







1.ArrayList
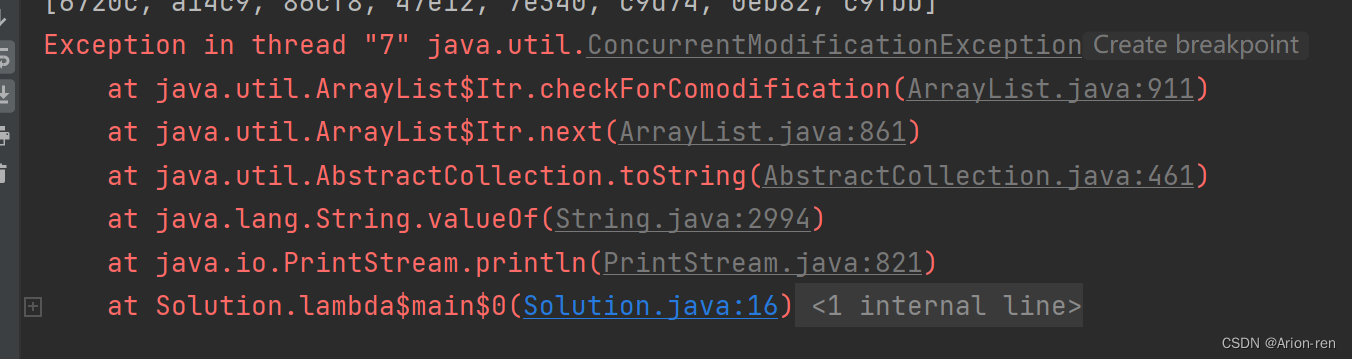
ArrayList中的方法都是非同步的,因此是线程不安全的,在如下的代码中同时开启十个线程
public class Solution {
public static void main(String[] args) {
List<String> list = new ArrayList();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0,5));
System.out.println(list);
},String.valueOf(i)).start();
}
}
}
运行后java报错如下,ConcurrentModificationExecption,即 并发修改异常,显然是线程不安全的
 解决方法(1)利用Vector,但是Vector'所有的方法都是同步的,开销非常大
解决方法(1)利用Vector,但是Vector'所有的方法都是同步的,开销非常大
List list = new Vector<>();(2)Collections集合类为我们提供了很多的方法,其中就包括了创建线程安全的list
List list = new ArrayList<>();
Collections.synchronizedList(list);(3) CopyOnWriteArrayList是jdk1.5后引入,属于JUC的一部分,基本原理和ArrayList的原理是一样的,只是写入的时候不是直接写入,而是先复制一份,写入后再返回给调用者,避免了写入的覆盖,同时涉及线程安全的部分加了lock锁提高了效率。
List<String> list = new CopyOnWriteArrayList<>();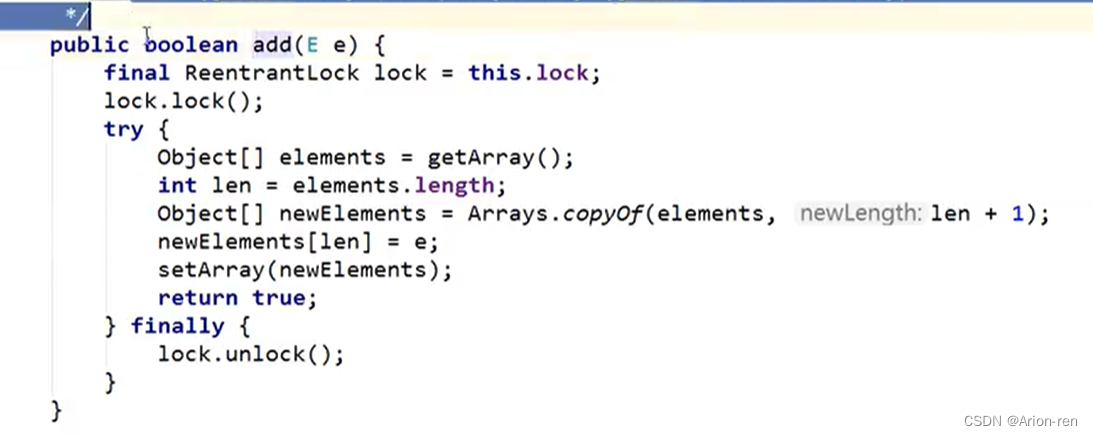
2.Set集合
和ArrayList一样,HashSet也是线程不安全的,不同的是ArrayList有Vector替代,而HashSet没有,只有后面的两种方式。
3.map集合
map的实现类hashmap是线程不安全的,hashtable做了同步的操作,但是每次操作都需要锁住整张表,效率非常的低。为了解决这个问题JUC下有一个concurrentHashMap,不同于Hashtable对get/put/remove都使用了同步操作,ConcurrentHashMap只对put/remove同步。
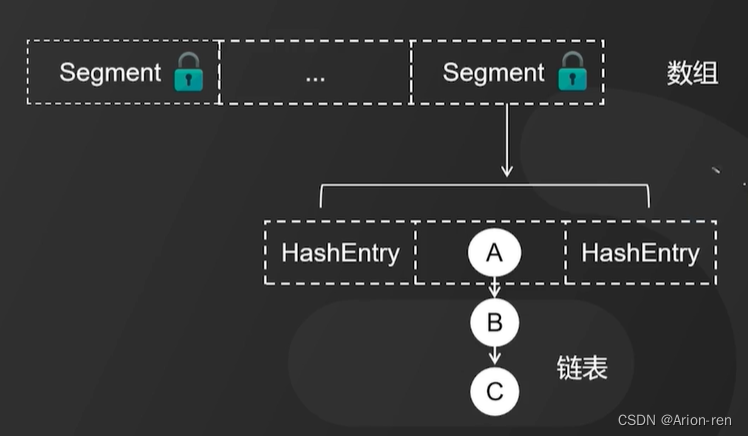
jdk1.7:segement数组+ReentrantLock
利用lock锁对每段segment数组加锁,保证一个数组只有一个线程在操作,一个segment数组可以看成一个hashtable的结构,其中维护一个hashentry的数组。可以看出定位到一个一个元素的过程需要两次的hash操作,第一次定位到数组,第二次定位到元素所在链表的头部,
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
put操作:
执行put操作时,会进行第一次key的hash来定位Segment的位置,会通过ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就二次hash计算出所在的hashentry,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。
get操作不加锁,size操作比较特殊,因为你计算容量需要时间,这期间可能会有线程继续插入,因此需要对全部的segement加锁或者是连续三次做size操作比较前后的值。
jdk1.8:cas+synchronized
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,synchronize操作加锁只会锁当前的根节点或者链表中的头结点,进一步减小了锁的粒度。
put:
- 如果没有初始化就先调用initTable()方法来进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在hash冲突,就加锁(头结点或者根节点)来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
- 最后一个如果Hash冲突时会形成Node链表,在链表长度超过8,Node数组超过64时会将链表结构转换为红黑树的结构,break再一次进入循环
- 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
get:
- 计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
- 以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
扩容:
扩容过程有点复杂,这里主要涉及到多线程并发扩容,ForwardingNode的作用就是支持扩容操作,将已处理的节点和空节点置为ForwardingNode,并发处理时多个线程经过ForwardingNode就表示已经遍历了,就往后遍历。















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









