







 超级会员免费看
超级会员免费看
 载波聚合(CA)是提升网络容量和速度的关键技术,通过结合多个载波资源以增加带宽。4G的LTE-Advanced引入CA,最高达32载波聚合,5G则支持16载波聚合,带宽可高达1.6GHz(Sub6G)或6.4GHz(毫米波)。5G的CA技术更为复杂,包括FR1与FR2频段内的聚合,以及与4G的双连接技术,进一步增强下行传输速率。
载波聚合(CA)是提升网络容量和速度的关键技术,通过结合多个载波资源以增加带宽。4G的LTE-Advanced引入CA,最高达32载波聚合,5G则支持16载波聚合,带宽可高达1.6GHz(Sub6G)或6.4GHz(毫米波)。5G的CA技术更为复杂,包括FR1与FR2频段内的聚合,以及与4G的双连接技术,进一步增强下行传输速率。
到底什么是载波聚合(CA)?
参考链接:https://xueqiu.com/7282046183/165602383
1
为什么需要载波聚合?
一般来说,要提升网速或者容量,有下面几个思路:
建更多的基站:这样一来同一个基站下抢资源的人就少了,网速自然就上去了。但缺点是投入太大了,运营商肯定不会做亏本的买卖。
提升频谱效率:从2G到5G,有多少专家潜心钻研,一头青丝变华发,就是为了提升效率,在每赫兹的频谱上传更多的数据!可见这项工作是真的很艰难。
增加频谱带宽:这是提升容量最简单粗暴的办法了,从2G到5G,单个载波的带宽不断增长,从2G的200K,再到3G的5M,4G的20M,在5G时代甚至达到了100M(Sub6G频段)乃至400M(毫米波频段)!
然而,这一切努力在汹汹流量面前还是杯水车薪,这可怎么办?
只能再增加频谱带宽了!4G的做法主要是把2G和3G,乃至Wifi的频段抢过来用,5G的做法主要是扩展新频段,从传统的低频向带宽更大的高频发起冲击。
频谱千方百计搞到了,但载波的带宽却已经由协议定好了,不容再改,这又咋办?
说起来要实现也简单,人多力量大是永恒的真理,一个载波容量不够,我就再加一个一起传数据,不信速度上不去。什么,还不够?那就继续增加载波!
这种技术就叫做:载波聚合。
话说LTE的第一个版本因为容量有限,虽然被广泛宣传为4G技术,但实际上达不到国际电联的4G标准,业内也就称之为3.9G。
后来LTE演进到LTE-Advanced时,引入了5载波聚合,把单用户可用的带宽从20MHz扩大到了100MHz,这才坐稳了4G的头把交椅。

后面的5G,自然是继承了4G的衣钵,把载波聚合作为提升容量的利器。
2
载波聚合的分类及发展史
根据载波聚合所在的频带,CA可以分为Intra-Band和Inter-Band,频段内载波聚合又分为连续载波和非连续载波,频段间载波聚合
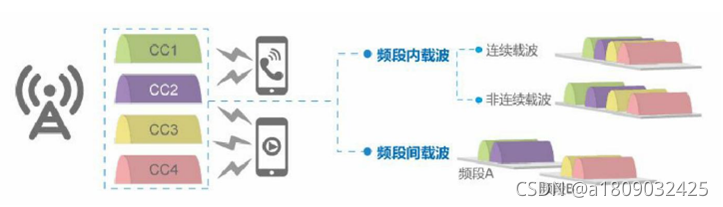
话说频谱资源是稀缺的,每个频段就那么一小段,因此载波聚合需要支持多种方式,以两载波聚合为例:
如果两个载波的频段相同,还相互紧挨着,频谱连续,就称作频段内连续的载波聚合。
如果两个载波的频段相同,但频谱不连续,中间隔了一段,就称作频段内不连续的载波聚合。
如果两个载波的频段不同,则称作频段间的载波聚合。

这三种方式包含了所有的情况,可谓任你几路来,都只一路去,再多的载波,也能给拧成一股绳。
参与载波聚合的每一个载波,又都叫做分量载波(Component Carrier,简称CC)。因此,3载波聚合也可称之为3CC。
这些载波在一起工作,需要相互协同,就总得有个主辅载波之分。
所谓主载波,就是承载信令,并管理其他载波的载波,也叫Pcell(Primary cell)。
辅载波也叫Scell(Secondary cell),用来扩展带宽增强速率,可由主载波来决定何时增加和删除。

主辅载波是相对终端来说的,对于不同终端,工作的主辅载波可以不同。并且,参与聚合的多个载波不限于同一个基站,也可以来自相邻的基站。
从4G的LTE-Advanced协议引入载波聚合之后,该技术就如脱缰的野马一样狂奔,从最初的5载波聚合,总带宽100MHz,再到后面的32载波聚合,总带宽可达640MHz!
到了5G时代,虽说可聚合的载波数量仅为16个,但架不住5G的载波带宽大啊。
Sub6G的单载波带宽最大100MHz,16个载波聚合一共就1.6GHz带宽了;毫米波频段更夸张,单载波带宽最大400MHz,16个载波聚合一共就有6.4GHz带宽!

时代的车轮就这样滚滚向前。前浪以为自己已经很牛逼了,但回头一看,后浪简直就是滔天巨浪啊,然后还没反应过来就已经被拍在了沙滩上摩擦。
3
5G的载波聚合技术
话说5G的载波聚合,相比4G来说更复杂一些。
首先5G的频段分为两类,FR1和FR2,也就是俗称的6GHz以下的频段(Sub6G),以及高频,也就毫米波(mmWave)。

FR1包含了众多从2G,3G和4G传承下来的频段,有些是FDD的,有些是TDD的。

这样一来,在FR1内部就存在FDD+FDD频段间的载波聚合,FDD+TDD频段间的载波聚合,以及TDD+TDD频段间的载波聚合。
在上述的每个FDD或者TDD的频段内部,还可以由多个带内连续的载波聚合而成。3GPP定义了多种的聚合等级,对应于不同的聚合带宽和连续载波数。

比如上图中的FR1频段内载波聚合等级C,就表示2个带内连续的载波聚合,且总带宽在100MHz到200MHz之间。
不同于FR1,FR2是全新定义毫米波频段,双工方式全部都是TDD。

跟FR1类似,3GPP也为FR2频段定义了带内连续的多种的聚合等级,对应于不同的聚合带宽和连续载波数。

比如上图中的FR2频段内载波聚合等级M,就表示8个带内连续的载波聚合,且总带宽在700MHz到800MHz之间。
有了上述的定义,我们就可以在FR1内部频段内,频段间进行载波聚合,还能和FR2进行聚合,并且载波数量,以及每个载波的带宽也都可以不同,它们之间的排列组合非常多。
举个例子,“CA_n78A-n258M”这个组合,就代表n78(又称3.5GHz或者C-Band)和n258(毫米波26GHz)这两个频段间的聚合,其中n78的频段内聚合等级为A,也就是单载波,n258的频段内聚合等级为M,也就是有8个载波且总带宽小于800MHz。
4
NSA组网下的双连接技术
且说上面的5G内部载波聚合已经很强悍了,但这还只是带宽扩展的冰山一角。
5G在NSA架构下引入了双连接(Dual Connection,简称DC)技术,手机可以同时连接到4G基站和5G基站。

在双连接的基础上,4G部分和5G部分还都可以在其内部进行载波聚合,这就相当于把4G的带宽也加进来,可进一步增强下行传输速率!

在双连接下,手机同时接入4G基站和5G基站,这两基站也要分个主辅,一般情况下Option3系列架构中,4G基站作为控制面锚点,称之为主节点(Master Node),5G基站称之为辅节点(Secondary Node)。
主节点和辅节点都可以进行载波聚合。其中主节点的主载波和辅载波称为Pcell和Scell,辅节点的主载波和辅载波称为PScell和Scell。
带载波聚合的主节点和辅节点又可以被称作MCG(Master Cell Group,主小区组)和SCG(Secondary Cell Group,辅小区组)。

虽说NSA架构的初衷并不是提升速率,而是想着藉由4G来做控制面锚点,这样一来不但现网的4G核心网EPC可以利旧,还能使用成熟的4G覆盖来庇护5G这个初生的孩童。
但是客观上来讲,通过双连接技术,手机可同时连接4G和5G这两张网络,获取到的频谱资源更多,理论上的峰值下载速率可能要高于SA组网架构,除非以后把4G载波全部重耕到5G。
这些双连接加载波聚合的组合,也都是由协议定义的。
如果看到这串字符:DC_1A_n78A-n257M,我们先按照下划线“_”把它拆解为三个部分,DC,1A,和n78A-n257M。
DC就表示双连接,1A表示LTE band1(2100MHz)单载波,后面的n78A-n257M见前文的解释,这串字符综合起来就是5G FR1和FR2多个载波聚合后,在和一个4G载波进行了双连接。
5
高通骁龙888集成的X60基带,下载速率是怎样达到7.5Gbps的?
话说近期高通发布了骁龙888芯片,这个名字确实非常吉利,其内部集成的X60基带也是非常牛逼的,号称能达到7.5Gbps的最大下载速度。
我们且先看看X60主要都支持哪些高级能力:
频段支持:Sub6G(FR1)和mmWave(FR2)都支持,在Sub6G还支持4G和5G的动态频谱共享(Dynamic Spectrum Sharing,简称DSS)。
Sub6G能力:支持200M带宽,4x4 MIMO。也就是说,可以在这200M带宽(2个100M载波)上,同时接收4路不同的下载数据,也叫做4流。
mmWave能力:支持800M带宽,8个载波,2x2 MIMO。也就是说,这800M带宽被划分为了8个载波,每个100M,它们可聚合起来,同时接收2路不同的下载数据,也叫做2流。
载波聚合能力:Sub6G载波聚合(FDD+TDD,FDD+FDD,TDD+TDD),以及Sub6G和mmWave之间的载波聚合。
那么,7.5Gbps的下载速率是怎么实现的呢?
由于没有详细资料,蜉蝣君大概通过各种组合的拼凑,大概猜测了一下,这个速率可能是在NSA模式下,由一个5G Sub6G 100M载波加上7个mmWave 100M载波聚合起来, 再和4G的一个20MHz载波做了双连接而得来的。

当然,这只是芯片的上限能力,具体能把这些潜能发挥到多少,还要看手机厂家的具体实现。让我们拭目以待。
好了,本期的内容就到这里,希望对大家有所帮助。

















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









