









scala的函数式编程
面向对象编程和函数式编程对比
面向对象编程:在面向对象编程中,面向对象程序设计(英语:Object-oriented programming,缩写:OOP)是种具有对象概念的程序编程范型,同时也是一种程序开发的方法。它可能包含数据、属性、代码与方法。对象则指的是类的实例。它将对象作为程序的基本单元,将程序和数据封装其中,以提高软件的重用性、灵活性和扩展性,对象里的程序可以访问及经常修改对象相关连的数据。在面向对象程序编程里,计算机程序会被设计成彼此相关的对象。
对象的本质是对数据和行为的一个封装。
函数式编程:函数式编程(英语:functional programming)或称函数程序设计,又称泛函编程,是一种编程范型,它将电脑运算视为数学上的函数计算,并且避免使用程序状态以及易变对象。函数编程语言最重要的基础是λ演算(lambda calculus)。而且λ演算的函数可以接受函数当作输入(引数)和输出(传出值)。
对比:对象与对象之间的关系是面向对象编程首要考虑的问题,而在函数式编程中,所有的数据都是不可变的,不同的函数之间通过数据流来交换信息,函数作为FP中的一等公民,享有跟数据一样的地位,可以作为参数传递给下一个函数,同时也可以作为返回值。
函数的本质是函数可以当做一个值进行传递。
scala语言是既是一个完全面向对象也是完全函数式编程语言,万物皆对象,万物皆函数。
1、函数基本语法
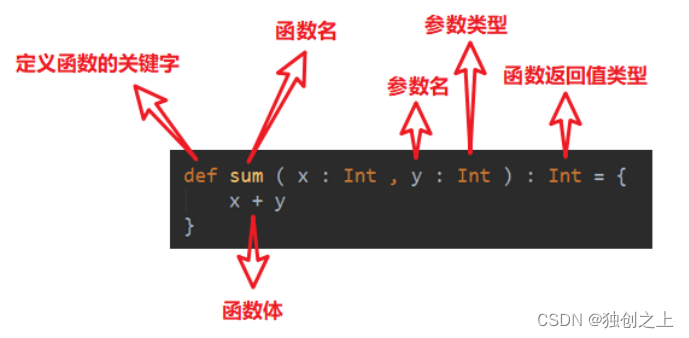
案例:定义一个函数,实现将传入的名称打印出来
object TestFunction {
def main(args: Array[String]): Unit = {
// (1)函数定义
def f(arg: String): Unit = {
println(arg)
}
// (2)函数调用
// 函数名(参数)
f("hello world")
}
}函数和方法的区别:
方法可以说是特征的函数,是函数的子集
核心概念:为完成某一功能的程序语句的集合,称为函数;类中的函数称为方法
函数没有重载和重写的概念,方法可以进行重载和重写
案例:
package cn.itjdb.chapter05
/**scala函数
*/
object FunctionTest {
//方法可以进行重载和重写
def main(): Unit = {
println("方法可以重载")
}
def main(args: Array[String]): Unit = {
main()
//Scala 语言可以在任何的语法结构中声明任何的语法
import java.util.Date
val date = new Date()
println(date)
//函数没有重载和重写的概念,程序报错,不能以相同名字命名
def test():Unit={
println("无参,无返回值")
}
test()
// def test(name:String,age:Int):Unit={
// println()
// }
//Scala 中函数可以嵌套定义
def test2():Unit={
def test3(name:String):Unit={
println(name)
}
test3("zhangsan ")
}
test2()
//函数参数:可变参数
def test4(s:String*):Unit={
println(s)
}
//有输入参数,输出:Array,,无参数输入,输出List
//WrappedArray(zhangsan, lisi)
// test4("zhangsan","lisi")
test4()
//如果参数列表中存在多个参数,那么可变参数一般放置在最后
def test5( name : String, s: String* ): Unit = {
println(name + "," + s)
}
test5("jinlian", "dalang")
//Scala 如果期望是无返回值类型,可以省略等号
// 将无返回值的函数称之为过程
def f6() {
"dalang6"
}
println(f6())
}
}
函数至简原则:能省则省
(1)return 可以省略,Scala 会使用函数体的最后一行代码作为返回值
(2)如果函数体只有一行代码,可以省略花括号
(3)返回值类型如果能够推断出来,那么可以省略(:和返回值类型一起省略)
(4)如果有 return,则不能省略返回值类型,必须指定
(5)如果函数明确声明 unit,那么即使函数体中使用 return 关键字也不起作用 (6)Scala 如果期望是无返回值类型,可以省略等号
(7)如果函数无参,但是声明了参数列表,那么调用时,小括号,可加可不加
(8)如果函数没有参数列表,那么小括号可以省略,调用时小括号必须省略
(9)如果不关心名称,只关心逻辑处理,那么函数名(def)可以省略
至简原则案例:
package cn.itjdb.chapter05
/**
函数至简原则
*/
object FunctionTest02 {
def main(args: Array[String]): Unit = {
//参数的类型可以省略,会根据形参进行自动的推导;
var arr2 = operation(Array(1, 2, 3, 4), (elem) => {
elem + 1
})
println(arr2.mkString(","))
//类型省略之后,发现只有一个参数,则圆括号可以省略;其他情况:没有参数和参数超过 1 的永远不能省略圆括号。
var arr3 = operation(Array(1, 2, 3, 4), elem => {
elem + 1
})
println(arr3.mkString(","))
// 匿名函数如果只有一行,则大括号也可以省略
var arr4 = operation(Array(1, 2, 3, 4), elem => elem + 1)
println(arr4.mkString(","))
// 如果参数只出现一次,则参数省略且后面参数可以用_代替
var arr5 = operation(Array(1, 2, 3, 4), _ + 1)
println(arr5.mkString(","))
//匿名函数简写
def func1(a1:Int):String=>Char=>Boolean={
b1=>c1=>if(a1==0 && b1=="" && c1=='0') false else true
}
println(func1(0)("")('0'))
}
2、高阶函数
1)高阶函数
(1)函数可以作为值进行传递
object FunctionTest02 {
def main(args: Array[String]): Unit = {
//函数可以作为值进行传递
// val a=test()
val a1 = test
println(a1)
//在被调用函数 test 后面加上 _,相当于把函数 test 当成一个整体,传递给变量 f1
val a2 = test _
a2()
//如果明确变量类型,那么不使用下划线也可以将函数作为整体传递给变量
var a3: () => Int = test
a3()
}
def test(): Int ={
println("test 运行")
1
}
}(2)函数可以作为参数来传递
//函数可以作为参数来传递
def test1(f: (Int, Int) => Int): Int = {
f(2, 3)
}
def add(a: Int, b: Int): Int = {
a + b
}
println(test1(add))(3)函数可以作为函数返回值返回
def main(args: Array[String]): Unit = {
def f1() = {
def f2() = {
}
f2 _
}
val f = f1()
// 因为 f1 函数的返回值依然为函数,所以可以变量 f 可以作为函数继续调用
f()
// 上面的代码可以简化为
f1()()
}2)匿名函数
说明:没有名字的函数就是匿名函数:(x:Int)=>{函数体},x:表示输入参数类型;Int:表示输入参数类型;函数体:表示具体代码逻辑。
案例实操:传递的函数有一个参数,有两个参数
传递匿名函数的至简原则:
(1)参数的类型可以省略,会根据形参进行自动的推导
(2)类型省略之后,发现只有一个参数,则圆括号可以省略;其他情况:没有参数和参数超过 1 的永远不能省略圆括号。
(3)匿名函数如果只有一行,则大括号也可以省略
(4)如果参数只出现一次,则参数省略且后面参数可以用_代替
//匿名函数
def operation(array: Array[Int], op: Int => Int) :Array[Int]= {
//yield:数据进行op(elem)处理后,返回到一个新的集合中。
for (elem <- array) yield {
op(elem)
}
}
def op(elem: Int): Int = {
elem + 1
}
val fun2=(name:String)=>{println(name)}
fun2("njb========================================")
//将匿名函数当做一个参数传入另一个函数
def fun5(fun:String=>Unit)={
fun("njb")
}
val arr = operation(Array(1, 2, 3, 4), op)
println(arr.mkString(","))
//匿名函数使用,此处可以省略op函数名
var arr1 = operation(Array(1, 2, 3, 4), (elem: Int) => {
elem + 1
})
println(arr1.mkString(","))
//参数的类型可以省略,会根据形参进行自动的推导;
var arr2 = operation(Array(1, 2, 3, 4), (elem) => {
elem + 1
})
println(arr2.mkString(","))
//类型省略之后,发现只有一个参数,则圆括号可以省略;其他情况:没有参数和参数超过 1 的永远不能省略圆括号。
var arr3 = operation(Array(1, 2, 3, 4), elem => {
elem + 1
})
println(arr3.mkString(","))
// 匿名函数如果只有一行,则大括号也可以省略
var arr4 = operation(Array(1, 2, 3, 4), elem => elem + 1)
println(arr4.mkString(","))
// 如果参数只出现一次,则参数省略且后面参数可以用_代替
var arr5 = operation(Array(1, 2, 3, 4), _ + 1)
println(arr5.mkString(","))
/*
===============================================================
*/
// 传递的函数两个参数
def calculator(a: Int, b: Int, op1: (Int, Int) => Int): Int = {
op1(a, b)
}
def add1(a:Int,b:Int):Int={
a+b
}
println(calculator(25,24,add1))
//标准版,匿名函数
println(calculator(2, 3, (x: Int, y: Int) => {
x + y
}))
//如果只有一行,则大括号也可以省略
println(calculator(2, 3, (x: Int, y: Int) => x + y))
// 参数的类型可以省略,会根据形参进行自动的推导;
println(calculator(2, 3, (x, y) => x + y))
//如果参数只出现一次,则参数省略且后面参数可以用_代替
println(calculator(2, 3, _ + _))
3)高阶函数案例
练习 1:定义一个匿名函数,并将它作为值赋给变量 fun。函数有三个参数,类型分别为 Int,String,Char,返回值类型为 Boolean。 要求调用函数 fun(0, “”, ‘0’)得到返回值为 false,其它情况均返回 true。
def fun(a:Int,b:String,c:Char,op2:(Int,String,Char)=>Boolean):Boolean={
op2(a,b,c)
}
val bool: Boolean = fun(1, "", '0', (a1, b1, c1) => {
if (a1 == 0 && b1 == "" && c1 == '0') {
false
} else {
true
}
}
)
println(bool)练习 2: 定义一个函数 func,它接收一个 Int 类型的参数,返回一个函数(记作 f1)。 它返回的函数 f1,接收一个 String 类型的参数,同样返回一个函数(记作 f2)。函数 f2 接 收一个 Char 类型的参数,返回一个 Boolean 的值。 要求调用函数 func(0) (“”) (‘0’)得到返回值为 false,其它情况均返回 true。
//函数作为函数的返回值返回
def func(a1:Int):String=>Char=>Boolean={
def f1(b1:String):Char=>Boolean={
def f2(c1:Char):Boolean={
if(a1==0 && b1=="" && c1=='0'){
false
}else{
true
}
}
f2
}
f1
}
println(func(0)("")('0'))4)函数柯里化&闭包
闭包:如果一个函数,访问到了它的外部(局部)变量的值,那么这个函数和他所处的 环境,称为闭包。
def f1()={
var a:Int = 10
def f2(b:Int)={
a + b
}
f2 _
}
// 在调用时,f1 函数执行完毕后,局部变量 a 应该随着栈空间释放掉
val f = f1()
// 但是在此处,变量 a 其实并没有释放,而是包含在了 f2 函数的内部,形成了闭合的效果
println(f(3))
println(f1()(3))
函数柯里化:把一个参数列表的多个参数,变成多个参数列表。
//柯里化
def func2(a1:Int)(s:String)(c:Char):Boolean={
if(a1==0 && s=="" && c=='0') false else true
}
println(func2(0)("")('0'))5)递归
一个函数/方法在函数/方法体内又调用了本身,我们称之为递归调用。
def test(i:Int):Int={
if (i==1 ||i==0){
1
}else{
i*test(i-1)
}
}scala的面向对象
Scala 的面向对象思想和 Java 的面向对象思想和概念是一致的。Scala 中语法和 Java 不同,补充了更多的功能。
1、scala包
1)基本语法 package 包名
2)Scala 包的三大作用(和 Java 一样)
(1)区分相同名字的类
(2)当类很多时,可以很好的管理类
(3)控制访问范围
命名规则:只能包含数字、字母、下划线、小圆点.,但不能用数字开头,也不要使用关键字。
包说明:Scala 有两种包的管理风格,一种方式和 Java 的包管理风格相同,每个源文件一个包(包 名和源文件所在路径不要求必须一致),包名用“.”进行分隔以表示包的层级关系,如 com.atguigu.scala。另一种风格,通过嵌套的风格表示层级关系。
包对象:在 Scala 中可以为每个包定义一个同名的包对象,定义在包对象中的成员,作为其对应包下所有 class 和 object 的共享变量,可以被直接访问。
2、类和对象
类:可以看成一个模板 对象:表示具体的事物
1)、定义类
Java 中的类如果类是 public 的,则必须和文件名一致。 一般,一个.java 有一个 public 类 注意:Scala 中没有 public,一个.scala 中可以写多个类。
基本语法:[修饰符] class 类名 { 类体 }
说明:(1)Scala 语法中,类并不声明为 public,所有这些类都具有公有可见性(即默认就是 public)
(2)一个 Scala 源文件可以包含多个类
2)、属性
属性是类的一个组成部分
基本语法:[修饰符] var|val 属性名称 [:类型] = 属性值
注:Bean 属性(@BeanPropetry),可以自动生成规范的 setXxx/getXxx 方法
import scala.beans.BeanProperty
class Person {
var name: String = "bobo" //定义属性
var age: Int = _ // _表示给属性一个默认值
//Bean 属性(@BeanProperty)
@BeanProperty var sex: String = "男"
//val 修饰的属性不能赋默认值,必须显示指定
}
object Person {
def main(args: Array[String]): Unit = {
var person = new Person()
println(person.name)
person.setSex("女")
println(person.getSex)
}
}
3)、方法
基本语法:def 方法名(参数列表) [:返回值类型] = { 方法体 }
4)、创建对象
基本语法:val | var 对象名 [:类型] = new 类型()
(1)val 修饰对象,不能改变对象的引用(即:内存地址),可以改变对象属性的值。
(2)var 修饰对象,可以修改对象的引用和修改对象的属性值
(3)自动推导变量类型不能多态,所以多态需要显示声明
class Person {
var name: String = "canglaoshi"
}
object Person {
def main(args: Array[String]): Unit = {
//val 修饰对象,不能改变对象的引用(即:内存地址),可以改变对象属
性的值。
val person = new Person()
person.name = "bobo"
// person = new Person()// 错误的
println(person.name)
}
}
5)、构造器
和 Java 一样,Scala 构造对象也需要调用构造方法,并且可以有任意多个构造方法。 Scala 类的构造器包括:主构造器和辅助构造器。
基本语法: class 类名(形参列表) { // 主构造器 // 类体 def this(形参列表) { // 辅助构造器 } def this(形参列表) { //辅助构造器可以有多个... } }
说明:
(1)辅助构造器,函数的名称 this,可以有多个,编译器通过参数的个数及类型 来区分。 (2)辅助构造方法不能直接构建对象,必须直接或者间接调用主构造方法。
(3)构造器调用其他另外的构造器,要求被调用构造器必须提前声明。
案例:
//(1)如果主构造器无参数,小括号可省略
//class Person (){
class Person {
var name: String = _
var age: Int = _
def this(age: Int) {
this()
this.age = age
println("辅助构造器")
}
def this(age: Int, name: String) {
this(age)
this.name = name
}
println("主构造器")
}
object Person {
def main(args: Array[String]): Unit = {
val person2 = new Person(18)
}
}构造器参数说明: Scala 类的主构造器函数的形参包括三种类型:未用任何修饰、var 修饰、val 修饰 。
(1)未用任何修饰符修饰,这个参数就是一个局部变量
(2)var 修饰参数,作为类的成员属性使用,可以修改
(3)val 修饰参数,作为类只读属性使用,不能修改
3、封装
封装就是把抽象出的数据和对数据的操作封装在一起,数据被保护在内部,程序的其它部分只有通过被授权的操作(成员方法),才能对数据进行操作。
Java 封装操作如下:
(1)将属性进行私有化
(2)提供一个公共的 set 方法,用于对属性赋值
(3)提供一个公共的 get 方法,用于获取属性的值
Scala 中的 public 属性,底层实际为 private,并通过 get 方法(obj.field())和 set 方法 (obj.field_=(value))对其进行操作。所以 Scala 并不推荐将属性设为 private,再为其设置 public 的 get 和 set 方法的做法。但由于很多 Java 框架都利用反射调用 getXXX 和 setXXX 方 法,有时候为了和这些框架兼容,也会为Scala 的属性设置 getXXX 和 setXXX 方法(通过 @BeanProperty 注解实现)。
4、继承和多态
基本语法 :class 子类名 extends 父类名 { 类体 }
(1)子类继承父类的属性和方法
(2)scala 是单继承
(3)继承的调用顺序:父类构造器->子类构造器
案例:
class Person(nameParam: String) {
var name = nameParam
var age: Int = _
def this(nameParam: String, ageParam: Int) {
this(nameParam)
this.age = ageParam
println("父类辅助构造器")
}
println("父类主构造器")
}
class Emp(nameParam: String, ageParam: Int) extends
Person(nameParam, ageParam) {
var empNo: Int = _
def this(nameParam: String, ageParam: Int, empNoParam: Int) {
this(nameParam, ageParam)
this.empNo = empNoParam
println("子类的辅助构造器")
}
println("子类主构造器")
}
object Test {
def main(args: Array[String]): Unit = {
new Emp("z3", 11,1001)
}
}
5、抽象类
1)、抽象属性和抽象方法
基本语法
(1)定义抽象类:abstract class Person{} //通过 abstract 关键字标记抽象类
(2)定义抽象属性:val|var name:String //一个属性没有初始化,就是抽象属性
(3)定义抽象方法:def hello():String //只声明而没有实现的方法,就是抽象方法
继承&重写
(1)如果父类为抽象类,那么子类需要将抽象的属性和方法实现,否则子类也需声明 为抽象类 、
(2)重写非抽象方法需要用 override 修饰,重写抽象方法则可以不加 override。
(3)子类中调用父类的方法使用 super 关键字
(4)子类对抽象属性进行实现,父类抽象属性可以用 var 修饰; 子类对非抽象属性重写,父类非抽象属性只支持 val 类型,而不支持 var。 因为 var 修饰的为可变变量,子类继承之后就可以直接使用,没有必要重写
2)匿名子类
说明:和 Java 一样,可以通过包含带有定义或重写的代码块的方式创建一个匿名的子类。
案例:
abstract class Person {
val name: String
def hello(): Unit
}
object Test {
def main(args: Array[String]): Unit = {
val person = new Person {
override val name: String = "teacher"
override def hello(): Unit = println("hello teacher")
}
}
}6、单例对象(伴生对象)
Scala语言是完全面向对象的语言,所以并没有静态的操作(即在Scala中没有静态的概 念)。但是为了能够和Java语言交互(因为Java中有静态概念),就产生了一种特殊的对象 来模拟类对象,该对象为单例对象。若单例对象名与类名一致,则称该单例对象这个类的伴 生对象,这个类的所有“静态”内容都可以放置在它的伴生对象中声明。
1)、单例对象语法
基本语法 object Person{ val country:String="China" }
说明 :
(1)单例对象采用 object 关键字声明
(2)单例对象对应的类称之为伴生类,伴生对象的名称应该和伴生类名一致。
(3)单例对象中的属性和方法都可以通过伴生对象名(类名)直接调用访问。
案例实操:
//(1)伴生对象采用 object 关键字声明
object Person {
var country: String = "China"
}
//(2)伴生对象对应的类称之为伴生类,伴生对象的名称应该和伴生类名一致。
class Person {
var name: String = "bobo"
}
object Test {
def main(args: Array[String]): Unit = {
//(3)伴生对象中的属性和方法都可以通过伴生对象名(类名)直接调用访
问。
println(Person.country)
}
}
2)、apply 方法
说明:
(1)通过伴生对象的 apply 方法,实现不使用 new 方法创建对象。
(2)如果想让主构造器变成私有的,可以在()之前加上 private。
(3)apply 方法可以重载。
(4)Scala 中 obj(arg)的语句实际是在调用该对象的 apply 方法,即 obj.apply(arg)。用 以统一面向对象编程和函数式编程的风格。
(5)当使用 new 关键字构建对象时,调用的其实是类的构造方法,当直接使用类名构 建对象时,调用的其实时伴生对象的 apply 方法。
案例:
object Test {
def main(args: Array[String]): Unit = {
//(1)通过伴生对象的 apply 方法,实现不使用 new 关键字创建对象。
val p1 = Person()
println("p1.name=" + p1.name)
val p2 = Person("bobo")
println("p2.name=" + p2.name)
}
}
//(2)如果想让主构造器变成私有的,可以在()之前加上 private
class Person private(cName: String) {
var name: String = cName
}
object Person {
def apply(): Person = {
println("apply 空参被调用")
new Person("xx")
}
def apply(name: String): Person = {
println("apply 有参被调用")
new Person(name)
}
//注意:也可以创建其它类型对象,并不一定是伴生类对象
}
7、特质(Trait)
Scala 语言中,采用特质 trait(特征)来代替接口的概念,也就是说,多个类具有相同 的特质(特征)时,就可以将这个特质(特征)独立出来,采用关键字 trait 声明。 Scala 中的 trait 中即可以有抽象属性和方法,也可以有具体的属性和方法,一个类可 以混入(mixin)多个特质。这种感觉类似于 Java 中的抽象类。 Scala 引入 trait 特征,第一可以替代 Java 的接口,第二个也是对单继承机制的一种 补充。
















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











