的数据,容量相对较大;而 TLB 则专门缓存内存中的页表,容量相对较小。
(b) 目的侧重点不同。Cache 中存放的是数据,目的是为了提高访问速率;TLB 中存放地址转换条目,目的是提高查找效率。
(c) Cache 块内的数据既有空间局部性,又有时间局部性;而 TLB 中的页表数据只有时间局部性。5.常见缓存对比
缓存可以加快计算机对目标存储器信息的访问速度。在本章学习的各种存储器中,很多都可以用来缓存,根据存储器的作用和位置,其缓存内容也各有不同。如表 3.6 是几类本章所学的能当缓存的存储器对比。



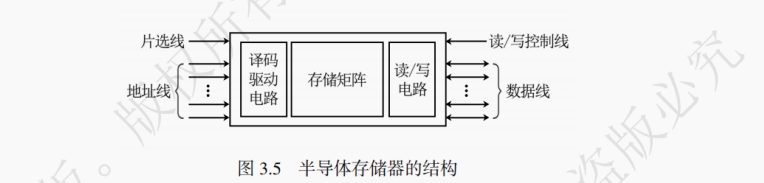
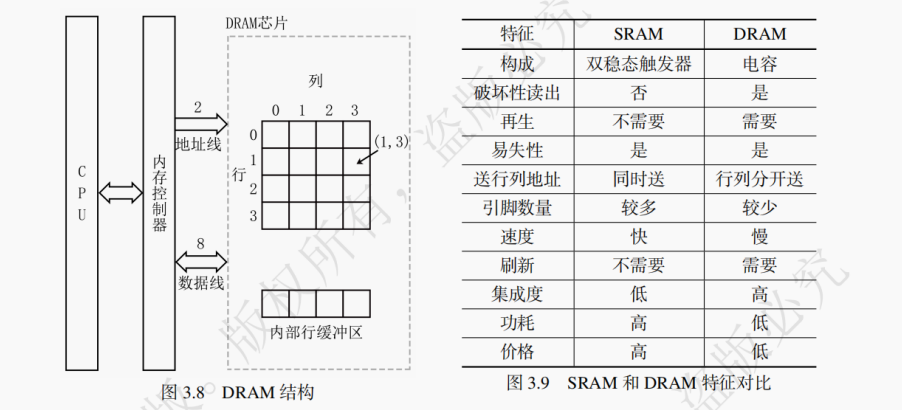
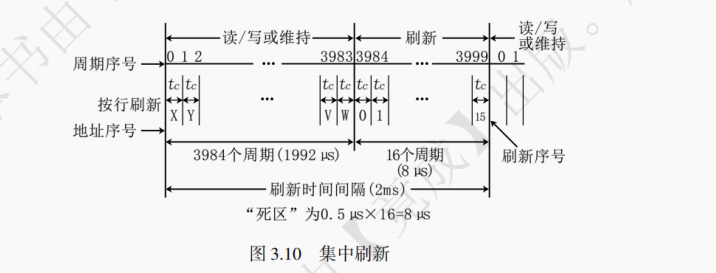
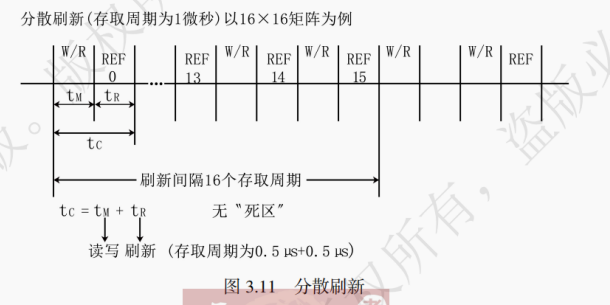

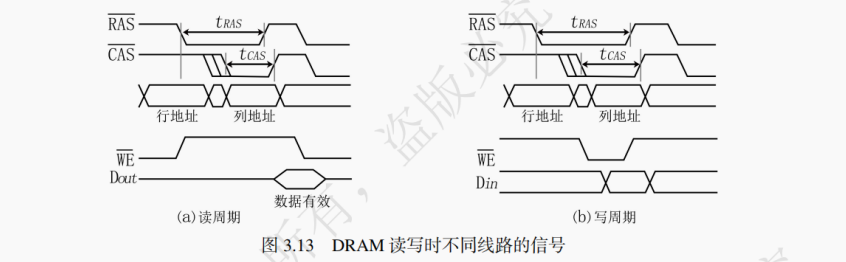

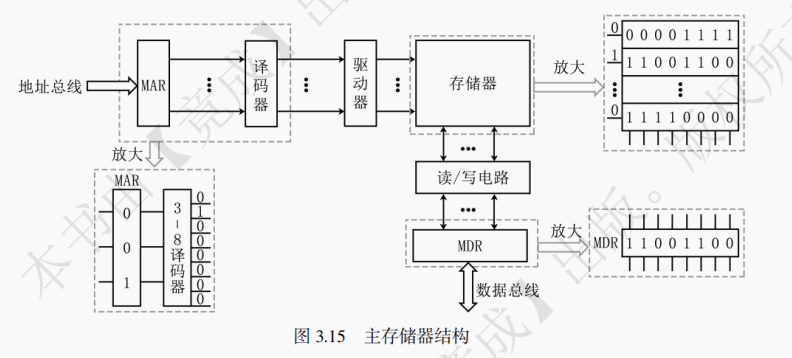
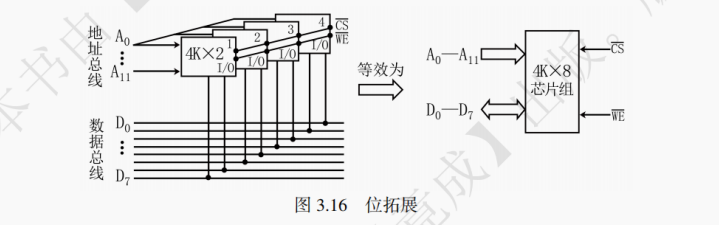
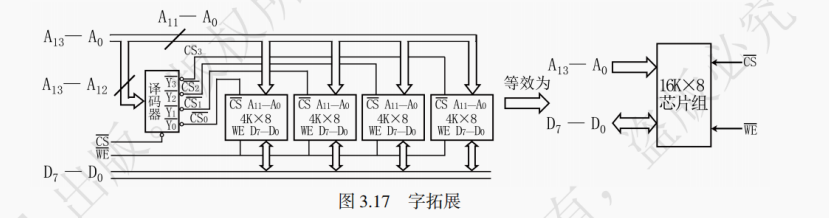
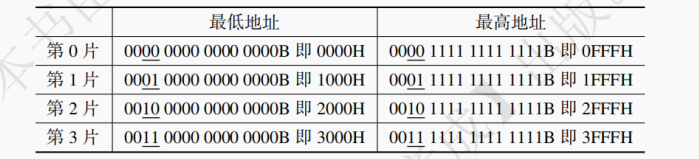
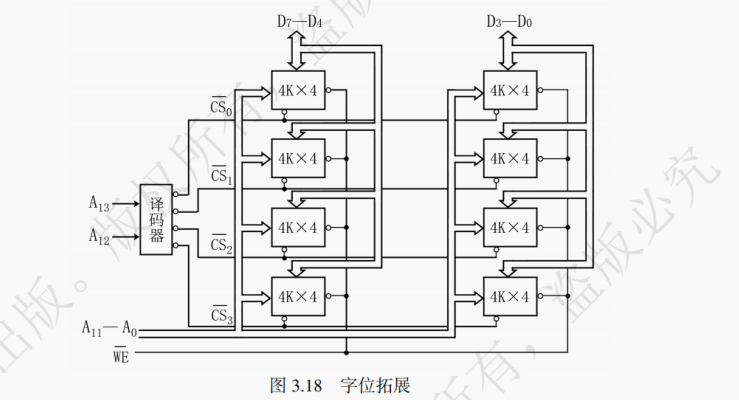
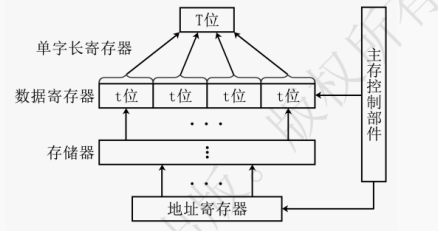
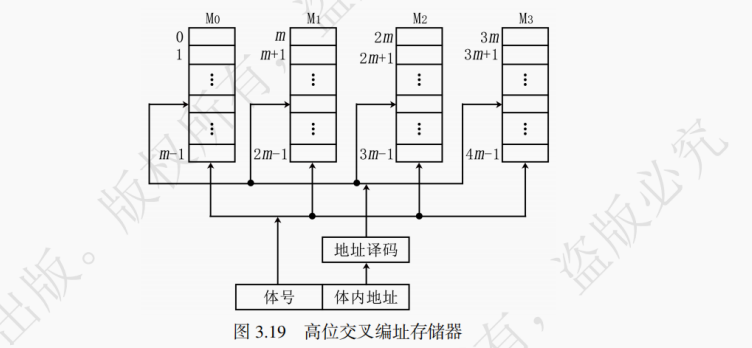
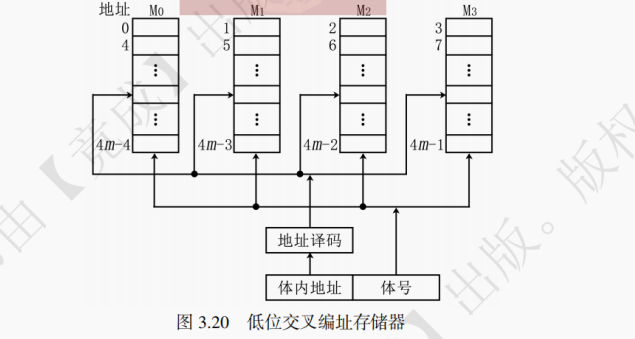
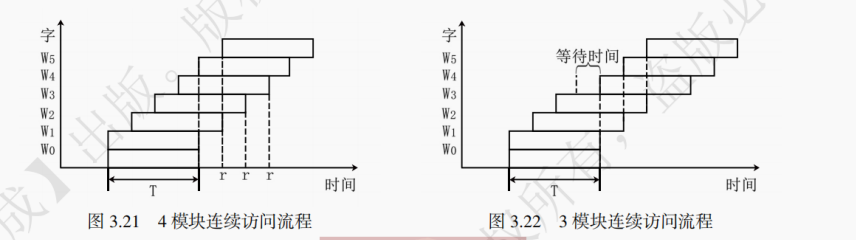
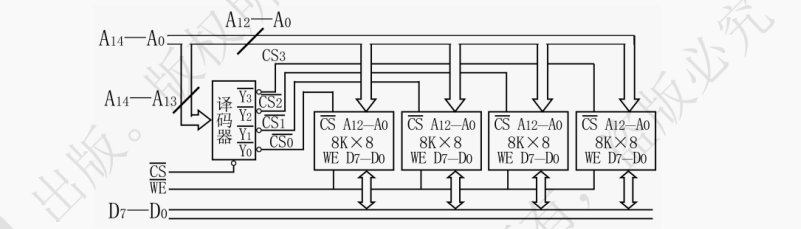
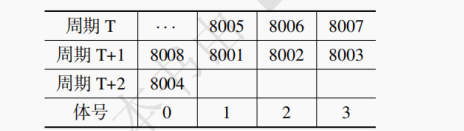
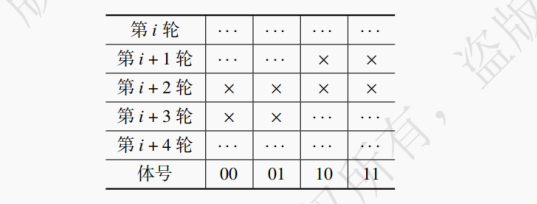
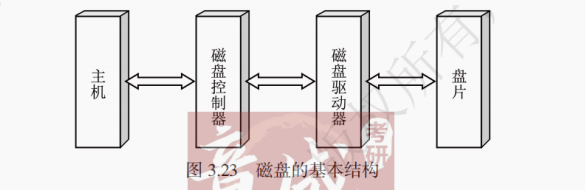
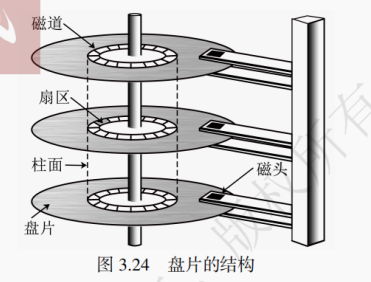

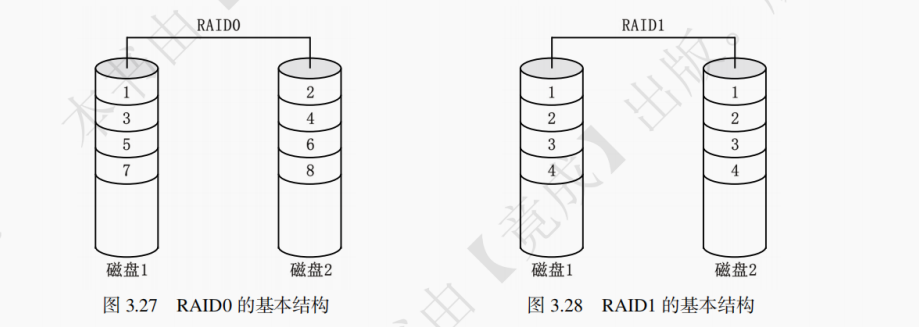
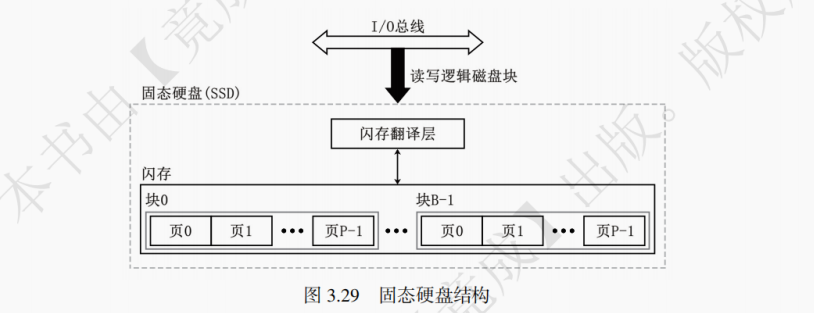
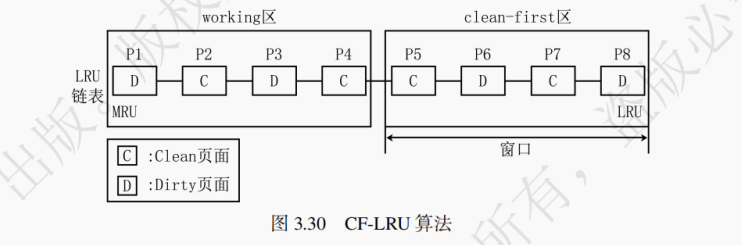
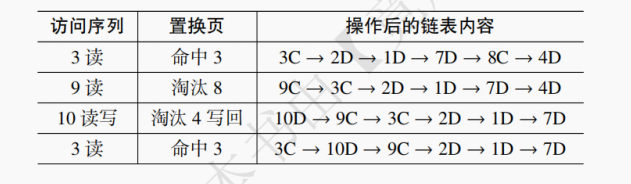

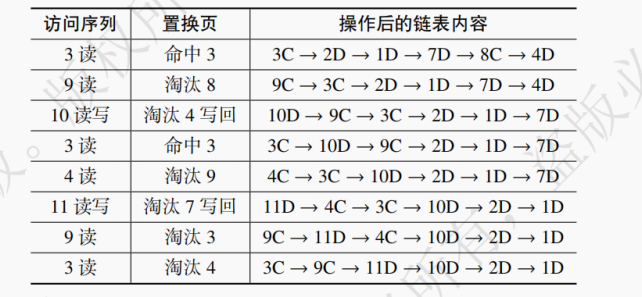
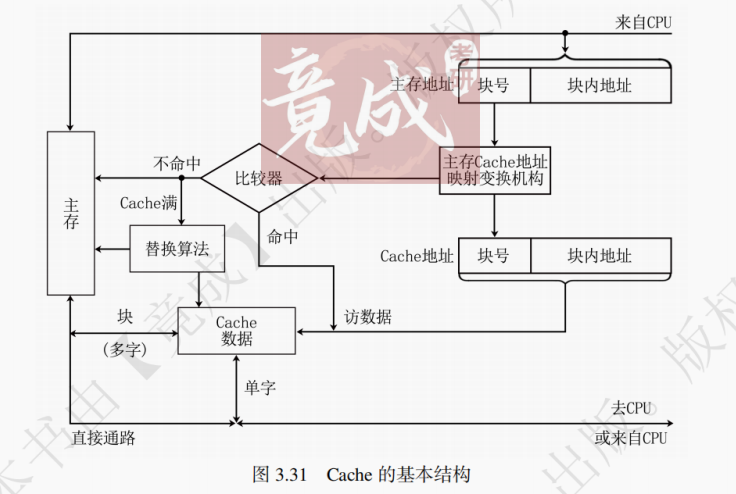


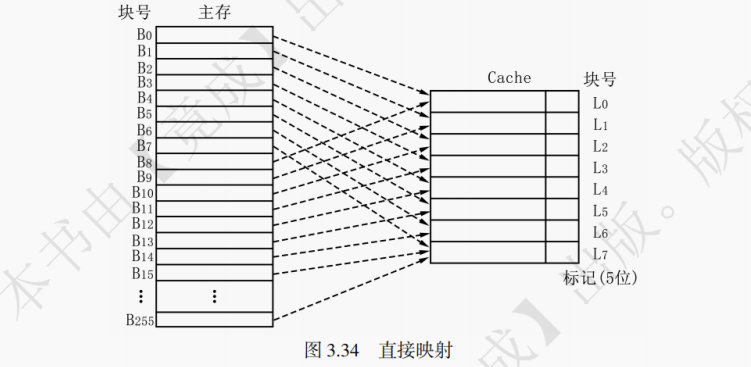
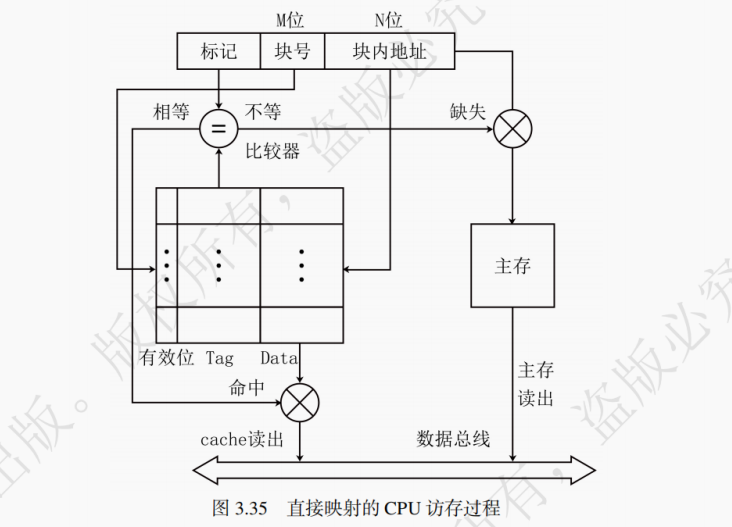
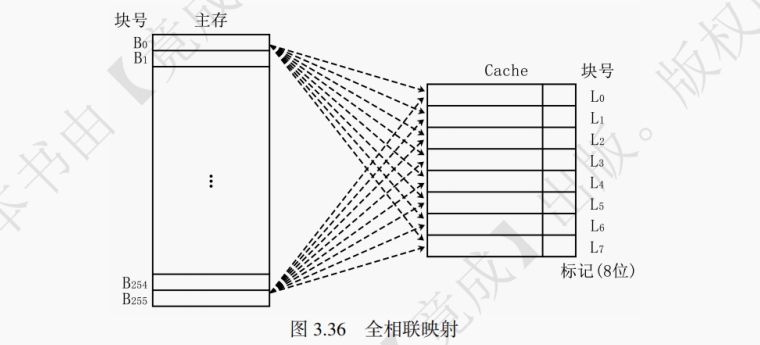

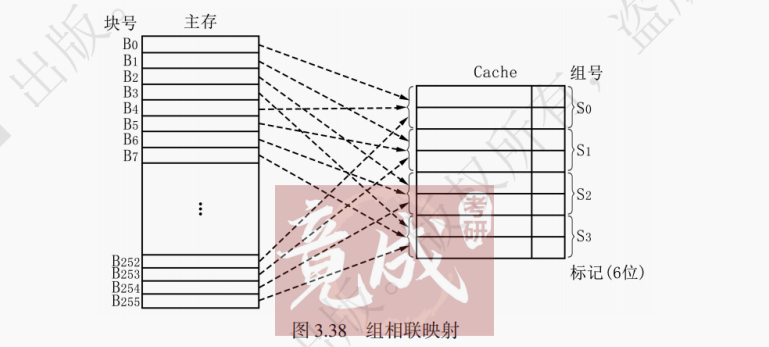

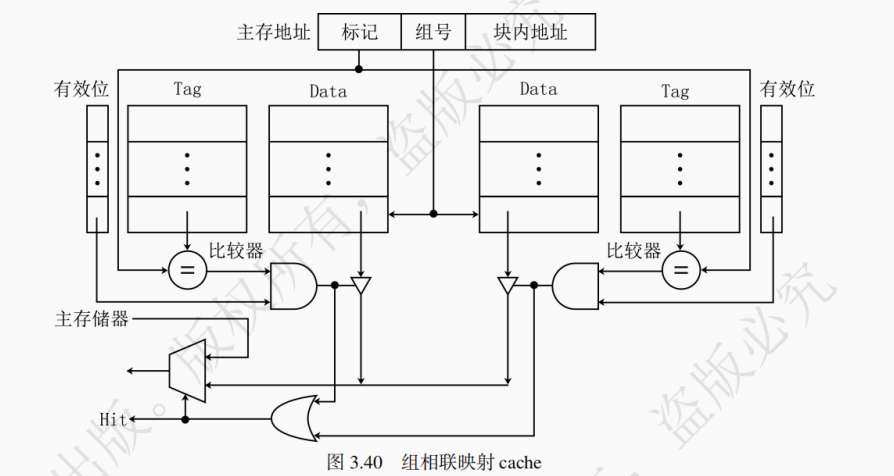

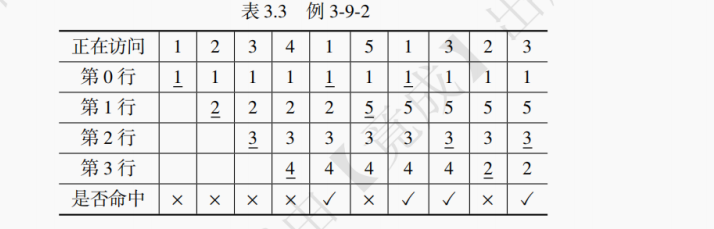

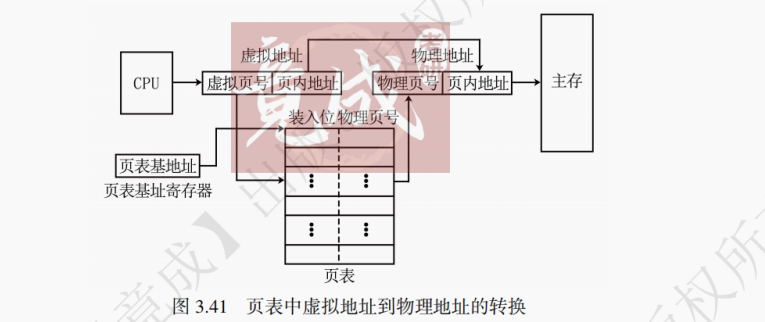
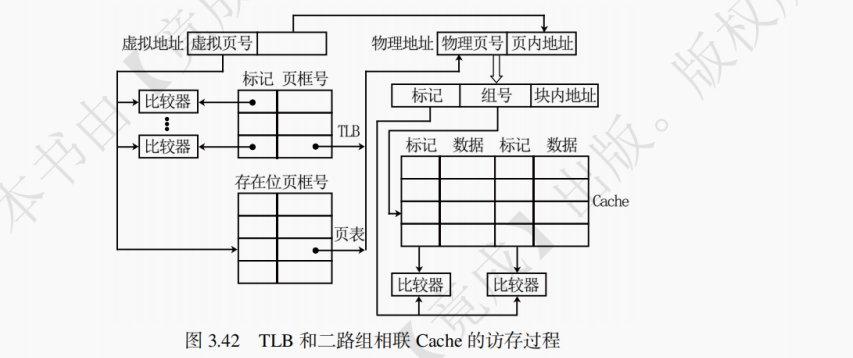
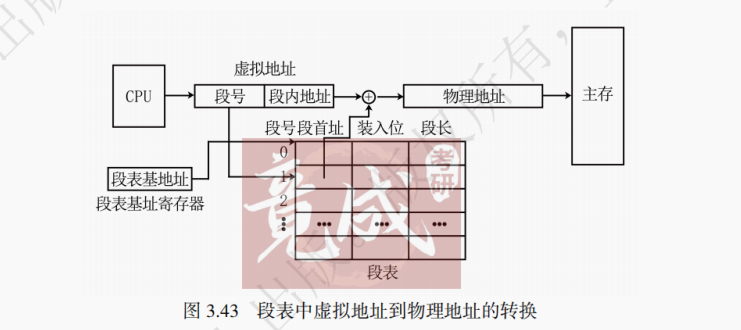

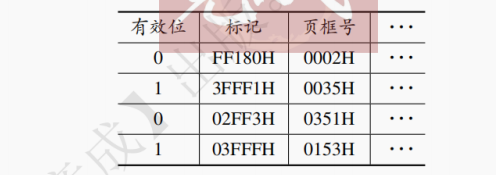


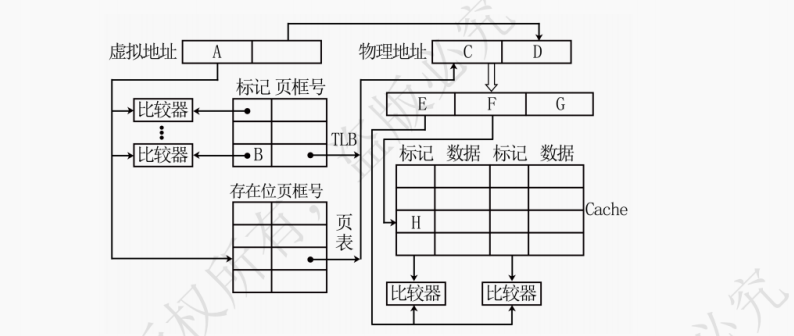
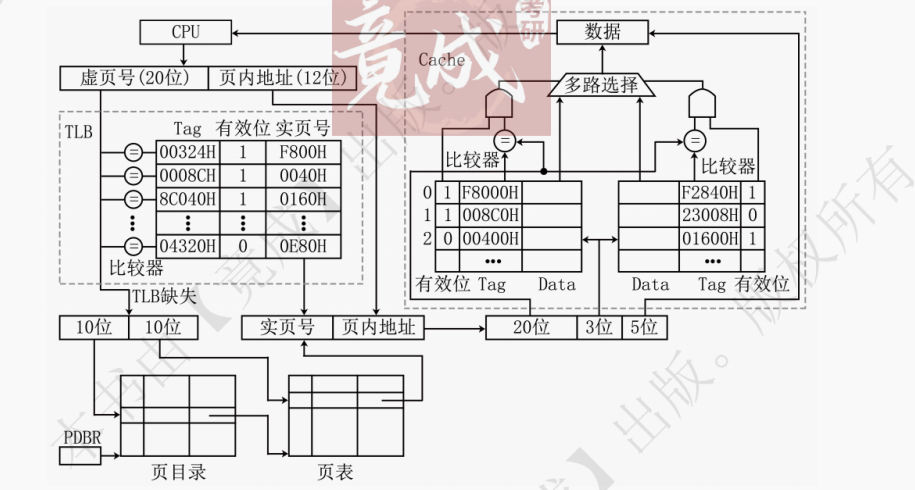
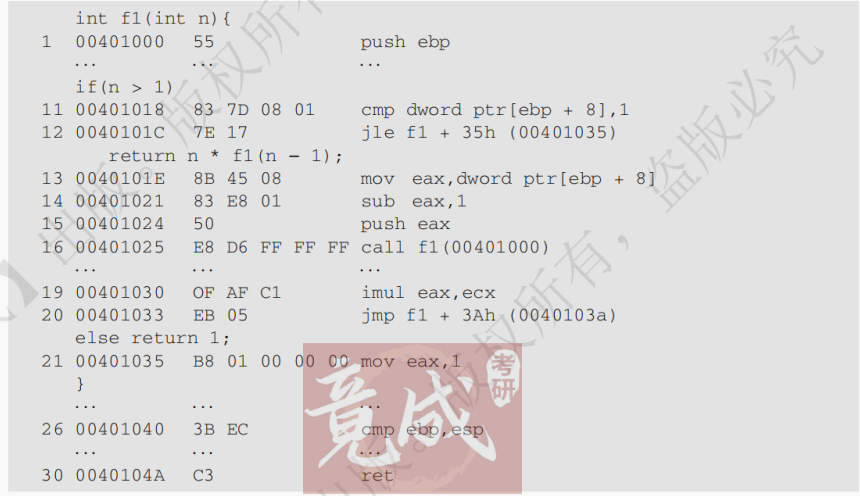
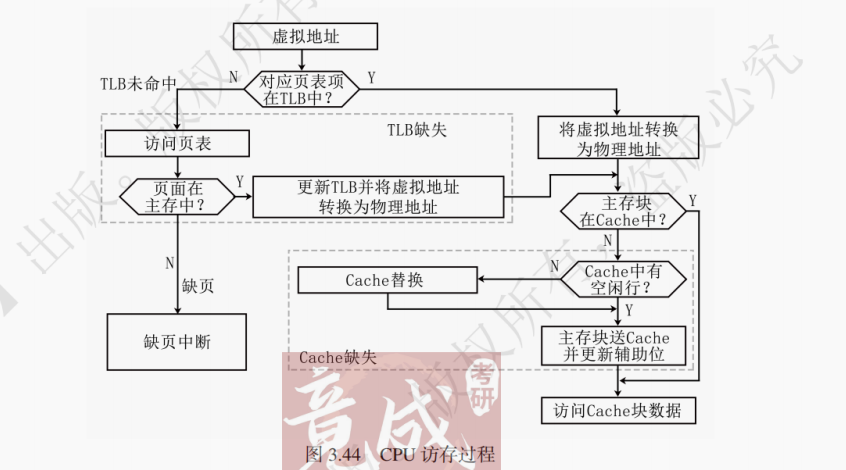
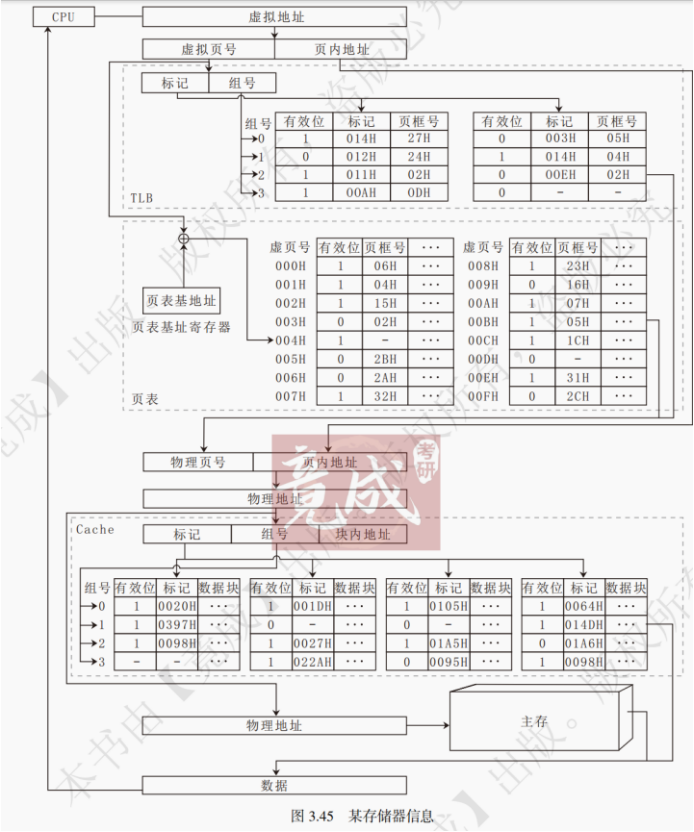











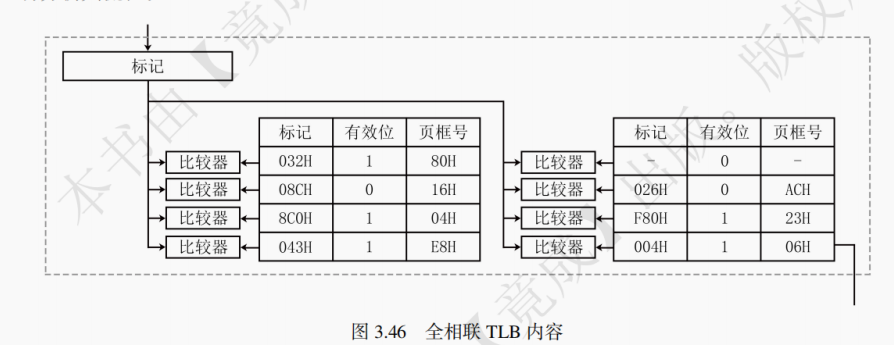
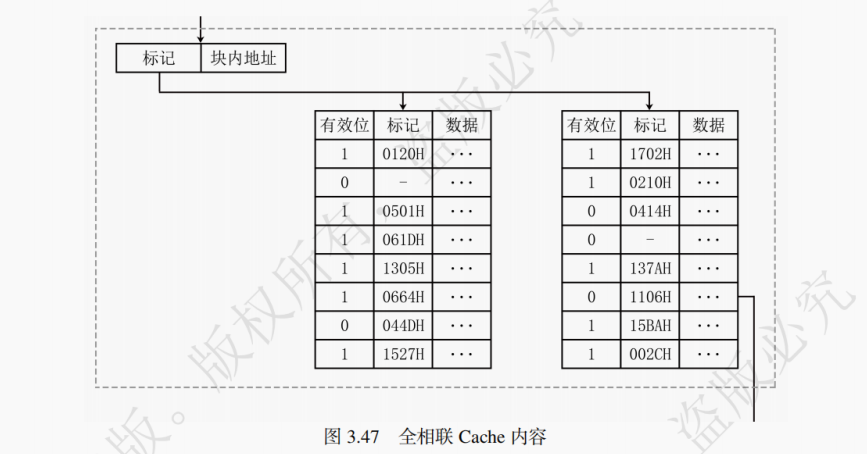
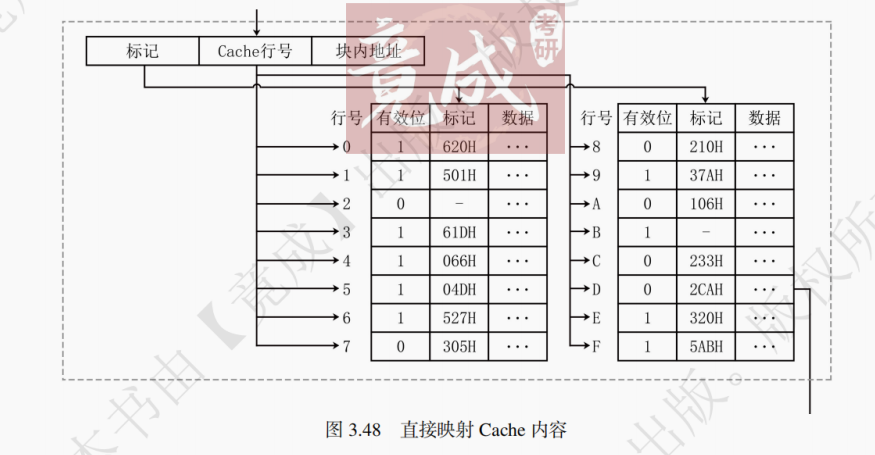
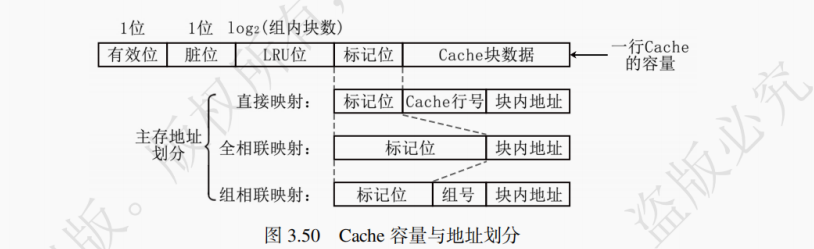
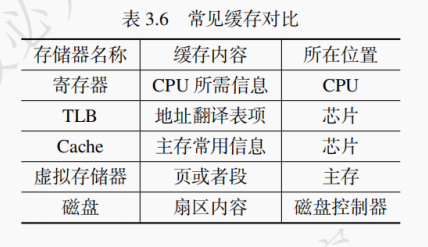

















03-22
 1851
1851
1851
08-26
1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









