







核心内容:
1、小编带你通过WordCount程序查看Spark与MapReduce的诸多雷同情节
今天通过数据流动的角度再一次从整体上认知了Spark中的WordConunt程序,但是在分析的过程中,给我的第一个感觉就是Spark的运行过程与MapReduce有很多相似之处,接下来就仔细分下一下:
首先,从整体上而言,MapReduce的运行过程分为两个阶段:Mapper阶段和Reducer阶段,用户只需要实现map函数和reduce函数,即可实现分布式计算,但是我们来看一下WordCount在Spark中的DAG图:
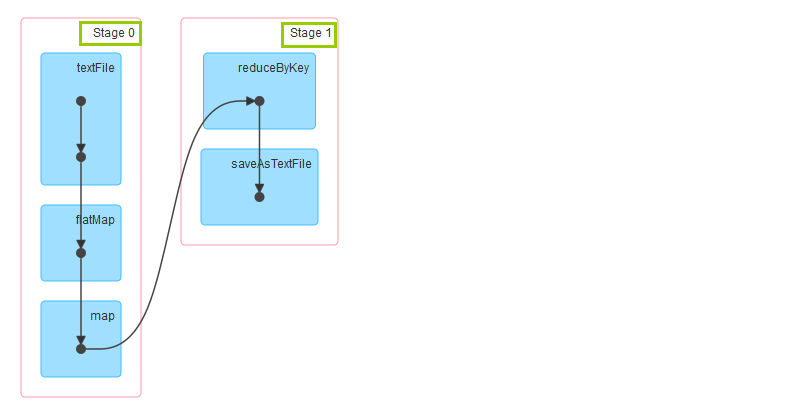
呵呵,你没有看错,WordCount在Spark当中也分为两个阶段,只不过阶段的名字改成了Stage0和Stage1。接下来我们在从细节上对比一下两者:
Spark中第一个阶段产生的RDD:
HadoopRDD、 MapPartitionsRDD、MapPartitionsRDD、MapPartitionsRDD、MapPartitionsRDD(reduceByKey所产生)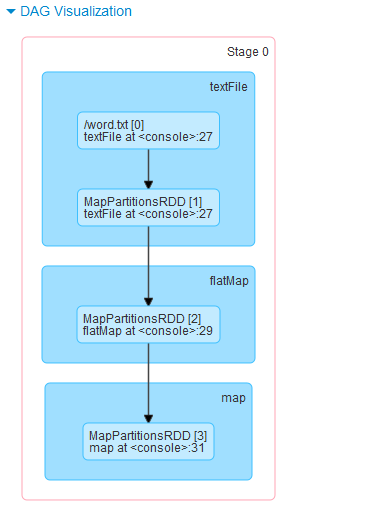
接下来我们逐个分析每个RDD:
HadoopRDD的作用:HadoopRDD会从HDFS上读取分布式文件,并将输入文件以数据分片的方式存在于集群之上,并将输入文件转化成键值对key,value。
在MapReduce程序编写的第一个过程:指定输入文件的路径,并将输入文件在逻辑上切分成若干个Split数据片,并将数据分片按照一定的规则解析成键值对key,value。呵呵,是不是很像!
MapPartitionsRDD的作用:MapPartitionsRDD将HadoopRDD产生的数据分片(partition)中的键值对去掉相应的key,只留value。
我们在看一下MapReduce的相似步骤:map函数的编写逻辑是,拿到日志中的一行数据即v1.toString()……,呵呵,MapReduce对键值对key,value中的key1实际上也不感兴趣。
MapPartitionsRDD的作用:这个MapPartitionsRDD在这里面的作用其实是很简单的,对每个Partition中的每一行内容进行单词切分并合并成一个大的单词实例的集合。
在看一下MapReduce的相似步骤:拿到日志中一行数据,切分各个字段,获取我们所需要的字段,呵呵,差不多吧。
MapPartitionsRDD的作用:这个MapPartitionsRDD在这里面的作用为,在我们单词拆分的基础上对我么的单词计数为1。
我们的MapReduce也是差不多的。
MapPartitionsRDD:进行本地级别(local)的归并操作,并且把统计后的结果按照分区(分区就是将上一阶段的结果分为几个标志交给下一阶段进行处理)策略放到不同的File,这个步骤发生在Stage1的末尾端,减少网络的传输;并将当前阶段作为stage1阶段的内容,放在本地磁盘上,供shuffle阶段使用。本地归并之后就进入了发生网络传输的shuffle。
这个阶段更不用说了,在MapReduce程序编写的第4个步骤:(可选)对本地数据进行本地归并操作,即Combiner操作,Combiner发生在每一个Mapper任务的末尾端,主要用来对输出的数据进行规约处理,即将本地的键值对k2,v2s先进行一次合并操纵,进而通过网络传输的数据变少,传输的时间变短,作业的整体效率提高。
上面两段话是不是非常相似。
接下来我们在看Spark的第二阶段:
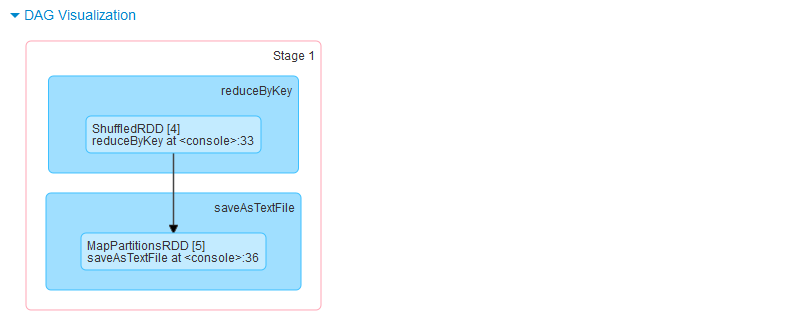
第二阶段产生的RDD:
ShuffledRDD(reduceByKey所产生)、MapPartitionsRDDShuffledRDD的作用:进行全局reduce级别的归并操作。
而我们在看一下MapReduce此处的相似步骤(Reducer任务的第一阶段):对多个Mapper任务的输出,按照不同的分区,通过网络拷贝到不同的Reducer节点上,并将多个Mapper任务的输出进行合并、排序操作—–生成键值对k2,v2s,随后调用reducer函数将输入的键值对k2,v2s转化成键值对k3,v3。
太相似了吧!
MapPartitionsRDD的作用:我们将Stage2产生的结果输出到我们HDFS中的时候数据的输出要符合一定的格式,而我们现在的结果只有value,没有Key,所以MapPartitionsRDD帮助我们生成相应的Key。
在MapReduce的最后一个步骤:指定输出文件的路径,并将输出文件按照一定的格式进行输出。
总结:从WordCount程序来看,MapReduce与Spark在程序的编写过程中有很多的相似之处,看来Spark到底有多强大,还要继续学习了!
















 1788
1788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











