









zookeeper的作用:
Zookeeper是针对大型分布式系统的高可靠的协调系统,如dubbo里面的注册中心、分布式锁等,主要应用于分布式系统中。
分布式应用的优点:
- 可靠性- 单个或几个系统的故障不会使整个系统出现故障。
- 可扩展性- 可以在需要时增加性能,通过添加更多机器,在应用程序配置中进行微小的更改,而不会有停机时间。
- 透明性- 隐藏系统的复杂性,并将其显示为单个实体/应用程序。
分布式应用的挑战:
- 竞争条件- 两个或多个机器尝试执行特定任务,实际上只需在任意给定时间由单个机器完成。例如,共享资源只能在任意给定时间由单个机器修改。
- 死锁- 两个或多个操作等待彼此无限期完成。
- 服务发现 -client如何发现server,检测server存活性。
- 不一致- 数据的部分失败。
zk基本概念:
- 观察者模式:zk的核心功能,监听数据的变化
- 服务管理框架:zk的重要性就体现在对绝大部分分布式架构的服务治理
提供的常见服务:
- 命名服务- 按名称标识集群中的节点。它类似于DNS,但仅对于节点。
- 配置管理- 加入节点的最近的和最新的系统配置信息。
- 集群管理- 实时地在集群和节点状态中加入/离开节点。
- 选举算法- 选举一个节点作为协调目的的leader。
- 锁定和同步服务- 在修改数据的同时锁定数据。此机制可帮助你在连接其他分布式应用程序(如Apache HBase)时进行自动故障恢复。
- 高度可靠的数据注册表- 即使在一个或几个节点关闭时也可以获得数据。
架构:
| 组件 | 描述 |
|---|---|
| Client(客户端) | 客户端,我们的分布式应用集群中的一个节点,从服务器访问信息。对于特定的时间间隔,每个客户端向服务器发送消息以使服务器知道客户端是活跃的。 类似地,当客户端连接时,服务器发送确认码。如果连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。 |
| Server(服务器) | 服务器,我们的ZooKeeper总体中的一个节点,为客户端提供所有的服务。向客户端发送确认码以告知服务器是活跃的。 |
| Ensemble | ZooKeeper服务器组。形成ensemble所需的最小节点数为3。 |
| Leader | 服务器节点,如果任何连接的节点失败,则执行自动恢复。Leader在服务启动时被选举。 |
| Follower | 跟随leader指令的服务器节点。 |
ZooKeeper的层次命名空间:
- ZooKeeper节点称为 znode :每个znode都维护着一个stat结构。一个stat仅提供一个znode的元数据。它由版本号,操作控制列表(ACL),时间戳和数据长度组成。
- Znode的类型:
持久节点:即使在创建该特定znode的客户端断开连接后,持久节点仍然存在。默认情况下,除非另有说明,否则所有znode都是持久的。
临时节点- 客户端活跃时,临时节点就是有效的。当客户端与ZooKeeper集合断开连接时,临时节点会自动删除。因此,只有临时节点不允许有子节点。如果临时节点被删除,则下一个合适的节点将填充其位置。临时节点在leader选举中起着重要作用。
顺序节点- 顺序节点可以是持久的或临时的。当一个新的znode被创建为一个顺序节点时,ZooKeeper通过将10位的序列号附加到原始名称来设置znode的路径。例如,如果将具有路径/myapp的znode创建为顺序节点,则ZooKeeper会将路径更改为/myapp0000000001,并将下一个序列号设置为0000000002。如果两个顺序节点是同时创建的,那么ZooKeeper不会对每个znode使用相同的数字。顺序节点在锁定和同步中起重要作用。
Watches(观察模式):
监视是一种简单的机制,使客户端收到关于ZooKeeper集合中的更改的通知。客户端可以在读取特定znode时设置Watches。Watches会向注册的客户端发送任何znode(客户端注册表)更改的通知。Znode更改是与znode相关的数据的修改或znode的子项中的更改。只触发一次watches。如果客户端想要再次通知,则必须通过另一个读取操作来完成。当连接会话过期时,客户端将与服务器断开连接,相关的watches也将被删除。
- keeperState:反应当前的节点状态,节点发生了什么样的变化
- eventType:反应当前的事件状态,对节点做了什么操作
- 可以监听的范围:
- 创建连接的时候
- 子节点操作
- 当前节点的数据操作
- 监听指定节点的存在情况
- 监听器默认情况下,只能监听到一次;如果需要让他一直生效,需要循环监听
- 由于监听者是由一个守护线程来维持的,所以当用户线程结束后,守护线程自动结束;由代理来调用该process方法
数据发布与订阅:
发布与订阅即所谓的配置管理,顾名思义就是将数据发布到zk节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,地址列表等就非常适合使用。
索引信息和集群中机器节点状态存放在zk的一些指定节点,供各个客户端订阅使用。
系统日志(经过处理后的)存储,这些日志通常2-3天后被清除。
应用中用到的一些配置信息集中管理,在应用启动的时候主动来获取一次,并且在节点上注册一个Watcher,以后每次配置有更新,实时通知到应用,获取最新配置信息。
业务逻辑中需要用到的一些全局变量,比如一些消息中间件的消息队列通常有个offset,这个offset存放在zk上,这样集群中每个发送者都能知道当前的发送进度。
系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息。以前通常是暴露出接口,例如JMX接口,有了zk后,只要将这些信息存放到zk节点上即可。
分布通知/协调:
ZooKeeper 中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对 ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能 够收到通知,并作出相应处理。
- 另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。
- 另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改
了ZK上某些节点的状态,而zk就把这些变化通知给他们注册Watcher的客户端,即推送系统,于是,作出相应的推送任务。- 另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到zk来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。
总之,使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合。
分布式锁:
分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性,即用户只要完全相信每时每刻,zk集群中任意节点(一个zk server)上的相同znode的数据是一定是相同的。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
- 保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create
znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。- 控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
集群管理:
- 集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。这种做法可行,但是存在两个比较明显的问题:1.
集群中机器有变动的时候,牵连修改的东西比较多。2. 有一定的延时。- 利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统:a. 客户端在节点 x 上注册一个Watcher,那么如果 x的子节点变化了,会通知该客户端。b. 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
- Master选举则是zookeeper中最为经典的使用场景了。 在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行,
其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。
利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建
/currentMaster 节点,最终一定只有一个客户端请求能够创建成功。
节点状态
- czxid 创建该节点的事务ID
- ctime 创建该节点的时间
- mZxid 更新该节点的事务ID
- mtime 更新该节点的时间
- pZxid 操作当前节点的子节点列表的事物ID(包含增加子节点,删除子节点)
- cversion 当前节点的子节点版本号
- dataVersion 当前节点的数据版本号 aclVersion 当前节点的acl权限版本号
- ephemeralowner 当前节点的如果是临时节点,该属性是临时节点的事物ID
- dataLength 当前节点的数据长度
- numchildren 当前节点的子节点个数
基本api:
//创建节点
public static void createNode() throws Exception {
ZooKeeper zk = new ZooKeeper("192.168.10.12:2181", 100000, null);
String str = "真帅";
String result = zk.create("/testNode/test1", //路径
str.getBytes(), //获取数据的字节码
ZooDefs.Ids.OPEN_ACL_UNSAFE, //任何人都拥有所有权限
CreateMode.PERSISTENT);//永久节点
System.out.println(result);//返回当前已经创建的路径
zk.close();
}
//获取节点
public static void getNode() throws Exception {
ZooKeeper zk = new ZooKeeper("192.168.10.12:2181", 100000, null);
// States stats = zk.getState();//获取状态-运行状态
// System.out.println(stats);
//数据节点状态
Stat stat = new Stat();
byte[] data = zk.getData("/testNode/test1", null, stat);
System.out.println(new String(data));//节点数据
System.out.println(stat.toString());//节点状态
zk.close();
}
//修改节点
public static void setNode() throws Exception {
ZooKeeper zk = new ZooKeeper("192.168.10.12:2181", 100000, null);
Stat stat = zk.setData("/testNode/test1", "杨斌斌真帅!!!!".getBytes(), -1);
System.out.println(stat.toString());//节点状态
zk.close();
}
//删除节点
public static void removeNode() throws Exception {
ZooKeeper zk = new ZooKeeper("192.168.10.12:2181", 100000, null);
zk.delete("/testNode/test1", -1);
zk.close();
}
监听服务器的变化:
private Semaphore sp = new Semaphore(1);
//监听时,服务器要保证客户端一定能收到消息,反复不断的向客户端发送状态
private boolean flag = true;//加一个状态防止虚假提交
public synchronized void test() throws Exception {
ZooKeeper zk = new ZooKeeper("192.168.10.102:21811", 100000, null);
//信号量
while(true) {
zk.getData("/testNode/test1", new Watcher() {
public void process(WatchedEvent event) {
if(!flag) {//每次注册之后,只接收一次数据
return;
}
System.out.println(event.getState().name());//节点状态
System.out.println(event.getType().name());//操作类型
System.out.println(event.getPath());//那个节点发生了变化
sp.release(1);//清空信号量
flag = false;
}
}, new Stat());
sp.acquire(1);//信号量加满,线程也就停下来了
flag = true;
}
}
watcher注册api:
| API | 说明 | |
|---|---|---|
| getChildren | NodeChildrenChanged | 新建子节点【激活】 |
| 删除子节点【激活】 | ||
| 修改子节点【不激活】 | ||
| getData | NodeDataChanged | 修改该节点 |
| NodeDeleted | 删除该节点 | |
| exists | NodeCreated | 新建该节点 |
| NodeDataChanged | 修改该节点 | |
| NodeDeleted | 删除该节点 |
验证模式(scheme):
| 权限 | 说明 |
|---|---|
| digest | Client端由用户名和密码验证,譬如user:password,digest的密码生成方式是Sha1摘要的base64形式 |
| auth | 不使用任何id,代表任何已确认用户。 |
| ip | Client端由IP地址验证,譬如172.2.0.0/24 |
| world | 固定用户为anyone,为所有Client端开放权限 |
| super | 在这种scheme情况下,对应的id拥有超级权限,可以做任何事情(cdrwa) |
| 注意: exists操作和getAcl操作并不受ACL许可控制,因此任何客户端可以查询节点的状态和节点的ACL。 |
节点的权限(perms)
| 权限 | 说明 |
|---|---|
| Create | 允许对子节点Create操作 |
| Read | 允许对本节点GetChildren和GetData操作 |
| Write | 允许对本节点SetData操作 |
| Delete | 允许对子节点Delete操作 |
| Admin | 允许对本节点setAcl操作 |
Paxos算法的目的:
为了解决分布式环境下一致性的问题。多个节点并发操纵数据,如何保证在读写过程中数据的一致性,并且解决方案要能适应分布式环境下的不可靠性(系统如何就一个值达到统一)
Paxos有两个原则:
- 安全原则—保证不能做错的事:针对某个实例的表决只能有一个值被批准,不能出现一个被批准的值被另一个值覆盖的情况;(假设有一个值被多数Acceptor批准了,那么这个值就只能被学习)。每个节点只能学习到已经被批准的值,不能学习没有被批准的值。
- 存活原则—只要有多数服务器存活并且彼此间可以通信,最终都要做到的下列事情: 最终会批准某个被提议的值;一个值被批准了,其他服务器最终会学习到这个值。
分布式选举之三军问题场景:
-
先后提议的场景
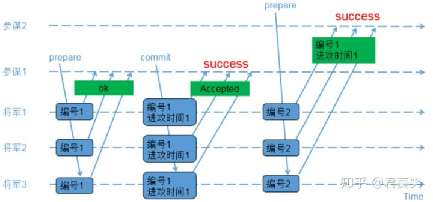
-
交叉场景

CAP原则
又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。这三个要素最多只能同时实现两点,不可能三者兼顾。
zookeeper中节点分四种状态:
- looking:选举Leader的状态(集群刚启动时或崩溃恢复状态下,也就是需要选举的时候)
- following:跟随者(follower)的状态,服从Leader命令
- leading:当前节点是Leader,负责协调工作。
- observing:observer(观察者),不参与选举,只读节点。
zookeeper选举过程:leader挂了,需要选举新的leader
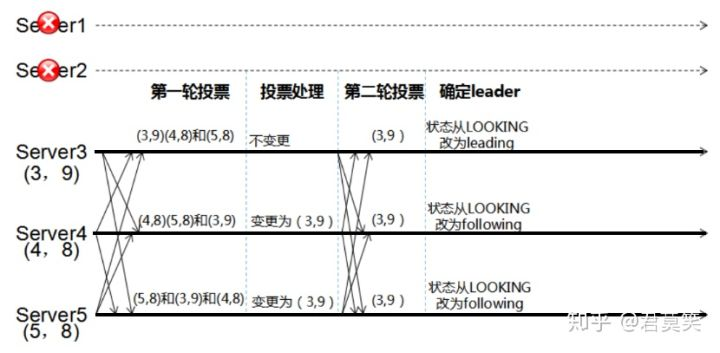
- 阶段一:崩溃恢复
- 阶段二:消息广播
- 阶段三:数据同步
zk选举过程:
- 找到新的leader(myid:zxid)
- 新的leader广播信息,告诉所有的follower我要进行数据同步
- follower接受到信息准备好之后会告诉leader我准备好了
- leader判断是否有半数以上follower准备好了
- 如果超过半数则再次广播同意写入,follower接受到同意的信息后,完成写入工作
- 如果有新节点加入或者有数据要写入,过程参照上面数据同步的流程(2-5)
















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











