







scala集合
1、集合简介
1)Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable 特质。
2)对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两 个包 不可变集合:scala.collection.immutable 可变集合: scala.collection.mutable
3)Scala 不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而 不会对原对象进行修改。类似于 java 中的 String 对象
4)可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似 于 java 中 StringBuilder 对象
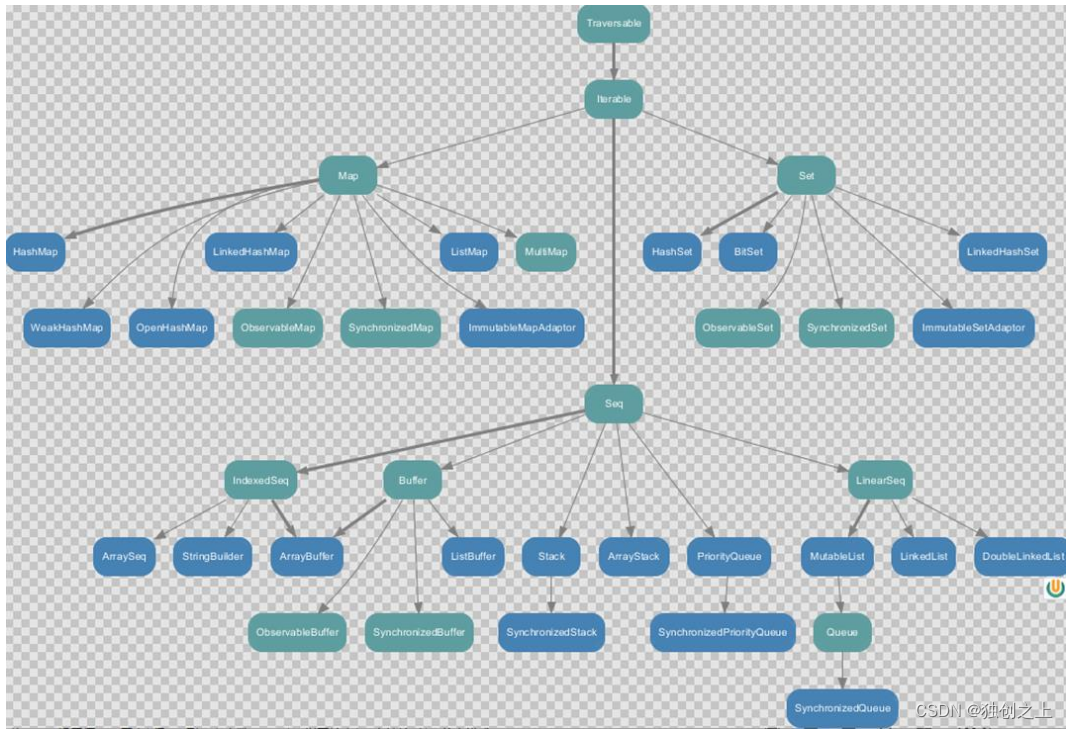
1)、不可变集合继承图(即类型转变的顺序)

IndexedSeq 和 LinearSeq 的区别: (1)IndexedSeq 是通过索引来查找和定位,因此速度快,比如 String 就是一个索引集合,通过索引即可定位。(2)LinearSeq 是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找。
2)、可变集合继承图(增加了一个buffer来存储数据)
2、数组
1)不可变数组
(1)第一种方式定义数组
定义:val arr1 = new Array[Int](10)
(1)new 是关键字
(2)[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定 Any
(3)(10),表示数组的大小,确定后就不可以变化。
案例: 创建不可变数组,修改数据到新数组
object TestArray{
def main(args: Array[String]): Unit = {
//(1)数组定义
val arr01 = new Array[Int](4)
println(arr01.length) // 4
//(2)数组赋值
//(2.1)修改某个元素的值
arr01(3) = 10
//(2.2)采用方法的形式给数组赋值
arr01.update(0,1)
//(3)遍历数组
//(3.1)查看数组
println(arr01.mkString(","))
//(3.2)普通遍历
for (i <- arr01) {
println(i)
}
//(3.3)简化遍历
def printx(elem:Int): Unit = {
println(elem)
}
arr01.foreach(printx)
// arr01.foreach((x)=>{println(x)})
// arr01.foreach(println(_))
arr01.foreach(println)
//(4)增加元素(由于创建的是不可变数组,增加元素,其实是产生新的数组)
println(arr01)
val ints: Array[Int] = arr01 :+ 5
println(ints)
}
}2)可变数组
(1)定义变长数组
val arr01 = ArrayBuffer[Any](3, 2, 5)
(1)[Any]存放任意数据类型
(2)(3, 2, 5)初始化好的三个元素
(3)ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer
案例:创建可变数组,并操作数据
object TestArrayBuffer {
def main(args: Array[String]): Unit = {
//(1)创建并初始赋值可变数组
val arr01 = ArrayBuffer[Any](1, 2, 3)
//(2)遍历数组
for (i <- arr01) {
println(i)
}
println(arr01.length) // 3
println("arr01.hash=" + arr01.hashCode())
//(3)增加元素
//(3.1)追加数据
arr01.+=(4)
//(3.2)向数组最后追加数据
arr01.append(5,6)
//(3.3)向指定的位置插入数据
arr01.insert(0,7,8)
println("arr01.hash=" + arr01.hashCode())
//(4)修改元素
arr01(1) = 9 //修改第 2 个元素的值
println("--------------------------")
for (i <- arr01) {
println(i)
}
println(arr01.length) // 5
}
3)不可变数组与可变数组的转换
1)说明
arr1.toBuffer //不可变数组转可变数组
arr2.toArray //可变数组转不可变数组
(1)arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化
(2)arr1.toBuffer 返回结果才是一个可变数组,arr1 本身没有变化
4)多维数组
1)多维数组定义
val arr = Array.ofDim[Double](3,4)
说明:二维数组中有三个一维数组,每个一维数组中有四个元素
3、列表 List
1)不可变 List
(1)说明
(1)List 默认为不可变集合
(2)创建一个 List(数据有顺序,可重复)
(3)遍历 List
(4)List 增加数据
(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
(6)取指定数据
(7)空集合 Nil
案例实操:
package cn.itjdb.chapter07
/**
* list列表:不可变,用于排列和保存一组数
* List 默认为不可变集合
*/
object test04_List {
def main(args: Array[String]): Unit = {
//创建一个list
val list = List(12, 32, 34, 53)
println(list)
//访问和遍历元素
println(list(0))
list.foreach(println)
//添加元素
val list2=list:+89
// val list3=20 +: list
val list3= list.+:(20) //在列表前面添加元素
println(list)
println(list2)
println(list3)
}
}2)可变ListBuffer
(1)说明
(1)创建一个可变集合 ListBuffer
(2)向集合中添加数据
(3)打印集合数据
案例:
object TestList {
def main(args: Array[String]): Unit = {
//(1)创建一个可变集合
val buffer = ListBuffer(1,2,3,4)
//(2)向集合中添加数据
buffer.+=(5)
buffer.append(6)
buffer.insert(1,2)
//(3)打印集合数据
buffer.foreach(println)
//(4)修改数据
buffer(1) = 6
buffer.update(1,7)
//(5)删除数据
buffer.-(5)
buffer.-=(5)
buffer.remove(5)
}
}4、Set 集合
默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用 scala.collection.mutable.Set 包
1)不可变 Set
(1)说明
(1)Set 默认是不可变集合,数据无序
(2)数据不可重复
(3)遍历集合
2)可变Mutable.Set
(1)说明
(1)创建可变集合 mutable.Set
(2)打印集合
(3)集合添加元素
(4)向集合中添加元素,返回一个新的 Set
(5)删除数据
案例:
object TestSet {
def main(args: Array[String]): Unit = {
//(1)创建可变集合
val set = mutable.Set(1,2,3,4,5,6)
//(3)集合添加元素
set += 8
//(4)向集合中添加元素,返回一个新的 Set
val ints = set.+(9)
println(ints)
println("set2=" + set)
//(5)删除数据
set-=(5)
//(2)打印集合
set.foreach(println)
println(set.mkString(","))
}
}
5 、Map 集合
Scala 中的 Map 和 Java 类似,也是一个散列表,它存储的内容也是键值对(key-value) 映射。
1)可变Map集合
1)说明
(1)创建不可变集合 Map
(2)循环打印
(3)访问数据
(4)如果 key 不存在,返回 0
2)不可变Map集合
1)说明
(1)创建可变集合
(2)打印集合
(3)向集合增加数据
(4)删除数据
(5)修改数据
6、元组
1)说明 元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,称为元组。 注意:元组中最大只能有 22 个元素。
object test08_tuple {
def main(args: Array[String]): Unit = {
val tuple=("nihao",23,'a')
//通过元素的顺序进行访问,调用方式:_顺序号
println(tuple._1)
println(tuple._2)
println(tuple._3)
//遍历元组,通过迭代器访问数据
for (elem <- tuple.productIterator) println(elem)
println("================================")
//嵌套元组
val tuple2=("nihao",23,('a',0),("boolean",true),"asd")
println(tuple2._4._2)
}
}7、集合常用函数操作
object test09_CommonOp {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7)
val set=Set(12,34,23,45,56,12,21)
println(list)
println(set)
// (1)获取集合长度
println(list.length)
// (2)获取集合大小
println(set.size)
// (3)循环遍历
for (elem<-list) println(elem)
set.foreach(println)
println("==============================")
// (4)迭代器
for (elem<-list.iterator) println(elem)
// (5)生成字符串
println(list.mkString("--"))
println(set.mkString(","))
// (6)是否包含
println(list.contains(23))
println(set.contains(12))
}
}衍生集合
object test10_DerivedCollection {
def main(args: Array[String]): Unit = {
val list=List(12,34,56,78,23,112,34)
println(list)
//(1)获取集合的头
println(list.head)
// (2)获取集合的尾(不是头的就是尾)
println(list.tail)
// (3)集合最后一个数据
println(list.last)
// (4)集合初始数据(不包含最后一个)
println(list.init)
println(list.indices) //结果:Range 0 until 7
// (5)反转
println(list.reverse)
// (6)取前(后)n 个元素
println(list.take(4))
println(list.takeRight(5))
// (7)去掉前(后)n 个元素
println(list.drop(2))
println(list.dropRight(3))
println(list)
println("===================-===================")
val list2=List(23,12,234,54,21,35,31)
// (8)并集,如果是set集合,会去重
println(list.union(list2))
// (9)交集
println(list.intersect(list2))
// (10)差集
println(list.diff(list2)) //属于list不属于list2
// (11)拉链,两个list对应元素配对形成二元组
println("zip:"+list.zip(list2))
println("zip2:"+list2.zip(list))
// (12)滑窗
println(list.sliding(3)) //<iterator>类型,需要遍历
for (elem<-list.sliding(3)) println(elem) //是由数个集合构成的
println("======================================")
for (elem<-list2.sliding(3,3)) println(elem) //是由数个集合构成的
}
}计算简单函数
object test11_SimpleFunction {
def main(args: Array[String]): Unit = {
val list=List(3,5,5,2,-4,1,-7)
val list2=List(("a",2),("b",4),("c",8),("d",3),("e",5))
// (1)求和
println(list.sum)
// (2)求乘积
println(list.product)
// (3)最大值
println(list.max)
println(list2.maxBy((tuple:(String,Int))=>tuple._2))
// (4)最小值
println(list.min)
// (5)排序
println("===================================================")
val list3=list.sorted
println(list3)
//从大到小逆序排列
println(list.sorted.reverse)
println(list.sorted(Ordering[Int].reverse)) //传入隐私参数
//对一个属性或多个属性进行排序,通过它的类型。
println(list2.sortBy((tuple:(String,Int))=>tuple._2))
println(list2.sortBy(_._2).reverse)
//基于函数的排序,通过一个 comparator 函数,实现自定义排序的逻辑。sortWith
println(list.sortWith(_ < _))
}
}计算高级函数
object test12_HighLevelFunction {
def main(args: Array[String]): Unit = {
val list=List(1,2,3,4,5,6,7,8,9,10)
// (1)过滤:遍历一个集合并从中获取满足指定条件的元素组成一个新的集合
val enveList=list.filter((elem:Int)=>(elem % 2==0))
println(enveList)
// (2)转化/映射(map) :将集合中的每一个元素映射到某一个函数
println(list.map((elem:Int)=>elem *2))
println(list.map(_*2))
println(list.map(x=>x*x))
// (3)扁平化
val nestedList=List(List(1,2,3),List(4,5,6),List(7,8))
val flatList=nestedList(0):::nestedList(1):::nestedList(2)
println(flatList)
println(nestedList.flatten)
println("==============================================================")
// (4)扁平化+映射 注:flatMap 相当于先进行 map 操作,在进行 flatten 操作
// 集合中的每个元素的子元素映射到某个函数并返回新集合
val strings = List("hello world", "hello scala", "we study")
val stringses = strings.map(strings => strings.split(" "))
println(stringses.flatten)
//等价于
val strings1 = strings.flatMap(strings => strings.split(" "))
println(strings1)
println("==============================================================")
// (5)分组(group):按照指定的规则对集合的元素进行分组
//分成奇偶两组
val groupby1: Map[Boolean, List[Int]] = list.groupBy(elem => elem % 2 == 0)
println(groupby1)
val groupby2 = list.groupBy(elem => if (elem % 2 == 0) "偶数" else "奇数")
println(groupby2)
//给定词汇,按照单词首字母进行分组
println(strings.groupBy(_.charAt(0)))
println("=================================================================")
// (6)简化(归约)reduce操作
//Reduce 简化(归约) :通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最终获取结果。
println(list.reduce(_+_))
println(list.reduceLeft(_+_))
println(list.reduceRight(_+_))
println(list.reduce(_-_))
println(list.reduceLeft(_-_))
println(list.reduceRight(_-_)) //-5:实际是一个递归操作。1-(2-(3-(4-(5-(6-(7-(8—(9-10))))))))
// (7)折叠fold
println(list.fold(10)(_+_)) //flod中的10代表初始值结果:10+1+2+3+4+5+6+7...
println(list.foldLeft(10)(_+_)) //相对于fold区别在于函数中的值可以不一样
}
}8、案例:简单WordCount操作
1)需求
单词计数:将集合中出现的相同的单词,进行计数,取计数排名前三的结果
2)需求分析

object test01_WordCountSimple {
def main(args: Array[String]): Unit = {
val strings: List[String] = List("hello word",
"hello spark",
"hello scala",
"hello spark from scala",
"hello flink from scala")
//第一步,首先将list中字符串划分,并flatten
// val listString: List[Array[String]] = strings.map(elem => elem.split(" "))
// val listString2=listString.flatten
// println(listString2)
//等价于
val strings1: List[String] = strings.flatMap(_.split(" "))
println(strings1)
//第二步,将划分好的数据进行分组
val stringToList: Map[String, List[String]] = strings1.groupBy(name => name)
println(stringToList)
//第三步,将分好组的数据进行取长度,得到每个单词的个数
val stringToInt: Map[String, Int] = stringToList.map(kv => (kv._1, kv._2.length))
println(stringToInt)
//第四步,将map集合转换为list集合,并进行排序
val list: List[(String, Int)] = stringToInt.toList
println(list)
val tuples: List[(String, Int)] = list.sortWith(_._2 > _._2).take(3)
println(tuples)
}
}scala模式匹配
Scala 中的模式匹配类似于 Java 中的 switch 语法。
1、基本语法
模式匹配语法中,采用 match 关键字声明,每个分支采用 case 关键字进行声明,当需 要匹配时,会从第一个 case 分支开始,如果匹配成功,那么执行对应的逻辑代码,如果匹 配不成功,继续执行下一个分支进行判断。如果所有 case 都不匹配,那么会执行 case _分支, 类似于 Java 中 default 语句。
package cn.itjdb.chapter09
/**
* 基本模式匹配语法
*/
object test01_PattenMatchBase {
def main(args: Array[String]): Unit = {
val a=3
val b=4
val operator='+'
val result=operator match {
case '+' =>a+b
case '-'=>a-b
case '*'=>a*b
case '/'=>a/b
case _=>"illegal"
}
println(result)
//模式守卫,如果想要表达匹配某个范围的数据,就需要在模式匹配中增加条件守卫。
def abs(num :Int):Int= num match {
case i:Int if i<=0 => -i
case j:Int if j>0 => j
}
println(abs(-8))
}
}
(1)说明
(1)如果所有 case 都不匹配,那么会执行 case _ 分支,类似于 Java 中 default 语句, 若此时没有 case _ 分支,那么会抛出 MatchError。
(2)每个 case 中,不需要使用 break 语句,自动中断 case。
(3)match case 语句可以匹配任何类型,而不只是字面量。
(4)=> 后面的代码块,直到下一个 case 语句之前的代码是作为一个整体执行,可以 使用{}括起来,也可以不括。
2、模式守卫
1)说明 如果想要表达匹配某个范围的数据,就需要在模式匹配中增加条件守卫。
3、模式匹配类型
1)、匹配常量
(1)说明
Scala 中,模式匹配可以匹配所有的字面量,包括字符串,字符,数字,布尔值等等。
2 )、匹配类型
(1)说明
需要进行类型判断时,可以使用前文所学的 isInstanceOf[T]和 asInstanceOf[T],也可使 用模式匹配实现同样的功能。
3)、 匹配数组
1)说明
scala 模式匹配可以对集合进行精确的匹配,例如匹配只有两个元素的、且第一个元素 为 0 的数组。
4、 匹配列表
5、匹配元组
案例实操:
package cn.itjdb.chapter09
/**
* 模式匹配类型
*/
object test02_MatchTypes {
def main(args: Array[String]): Unit = {
//匹配常量
def matchConstant(x:Any) =x match {
case 1 => "Int one"
case "hello" => "hello scala"
case true=>"hello Boolean"
case '-'=>"char -"
case _ => "没有匹配到!"
}
println(matchConstant(2))
println(matchConstant("hello"))
println(matchConstant((1==1)))
println(matchConstant('-'))
println("===========================================")
//匹配类型
def matchType(x:Any):String=x match {
case i:Int=>"Int" +" "+i
case s:String=>"String" +" "+ s
case list:List[_]=>"List" +" "+list
case array:Array[_]=>"Array"+" "+array.mkString(",")
case _=>"没有匹配到!"
}
println(matchType(2))
println(matchType("hello"))
println(matchType((1==1)))
println(matchType('-'))
println(matchType(List(1, 2, 3, 4, 5)))
println(matchType(Array("asv")))
println(matchType(Array(1,2,3,4,5,5)))
println("=========================================================")
//匹配数组,
// scala 模式匹配可以对集合进行精确的匹配
for (arr <- List(
Array(0),
Array(1,0), //若在匹配选项中已经匹配到了,就不会继续后续的匹配
Array(0,1,0),
Array(1,1,0),
Array(23,45,62,2),
Array("hello",1,0),
)) {
val result=arr match {
case Array(0) => "0"
case Array(1,0) => "Array(1,0)"
case Array(x,y) => "Array:" +x+ ","+y //匹配两元素数组
case Array(0,_*) => "匹配以0开头的数组"
case Array(x,1,z) => "匹配中间为1的三元数组"
case _ => "没有匹配的选项!"
}
println(result)
}
println("=========================================================")
//匹配列表
/**
* 方式1
*/
for (list <- List(
List(0),
List(0,1),
List(0,1,2),
List(1,2,1),
List(88)
)){
val result2=list match {
case List(0)=>"0"
case List(x,y) => "List(x,y):"+x+","+y
case List(0,_*) => "List,以0开头"
case List(a) => "List(a):"+a
case _ => "没有匹配的选项!"
}
println(result2)
}
/**
* 方式2
*/
val list: List[Int] = List(1, 2, 5, 6, 7)
list match {
case first :: second :: rest => println(first + "-" +
second + "-" + rest) //1-2-List(5, 6, 7)
case _ => println("something else")
}
println("==========================================================")
//元组匹配
//对一个元组集合进行遍历
for (tuple <- Array((0, 1), (1, 0), (1, 1), ( 1, 0, 2))) {
val result = tuple match {
case (0, _) => "0 ..." //是第一个元素是 0 的元组
case (y, 0) => "" + y + "0" // 匹配后一个元素是 0 的对偶元组
case (a, b) => "" + a + " " + b
case _ => "something else" //默认
}
println(result)
}
//扩展案例
val List(first,second,thrid)=List(1,23,5)
println(first)
val fir::sec::rest=List(323,34,5,22)
println(s"first:$fir,second:$sec,rest:$rest")
//在for推导中进行模式匹配
val tuples: List[(String, Int)] = List(("a", 12), ("b", 6), ("c", 37),("a",34))
for (elem <-tuples){
println(elem._1+" "+elem._2)
}
//将list的元素直接定义为元组,对变量赋值
for ((word,count) <-tuples){
println(word+" "+count)
}
//可以不考虑某个位置的变量,只遍历key或者value
for ((word,_) <-tuples){
println(word)
}
//可以指定某个位置的值必须是多少
for (("a",count) <-tuples){
println(count)
}
}
}
6、匹配对象及样例类
package cn.itjdb.chapter09
/**
* 模式匹配对象
* @date 2022-07-03-8:53
*/
object test03_MatchObject {
def main(args: Array[String]): Unit = {
val user = new User("tom", 29)
//针对对象实例的内容进行匹配
val result=user match {
case User("tom",29) => "tom 29"
case _=> "未匹配"
}
println(result)
}
}
class User(val name:String,val age:Int)
//增加一个伴生对象,进行应用和拆解
object User{
def apply(name: String, age: Int): User = new User(name, age)
//必须实现一个unapply方法,用来对对象属性进行拆解
def unapply(user: User): Option[(String, Int)] = {
if (user==null){
None
}else{
//unapply 方法将 user 对象的 name 和 age 属性提取出来,与 User("zhangsan", 11)中的属性值进行 匹配
Some(user.name,user.age)
}
}
}小结
➢ val user = User("zhangsan",11),该语句在执行时,实际调用的是 User 伴生对象中的 apply 方法,因此不用 new 关键字就能构造出相应的对象。
➢ 当将 User("zhangsan", 11)写在 case 后时[case User("zhangsan", 11) => "yes"],会默 认调用 unapply 方法(对象提取器),user 作为 unapply 方法的参数,unapply 方法 将 user 对象的 name 和 age 属性提取出来,与 User("zhangsan", 11)中的属性值进行 匹配
➢ case 中对象的 unapply 方法(提取器)返回 Some,且所有属性均一致,才算匹配成功, 属性不一致,或返回 None,则匹配失败。
➢ 若只提取对象的一个属性,则提取器为 unapply(obj:Obj):Option[T] 若提取对象的多个属性,则提取器为 unapply(obj:Obj):Option[(T1,T2,T3…)] 若提取对象的可变个属性,则提取器为 unapplySeq(obj:Obj):Option[Seq[T]]
(2)样例类
(1)语法: case class Person (name: String, age: Int)
(2)说明
○1 样例类仍然是类,和普通类相比,只是其自动生成了伴生对象,并且伴生对象中 自动提供了一些常用的方法,如 apply、unapply、toString、equals、hashCode 和 copy。
○2 样例类是为模式匹配而优化的类,因为其默认提供了 unapply 方法,因此,样例 类可以直接使用模式匹配,而无需自己实现 unapply 方法。
○3 构造器中的每一个参数都成为 val,除非它被显式地声明为 var(不建议这样做)
package cn.itjdb.chapter09
/**
* 样例类模式匹配,不需要写伴生对象进行应用和拆解
*/
object test04_MatchCaseClass {
def main(args: Array[String]): Unit = {
val user = User1("tom", 29)
//针对对象实例的内容进行匹配
val result=user match {
case User1("tom",29) => "tom 29"
case _=> "未匹配"
}
println(result)
}
}
case class User1(name:String,age:Int)
(3) 变量声明中的模式匹配
case class Person(name: String, age: Int)
object TestMatchVariable {
def main(args: Array[String]): Unit = {
val (x, y) = (1, 2)
println(s"x=$x,y=$y")
val Array(first, second, _*) = Array(1, 7, 2, 9)
println(s"first=$first,second=$second")
val Person(name, age) = Person1("zhangsan", 16)
println(s"name=$name,age=$age")
}
}(4)for 表达式中的模式匹配
object TestMatchFor {
def main(args: Array[String]): Unit = {
val map = Map("A" -> 1, "B" -> 0, "C" -> 3)
for ((k, v) <- map) { //直接将 map 中的 k-v 遍历出来
println(k + " -> " + v) //3 个
}
println("----------------------")
//遍历 value=0 的 k-v ,如果 v 不是 0,过滤
for ((k, 0) <- map) {
println(k + " --> " + 0) // B->0
}
println("----------------------")
//if v == 0 是一个过滤的条件
for ((k, v) <- map if v >= 1) {
println(k + " ---> " + v) // A->1 和 c->33
}
}
}
7、偏函数中的模式匹配
偏函数也是函数的一种,通过偏函数我们可以方便的对输入参数做更精确的检查。例如 该偏函数的输入类型为 List[Int],而我们需要的是第一个元素是 0 的集合,这就是通过模式 匹配实现的。
偏函数定义:
val second: PartialFunction[List[Int], Option[Int]] = { case x :: y :: _ => Some(y) }

偏函数原理
上述代码会被 scala 编译器翻译成以下代码,与普通函数相比,只是多了一个用于参数 检查的函数——isDefinedAt,其返回值类型为 Boolean。
偏函数使用
偏函数不能像 second(List(1,2,3))这样直接使用,因为这样会直接调用 apply 方法,而应 该调用 applyOrElse 方法,如下 second.applyOrElse(List(1,2,3), (_: List[Int]) => None) applyOrElse 方法的逻辑为 if (ifDefinedAt(list)) apply(list) else default。如果输入参数满 足条件,即 isDefinedAt 返回 true,则执行 apply 方法,否则执行 defalut 方法,default 方法 为参数不满足要求的处理逻辑。
package cn.itjdb.chapter09
/**
* 偏函数中的模式匹配
* 偏函数也是函数的一种,通过偏函数我们可以方便的对输入参数做更精确的检查。
*/
object test05_PartialFunction {
def main(args: Array[String]): Unit = {
val tuples: List[(String, Int)] = List(("a", 12), ("b", 6), ("c", 37),("a",34))
//需求:将元组中的key不变,value*2
val tuples1: List[(String, Int)] = tuples.map(elem => (elem._1, elem._2 * 2))
//使用模式匹配对元组元素赋值,实现功能
val tuples2: List[(String, Int)] = tuples.map(elem => {
elem match {
case (word, count) => (word, count * 2)
}
})
//使用偏函数的模式匹配,省略lambda表达式的写法,进行简化
val tuples3: List[(String, Int)] = tuples.map {
case (word, count) => (word, count * 2)
}
println(tuples1)
println(tuples2)
println(tuples3)
//偏函数的应用,求绝对值
//对输入数据分为不同的情形,正、负、0
val postiveAbs:PartialFunction[Int,Int]={
case x if x>0 =>x
}
val negativeAbs:PartialFunction[Int,Int]={
case x if x<0 => -x
}
val zeroAbs:PartialFunction[Int,Int]={
case 0=>0
}
def abs(x:Int): Int=(postiveAbs orElse negativeAbs orElse zeroAbs)(x)
println(abs(3))
println(abs(-3))
println(abs(0))
}
}
其他
Scala 异常处理
def main(args: Array[String]): Unit = {
try {
var n= 10 / 0
}catch {
case ex: ArithmeticException=>{
// 发生算术异常
println("发生算术异常")
}
case ex: Exception=>{
// 对异常处理
println("发生了异常 1")
println("发生了异常 2")
}
}finally {
println("finally")
}
}
1)我们将可疑代码封装在 try 块中。在 try 块之后使用了一个 catch 处理程序来捕获异 常。如果发生任何异常,catch 处理程序将处理它,程序将不会异常终止。
2)Scala 的异常的工作机制和 Java 一样,但是 Scala 没有“checked(编译期)”异常, 即 Scala 没有编译异常这个概念,异常都是在运行的时候捕获处理。
3)异常捕捉的机制与其他语言中一样,如果有异常发生,catch 子句是按次序捕捉的。 因此,在 catch 子句中,越具体的异常越要靠前,越普遍的异常越靠后,如果把越普遍的异 常写在前,把具体的异常写在后,在 Scala 中也不会报错,但这样是非常不好的编程风格。
4)finally 子句用于执行不管是正常处理还是有异常发生时都需要执行的步骤,一般用 于对象的清理工作,这点和 Java 一样。
5)用 throw 关键字,抛出一个异常对象。所有异常都是 Throwable 的子类型。throw 表 达式是有类型的,就是 Nothing,因为 Nothing 是所有类型的子类型,所以 throw 表达式可以用在需要类型的地方
6)java 提供了 throws 关键字来声明异常。可以使用方法定义声明异常。它向调用者函 数提供了此方法可能引发此异常的信息。它有助于调用函数处理并将该代码包含在 try-catch 块中,以避免程序异常终止。在 Scala 中,可以使用 throws 注解来声明异常
















 2112
2112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











