







文章目录
CCNP11:组播【简介、部署原理】、组播的【IP、MAC】、IGMP【v1、v2、snooping】、CGMP、SPT树、RPT树、组播路由协议PIM的【稀疏、密集】模式
一、组播简介:
组播:又叫多播,它是网络当中很好的一种传播数据的方式,适用于大的语音流量的传输。范围是全组,但这个组可以部署于全球的任何范围,里面的组员可以分散在全球的不同范围。
当网络中进行了组播网络部署后,一台设备仅需要基于一个流量进行一个封装即可将流量转发到所有的组员处,而对非组员不产生影响。在未进行组播网络部署的环境下,以组播地址为目标IP时,流量将和广播传输方式完全一致。
我们和之前我们学过的两种数据传播方式进行比较:
| 方式 | 对象 | 范围 | 特点 |
|---|---|---|---|
| 单播 | 一对一 | 全球范围 | 一个包发给多个人,需要把这个包封装并发出多次。 |
| 广播 | 一对多 | 广播域 | 一个包发出去后,由交换机洪泛一次给其他人。 优点:节约流量 缺点:会骚扰到其它不需要该流量,需要占用他人的带宽和缓存。 |
| 组播 | 一对多 | 部署的组内 | 一个包发出后,洪泛到处于这个组中的所有人。 |
因此,综上,组播最重要的意义在于部署。
组播的优缺点:
(1)优点:占用资源极少
(2)缺点:基于UDP传输
①不可靠
②没有流控
③无序性:应用流量需要自己来排序
④一定要完全避免重复性接收同一个流量。

在可靠的四大机制当中:确认、排序、流控、重传。这四个机制当中,缺什么都最好不要缺排序,因为确认、重传、流控没有的话,对端收到消息之后,消息就有问题,可以通过校验来判定消息是否是完整的。如果对端收到全部的消息,但由于没有序列号,排序会排错,数据包就会被丢掉。
可以使用软件来对组播中的UDP包进行排序等措施。(下层不管我,上层自己来)
二、组播的部署:
向我们之前接触的RIP、OSPF等协议,都属于单播路由协议。因为这些协议所生成的路由表转发的是单播流量,让你在全球范围内一对一通。
组播的示意图很如下:这个图很经典,一定要把这张图理解了。
如果接收该组播的电脑都关机了,那么最好该组播流量就不要在占用中间的链路了。因此:
①最后一跳路由器要实时的知道与它相连的组员,是否还存在。
②与最后一跳路由器相连的交换机要基于组播转发流量。

总结一下组播部署:
组播部署:需要在第一跳路由器和最后一跳路由器之间使用组播路由协议,这样之间生成临时、唯一、最短路径。(树形结构)然后最后一跳路由器和组员间使用IGMP。
IGMP:Internet 组管理协议,用于最后一跳路由器和成员之间的互动,让最后一跳路由器知道下面的成员加了哪个组,并帮助交换机去转发组播流量。
有关名词:
First-hop:第一跳路由器
Last-hop:最后一跳路由器(叶子路由器)
三、组播(D类)的IP地址:
1、组播地址不存在子网掩码:
组播地址叫做扁平地址,没有子网掩码。之所以没有掩码是因为:掩码用于区分网络位和主机位,有无掩码直接关系到广播域。
组播是一个全球范围当中的一个组,一个IP代表一个组,广播域是一个网络号一个范围,因此组播跟广播没有任何关系。因此组播地址不需要区分网络位和主机位,就不需要掩码了,一个IP是一个范围,只能作为目标地址。
当出现类似这样的写法:224.1.1.0 255.255.255.0的时候,此时代表的意义就是一段组播地址
2、组播的IP地址:
IPv4部分的组播地址为D类,范围为224(1110 0000,24)- 239(1110 1111,24),总共2^28个IP。
(1)保留地址:
保留地址 224.0.0.0 255.255.255.0
这部分有效IP范围为:224.0.0.1~254,因此224.0.0.255就被浪费掉了。
注:限定组播传播范围可以使用TTL
| 保留地址 | 注解 |
|---|---|
| 224.0.0.0 | 基准地址(保留) |
| 224.0.0.1 | 全球所有的路由器和所有主机 |
| 224.0.0.2 | 全球所有的路由器 |
| 224.0.0.3 | 不分配 |
| 224.0.0.4 | DVMRP(距离矢量组播路由协议) |
| 224.0.0.5 | OSPF(开放式最短路径优先)路由器 |
| 224.0.0.6 | OSPF DR 指定路由器 |
| 224.0.0.7 | 共享树路由器 |
| 224.0.0.9 | RIPv2路由器 |
| 224.0.0.10 | EIGRP |
| 224.0.0.12 | DHCP服务器 |
| 224.0.0.13 | 所有PIM(组播路由协议)路由器 |
| 224.0.0.14 | RSVP(资源预留协议)封装 |
| 224.0.0.15 | 所有 CBT 路由器 |
| 224.0.0.16 | 指定 SBM(子网宽带管理)路由器 |
| 224.0.0.17 | 所有SBMS |
| 224.0.0.18 | VRRP虚拟路由冗余协议 |
| 224.0.1.39 | C-RP周期发出希望成为RP的信息 |
| 224.0.1.40 | MA宣布RP |
(2)公有地址:
公有组播IP地址为:224.0.1.0 到 238.255.255.255。
| 公有地址中存在两个特殊段: | 注解 |
|---|---|
| 232.0.0.0 到 232.255.255.255 | SSM(高阶版PIM) |
| 233.0.0.0 到 233.255.255.255 | GLOP(每申请一个AS号,赠送一段(254个)该GLOP地址) |
赠送规则:假设AS号为9949,先化为16进制为26DD
然后将26DD分为两部分:26和DD,接着再将26和DD转化为10进制就是38和221最后的结果就是:233.38.221.0(233.38.221.0-233.38.221.255)这一段作为买9949这个AS号的赠品。
理解:AS存在65535个,也就是216个,它占16位。
(3)私有地址:
私有组播IP地址为:239.0.0.0 到 239.255.255.255
(4)组播的MAC地址:
①MAC地址概述:

| 名称 | 占位 | 数值 | 作用 |
|---|---|---|---|
| Broadcast 广播位 | 1 | 一般是0,全F为1 | 用于告知交换机能否洪泛。 |
| Local 本地位 | 1 | 一般是0,标识该MAC不可擦写 若为1,标识该MAC可擦写 | 标识MAC是否可以擦写 |
| OUI 厂商标识位 | 22 | 1个OUI拥有224个MAC |
当时组播的研发者一个博士向其导师申请经费,在当时1988年花了2000美元买了1个OUI,但由于OUI太贵了,于是他的导师提出分出半个OUI用于进行其他科研项目,导致组播只有半个OUI,虽然当时组播IP没有那么多,够用,可以一个IP对应一个MAC。但是后来的IPv4分配组织,阔气的分出了整个D类送给他们用于组播。
因此需要228个IP分配到半个OUI(223个MAC)上,也就是一个MAC对应了25个IP,让32个IP共用同一个MAC。
这样就会出现一个问题,我把消息发给A组和B组,如果两个组使用的是同一个MAC的话,交换机就分不清了,路由器看IP,因此不影响,这也就成为了现在的遗憾。
现在解决这个的方案是:牺牲一下成本,利用三层交换机可以识别IP的特点,不依赖MAC区分,而是依赖IP区分。
②MAC地址详解:
组播的OUI前25位为固定位,第25位为0,为1的部分已经部分给出去了。
【01-00-53-0(第25位)】+【后23位可变】
之前我们提到了MAC地址和IP的对应关系,具体的对应关系是这样的:
组播地址的后23位 作为 组播MAC地址的后23位:

| 组播地址 | 组播MAC |
|---|---|
| 224.1.1.1 | 01-00-5e-0 0001.1.1 |
| 225.1.1.1 | 01-00-5e-0 0001.1.1 |
因此224.1.1.1和225.1.1.1两个IP的MAC地址是一样的。
四、解决叶子路由器到成员之间的问题:
1、IGMP——internet组管理协议:
(1)IGMP概述:
IGMP:该协议跨层封装,协议号为2。
工作于叶子路由器和PC之间,存在以下作用:
①帮助叶子路由器获取下方信息:是否存在设备加组,以及成员所在组的地址。
②帮助交换机基于组播转发流量。
它有1、2、3个版本,最流行的是2版。
IGMP协议不需要专门的配置,它是随着路由带出来的。
(2)IGMPv1版本:
①IGMPv1包介绍:
下面这张图片显示的是IGMP协议版本1的报头:

| 名词 | 注解 |
|---|---|
| Ver | 版本号,这里为1 |
| Type | 类型号,类型存在两个: 1:表示查询包 2:表示报告包 |
| Unused | 保留的,不拿来使用 |
| Checksum | 校验和 |
| Group Address | 组地址 |
当传输的时候,它跨层封装后就长这个样子:

②IGMPv1工作过程:
叶子路由器每隔60s向成员发查询类型号为1,源IP为叶子路由器接口的IP,目标IP时由于不知道该成员中都包含哪些路由器,因此它的目标IP为224.0.0.1(所有路由器和主机),TTL值为1(相当于发的是广播),组地址为0.0.0.0
之后里面的成员回复报告包,类型号为2,源IP为PC接口的IP地址,目标IP地址为PC所在组地址,组地址为所在组地址
| 属性\包 | 查询包 | 报告报文 |
|---|---|---|
| 源IP地址 | 路由器接口IP地址 | PC接口IP地址 |
| 目标IP地址 | 60s一周期、180s hold time、224.0.0.1、TTL=1 | 所在组地址 |
| 组地址 | 0.0.0.0 | 所在组地址 |
为什么报告包的目标IP地址不是路由器而是所在组地址呢?
因为当发送的目标IP是组地址时,除了叶子路由器之外,这个组的其它成员也能收到,最先发出的报告报文将抑制其它PC发出报告。这样叶子路由器知道了某个组是否存在组员了,没有必要所有组员均回答。
续:
电脑只要收到查询包均会使用报告包进行应答。若叶子路由器连续发出3次询问(180s),均没有成员应答,那么该叶子路由器会将自己的缓存信息删掉,然后向第一跳方向的路由器告知其没有成员在使用该组播了,最后这些路由器将流量裁剪。
当之后如果有新成员加入该组播的时候,该成员会重新发出报告报文。叶子路由器会被重新激活,继续向第一跳方向的路由器询问流量。
注:若在同一广播域中最后一跳路由器可以存在多个,那么它们中只能有一台作为查询者,在IGMP v1 中利用了PIM选举的DR来作为查询者,接口IP地址最大者为DR。
③IGMPv1的缺点:
Ⅰ、因为V1的hold time 为180s,因此当不存在组播成员的时候,它会占用180s的信道。
Ⅱ、V1版本的响应单位是以秒为单位的,响应速度会非常的慢。因此即使包封装完成之后,也需要等待下一个秒到了才可以发出。
(3)IGMPv2版本:
①IGMPv1报头:
基于版本1的缺陷,有了版本2,它的报头长下面这个样子:

| 名称 | 注解 |
|---|---|
| Type 类型号 | 0x11:查询包 0x12:版本1报告包 0x16:版本2报告包 0x17:离组包 |
| Max Resp Time | 最大响应时间,默认为0.1 |
| Checksum | 校验和 |
| Group Address | 组播IP地址 |
封装和V1一样,没有什么差别。
| 包的种类\IP | 源IP | 目标IP | 组地址 |
|---|---|---|---|
| 查询包 | 路由器接口IP | 224.0.0.1、TTL=1 | 0.0.0.0 |
| 报告包 | PC接口IP | 所在组IP | 所在组IP |
| 离组包 | PC接口IP | 224.0.0.2、TTL=1 | 所离组IP |
| 指定组查询包 | 路由接口IP | 指定组地址 | 指定组地址 |
②IGMPv2工作过程:
正常查询和报告机制同v1一致,v2中若某一个组中某台PC离开某个组,那么这台PC会向最后一跳路由器发出一个离组报文,之后叶子路由器将马上针对该组发出指定组查询包,询问该组是否还有成员。若3s内没有成员回应,那么删除该组信息。
注:IGMPv2中查询者同v1的功能是一样的,但选举方式不同。路由器接口IP地址最小的叶子路由器为查询者,当一个查询者失效后,需要120s另一台设备才会发出查询包
选择最小的原因是因为和IGMPv1错开。
(4)IGMPv2的配置:
配置:若在一台路由器的接口上运行了组播路由协议,那么该接口的IGMP协议也被开启。
规则:
①默认设备不支持组播路由功能,若需要运行组播路由协议,必须先开启组播路由功能。
R1(config)#ip multicast-routing
②在接口上运行组播路由协议来激活IGMP:
R1(config)#int f0/0
R1(config-if)#ip pim sparse-mode
如果需要查看某个接口上运行的 IGMP 协议,可以使用如下命令:
R1#show ip igmp interface f0/0
③用户加组:PC端开启软件即可,路由器可以使用命令来加入。
R3(config)#interface f0/0
R3(config-if)#ip igmp join-group 224.1.1.1
查看 IGMP 有哪些组:
R2#show ip igmp groups
(5)IGMP协同交换机基于组播流量生成转发列表:
交换机必须为多层交换机,二层交换机、透明交换机只能对流量进行洪泛。
IGMP snooping:
IGMP snooping为公有协议,工作于叶子路由器和PC之间,在三层交换机上配置(若该设备支持,将默认开启),三层交换机在窥探PC向路由器发出报告报文,然后将其所加入组IP地址和接口绑定,生成记录列表。
只有当流量的目标MAC地址为组播MAC时,才会窥探。

//开启IGMPsnooping协议
sw(config)#ip igmp snooping
2、CGMP——Cisco组成员关系协议:
该协议需要路由器和交换机协同工作,路由器将PC返回的IGMP报告报文中的PC源MAC地址和所在组MAC地址进行绑定,然后将该表下放给交换机,交换机将根据该数据流中的目标组MAC来找到对应的PC MAC和接口。
注:由于组播MAC地址不精确,32个IP共用同一个MAC地址,可能导致发出组播流量到错位的目标。
建议在使用CGMP协议时,网络中的组播地址后23位尽量不一致,来避免错误转发组播流量的情况。

3、两协议的对比:
| 协议 | 设备要求 | 工作原理 |
|---|---|---|
| IGMP snooping | 三层交换机 | 基于IP |
| CGMP | 基于MAC (二层交换机可以做到) | 路由器帮助交换机 |
五、组播路由协议:用于第一跳路由器 到 最后一跳路由器
组播路由协议:在第一跳路由器和存在组员的叶子路由器之间生成 临时、唯一、最短(不一定),也就是一颗树形结构。中间的路由器存在一张组播路由表,这些表保证了源到每个组员只有1条最佳路径,不能出现重复性流量。
1、避免重复性流量的机制:
为了避免流量的重复性,所有的组播路由协议均存在一些机制来避免重复性的流量,有以下3种机制:
RPF反向校验、声明、树形结构
(1)RPF反向校验:
RPF反向校验:用于一台路由器同时从多个接口接收到同一组播流量时,只选举出最佳的一个入接口,这个接口也被称作是RPF接口。
例如上图:假设一台路由器接收到一个组播流量,该流量从F0/0口进入,其源IP地址位12.1.1.1/24,那么本地的单播路由表必须要有到达12.1.1.1 网段的路由条目,且该条目的出接口为F0/0口,那么F0/0口便满足了反向校验规则。

当多个接口均满足反向校验规则时,将进行选举,因为一台路由器基于一个源只能存在一个RPF接口。
选举规则:
1、较小的AD(管理距离):比较该接口到源的管理(因为能加表,说明管理距离是一样的)
2、较小的度量:针对EIGRP的非等开销负载均衡
3、较大的接口IP地址
若一台路由器到达源为负责均衡,那么默认选举的路径可能不是管理员希望的路由,可以使用静态组播路由协议来变更。可以实现负载分担,不同的源将流量通过不同的接口传入。前提是这些接口均满足RPF规则。
//点到点网络:告诉R4 1.1.1.1 255.255.255.255为组播源IP,它会从自己的S1/1口进入。
R4(config)#ip mroute 1.1.1.1 255.255.255.255 serial 1/1
//MA网络中:34.1.1.2 为上一跳写法
R4(config)#ip mroute 2.2.2.2 255.255.255.255 34.1.1.2

(2)声明机制:
上面我们说到RPF的反向校验入向接口只有一个,但是它的出向接口就不一定只有一个了。
比如说这样:
声明机制:在MA网络中会遇到本地一个RPF接口对应多个流量发出接口(上一跳)。此时需要在这些出接口中选择唯一的一个出接口来发出流量。

这个机制比的就是哪个接口离源更近。
如果在一个网段内基于一个源地址只能存在唯一的流量出口,那么将比较这些接口到达源:
①较小AD(说明是不同的路由协议,使用不同的路由协议到源的距离相等,这种概率比较低)
②接口到源的最小度量
③较大接口IP地址
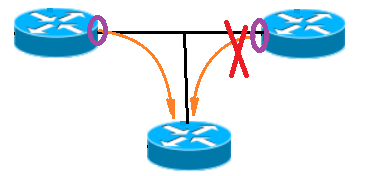
总结一下:
入接口是一个设备一个,出接口是一个网段一个。有了这两个机制入向和出向是唯一的。
(3)树型结构:
①SPT树:
SPT树,也就是最短路径树,或者源树,源到接收者最短路径。中间的每台路由器会生成这样一个表(S ,G ),S代表源,G代表组。也就是每台路由器都知道源、组是谁。
特点:一个源一棵树,多源多树。
缺点:树太多

②RPT共享树:
RPT共享树:选择一个RP,RP到目标仅一棵树,但是路径可能不是最优。路由器生成的表可能是(*,G),可能知道组,但是不知道源。

2、PIM——协议无关模块组播路由协议
PIM是一个 完全独立 的组播路由协议,可以使用任何单播协议,它不像大多的组播路由协议是让单播路由协议携带组播路由信息来实现组播路由协议的功能,例如:MBGP、MOSPF。
PIM特征:
跨层封装协议,协议号103,存在hello包,30s hello time,105s hold time。存在邻居关系,更新地址为224.0.0.13。
PIM存在两种模式:
①密集模式:Dense-mode,在企业网中运行
②稀疏模式:Sparse-mode,在网络服务提供商中运行
(1)密集模式:
①原理:
当PIM以密集模式运行完成后,相关设备会使用Hello包建邻,邻居关系建立后,它们之间只有邻居关系表,没有任何转发规则表(因为链路是临时的)。
密集模式:一般用于接收者较多的大多型企业内网(LAN),使用SPT树,基于 push 推模型工作。
先由第一跳路由器将源发出的流量推(泼)向整个网络,过程中每台路由器的RPF和声明机制开始计算生成最佳唯一路径,生成路由表(S(源),G(目标))。而后面没有用户的叶子路由器开始向源反方向发出修剪包,修剪到存在接收者路由器位置。

为了防止新增的用户加组,它会将上述行为每隔3分钟重复一次,用来重新把用户加组。
②配置:
首先让R2、R3、R4、R6中运行EIGRP,R1、R5关闭路由功能,同时把网关指向下一跳。

接下来我们要在R2-R4、R6的每个接口部署PIM,需要注意的是R4的S0/1口也需要配置PIM,因为如果不运行PIM,R5要加组,R4会不知道。**
对于R2的S0/0一样要运行PIM,如果R2的S0/0口不运行PIM,R1发组播流量到R2以后,由于流量没有进入PIM的工作半径,R2这个就不会转发流量,然后抛弃。在没有部署组播时,组播和广播是一样的,R1是出不了广播域的。
上述所有的接口都这样配置,这里只示例R2
R2(config)#ip multicast-routing
//在接口上配置密集模式:开启PIM协议后,可以基于IGMP工作,可以建立PIM邻居,不开启协议的接口是不会转发组播流量的。
R2(config)#int s0/1
R2(config-if)#ip pim dense-mode
R2(config)#int s0/0
R2(config-if)#ip pim dense-mode
此时组播部署完闭,R2、R3、R4、R6便开始发送hello包,建立邻居关系,生成邻居表:

| uptime | Expires | Ver | DR Prio |
|---|---|---|---|
| 建邻时长 | 保活时长 | 版本号 | DR优先级 |
优先级:优先级用于选举DR,DR仅在MA网络中选举,因此DR在密集模式中无意义。
DR选举规则:首先比较优先级,越大越优,默认为一,然后再比较接口IP,优选最大的。
| 模式 | 注解 |
|---|---|
| S | 状态可刷新,DR可以抢占 |
| B | 高级PIM,双向PIM |
| N | 低版本协议中不选举DR |
上面邻居表生成之后,并没有转发表。这是因为没有没有流量触发,要想流量触发,我们先让R5加个组。
R5(config)#int s0/0
R5(config-if)#ip igmp join-group 239.250.250.250
接着R1发ping 的流量,
上面的图片显示,收到了来自45.1.1.2的回复,延迟为52ms。我们之后在R2上看一下转发表:
正常情况下的转发表会显示框框中的这条12.1.1.1,而224.0.1.40是只要运行PIM就会有,是PIMieyi运行自己加的组。而(*,239.250.250.250)本来应该是共享树才能出现的,这里本不该出现。但出现的原因是只要有一个(S,G)就会产生一个(*,G)
我们看到框框里面的(S,G),S是12.1.1.1,G是239.250.250.250。
里面记录了,进入接口为S0/0口,这个接口的RPF邻居是空的,出接口是S0/1口,状态时Forward转发,模式是Dense密集。


我们再在R3上查看一下转发表:
RPF的邻居是23.1.1.1,出接口有两个,一个是S0/0口,一个是E0/0。我们看到E0/0口的模式为Prune,意思是修剪掉了。这是因为E0/0口连的是R6,R6没有用户,所以被修剪掉了。

这个是R6:
由于R6没有用户,出接口是空的Null。
这就是密集模式:先正常启动,然后生成邻居表。然后一旦源向外发出流量,第一跳路由开始推流量,各种机制开始工作,修剪开始进行后,各台路由器将会生成组播路由表,和转发规则。

(2)稀疏模式:
稀疏模式:主要应用于ISP网络,同时使用RPT树和SPT树,存在RP角色,拉模型。适用于用户较少的环境
①工作原理:
这个稀疏模式的意义在于,在使用推模型之前,判断有没有用户。在没有用户的情况下是不会推的,因此更适合于用户更少的环境。

②配置:
还是之前的那张图:
首先让R2、R3、R4、R6中运行EIGRP,R1、R5关闭路由功能,同时把网关指向下一跳。

Ⅰ、配置接口PIM的工作方式:
接口和密集模式的接口配置一样,R2、R3、R4、R6所有的接口都要配置。这里只示例R2。
R2(config)#ip multicast-routing
R2(config)#int s0/0
R2(config-if)#ip pim sparse-mode
由于没有定义RP,因此R1发消息给R5,R5是发不通的。

Ⅱ、定义RP:
定义RP的方式有三种:静态 RP、Auto-rp(Cisco私有)、BSR(公有),我这里只讲解前两个。
【1】静态RP:
静态RP:告知所有路由器谁为RP(一般使用环回地址来作为RP地址,若使用环回地址,单播路由表中必须可达环回路由,同时该环回接口也必须工作PIM中,选择环回接口是因为环回接口稳定。
//环回作为RP,因此它也需要修改模式为稀疏模式。
R3(config)#int lo0
R3(config-if)#ip pim sparse-mode
//所有设备上手动配置,用于告知RP所在位置。这里我们选择R3的环回
R3(config)#ip pim rp-address 3.3.3.3
R2(config)#ip pim rp-address 3.3.3.3
R4(config)#ip pim rp-address 3.3.3.3
R6(config)#ip pim rp-address 3.3.3.3
之后我们测试,它就通了。
证明推没推的方法很简单,就是查看组播路由表:
黄颜色线框中存在(S,G)证明这个就是推出来的。


【2】Auto-rp(Cisco私有):
上面的做法是手选的,一旦坏了就凉凉,因此有了这种自己选出来的RP。
这个技术存在两种角色:
| 属性\角色 | CRP | MA |
|---|---|---|
| 作用 | 候选RP | 映射代理 |
| 角色 | 参选者 (建议多个) | 决策者 (可以有多个) |
C-RP会周期向224.0.1.39发出希望成为RP的信息,该组只有MA加入,也就是说只有MA会收到C-RP的消息。
MA认定IP地址最大成为RP,通过224.0.1.40来宣布谁成为RP,所有运行PIM协议的路由器默认均加入该组。
C-RP配置:一般使用C-RP的环回地址来参选,故该环回可以被其他访问的同时,也必须工作于PIM中。
这里R2、R3当作C-RP,R6为MA
R2(config)#int lo0
R2(config-if)#ip pim sparse-mode
//发送RP 宣告 loopback 0 去参选,TTL为5。如果不设定TTL,那么默认为1,将传输不到MA。
R2(config)#ip pim send-rp-announce loopback 0 scope 5
MA配置:一般使用MA的环回地址来参选,故该换会可以被其他访问的同时,还必须工作于PIM中。
//R6用户环回作为MA
R6(config)#ip pim send-rp-discovery loopback 0 scope 5
注意:由于参选信息和结果的宣布均通过组播发出,而在稀疏模式中必须存在RP后才能进行组播流量的转发,故以上配置不能实现RP的选举
可以通过以下两种方式解决:
A、 在所有路由器配置该命令后,参选者会将参选信息单播发送给邻居,这样每台路由器均可收到参选信息和参选结果。
//R2、R3、R4、R6均配置,开启侦听
R6(config)#ip pim autorp listener
查看RP:
//显示选举RP的过程
show ip pim rp mapping
//显示组的信息RP信息、版本号
show ip pim rp
B、 让所有的路由器运行在稀疏密集模式中:

//所有接口配置,这里示例 R2
R2(config)#interface s0/0
//PIM的稀疏密集模式
R2(config-if)#ip pim sparse-dense-mode
这个模式的意思是:选举RP的信息将基于密集模式来进行,RP选举成功后,稀疏来转发网络组播流量。
六、关于DR的总结:
DR的作用:在MA网络中将进行DR选举,先优先级最大,再IP地址最大。
1、DR在IGMPv1中被利用成为查询者:
2、DR在IGMPv2中,由于查询者自己选举,因此在IGMPv2中无意义
3、DR在PIM的密集模式协议中无意义。
4、DR在稀疏模式下,第一跳和最后一跳路由器可能存在多台,那么将导致重复注册和家族,故进行DR选举,仅DR可以注册或加组。
R2(config)#int f0/0
//修改参选DR的权限
R2(config-if)#ip pim dr-priority 2















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









