






目录
第一章 线性表
1.1 线性表的定义
“线性表”是由同一类型的数据元素构成的有序序列的线性结构
常见的即有数组与链表两种
| 数组 | 链表 | |
| 优点 | 1. 物理空间上相邻,容易得到空间位置 2. 结构简单 | 1.长度不受限制 2. 中间位置插入/删除容易 |
| 缺点 | 1. 长度需要事先确定,限制元素个数(C++向量可以拓展,但会额外消耗时间) 2.中间不易插入/删除元素 | 1. 需要额外存储指针,消耗更多内存 2. 空间上位置不相邻,高速缓存命中率低 3.调试复杂 |
两者性能相近时(不需要太多的中部插入/删除操作)推荐数组
ADD 二维数组、指针数组、数组指针
1. 指针数组:储存的元素全是指针的数组
//创建一个数组,里面的元素均为int型指针
int* arr[10];2. 数组指针:指向一个数组的指针
//创建一个指向一个有10个int型元素数组的指针
int (*p)[10];
int arr[10];
p = &arr; //使指针指向数组注:指向数组的数组指针并不等同于这个数组的头指针,数组头是这个数组第一个元素存放的地址,而数组指针中存的是这个数组头的地址。即 arr[i] == (*p)[i]
3.二维数组:一个指针数组,其中每个元素又是一个数组头指针
//创建一个4*5的二维数组
int a[4][5];其中 a 是 a[4] 这个数组的数组头,a[4]中每个元素又都是一个数组头,如 a[2] 是 a[2][5]的头
//二维数组的内存动态分配(先外后内)
int** arr = (int**)malloc(row * sizeof(int*));
for(int i = 0; i < row; i++){
//这里不需再用int*定义
//每行可取不一样的长短,若是矩阵,则col[i]都相同即可
arr[i] = (int*)malloc(col[i] * sizeof(int));
}
//内存释放(先内后外)
for(int i = 0; i < row; i++){
free(arr[i]);
}
free(arr);联系:当数组指针中每个指针都是另一些数组的头指针时,即相当于一个二维数组
1.2 线性表的储存实现及操作
1.2.1 一般操作(略)
查找,插入,删除,求表长(链接储存)
注:使用链表时,为保证对所有链结操作的一致性,往往会设置一个不储存信息的空头
1.2.2 静态链表
实质:用数组来实现链表的动态结构
实现思路:给每个数组元素增加一个域,用来储存下一个元素的位置。预先分配一个比较大的空间,但之后的插入删除并不需要移动别的元素。物理空间上依赖于数组,但逻辑链接是链表的思想
| 下标 | data | next |
| 0 | --(空头) | 5 |
| 1 | f | 3 |
| 2 | r | 1 |
| 3 | w | 0(NULL) |
| 4 | ||
| 5 | j | 2 |
| 6 |
插入的话要先结合下标(不为0)及next(为默认值)先找到一个没储存元素的位置使用。
具体实现(C++):
template<class T> class StaticList;
//链结
template<class T>
class SListNode{
friend class StaticList<T>;
private:
T val; //该点数据
int next; //下一点的索引
};
//静态链表
template<class T>
class StaticList{
public:
StaticList(); //初始化
int Length(); //长度
int Search(T x); //查找元素,返回索引,如果没有则返回-1
int Locate(int i); //得到第i个元素的索引,如果没有则返回-1
bool Append(T x); //在末尾添加
bool Insert(int i, T x); //在某个位置添加
bool Remove(int i); //移除
bool IsEmpty(); //是否为空
private:
SListNode<T> elem[MAX_LEN];
int able; //下一个可用位索引
};
template <class T>
StaticList<T>::StaticList():able(1){
elem[0].next = -1; //指向-1即表示NULL
//制作空闲连接表
for(int i = 1; i < MAX_LEN - 1; i++){
elem[i].next = i + 1;
}
elem[MAX_LEN-1].next = -1;
}
template <class T>
int StaticList<T>::Length(){
int res = -1;
int pos = 0;
while(pos != -1){
pos = elem[pos].next;
res++;
}
return res;
}
template <class T>
int StaticList<T>::Search(T x){
int pos = 0;
while(pos != -1){
if(elem[pos].val == x) break;
pos = elem[pos].next;
}
return pos;
}
template <class T>
int StaticList<T>::Locate(int i){
int pos = 0;
while(i > 0 && pos != -1){
pos = elem[pos].next;
i--;
}
return pos;
}
template <class T>
bool StaticList<T>::Append(T x){
if(able == -1) return false;
int tmp = elem[able].next;
elem[able].next = -1;
elem[able].val = x;
//找到链尾
int pos = 0;
while(elem[pos].next != -1) pos = elem[pos].next;
elem[pos].next = able;
able = tmp;
return true;
}
template <class T>
bool StaticList<T>::Insert(int i, T x){
if(able == -1) return false;
int front = Locate(i-1); //去掉伪头,下标从1开始
int tmp = elem[able].next;
elem[able].val = x;
elem[able].next = elem[front].next;
elem[front].next = able;
able = tmp;
return true;
}
template <class T>
bool StaticList<T>::Remove(int i){
int front = Locate(i-1);
if(front == -1 || elem[front].next == -1) return false;
int tmp = able;
able = elem[front].next;
elem[front].next = elem[able].next;
elem[able].next = tmp;
return true;
}
template <class T>
bool StaticList<T>::IsEmpty(){
return Length() == 0;
}1.2.3 块状链表(HBD)
实质:用链表来充当数组的索引
实现思路:每一个块是一个长度相同数组,之后用一个链表维护这些块。数组的长度为N,其中除了最后一个块以外,每个块中要求元素个数不少于N/2。
作用:
1. 取N = sqrt(n),使得查找的时间复杂度变为
2. 结合数组与链表的优点,在能够较快时间实现随机插入的同时保证了高速缓存的命中率且不用储存过多的指针
3. 可以结合lazy标记,实现局部元素的切割反转
具体实现(C++):略
1.2.4 大整数处理
1. 相加(C++)
vector<int> big_add(const vector<int>& a, const vector<int>& b){
int pos1 = a.size() - 1;
int pos2 = b.size() - 1;
vector<int> res;
int sum = 0; //表示每一位的和
int inc = 0; //表示进位
//竖式相加
while(pos1 > -1 || pos2 > -1 || inc != 0){
sum = inc;
if(pos1 > -1) sum += a[pos1--];
if(pos2 > -1) sum += b[pos2--];
inc = sum / 10;
sum = sum % 10;
res.push_back(sum);
}
//转向
int len = res.size();
for(int i = 0; i < len / 2; i++){
int tmp = res[i];
res[i] = res[len - 1 - i];
res[len - 1 - i] = tmp;
}
return res;
}2. 相乘(C++)
vector<int> big_mul(const vector<int>& a, const vector<int>& b){
int len1 = a.size();
int len2 = b.size();
vector<int> res;
//竖式相乘
for(int i = 0; i < len1; i++){
if(a[len1 - 1 - i] == 0) continue;
for(int j = 0; j < len2; j++){
if(b[len2 - 1 - j] == 0) continue;
while(res.size() <= i + j) res.push_back(0);
res[i + j] += a[len1 - 1 - i] * b[len2 - 1 - j];
}
};
//进位处理
for(int i = 0, inc = 0; i < res.size(); i++){
inc = res[i] / 10;
res[i] %= 10;
if(i == res.size() - 1 && inc > 0) res.push_back(inc);
else res[i+1] += inc;
}
//转向
int len = res.size();
for(int i = 0; i < len / 2; i++){
int tmp = res[i];
res[i] = res[len - 1 - i];
res[len - 1 - i] = tmp;
}
return res;
}1.3 拓展
1.3.1 矩阵压缩
思路:对于上三角、下三角、带状矩阵等,可先确定压缩后向量的索引k与原矩阵横纵坐标i, j的系数关系,再代入多个点求出还要加的常数
1.3.2 稀疏矩阵快速转置
稀疏矩阵存储:由于矩阵中只有少部分的元素不为0,故只用一3*n的矩阵(相当于压缩)分别纪录非0元素的行、列、值。一般先按行从小到大,再按列从小到大排序记录
稀疏矩阵转置:不是简单交换row与col即可,而要求转置后排序方式不变
具体实现(C++)(前缀和)
template <class T>
vector<vector<T> > transposition(const vector<vector<T> >& mat){
//前缀和,维护每列之前有多少元素
int len = mat.size();
vector<int> col_count(len + 1, 0);
//先计算每一列有多少个
for(int i = 0; i < len; i++){
col_count[mat[i][1] + 1]++;
}
//再做成前缀和形式
for(int i = 1; i < len; i++){
col_count[i] += col_count[i-1];
}
vector<vector<T> > res(len);
for(int i = 0; i < len; i++){
int index = col_count[mat[i][1]];
col_count[mat[i][1]]++;
res[index] = mat[i];
int tmp = res[index][0];
res[index][0] = res[index][1];
res[index][1] = tmp;
}
return res;
}时间复杂度: O(n)
第二章 栈与队列
2.1 栈与队列的定义与结构
2.1.1 栈的定义与结构
1. 定义:一种受限制的线性表,插入新元素或删除元素都只在栈的一端(也称为栈顶)进行,也就是满足先进后出的顺序(LIFO)
2. STL库中stack类的基本操作(C++)
stack<int> nums;
nums.empty(); //判断是否为空
nums.size(); //栈的元素个数
nums.push(1); //栈顶加入元素
//一下两者需要判断栈非空
nums.top(); //取栈顶元素的值(不弹出)
nums.pop(); //删除栈顶(不返回值)2.1.2 特殊栈及其变种
1. 链接栈(linked stack):即用链表结构实现栈操作
2. 双栈:分为栈顶相连与栈底相连。栈顶相连与两个独立的栈没有区别;但栈顶相连,相向存储可充分利用空间
3.n栈共用:即用静态链表的思想实现
2.1.3 队列的定义与结构
1. 定义:同样是一种受限制的线性表,只能在队列的两端插入或删除元素(一般队列只允许队首删除,队尾插入),满足先进先出(FIFO)
2. STL中基本操作(都在头文件<queue>中定义)
queue类(普通队列)(只能再队首删除、队尾加入)
queue<int> nums1;
nums1.empty(); //是否为空
nums1.size(); //元素个数
nums1.push(1); //队尾添加
//以下需要非空
nums1.front(); //取队首元素
nums1.back(); //取队尾元素
nums1.pop(); //删除队首元素deque类(双端队列)(队首队尾都可加入删除)
deque<int> nums2;
nums2.clear(); //清空
nums2.empty();
nums2.size();
//迭代器
nums2.begin();
nums2.end();
nums2.cbegin();
nums2.cend();
nums2.push_back(1); //队尾添加
nums2.push_front(2); //队首添加
//以下需要非空
nums2.at(0); //查找对应位置元素
nums2.pop_back(); //删除队尾
nums2.pop_front(); //删除队首 注:根据两端对插入和删除的限制不同,队列还有“超队列”、“超栈”等类型
2.2 栈与队列的应用
2.2.1 表达式求值(栈)
思路:双栈,一个维护操作数nums,另一个维护操作符ops。从表达式中得到操作数时,直接压入,得到操作符时,将其与ops栈顶的操作符做优先级比较,如果小于栈顶,则将栈顶的操作数弹出,结合两个操作数计算后,将这两个操作数弹出,填入计算结果。括号类似于优先级最高的操作符,但是前后要求匹配。最终得到的操作数栈中的唯一一个元素及计算结果。
问题:不适用于单操作数或者右结合的运算符
具体实现(C++)
//从字符串中提取出pos位开始的数字
//pos移到该数结束后第一个位置
int get_num(const string& s, int& pos){
int res;
while(isdigit(s[pos])){
res = res * 10 + s[pos] - '0';
pos++;
}
return res;
}
//比较运算符优先级,前比后高或等返回true
//a比b小,才要算,相等也不算
bool cmp(char a, char b){
if(b == '(') return false;
if((b == '*' || b == '/') && (a == '+' || a == '-')) return true;
return false;
}
void count(stack<int>& nums, char op){
int a = nums.top();
nums.pop();
int b = nums.top();
nums.pop();
int res;
if(op == '+') res = b + a;
else if(op == '-') res = b - a;
else if(op == '*') res = b * a;
else if(op == '/') res = b / a;
nums.push(res);
}
int expression_evaluation(const string& s){
stack<char> ops;
stack<int> nums;
int len = s.size();
for(int i = 0; i < len; i++){
if(s[i] == ' ') continue; //假定只有空格这一种“其他元素”
if(isdigit(s[i])){
nums.push(get_num(s, i));
i--; //回置一位
}else if(s[i] == '('){
ops.push(s[i]);
}else if(s[i] == ')'){
while(!ops.empty() && ops.top() != '('){
count(nums, ops.top());
ops.pop();
}
ops.pop();
}else{
//运算优先级必须单增
while(!ops.empty() && cmp(s[i], ops.top())){
count(nums, ops.top());
ops.pop();
}
ops.push(s[i]);
}
}
while(!ops.empty()){
count(nums, ops.top());
ops.pop();
}
return nums.top();
}2.2.2 递归改非递归(栈)
递归的缺点:有栈溢出的风险,管理堆栈有较大的时间与空间开销
递归改非递归的思路:
1. 仍用递归思路,只是自己调用栈来模拟系统运行(均适用)
e.g. 汉诺塔的搬运过程
递归版:借助递归树思考,即第一步从A柱将比当前少一个的盘子移到B柱,第二步将最大盘移到C柱,第三部将剩下的盘子也移到C柱。其中第一、三步进行递归,盘数比当前少一个,柱子交换顺序
//left表示from柱子上还剩下的盘数
void hanoi1(int left, char from, char to, char other){
if(left == 0) return;
hanoi1(left-1, from, other, to);
cout << "Move From " << from << " to " << to << endl;
hanoi1(left-1, other, to, from);
}非递归:
法一:根据递归树,以及原递归程序中出入栈顺序,用循环等价代替
struct node{
public:
node(char aa, char bb, char cc, int nn):a(aa), b(bb), c(cc), n(nn){}
char a, b, c;
int n;
};
void set_value(node& tmp, int n, char a, char b, char c){
tmp.a = a;
tmp.b = b;
tmp.c = c;
tmp.n = n;
}
void move_disc(char from, char to){
cout << "Move From " << from << " to " << to << endl;
}
void hanoi2(int plate_num){
stack<node> nodes;
node tmp('A', 'B', 'C', plate_num);
bool finish = false;
while(!finish){
while(tmp.n > 1){
nodes.push(tmp);
set_value(tmp, tmp.n - 1, tmp.a, tmp.c, tmp.b);
}
move_disc(tmp.a, tmp.c);
if(!nodes.empty()){
tmp = nodes.top();
nodes.pop();
move_disc(tmp.a, tmp.c);
set_value(tmp, tmp.n - 1, tmp.b, tmp.a, tmp.c);
}else finish = true;
}
}法二:每次取出一个,又推入三个,不等价代替,但思路简单
void hanoi3(int plate_num){
stack<node> nodes;
node tmp('A', 'B', 'C', plate_num), tmp1, tmp2, tmp3;
nodes.push(tmp);
bool finish = false;
while(!finish){
if(!nodes.empty()){
tmp1 = tmp2 = tmp3 = nodes.top();
nodes.pop();
if(tmp1.n == 1) move_disc(tmp1.a, tmp1.c);
else{
//避免修改覆盖,所以用tmp1, tmp2, tmp3
set_value(tmp1, tmp1.n - 1, tmp1.b, tmp1.a, tmp1.c);
nodes.push(tmp1);
set_value(tmp2, 1, tmp2.a, tmp2.b, tmp2.c); //中间根节点这部也必须推入,否则不能按顺序执行
nodes.push(tmp2);
set_value(tmp3, tmp3.n - 1, tmp3.a, tmp3.c, tmp3.b); //先执行的要放面上
nodes.push(tmp3);
}
}else finish = true;
}
}法三:人脑模拟电脑,不理解递归内涵,只是用循环复刻步骤(略)
2. 用循环代替递归结构(适用于尾递归、线性递归)
I. 尾递归(递归只在最后一行或返回值出现)
做一个大循环,每次循环末尾,改变操作值,在循环外另设res记录结果在循环过程中的“累积”,最后达到“奇点”条件即退出循环,返回结果
II. 线性递归
模板:
void proc(int n){
S1(n);
if(Eval(n)){
proc(n-1);
S2(n);
}else S3(n);
}分析出入栈顺序后,发现其实是不断执行S1并push,不满足条件时执行一次S3,然后又不断执行S2并pop,如图:
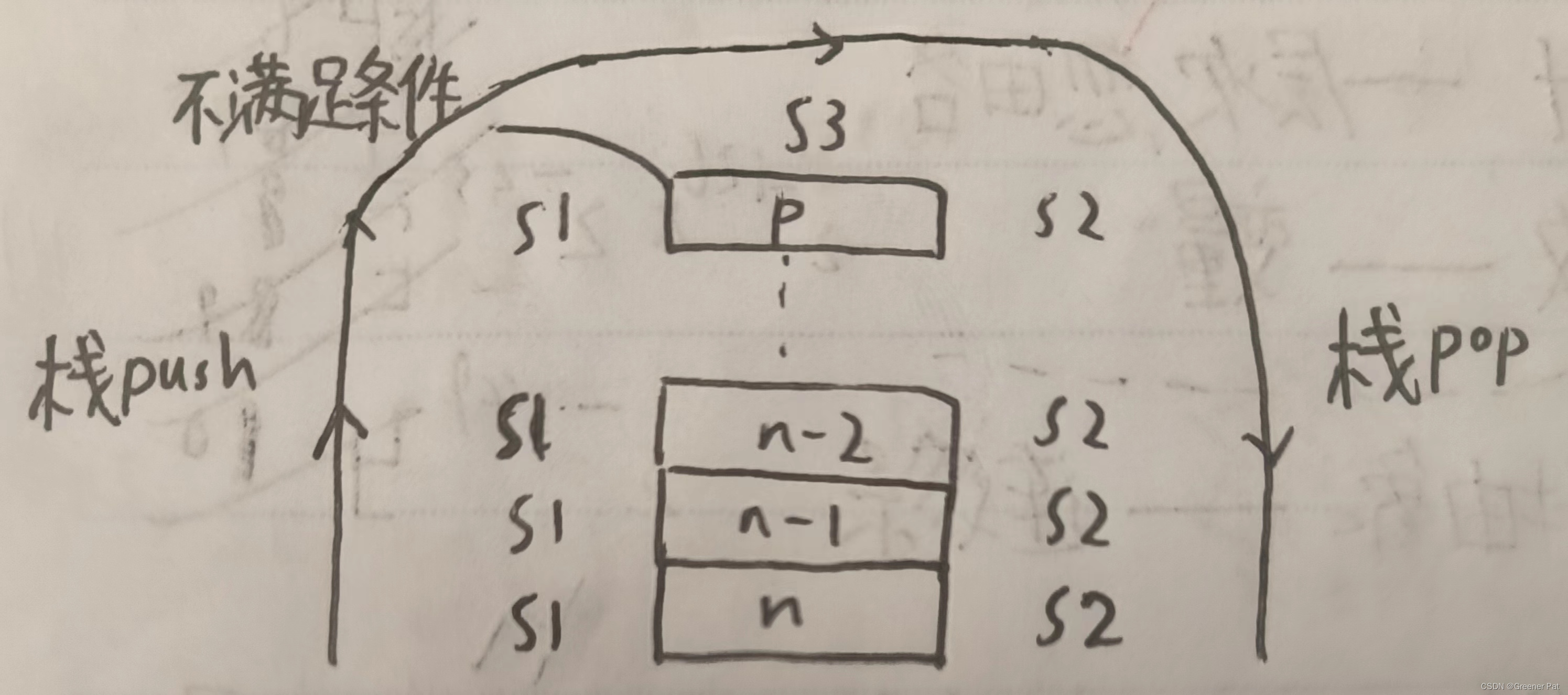
对应非递归程序模板:
void proc(int n){
int k = n;
while(Eval(k)){
S1(k);
k--;
}
S3(k);
while(k <= n){
S2(k);
k++;
}
}3. 换一种思路(没有普适性)(略)
2.2.3. 深度优先(栈)(HBD)
2.2.4 广度优先(队列)(HBD)
2.2.5 单调栈与单调队列
单调栈:以单增栈为例,每到一个新元素便检验,如果栈为空,则直接放入,否则将栈顶比它大的元素逐个删除后将其放入。
单调队列:一般用双端队列实现,队尾操作与栈相似,队首的pop则另由具体场景条件控制
适用场景:
1. 当问题中有两种优先级,如远近、大小等时
2. 一般对象是向量等一维数据,也包括可以分别按行列降维处理的矩阵等,同时也决定时间复杂度为O(n),具体每一步复杂度一般是O(1)
使用注意:
1. 其中元素数值、意义(前后表示原向量中的先后顺序)都要有单调性
2. 一般存储的是元素索引,而非具体值
Tip:
1. 求最近元素时,无论如何单调,元素大小关系如何,每一个元素都至少被push进栈/队列一次;
求最远元素,则满足单调才入栈,否则不入栈(单调栈变种)
2. 判断单增单减时,可用极限情况考虑,即出现最值时,原来元素还有没有用,没有就应该利用单调性将其全部删除
应用:
1. 给定一个序列,找每一个元素左边第一个更大的元素,如果没有则返回0:
思路:没有有另外限制一端入,另一端出,故考虑栈。而当当前元素最大时,后面元素的左边最大只可能是它,所以当时要把栈中原来元素全部删除,故考虑单减栈。经检验成立。
实现:每队一个元素,如果栈为空,则返回0;反之,则逐个比较其与栈顶元素大小,将比其小的元素全部删除后,若栈为空则返回0,非空便返回对应元素。无论如何,最后将该元素索引入栈。
2. 有一个n个元素的数组,对于每个长度为k的子串,求其中元素最大值(滑动窗口最大值问题)
思路:不仅有元素大小的比较,还有元素位置的影响,故考虑用队列。当新出现最大元素时,之前的都不再有作用了,故考虑单减队列。经检验成立。
实现:类似单减栈,只是每轮要看队首元素是否已在窗口外,如是则要将其删除
第三章 字符串
3.1 模式匹配算法
要求:在字符串s中找出与字符串t相等的子串,其中s称为主串/目标串,t称为模式串
3.1.1 BF 算法
BF(Brute Force)算法思路:暴力遍历,先将目标串与串模式串首位对齐,之后对每一位进行比较,若不匹配,则将模式串首位与目标串下一位对齐,再进行上述过程;反之,如匹配则返回模式串首位对齐的位置。如果没有可匹配的,则返回-1
int pattern_match_bf(const string& s, const string& t){
int len1 = s.size(), len2 = t.size(), res = -1;
for(int i = 0; i <= len1 - len2; i++){
bool pass = true;
for(int j = 0; j < len2; j++){
if(s[i+j] != t[j]){
pass = false;
break;
}
}
if(pass){
res = i;
break;
}
}
return res;
}问题:BF的问题在于,每一次只将模式串后移一位,而浪费了本来已经比较过的许多位。而事实上,之后的算法,都是基于这一点的优化
3.1.2 KMP 算法
KMP(Knuth-Morris-Pratt)算法思路:通过对模式串的考察,得到一定规律,使得每一次匹配失效时都能迅速跳转过不可能成功匹配的区间。e.g.

即在最后一个字符b失配时,从之前四个字符匹配成功可得目标串对应位置信息,从而知道上一位是a,下一个可能匹配的位置即是将模式串首移到失配出的上一位,之后再从目标串的原始配位继续比较
具体实现:
思路:
1. 预处理:记录模式串从首位开始,任意位结束的子串的最长公共前后缀长度
前缀即是从0位开始,第i 位( 0 <= i < n - 1)结束的子串;
后缀则是从 j 位(0 < j <= n - 1)开始,第n - 1位结束的字串;
注:
I. 公共前后缀中不包含该字符串本身
II. 用next[i]表示 0 ~ i - 1位的最长公共前后缀的长度,其中特殊标记next[0] = -1
子问题:求最长公共前后缀长度
递归思想:求next[i]时,先从next[i-1]中得到ab == cd,之后比较t[next[i-1]]和t[i-1],如果匹配,则next[i] = next[i-1] + 1;反之,那就再找0~i-1中第二长的公共前后缀,即找a'b == c'd',又因为ab == ac,所以相当于找a'b' == c''d'',这就又可以从next[j] (j = next[i-1] - 1中直接得到),之后再比较t[next[j]] 与 t[i-1] 一直重复这个过程,直到终于有t[next[k]] == t[i-1],或者找不到能与t[i]匹配的t[next[k]]结束
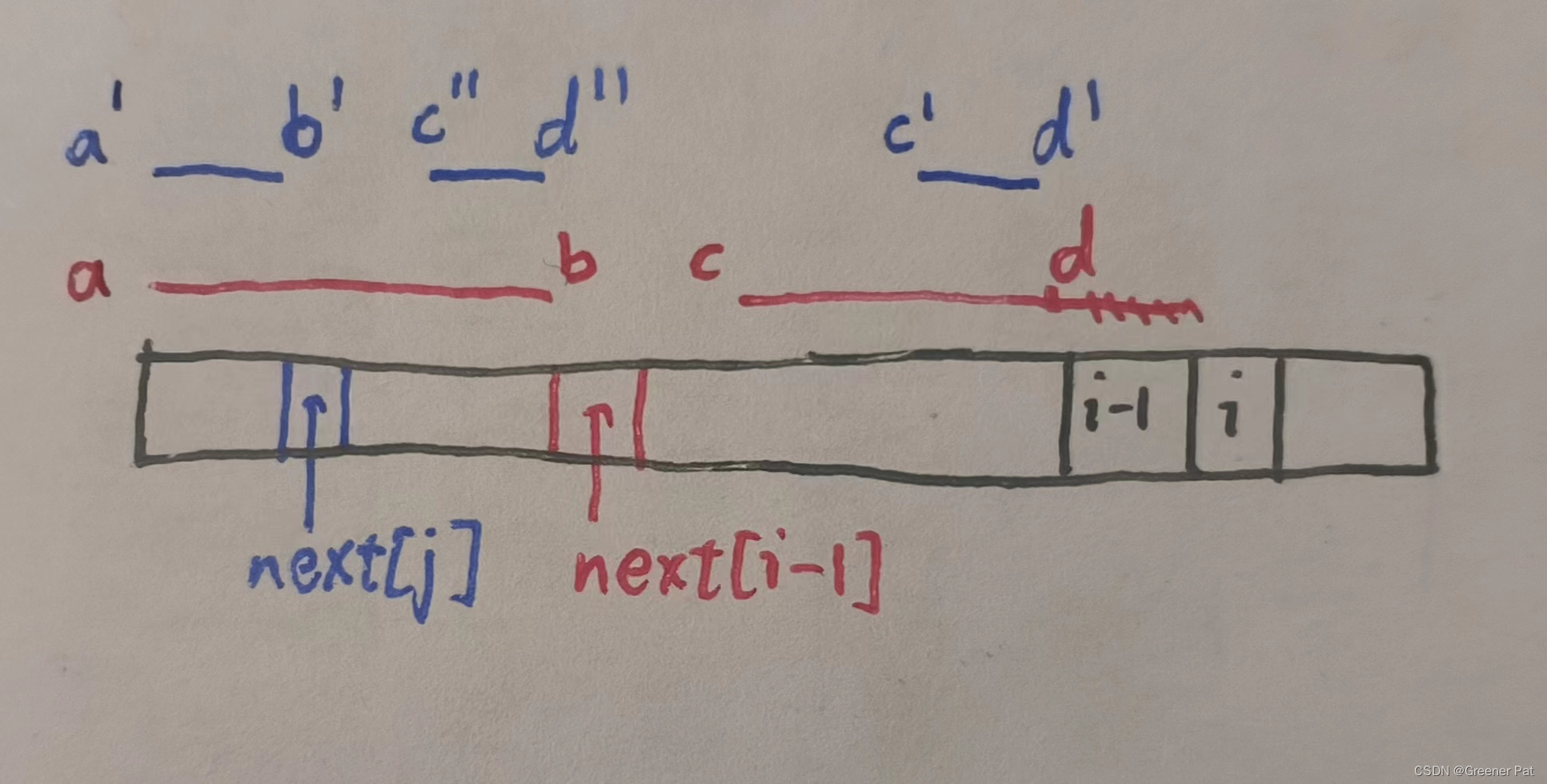
2. 模式匹配:每一次失配时,若此时是s的第i位,t的第j位,则令 j = next[j],因为ab == a'b',可以确保之前段是匹配的。若是段首失配,则特殊判断,将i++即可
代码:
//预处理
vector<int> make_next(const string& t){
int len = t.size();
vector<int> next(len);
next[0] = -1;
int k = next[0], i = 1;
while(i < len){
if(k == -1 || t[i-1] == t[k]){
next[i] = k + 1;
k = next[i];
i++;
}else k = next[k];
}
return next;
}
//模式匹配
int pattern_match_kmp(const string& s, const string& t){
vector<int> next = make_next(t);
int len1 = s.size(), len2 = t.size();
for(int i = 0; i <= len1 - len2; i++){
for(int j = 0; i < len1 && j < len2; i++, j++){
if(s[i] != t[j]){
if(j == 0) break;
else j = next[j] - 1;
}
if(j == len2 - 1) return i - len2 + 1;
}
}
return -1;
}3. 优化:可以在模式串最后添上‘\0’,而在匹配完前面所有的字符后即记录对应目标串位置,这样直到目标串结尾永远不会完成匹配,从而可以搜索出所有满足的字符串位置
//KMP多个匹配
vector<int> multi_kmp(string& s, const string& t){
s.push_back('\0'); //小小改动
vector<int> next = make_next(t);
vector<int> res;
int len1 = s.size(), len2 = t.size();
for(int i = 0; i <= len1 - len2; i++){
for(int j = 0; i < len1 && j < len2; i++, j++){
if(s[i] != t[j]){
if(j == 0) break;
else j = next[j] - 1;
}
if(j == len2 - 1){
res.push_back(i - len2 + 1);
}
}
}
return res;
}
3.1.3 BM算法(HBD)
是当前的标准库算法,也是效果最好的之一
3.1.4 KR算法(HBD)
第四章 树与二叉树
4.1 基本概念与性质
1. 树:树是由节点组成的有限集合,两点之间的连接有向,从父节点指向子节点,一般有一个根节点,且树中一定不成环
2. 度:结点的度:其子节点或非空子树的个数
树的度:树中所有节点的最大度数
3. 结点:叶子节点、中间节点(略)
兄弟结点:父节点相同的结点
4. 层次与高度(相反): 结点的层次:从根节点向下递增
结点的高度:从叶子节点向上递增
树的高度:根节点的高度
5. 有序树与无序树:区分标准即节点,子树能不能交换顺序,或者说交换顺序后是否认为树改变,一般涉及的都是有序树
6. 无根树:没有根节点,也没有父节点与子节点的关系,但有叶子节点(可用无环的图来理解,其实树本身就是一种特殊的图)
4.2 二叉树
概念:每个结点最多只有两个子节点子树的树,且左右不能交换顺序(即有序树)
4.2.1 特殊的二叉树
1. 满二叉树:只有度为0的叶子结点和度为2的中间节点构成,主要用在霍夫曼树、表达式树等
2. 完全二叉树:从上到下,从左到右依次填充的二叉树,即除了最后一层以外上面全满,而最后一层也是从左到右填充。在堆里有应用。
3. 完美二叉树:每一层都填满的二叉树,但由于这样限制死了节点数,所以这种结构并不常用(完美二叉树停止了思考……)
4. 扩充二叉树:在二叉树节点的空子树处全填上空树叶所构成的二叉树
4.2.2 二叉树的性质
1. 度为0的节点个数 = 度为2的节点个数 + 1(用不同的方式计算出节点总数再取等即可)
2. 有n个节点的完全二叉树的深度是upper(log(n+1))
4.3 树的遍历
即访问树的所有节点且每个节点只访问一次
4.3.1 深度优先遍历
1. 先序遍历(先根遍历):根结点 - 按序遍历子树
后序遍历(后根遍历):按序遍历子树 - 根结点
//所有有根树共有
struct Treenode{
int val; //每个节点储存的元素,也可以是别的
vector<Treenode*> sons;
};
//先序遍历
void preorder_dfs(Treenode* root){
if(root== NULL) return; //要先判断根结点的有效性
//operate with root->val
int len = root->sons.size();
for(int i = 0; i < len; i++){
preorder_dfs(root->sons[i]);
}
}
//后序遍历
void postorder(Treenode* root){
if(root== NULL) return;
//其实只是交换了一下遍历子节点和对当前节点做处理的顺序
int len = root->sons.size();
for(int i = 0; i < len; i++){
preorder_dfs(root->sons[i]);
}
//operate with root->val
}2. 中序遍历(二叉树特有):左子树 - 根节点 - 右子树
struct BTreenode{
int val;
BTreenode *left, *right;
};
void inorder_dfs(BTreenode* root){
if(root == NULL) return;
inorder_dfs(root->left);
//operate with root->val
inorder_dfs(root->right);
}注:无根树遍历时,可从递归函数传入父节点,避免反向走!
3. 二叉树的镜像遍历
先序:根 - 左 - 右 镜像 右 - 左 - 根
后序:左 - 右 - 根 镜像 根 - 右 - 左
中序:左 - 根 - 右 镜像 右 - 根 - 左
由递归的思想可以发现,镜像之后遍历节点的顺序恰好相当于原来对应的反过来
还可以借助投影图理解:
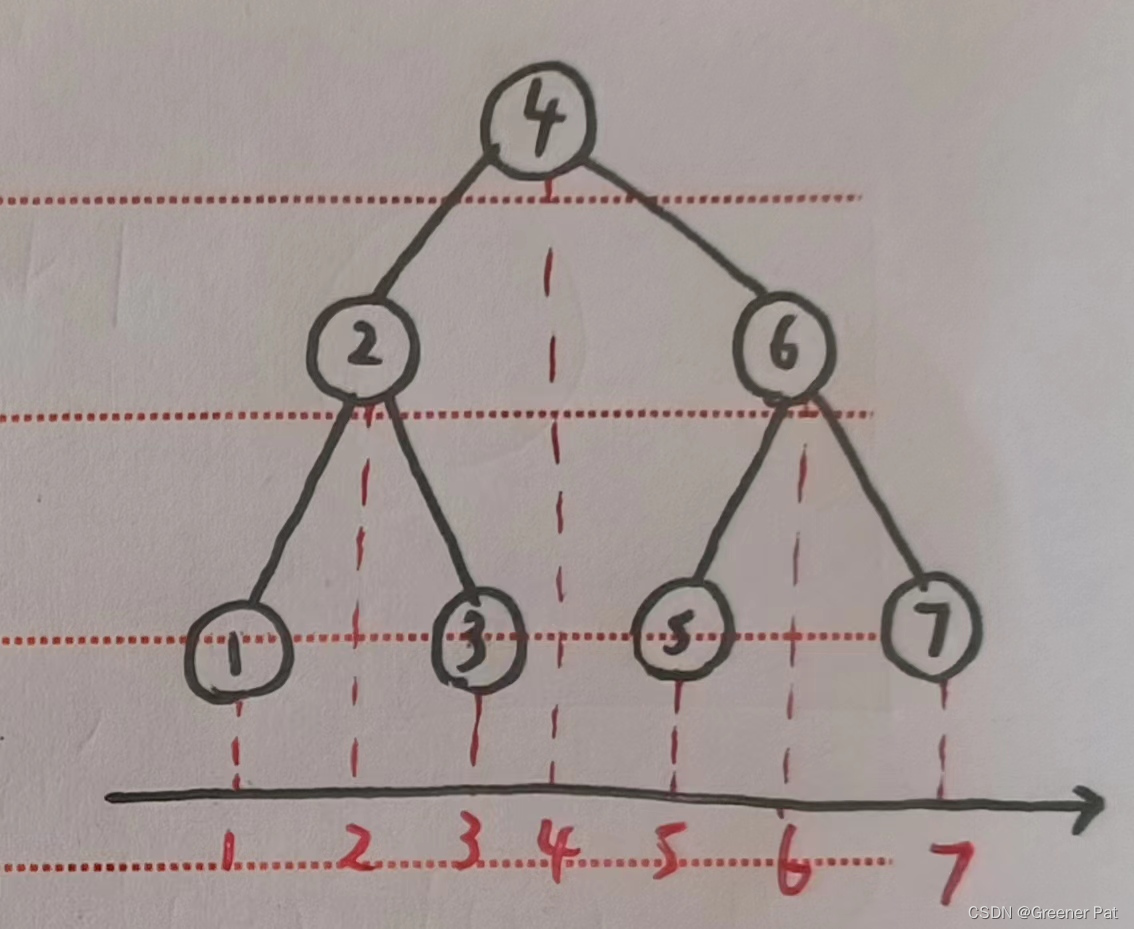
做镜像即在对应的投影轴上反过来走,所以镜像前后遍历顺序恰好相反
4.3.2 广度优先遍历
即层序遍历——一层一层从左到右遍历,不需要递归!
struct Treenode{
int val; //每个节点储存的元素,也可以是别的
vector<Treenode*> sons;
};
void bfs(Treenode* root){
if(root == NULL) return;
queue<Treenode*> nodes;
nodes.push(root);
while(!nodes.size()){
//先取出队首节点,其一定是层次遍历中最高的
Treenode* top = nodes.front();
nodes.pop();
//operate with the top->val
//然后将其子结点依次放入队列
int len = top->sons.size();
for(int i = 0; i < len; i++){
nodes.push(top->sons[i]);
}
}
}4.4 树的储存
注:这里的树即是指的一般的多叉树,甚至也可以是无根树(随便取一个节点作根即可)
4.4.1 等长与变长链表表示法
即每个节点都有一个/一些节点关键数据和一组指向子节点的指针构成,等长与变长的区别在于节点中为指向子结点的指针分配的空间是不是固定的。
| 等长 | 变长 | |
| 优点 | 方便维护,而且在特殊情况下(如字符种类受限的字典树中可以直接用索引储存节点信息,而且方便查找不用遍历子节点) | 避免了等长的空间浪费 |
| 缺点 | 会浪费较多的空间,且浪费空间与树的结构无关(有n个结点的k叉树一定会浪费n * (k -1) + 1个指针位置——由此还可看出,二叉树是这种情况下浪费最小的结构) | 需要用额外的手段管理子女链表(但在使用vector其实较为方便) |
4.4.2 左儿子右兄弟表示法
由二叉树较好的空间利用性出发,考虑将多叉树转化成二叉树
思路:即将每个节点的第一个子节点作为左子节点,然后从左到右依次连接,下一个为上一个的右子树
图示: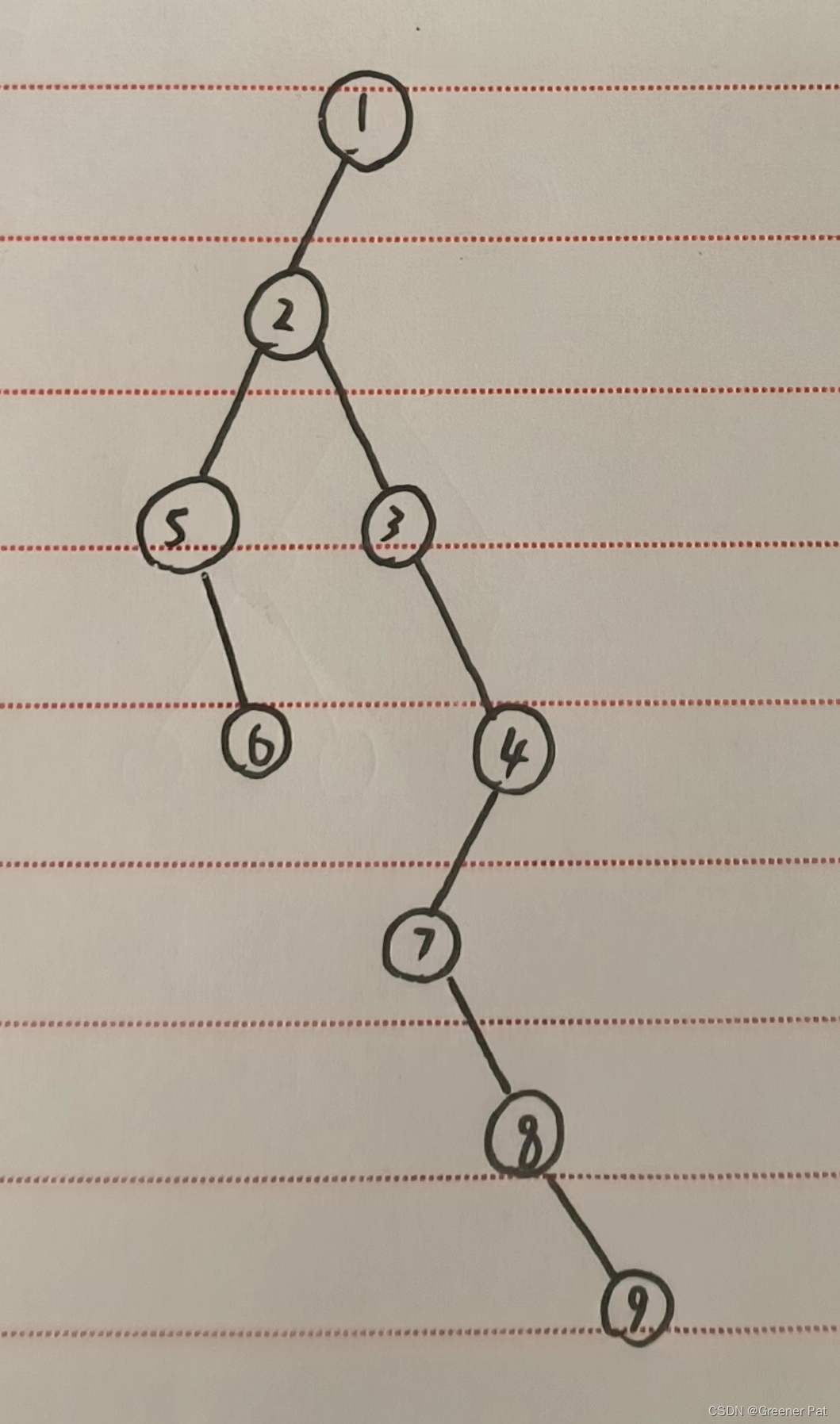
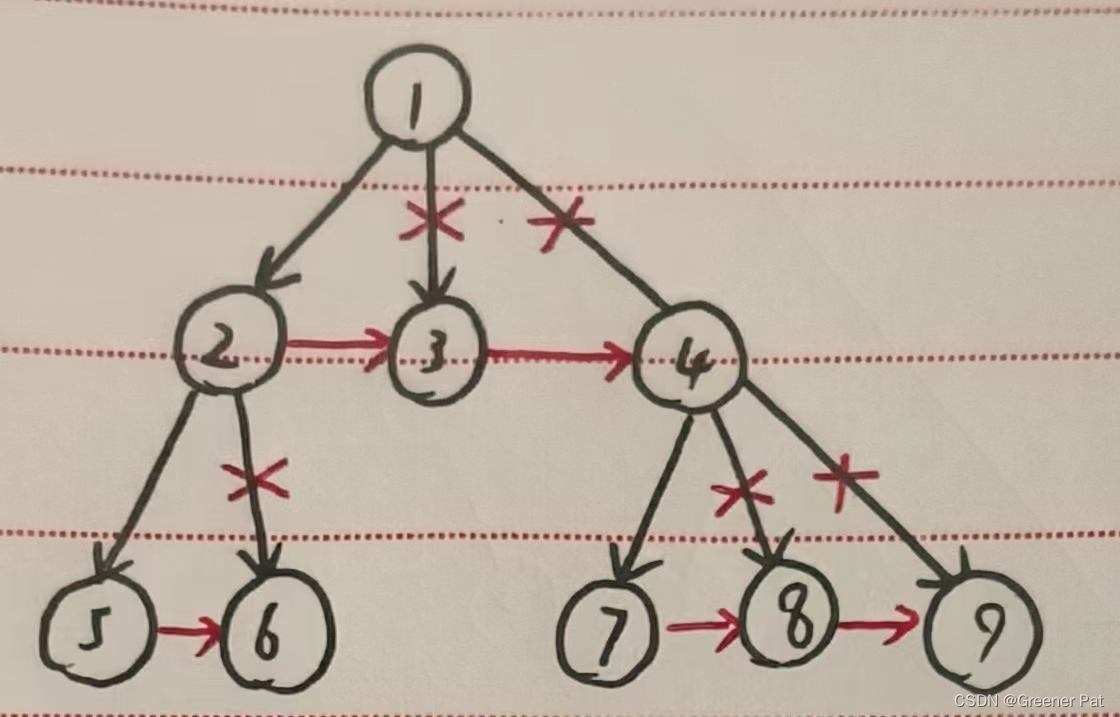
具体实现:
struct TreeNode{
TreeNode(int x): val(x){}
int val;
vector<TreeNode*> sons;
};
struct BTreeNode{
BTreeNode(int x): val(x), left(NULL), right(NULL){}
int val;
BTreeNode *left, *right;
};
//根据原来的多叉树构建二叉树,并返回根节点
BTreeNode* convert(TreeNode* root){
if(root == NULL) return NULL;
BTreeNode* broot = new BTreeNode(root->val);
int len = root->sons.size();
if(len == 0) return broot;
broot->left = convert(root->sons[0]);
BTreeNode* fa = broot->left;
for(int i = 1; i < len; i++){
BTreeNode* sibling = convert(root->sons[i]);
fa->right = sibling;
fa = sibling;
}
return broot;
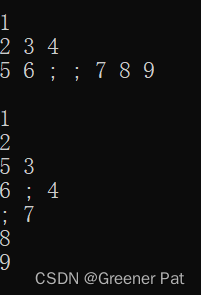
}效果:
4.4.3 接邻矩阵与接邻表
接邻矩阵即是创建一个n * n 的矩阵,若节点j是节点i的子节点,则接邻矩阵的元素(i, j)为1。其好处在于可以方便地表示无根树与加权树,但缺点是占用空间多
| 编号 | 1 | 2 | 3 | 4 | 5 |
| 1 | 0 | 1 | 1 | 1 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 |
接邻表则是针对接邻矩阵占用空间多这一点进行优化,接邻表采用二维数组或vector,但每一行仅保存其子节点的编号,从而压缩了空间
| 编号/索引 | 子结点1 | 子节点 | 子结点3 |
| 1 | 2 | 3 | 4 |
| 2 | 5 | - | - |
| 3 | - | - | - |
| 4 | - | - | - |
| 5 | - | - | - |
4.4.4 父节点、广义表与欧拉序列
1. 父节点表示法
即将每个结点的值存在一个线性表里(可以根据先序遍历等得到其顺序),而在另一个线性表(或者直接储存在二维数组/链表中)对应位置储存其父节点所在的位置(类似于静态链表)
常用于内存等结构,优点是极大的压缩了存储树的空间且没有损失信息,但缺点在于难以实现遍历等操作(常需要将其转换成其他储存形式才能遍历)
2. 广义表表示法
广义表基表的元素还可以是表
e.g. A( B(E, F), C, D(G) ) //注:二叉树中如果左子树为空要表示成 A( , B)避免左右子树混淆
3. 欧拉序列
同样按深度优先的思路递归遍历每一个节点,但每次返回时再记录一次该点,从而构成一个序列,这个序列即可完整地保留树的全部信息
4.4.5 二叉树的储存
1. 线性表储存
对于完全二叉树,由于中间节点填满,所以可将将根与左右子节点的关系设为 i 与2 * i、2 * i + 1,从而直接保存在线性表的对应位置
对于非完全二叉树,可以在缺少子节点的地方用特殊记号标记为空,然后同样利用索引关系进行保存。但这对于比较满的二叉树更有效,对像只有一个单支的二叉树来说会浪费极多的空间
2. 静态链表保存
做一个n * 3的数组,第一个保存节点值,另两个记录左子节点和右子结点的索引,甚至也可用n * 4把父节点索引也保存了
4.4.6 二叉树的反序列化
即在二叉树的四种遍历方法中选出两种得到的序列,反过来可以复原出原来的二叉树,6种组合中,只有含中序遍历的三种可以!
注:例子中的程序都默认节点值为1-n,如果是随机的,则可用在每个节点中用1-n标识(略复杂)
1. 前序 + 中序
思路:有前序遍历的性质,将遍历得到的个节点放在数组中,以root开头,其左子树在紧跟的前一段,右子树在后一段。而中序遍历得到的mid(这里其实是各结点的索引值)则用来确定左右子树在数组中对应的长度。递归进入左右子树,将左右子树的根节点设为root的子结点并重复上述过程,若某次调用”树长“为0(用begin, end标识中序遍历索引的收尾),则直接返回。
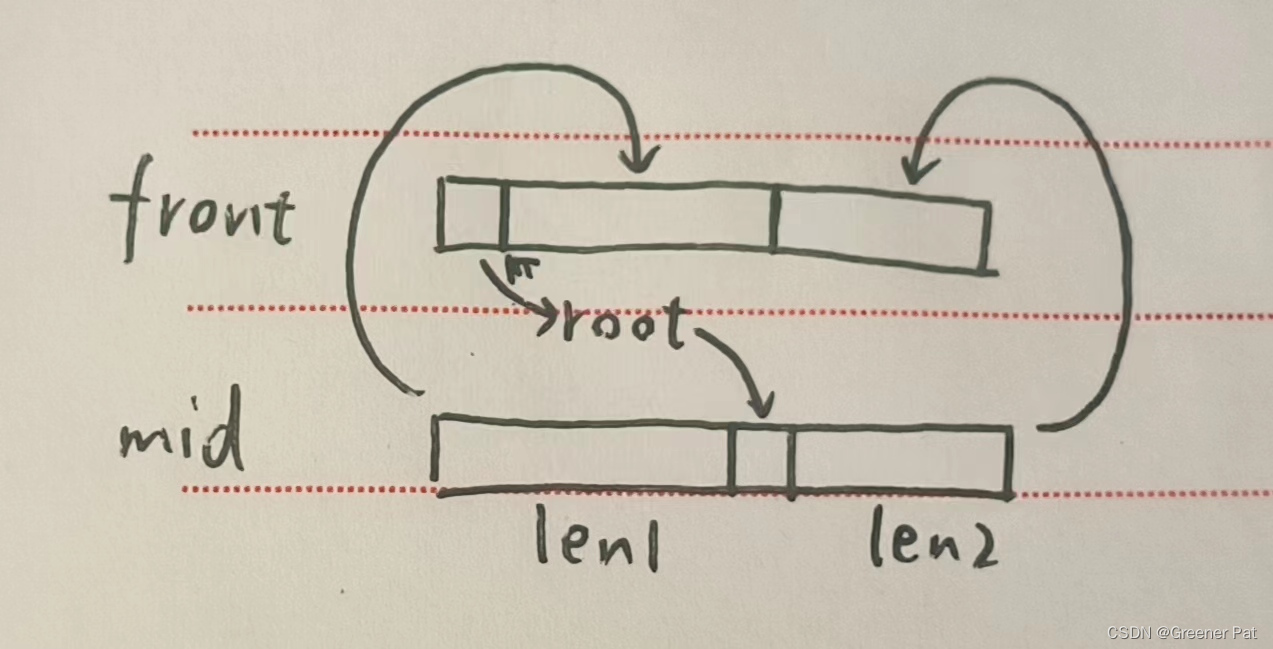
代码实现:
//返回以front[pos]为根的子树的根节点
//pos为front中根节点的位置
//begin, end是mid_search中该子树对应的起止点(闭区间)
BTreeNode* deserialize_pre_mid(const vector<int>& front, const vector<int>& mid_search, int pos, int begin, int end){
if(begin > end) return NULL;
BTreeNode* root = new BTreeNode(front[pos] + 1);
int root_pos = mid_search[front[pos]];
int left_len = root_pos - begin; //计算左子树长度
root->left = deserialize_pre_mid(front, mid_search, pos + 1, begin, root_pos - 1);
root->right = deserialize_pre_mid(front, mid_search, pos + left_len + 1, root_pos + 1, end);
return root;
}测试结果:

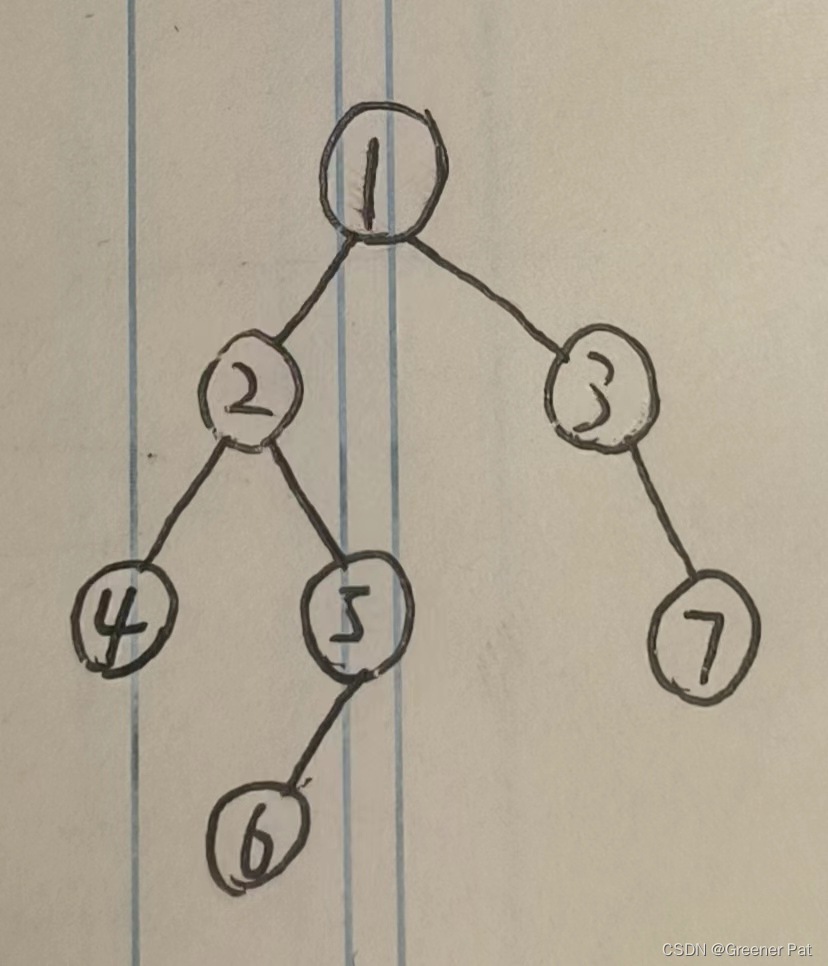
2. 后序 + 中序
思路:与 ”前序+中序“ 接近,只是有些部分要颠倒一下
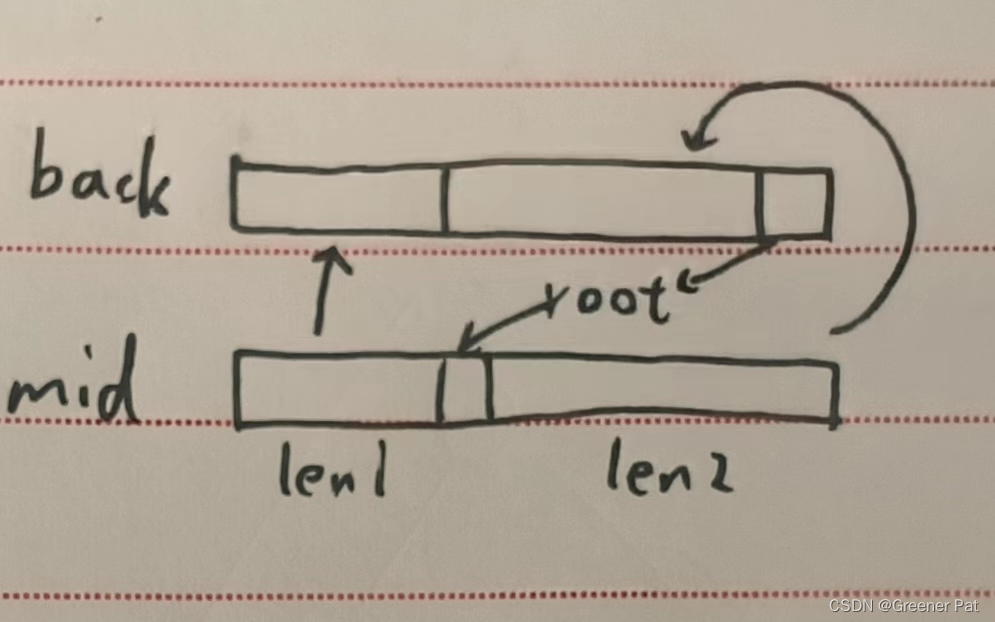
代码实现:
BTreeNode* deserialize_post_mid(const vector<int>& post, const vector<int>& mid_search, int pos, int begin, int end){
if(begin > end) return NULL;
BTreeNode* root = new BTreeNode(post[pos] + 1);
int root_pos = mid_search[post[pos]];
int right_len = end - root_pos;
root->left = deserialize_post_mid(post, mid_search, pos - right_len - 1, begin, root_pos - 1);
root->right = deserialize_post_mid(post, mid_search, pos - 1, root_pos + 1, end);
return root;
}测试结果:

3. 层次 + 中序
思路:仍采用队列来实现(广度优先一般考虑队列而非递归/栈),队列里每一个单元储存一个结点的一系列信息,包括:节点值(val),父节点指针(father),其是左/右子结点(side),其对应的中序索引范围 [begin, end] 。初始时将根节点及相关信息压入队列,之后执行以下过程
I. 取出队首元素并从队列中删除,为其分配空间
II. 考察其父节点,如果不为空,则按照记录将其连接到左/右子节点的位置;反之,及说明是根节点,将其保存为root
III. 于中序索引中找到其在[begin, end]中的位置sub_root_pos,并将其与begin, end进行比较,如不相等则说明其左/右子节点存在,再将其子节点压入队列(节点值由输入的层次遍历及其逐1增长的索引pos决定)
IV. 如果队列不为空,则回到步骤I
具体实现:
struct node{
node(int x, int b, int e, bool s, BTreeNode* fa = NULL):val(x), begin(b), end(e), side(s), father(fa){}
int val;
bool side; //true表示左子树,false表示右子树
int begin, end;
BTreeNode* father;
};
BTreeNode* deserialize_level_mid(const vector<int>& traverse, const vector<int>& mid_search){
queue<node> level;
int pos = 0;
int len = traverse.size();
node root_node(traverse[pos++], 0, len - 1, 0);
level.push(root_node);
BTreeNode *sub_root, *root;
while(!level.empty()){
node tmp = level.front();
level.pop();
sub_root = new BTreeNode(tmp.val + 1);
if(tmp.father){
if(tmp.side) tmp.father->left = sub_root;
else tmp.father->right = sub_root;
}else root = sub_root;
int sub_root_pos = mid_search[tmp.val];
if(tmp.begin != sub_root_pos && pos < len){
level.push(node(traverse[pos++], tmp.begin, sub_root_pos - 1, true, sub_root));
}
if(tmp.end != sub_root_pos && pos < len){
level.push(node(traverse[pos++], sub_root_pos + 1, tmp.end, false, sub_root));
}
}
return root;
}测试结果:

4. 其余几种不行的原因
一个原因是,当某个节点只有一个子节点时,无论”前序+层次“,”后序+层次“,还是”前序+后序“都无法区分这个子结点是左子节点还是右子节点的区别
4.5 最近公共祖先(LCA)
最近公共祖先(LCA, lowest common ancestor)算法即是要找出有根树中任意两个节点的最近公共祖先节点
注:程序均默认树中节点值为1-n
4.5.1 朴素算法
思路:先通过一次深度优先预处理出每个节点的父节点及其深度,之后比较两个节点深度,如果不同则将深度大者向上移,直到两者深度相同;反之深度相同则比较两者节点是否相同,如果不想同在随机将一个上移,之后重复上述过程之到达到最近公共祖先
具体实现:
struct TreeNode{
TreeNode(int x): val(x){}
int val;
vector<TreeNode*> sons;
};
void dfs(TreeNode* root, vector<int>& depth, vector<int>& father, int deep, int fa){
if(root == NULL) return;
depth[root->val] = deep;
father[root->val] = fa;
int len = root->sons.size();
for(int i = 0; i < len; i++){
dfs(root->sons[i], depth, father, deep+1, root->val);
}
}
void naive(TreeNode* root, int n){
int t;
cin >> t;
vector<int> depth(n), father(n);
vector<int> res(t);
dfs(root, depth, father, 0, -1);
for(int i = 0, x, y; i < t; i++){
cout << "nodes: ";
cin >> x >> y;
x--;
y--;
while(x != y){
if(depth[x] < depth[y]) y = father[y];
else x = father[x];
}
res[i] = x;
}
for(int i = 0; i < t; i++){
cout << res[i] + 1 << endl;
}
}时间复杂度(单次查询) 预处理:O(n);求LCA:O(logn) //平均树高O(logn)
4.5.2 倍增算法
思路:现根据树的最大深度预处理得到每个节点上方2^0,2^1,2^2,……2^LogN处的节点及每个结点的深度。之后每次查询,先通过跳跃(根据两者深度差的二进制表示)先将两者拉到同一高度,之后若两者已相同,则得到LCA;反之,则you jump, I jump一起向上跳,如果跳到相同则不改变原值(跳跃失败,因为无法确定是否已经超出),不同则更改两者值,最终两者恰好父节点相同时记录其父节点作为LCA //上述分类可做简化
具体实现:
#define Log 4 //默认树深不超过8
void dfs(TreeNode* root, vector<int>& depth, vector<int>& father, int deep, int fa){
if(root == NULL) return;
depth[root->val] = deep;
father[root->val] = fa;
int len = root->sons.size();
for(int i = 0; i < len; i++){
dfs(root->sons[i], depth, father, deep+1, root->val);
}
}
template <class T>
void swap(T* a, T* b){
T tmp = *a;
*a = *b;
*b = tmp;
}
void doubling(TreeNode* root, int n){
int t;
cin >> t;
vector<int> depth(n), fa(n);
dfs(root, depth, fa, 0, -1);
//预处理得到跳转表
vector<int> vec_tmp(Log);
vector<vector<int> > fathers(n, vec_tmp);
for(int j = 0; j < Log; j++){
for(int i = 0; i < n; i++){
if(j == 0) fathers[i][j] = fa[i];
else if(fathers[i][j-1] == -1) fathers[i][j] = -1;
else fathers[i][j] = fathers[fathers[i][j-1]][j-1];
}
}
vector<int> res(t);
for(int i = 0, x, y; i < t; i++){
cout << "node: ";
cin >> x >> y;
x--;
y--;
if(depth[x] < depth[y]) swap(&x, &y);
int gap = depth[x] - depth[y];
//拉平
int pow = 0;
while(gap > 0){
if(gap & 1) x = fathers[x][pow];
gap >>= 1;
pow++;
}
//一起向上跳
if(x == y){
res[i] = x + 1;
continue;
}
while(fathers[x][0] != fathers[y][0]){
for(int j = Log - 1; j > -1; j--){
if(fathers[x][j] != fathers[y][j]){
x = fathers[x][j];
y = fathers[y][j];
break;
}
}
}
res[i] = fathers[x][0] + 1;
}
for(int i = 0 ; i < t; i++){
cout << "LCA: " << res[i] << endl;
}
}时间复杂度 预处理:O(NlogN);查询:O(logN) //适用于需要查询多次时
测试结果:
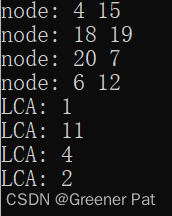
4.5.3 欧拉序列(HBD)
定义见4.4.4,由欧拉序列的性质可知,两节点a, b(不妨深度优先遍历a在前)的LCA即是以a为起点,b为终点(第一次达到即可)的欧拉子序列中深度最小的节点
4.5.4 稀疏表
即结合了倍增算法和欧拉序列的一种结构,每个元素储存欧拉序列从这一点开始,长2^0,2^1,2^2 ……的段中深度最小的节点,由此可实现预处理时间O(NlogN),空间O(nlogN),每次查询O(1)的时间复杂度!
4.5.6 离线查找(Tarjan算法)(HBD)
4.6 无根树
注:程序均默认树中节点值为1-n,并保存在邻接表中
4.6.1 直径
1. 定义:即无根树中最长的一条路
2. 性质:所有直径的中点一定重合于一个点,且不会同时存在两条偶数长的直径
3. 算法求解:任选一个节点出发,找到离其最远的点,记为A(可以其为根节点,深度优先得到深度最大的点)。之后在以这个点出发,找到离其最远的点,记为B。则A-B构成该树的一条直径。
合理性证明:从直径的一个端点出发,找到的最远点一定是该直径的另一端点,故只需要说明从任意一点出发找到的最远点可做直径的端点。
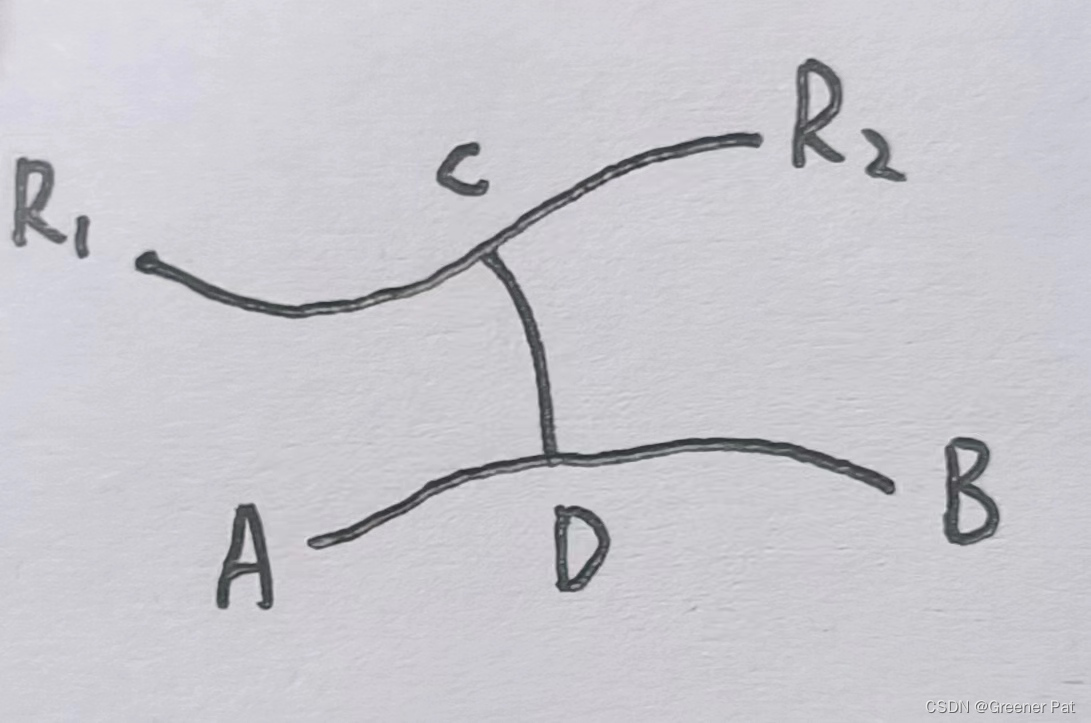
反证法:假设从任取的一点A出发,最远到达B,但B不能做直径端点。设该树的一条直径为R1-R2,树结构保证了A-B和R1-R2之间一定有且只有一条路相连。设|DB| = s1, |CD| = s2, |CR2| = s3,因为A最远到B,所以s1 >= s2 + s3;由直径性质易得s3 >= s1 + s2,又因为s2 >= 0。所以,若s2 = 0, s1 = s3则BR1也是一条直径;反之s1 > s3 且 s3 > s1,所以产生矛盾,故B可以作为直径端点
具体实现:
void dfs(const vector<vector<int> >& tree, vector<int>& depth, int num, int fa, int deep, int& max_depth, int& endian){
depth[num] = deep;
if(deep > max_depth){
max_depth = deep;
endian = num;
}
int len = tree[num].size();
for(int i = 0; i < len; i++){
if(tree[num][i] == fa) continue;
dfs(tree, depth, tree[num][i], num, deep+1, max_depth, endian);
}
}
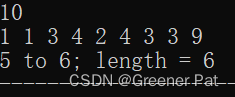
void diameter(const vector<vector<int> >& tree){
vector<int> depth(tree.size());
//第一次不妨以0做根节点
int dia_len = 0, endian1 = 0, endian2;
dfs(tree, depth, 0, -1, 1, dia_len, endian1);
dia_len = 0;
dfs(tree, depth, endian1, -1, 1, dia_len, endian2);
cout << endian1 + 1 << " to " << endian2 + 1 << "; length = " << dia_len;
}测试结果:
4.6.2 重心
1. 概念:一颗无根树上,若能取一个节点R,使得以这个节点为根的节点最多的子树节点最少,则R是这颗树的重心g
2. 性质:
I. 一个节点是树的重心当且仅当它的所有子树节点树都不超过所有节点的1/2
必要性:(反证法)选取某一重心R,其有一子树节点数为a > n/2。则选取该子树的根节点A,此时以R为根的子树节点个数最多是n/2,而他的其他子树节点数一定小于a,这样他的最大子树的节点数相比选取R做根节点时减少了,说明R不是重心,产生矛盾。
充分性:(反证法)选取某一结点R,其所有子树节点数均不大于n/2,但R不是重心。任取一个其他节点A,A一定在R的某一子树上。除该子树外,自他子树节点和加一(R自身)一定有大于等于n/2个节点,即若选A作根节点,其最大子树的节点数不会更少,与节点R不是重心矛盾。
II. 一棵树的两个重心一定相邻
如果不相邻的话,经分析得总结点数 > (因为两重心之间存在节点) n/2(两重心”一侧“的最小节点数) + n/2 = n,不成立
III. 一棵树最多有两个重心
如果有三个重心,两两相邻,则不满足树的结构
3. 算法求解
任取一个节点为根,深度优先遍历,在返回时计算每一个节点的最大子树节点数,如果均不大于n/2,则记其为重心
代码实现:
int dfs_count(const vector<vector<int> >& tree, int num, int fa){
int len = tree[num].size();
int res = 1;
for(int i = 0; i < len; i++){
if(tree[num][i] == fa) continue;
res += dfs_count(tree, tree[num][i], num);
}
return res;
}
int dfs_center(const vector<vector<int> >& tree, int num, int fa, int n, vector<int>& center){
int len = tree[num].size();
int max_num = 0;
int res = 1;
for(int i = 0, tmp; i < len; i++){
if(tree[num][i] == fa) continue;
tmp = dfs_center(tree, tree[num][i], num, n, center);
max_num = max(max_num, tmp);
res += tmp;
}
if(n - res <= n / 2 && max_num <= n / 2) center.push_back(num + 1);
return res;
}
vector<int> get_center(const vector<vector<int> >& tree){
vector<int> center;
int n = dfs_count(tree, 0, -1);
dfs_center(tree, 0, -1, n, center);
cout << "center(s): ";
for(int i = 0; i < center.size(); i++){
cout << center[i] << " ";
}
return center;
} //两遍dfs可能效率不太高,如果事先已知节点总数则一遍dfs即可
测试结果(输入的树结构与直径处相同):

4.6.3 同构判断
1. 概念:两棵树有相同的拓扑结构,即可以通过对节点重新编号,使得两棵树之间的连接关系完全相同。其中有根树同构还要求两棵树的根节点必须是对应的,而无根树同构中只要满足一一映射关系即可
2. 算法求解:考虑先找到树的重心作为根节点,然后以此作有根树同构检验(最多两次,因为树A的重心和树B的两个重心都有可能匹配)(相比无根树同构n^2地做根节点匹配要方便得多)
代码实现:
bool root_cmp(vector<vector<int> >& tree1, vector<vector<int> >& tree2, int root1, int fa1, int root2, int fa2){
int len1 = tree1[root1].size();
int len2 = tree2[root2].size();
if(len1 != len2) return false;
for(int i = 0, j; i < len1; i++){
//思路:对应的从0 ~ len1-1一个一个找tree2[root2]中的节点与tree1[root1]中的节点对应
//找到了就把tree2[root2]对应的节点索引i, j交换
if(tree1[root1][i] == fa1){
for(j = i; j < len2; j++){
if(tree2[root2][j] == fa2){
swap(tree2[root2][i], tree2[root2][j]);
break;
}
}
if(j == len2) return false;
else continue;
}
//默认前面已经匹配完成
for(j = i; j < len2; j++){
if(tree2[root2][j] == fa2) continue;
if(root_cmp(tree1, tree2, tree1[root1][i], root1, tree2[root2][j], root2)){
swap(tree2[root2][i], tree2[root2][j]);
break;
}
}
if(j == len2) return false;
}
return true;
}
bool isomorphism(vector<vector<int> >& tree1, vector<vector<int> >& tree2){
//get_center沿用求重心代码中的
vector<int> center1 = get_center(tree1);
vector<int> center2 = get_center(tree2);
if(center1.size() > center2.size()) swap(center1, center2);
for(int i = 0; i < center2.size(); i++){
if(root_cmp(tree1, tree2, center1[0], -1, center2[i], -1)){
cout << "same" << endl;
return true;
}
}
cout << "not same" << endl;
return false;
}测试结果:
1. 有一个重心的情况
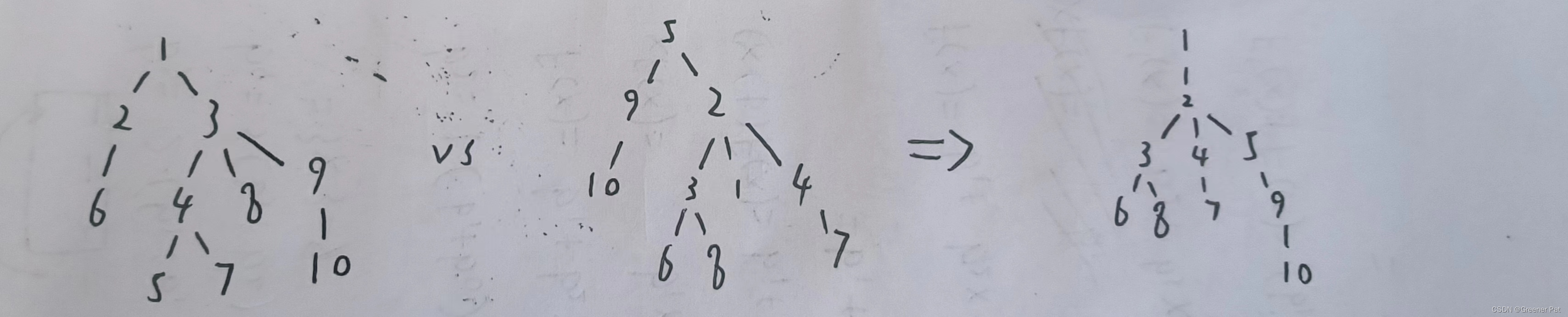

2. 稍微乱改一下

3. 有两个重心的情况
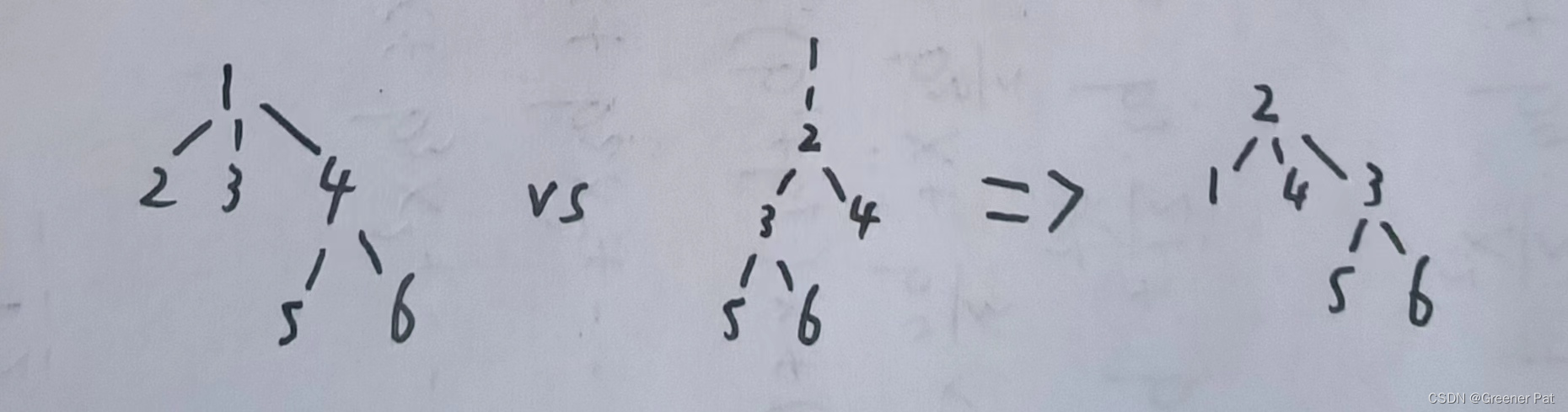

4.7 特殊的树结构
4.7.1 表达式树*
1. 概念:即非叶子节点全为操作符,叶子节点全为操作数的树。默认左子树op右子树,但也不一定是二叉的,因为可能有三元运算符 ? : 。如果遍历还原表达式的话,无论前序、中序、后序,叶子节点即数值的顺序不变(*当没有右结合的操作符时),但前序和后序不用加括号,中序要加
4.7.2 霍夫曼树
1. 概念:即给定一系列叶子节点的权值,要求构造一棵二叉树,使二叉树带权路径长度(WPL——Weighted Path Length),即最小,这样的树也叫“最优二叉树”
2. 霍夫曼算法:
步骤:
I. 维护两个序列,第一个序列最初为叶子节点权值序列,第二个序列为空。
II. 每一次分别从两个序列中取出最小的两个值a1, a2, b1, b2,之后从中选出最小的两个,从原来的序列中删除,将其加和的值放入第二个序列。
III. 然后做一个以它们加和为值的根节点,这两个值对应的结点(可能是某棵树的根节点,也可能是叶子节点)分别做这个跟的左右节点。
IV. 如果两个序列中还剩不止一个值(除非是第一个序列一开始就只有一个值以外,一定是第二个序列最后非空),则回到II
序列选择及操作:
若这叶子节点权值是乱序的,则可考虑维护两个小根堆,每次从中取出两个比较,没选上的再放回,加和也直接插入序列二对应的堆;
若叶子节点权值已经按照从小到大排序,则可用向量维护,每次选择两个序列前两个元素,加和后直接加入到序列二对应向量的尾部。(由数学归纳法,第一次选的一定是最小的两个值,且序列二中单增;假设前k次都选的是最小的两个值且序列二单增,如果第k+1次选择的两数加和小于序列二尾部元素,则上一次加和一定选的不是最小值——因为上一次能选的数一定小于等于这一次的,所以序列二一定保持单增,这样也能保证下一次选的值是两个序列中最小的)
3. 霍夫曼算法构建出的树是最优二叉树
证明(数学归纳法)
I. n = 2时,易得霍夫曼算法构建出的树是最优二叉树
II. 假设n = k时,霍夫曼算法构建出的树是最优二叉树;则对n = k + 1
设叶子结点的权值为{w1, w2, ……wn},已经由小到大排序,首先对{w1 + w2, w3 ……wn}建树,由假设可知,这样的树为最优二叉树,带权路径长度记为WPL(X)。然后在w1 + w2的节点之下添加子节点w1, w2得到霍夫曼算法构建出的树。其带权路径长度为WPL(X') = WPL(X) - (w1 + w2) * (deepest - 1) + w1 * deepest + w2 * deepest = WPL(X) + w1 + w2。
假设这样构建出的树不是最优二叉树,即另有构建方法使得WPL(Y') < WPL(X')。易得最优二叉树是满二叉树,所以最小的两个节点一定在最底层且互为兄弟节点。将Y'对应的树中w1与w2合并成一个父节点WPL(Y) = WPL(Y') - w1 - w2 > WPL(X') - w1 - w2 = WPL(X),这与X对应的是最优二叉树矛盾,故假设不成立
4. 具体实现(已排序的)
#define EMPTY_NUM 100000 //一个足够大的数来充当空值
int get_num(const vector<BTreeNode*>& nodes, int pos){
if(pos >= nodes.size()) return EMPTY_NUM;
else return nodes[pos]->val;
}
BTreeNode* sorted_Huffman(const vector<int>& val){
int n = val.size();
//直接全部做成叶子节点,之后再连接
vector<BTreeNode*> leaves(n);
vector<BTreeNode*> roots;
for(int i = 0; i < n; i++){
leaves[i] = new BTreeNode(val[i]);
}
int pos1 = 0, pos2 = 0;
if(n == 0) return NULL;
if(n == 1) return leaves[0];
BTreeNode* root;
int top1_1, top1_2, top2_1, top2_2;
while(pos2 < n - 2){
top1_1 = get_num(leaves, pos1);
top1_2 = get_num(leaves, pos1 + 1);
top2_1 = get_num(roots, pos2);
top2_2 = get_num(roots, pos2 + 1);
if(top1_2 <= top2_1){
root = new BTreeNode(top1_1 + top1_2, leaves[pos1], leaves[pos1+1]);
pos1 += 2;
}else if(top2_2 <= top1_1){
root = new BTreeNode(top2_1 + top2_2, roots[pos2], roots[pos2+1]);
pos2 += 2;
}else{
root = new BTreeNode(top1_1 + top2_1, leaves[pos1], roots[pos2]);
pos1++;
pos2++;
}
roots.push_back(root);
}
return root;
}4.7.3 前缀树
1. 概念:将一系列字符串用一个树结构维护,除了根节点外,每个节点对应一个字符,每一条从根到被标记的节点的路(如果不允许一个为另一个的前缀,则是根节点到叶子节点)代表一个不同的字符串。其中不同字符串的相同前缀共用同一条路,直到第一个不同节点才分叉。对于一个节点,它的子节点对应的字符一定互不相同
2. 具体实现(插入,删除,查找)(支持重复插入)(假设只考虑小写字母)
#include <iostream>
#include <vector>
#include <string>
using std::cin; using std::cout;
using std::endl; using std::vector;
using std::string;
struct node{
node():sons(vector<node*>(26, NULL)), leaf(0){}
int leaf; //以此表示是否为一字符串结尾,避免长覆盖短
vector<node*> sons;
//计算有多少个非空叶子
int count(){
int res = 0;
for(int i = 0; i < 26; i++){
if(sons[i] != NULL) res++;
}
return res;
}
};
class trie_tree{
public:
trie_tree():root(new node){}
~trie_tree(){del_tree(root);}
bool find(const string& s){
int count = find_add(s, false);
if(count > 0) cout << "found " << count << " \"" << s << "\"" << endl;
else cout << "\"" << s << "\" can't be found" << endl;
}
bool add(const string& s){
int count = find_add(s, true);
cout << "add \"" << s << "\", now exist " << count << endl;
}
//如果有删除,则返回true
bool remove(const string& s){
node* tmp_root = root;
int len = s.size();
bool cut = true;
int count = del(root, s, 0, len, cut);
if(count > 0) cout << "remove " << count << " \"" << s << "\"" << endl;
else cout << "\"" << s << "\" can't be found" << endl;
}
void del_tree(node* root){
if(root == NULL) return;
for(int i = 0; i < 26; i++){
del_tree(root->sons[i]);
}
delete root;
}
private:
node* root;
//查找(mode = false) + 添加(mode = true)
//如果查找到,则返回个数
//如果有添加,则返回添加后个数
int find_add(const string& s, bool mode){
node* tmp_root = root;
int len = s.size();
int res = 0;
for(int i = 0, num; i < len; i++){
num = s[i] - 'a';
if(tmp_root->sons[num] == NULL){
if(!mode){
res = -1;
break;
}
node* new_node = new node;
tmp_root->sons[num] = new_node;
res = true;
}
tmp_root = tmp_root->sons[num];
}
if(mode) res = ++(tmp_root->leaf);
else{
if(res != -1) res = tmp_root->leaf;
else res = 0;
}
return res;
}
//递归实现查找+删除
int del(node* tmp_root, const string& s, int pos, int n, bool& cut){
if(tmp_root == NULL){
cut = false;
return false;
}
if(pos == n){
if(tmp_root->leaf > 0){
int res = tmp_root->leaf;
cut = tmp_root->count() == 0;
if(cut) delete tmp_root;
else tmp_root->leaf = 0;
return res;
}
cut = false;
return 0;
}
int res = del(tmp_root->sons[s[pos]-'a'], s, pos+1, n, cut);
if(res > 0){
if(cut){
tmp_root->sons[s[pos]-'a'] = NULL;
if(tmp_root == root) return res;
if(tmp_root->count() == 0 && tmp_root->leaf == 0) delete tmp_root;
else cut = false;
}
}
return res;
}
};
int main(){
cout << "Welcome to Pat's Trie Tree Park!" << endl;
cout << "Please enter how many ops you want to have: ";
int n; //操作数量
cin >> n;
cout << "Have fun with yourself! (0:search, 1:add, 2:delete)" << endl;
trie_tree my_tree;
for(int i = 0, op; i < n; i++){
string s;
cin >> op >> s;
switch(op){
case 0:
//查找
my_tree.find(s);
break;
case 1:
//增加
my_tree.add(s);
break;
case 2:
//删除
my_tree.remove(s);
break;
}
cout << endl;
}
return 0;
}3. 前缀树的应用
I. 字典树:可用于储存大量字符串,并从中快速查找(如果结合KMP算法还可实现AC自动机),或实现词频统计等
II. 后缀树:后缀树即是一个字符串所有后缀组成的前缀树,其中每一个节点都不重复的记录了原字符串的一个子字符串。(后缀树还可以进行一些压缩*)
//注:前缀树的缺点一般在于占用空间较多,它其实是一种用空间换时间的结构
4.7.4 线段树(HBD)
4.7.5 并查集
I. 适用场景:问题中涉及到由一系列元素组成不相交的集合,且需要快速查询两元素是否在同一集合,或执行集合合并操作时适用。典型应用场景包括图论中的连通性问题(e.g. Kruskal中成环的判断),以及社交网络中的关系管理,乃至于LCA等
II. 基本思路:
a. 维护一个树(森林)结构,为每一个元素分配一个Node节点,这个节点至少包含一个Node*指针用于指向其父节点,除此之外还可以保存这个元素的其它信息(也可以另存),并且要保存对每个结点的访问表(可用vector/map等储存)。
b. 初始时每个元素父指针均为NULL,表示每个元素是独立的。从初始开始,保证每一个集合中所有元素有一个公共的根节点,及这棵树上的所有节点即对应集合中的所有数。合并两个集合,即将其中一棵树的根节点的父指针指向另一个根节点;查询两元素是否在同一集合时,即比较两者的根节点是否相同
// 优化方案上,主要有按秩合并和路径压缩两种思想:按秩合并即在合并时将较矮的树合并成较高的数的子树,这样可以使树相对平衡,便于根节点的查找;路径压缩即指每一次寻根时,直接将路径上所有节点的父节点设置成根节点,后续查询该路节点的根节点便只需O(1)即可。
//不过需要注意的是,路径压缩由于会改变树的高度,所以往往不易与按秩合并同用。由于按秩合并时间复杂度为O(logn),路径压缩平均时间复杂度为O(1),所以除了需要一直保持树的结构时使用按秩合并外,都用路径压缩实现并查集
III. 具体实现:
#include <iostream>
#include <vector>
using std::cin; using std::cout;
using std::vector; using std::endl;
template <class T>
struct Node{
Node():height(1), father(NULL){};
Node(T v):height(1), val(v), father(NULL){};
Node* father;
T val;
int height;
};
template <class T>
void swap(T& a, T& b){
T tmp = a;
a = b;
b = tmp;
}
//并
//合并两个集合
template <class T>
bool merge(Node<T>* a, Node<T>* b){
Node<T>* a_f = find(a);
Node<T>* b_f = find(b);
if(a_f != b_f){
//先检查是否本身就是同一个集合!!
if(a_f->height < b_f->height) swap(a, b);
b_f->father = a_f;
if(a_f->height == b_f->height) a_f->height++;
return true;
}else return false;
}
//查
//查询一个元素的父节点
template <class T>
Node<T>* find(Node<T>* node){
if(node == NULL) return NULL;
if(node->father == NULL) return node;
node->father = find(node->father); // 路径压缩
return node->father;
}
//集
//查询两个元素是否在一个集合
template <class T>
bool same_set(Node<T>* a, Node<T>* b){
Node<T>* a_f = find(a);
Node<T>* b_f = find(b);
return a_f == b_f;
}
int main(){
int nums, ops;
cout << "Welcome to Pat's Disjoint Set Park!" << endl;
cout << "Please enter how many elements you want to have: (default nums 1 ~ n) ";
cin >> nums;
cout << "Please enter how many ops you want to have: ";
cin >> ops;
vector<Node<int> > nodes(nums);
for(int i = 0; i < nums; i++){
nodes[i].val = i + 1;
}
cout << "Have fun with yourself! [0:find(a), 1:same_set(a, b), 2:merge(a, b)]" << endl;
for(int i = 0, op, a, b; i < ops; i++){
cin >> op;
Node<int>* res;
switch(op){
case 0:
cin >> a;
res = find(&nodes[a-1]);
cout << a << "' root is " << res->val << endl;
break;
case 1:
cin >> a >> b;
if(same_set(&nodes[a-1], &nodes[b-1])) cout << a << " and "<< b << " are in the same set" << endl;
else cout << a << " and "<< b << " aren't in the same set" << endl;
break;
case 2:
cin >> a >> b;
if(merge(&nodes[a-1], &nodes[b-1])) cout << a << "' and " << b << "' sets are merged" << endl;
else cout << a << " and " << b << " are already in the same set" << endl;
break;
}
}
return 0;
}IV. 测试效果:
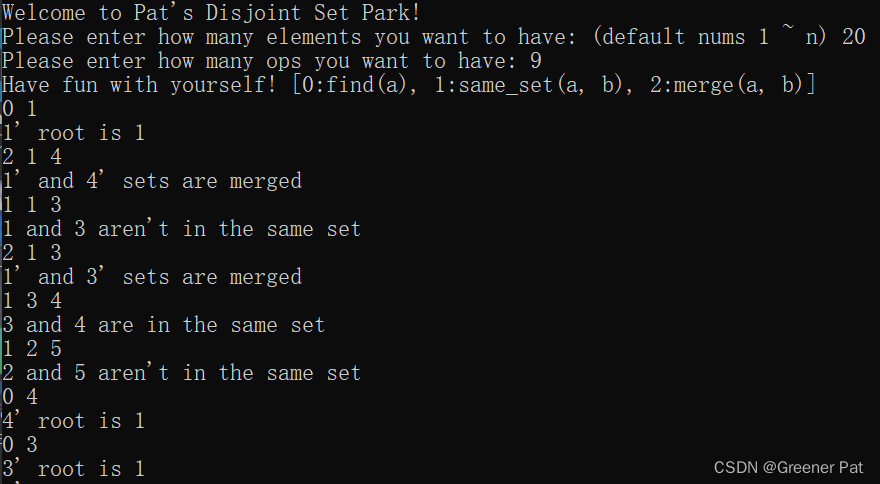
V. 性能分析
时间复杂度(一次查询/合并):按秩合并 —— O(logn)
路径压缩 —— 近似O(1) // 在n < 10^80的时候都有 α < 4
第五章 堆与优先级队列
5.1 二叉堆
1. 概念:父节点元素和子结点元素满足一定关系的完全二叉树,根据关系的不同,常用有有最大堆和最小堆。最大堆即父节点元素要求大于子结点元素,故根节点处为堆中的最大值,最小堆相反
//注:由于结构满足完全二叉树,所以其实可用一个数组储存
2. 基本操作:
a. 上调:即某个位置元素不满足要求的父子结点关系时,不断将其与父节点比较并交换,直到移到合适的位置。时间复杂度O(logn)
b. 下调:同样是不满足要求的关系,但将其与子结点比较、交换,移到对应的位置。时间复杂度O(logn)
c. 插入:可先放在在堆尾,然后上调 O(logn)
d. 删除(堆顶):可将堆顶值赋成堆尾值,然后删除堆尾,再执行下调 O(logn)
e. 建堆:可先将元素放在数组/向量中,然后通过自底向上,逐个下调实现堆结构。时间复杂度O(n) //如果从底到顶逐个上调会增加时间复杂度
3. 具体实现:
#include <iostream>
#include <vector>
#include <stdexcept>
using std::cin; using std::cout;
using std::vector; using std::domain_error;
using std::endl;
template <class T>
void swap(T& a, T& b){
T tmp = a;
a = b;
b = tmp;
}
template <class T>
bool default_cmp(const T& a, const T& b){
return a < b;
}
//堆/优先队列
//仅支持向量存储
//默认大根堆,如果需使用别的比较方式可再参数中传入函数指针
//真正STL库的对比较是通过()操作符重载,比较方式与顺序恰好与sort排序相反
template <class T>
class heap{
public:
//类型定义与构造函数
typedef bool (*cmp_fun)(const T&, const T&);
heap(cmp_fun func = default_cmp):size_(0), len(0), eles(), cmp_(func){}
heap(const vector<T>& vec, cmp_fun func = default_cmp): size_(vec.size()), len(vec.size()), eles(vec), cmp_(func){construct();}
//访问器函数
T& top(){
if(size_ == 0) throw domain_error("heap is empty\n");
else return eles[0];
}
const T& top() const {
if(size_ == 0) throw domain_error("heap is empty\n");
else return eles[0];
}
bool empty() const {return size_ == 0;}
int size() const {return size_;}
//堆操作
void pop(){
if(size_ == 0) throw domain_error("heap is empty\n");
eles[0] = eles[size_-1];
shift_down(0);
size_--;
}
void push(const T& new_ele){
if(size_ < len) eles[size_] = new_ele;
else{
eles.push_back(new_ele);
len++;
}
shift_up(size_);
size_++;
}
private:
vector<T> eles;
int size_; //有多少个元素
int len; //数组有多长,在pop后可能元素个数小于数组长度
cmp_fun cmp_;
//私有函数
void construct(){
for(int i = size_; i > -1; i--){
shift_down(i);
}
}
//上调
void shift_up(int pos){
while(pos != 0){
if(cmp(eles[pos], eles[(pos-1)/2])){
swap(eles[pos], eles[(pos-1)/2]);
pos = (pos - 1) / 2;
}else break;
}
}
//下调
void shift_down(int pos){
while(pos * 2 + 1 < size_){
if(pos * 2 + 2 < size_ && cmp(eles[pos*2+2], eles[pos]) && cmp(eles[pos*2+2], eles[pos*2+1])){
swap(eles[pos], eles[pos*2+2]);
pos = pos * 2 + 2;
}else if(cmp(eles[pos*2+1], eles[pos])){
swap(eles[pos], eles[pos*2+1]);
pos = pos * 2 + 1;
}else break;
}
}
//比较
bool cmp(const T& a, const T& b) const {
return cmp_(a, b);
}
};4. 功能
在不断加入删除的序列中维护最大(小)值 / 第k大(小)值 / 中位数等,可用于许多中算法的优化(包括最短路径,最小生成树等)
1. Top-k:逐个从堆顶取出,每一次取出后调节
2.堆排序(见内排序一章)
3.优先队列:可直接调用STL库中的priority_queue,实现需要动态维护最大值/第k最/某一比例点元素算法的优化
5.2 多叉堆(HBD)
1. 与二叉堆区别:上调变快——log的底数从2变为k,但下调变慢——log前系数从2变为k
2. 用途:插入(上调)多而删除(下调)少的情景;同时多叉堆具有更好的高速缓存特性,当数据非常庞大时或能体现出优势
5.3 可并堆(HBD)
第六章 图
6.1 图的基本概念、储存
6.1.1 图的基本概念
1. 定义:图是由顶点集和边集(都是有穷集合)组成的一种数据结构(边集可以加权)
2. 度:一个顶点的度是与他相连的边的数量,有向图中又分入度与出度
3. 路径:由顶点组成的序列,其长度值边的条数(带权图指路上的边权之和)
4. 生成树:包含原图所有顶点的极小连通子图(大概率不唯一)
6.1.2 图的储存
1. 接邻矩阵:直接用一个n x n的矩阵(二维向量/数组)保存所有边之间的信息,i, j 两点之间有边即将M[i][j], M[j][i]置为1或对应的权值,若是有向边则只操作其中一个;若没有变则将M[i][j]存为一个特殊的数,通常为极大数或负值
2.接邻表:通常用二维向量实现,只在 i, j 之间有边时将j保存至M[i]中
//注:由于图中每个点的入度不一定为1,所以不用父节点表示法来保存
具体实现:
int main(){
int n, m;
cin >> n >> m; //n是节点数目,m为边的数目
vector<vector<int> > connection1(n, vector<int>(n));
vector<vector<int> > connection2(n);
vector<int> fa(n);
//邻接矩阵
for(int i = 0, u, v; i < m; i++){
//默认输入编号是1-n
cin >> u >> v;
connection1[u-1][v-1] = connection1[v-1][u-1] = 1;
}
//邻接表
for(int i = 0, u, v; i < m; i++){
cin >> u >> v;
connection2[u-1].push_back(v-1);
connection2[v-1].push_back(u-1);
}
return 0;
}两者比较:
| 优点 | 缺点 | |
| 邻接矩阵 | 可O(1)查询两点之间的关系 | 耗费空间大,遍历时的时间开销大O(n^2) |
| 邻接表 | 空间占用小,遍历时间复杂度O(n) | 查询任意两点关系相对较慢 |
使用情况:
父节点表示通常是在储存时压缩空间用,而不用于具体查询相关量;除非在接近完全图的情况下,一般不用邻接矩阵而都用邻接表
6.2 图中的基本操作
6.2.1 遍历
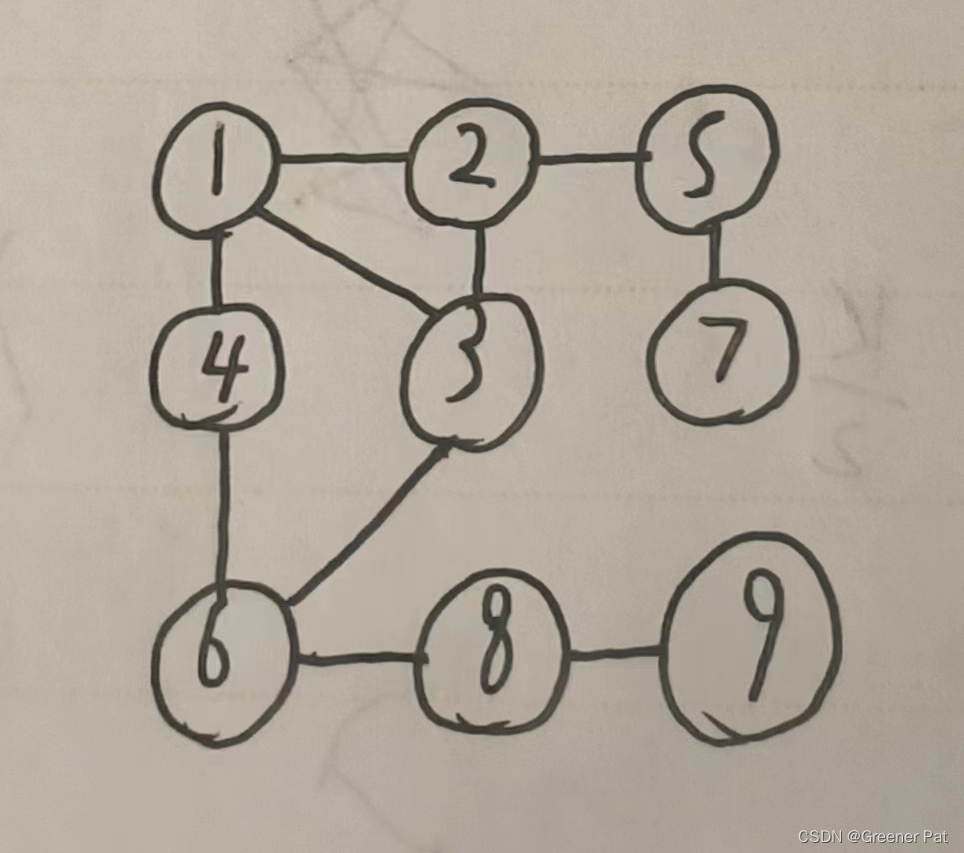
与树相同,主要分为深度优先和广度优先两种;不同的是,由于图中可能成环,所以对之前遍历过的点需要标记。具体实现如下:
//深度优先遍历(depth first)
void dfs(const vector<vector<int> >& graph, vector<bool>& visited, int num){
if(visited[num]) return;
visited[num] = true;
cout << num + 1 << " ";
int len = graph[num].size();
for(int i = 0; i < len; i++){
dfs(graph, visited, graph[num][i]);
}
}
//广度优先遍历(breadth first)
void bfs(const vector<vector<int> >& graph){
//广度优先可以内部处理visited数组
vector<bool> visited(graph.size(), false);
queue<int> nodes;
nodes.push(0);
while(!nodes.empty()){
int front = nodes.front();
nodes.pop();
if(visited[front]) continue;
visited[front] = true;
cout << front + 1 << " ";
int len = graph[front].size();
for(int i = 0; i < len; i++){
nodes.push(graph[front][i]);
}
}
}具体效果:
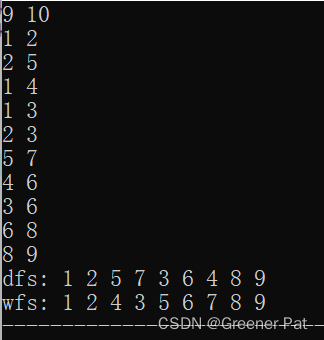
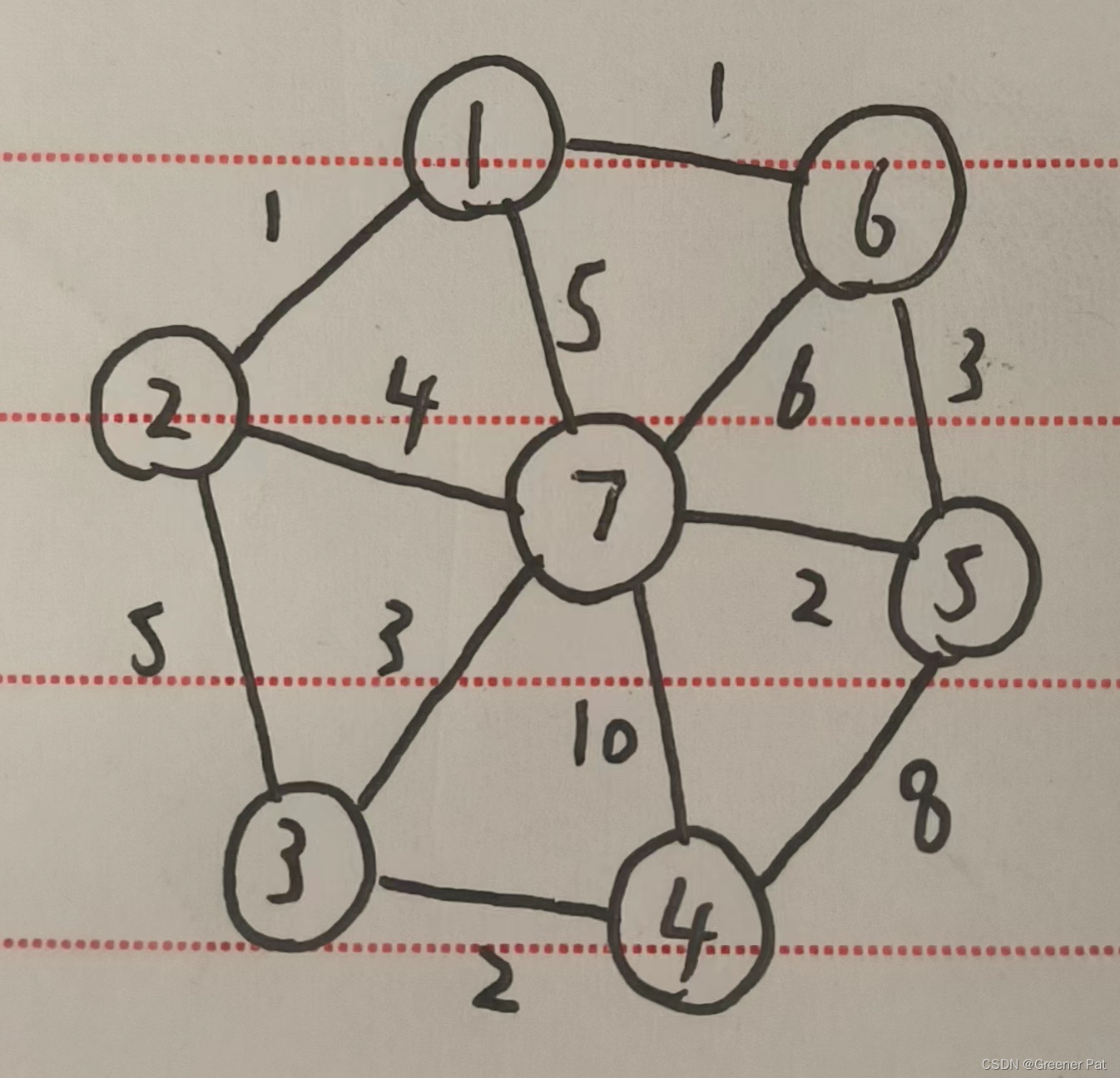
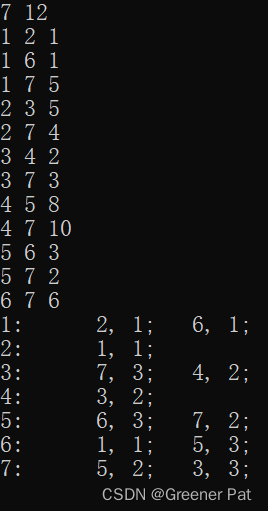
性能分析:
邻接表:O(n+e)需要查找所有点和边; 邻接矩阵:O(n^2),查找每个点的所有边都需要O(n)
6.2.2 最小生成树(证明HBD)
1. 概念:及一个带权图的生成树中所有边的权值之和最小的一个 //这里的图一定保证联通
2. Prim算法:
I. 具体步骤:
a. 先设一个空图S,从原图G中任意选一个点加入S
b. 考察G中所有只有一个端点在S中的边,选取其中最短的一条,将改变和其另一个不在S中的端点加入S
c. 重复b直到G中不再有这样的边,得到最终的S即是G的最小生成树
II. 证明(HBD)——反证法,两个图从同一个点开始”匹配“,便能相同则相同,不能相同则设置成环……
III.具体实现(加入堆优化——选择最短边时):
vector<vector<T> > prim(const vector<vector<T> >& graph){
int n = graph.size();
vector<vector<T> > res(n);
vector<bool> unchosen(n, true);
priority_queue<S, vector<S>, greater<S> > heap;
int count = 0, add = 0; //不妨从第一个开始加
int from, way_len;
while(count < n - 1){
unchosen[add] = false;
count++;
//添加新加入的边
int len = graph[add].size();
for(int i = 0, tmp; i < len; i++){
tmp = graph[add][i].second;
if(unchosen[tmp]) heap.push(make_pair(graph[add][i].first, make_pair(add, tmp)));
}
//得到最小的,不构成回路的的边,并加入
while(!heap.empty() && !unchosen[heap.top().second.second]) heap.pop();
add = heap.top().second.second;
from = heap.top().second.first;
way_len = heap.top().first;
res[add].push_back(make_pair(way_len, from));
res[from].push_back(make_pair(way_len, add));
heap.pop();
}
return res;
}IV.测试结果:
V. 复杂度分析
无堆优化:O(V^2)——每加入一次节点就要遍历所有未加入的节点到S的边长,以选出最小的一条,复杂度为O(V),需要重复V次
堆优化:O((V+E)*logE)——在堆中插入或删除的时间复杂度是O(logE),每一条边都会至少入堆一次O(E),最少出堆V-1次,最多E次O(V+E),故复杂度为O((V+E)logE)。但其实连通图中O(E)一定大于等于O(V),故也可写为O(ElogE)
3. Kruskal算法
I. 具体步骤
a. 先设一个空图S
b. 选择原图G中的不在S中边中最小的一条,如果其加入S不会构成回路,则将其加入S,反之则丢弃
c. 重复上述操作,直到G中不再有边,最终得到的S即是最小生成树
II. 证明(HBD)——也用反证(集图)
III. 具体实现(加入并查集+堆优化):
//并查集实现
template <class T>
class Node{
public:
Node(Node* fa = NULL):father(fa){}
//查找根节点
Node* Find(){
if(father == NULL) return this;
father = father->Find();
return father;
}
void set_father(Node* fa){father = fa;}
private:
Node* father;
T val;
};
//判断是否相同集合
template <class T>
bool Search(Node<T>* a, Node<T>* b){
return a->Find() == b->Find();
}
//合并集合
template <class T>
void Union(Node<T>* a, Node<T>* b){
Node<T>* a_f = a->Find();
Node<T>* b_f = b->Find();
if(a_f != b_f) b_f->set_father(a_f);
}
typedef pair<int, int> T; //前一个是长度,后一个是索引
typedef pair<int, pair<int, int> > S; //前一个是长度,后两个是起点与终点
vector<vector<T> > kruskal(const vector<vector<T> >& graph){
int n = graph.size();
vector<vector<T> > res(n);
vector<Node<int> > nodes(n);
priority_queue<S, vector<S>, greater<S> > heap;
//先将所有边全部推入堆
for(int i = 0; i < n; i++){
int len = graph[i].size();
for(int j = 0; j < len; j++){
//避免一条边入堆两次
if(graph[i][j].second > i) heap.push(make_pair(graph[i][j].first, make_pair(graph[i][j].second, i)));
}
}
while(!heap.empty()){
S top = heap.top();
heap.pop();
//判断两端点是否在同一个集合——加入该边会成环
int endian1 = top.second.first;
int endian2 = top.second.second;
if(Search(&nodes[endian1], &nodes[endian2])) continue;
Union(&nodes[endian1], &nodes[endian2]);
res[endian1].push_back(make_pair(top.first, endian2));
res[endian2].push_back(make_pair(top.first, endian1));
}
return res;
}IV. 测试结果:同上(略)
V. 性能分析:
时间复杂度
//都在有并查集的基础上讨论——查询时间均摊O(1),没有的话每次判断是否成环的复杂度为O(n),难以接受
无堆优化:O(V*E)——每次便历O(E)条边以找出最小的一个,需要进行O(V)次
堆优化:O(E*logE)——建堆时遍历所有点和边,直接由数组建堆O(V+E) ,构建最小生成树最多需要出堆O(E),最少O(V)次,复杂度为O((V+E)logE)。由于连通图O(E) >= O(V),故总复杂度为O(ElogE) //如果用邻接表存的话,建堆需要O(V^2),总复杂度为O(ElogE + V^2)
4. 两者的适用情况
Prim算法主要适用于图接近完全图的时候,此时反而不用堆优化更好,时间复杂度为O(V^2),加了堆/Kruskal的复杂度都为O(V^2logV)
Kruskal算法更适用于图比较稀疏,即边比较少的情况
6.2.3 最短路径(证明HBD)
问题概述:求图中某一点到达另一点的最短路径(一般针对带权图,无权图则把每条边权值赋为1即可)
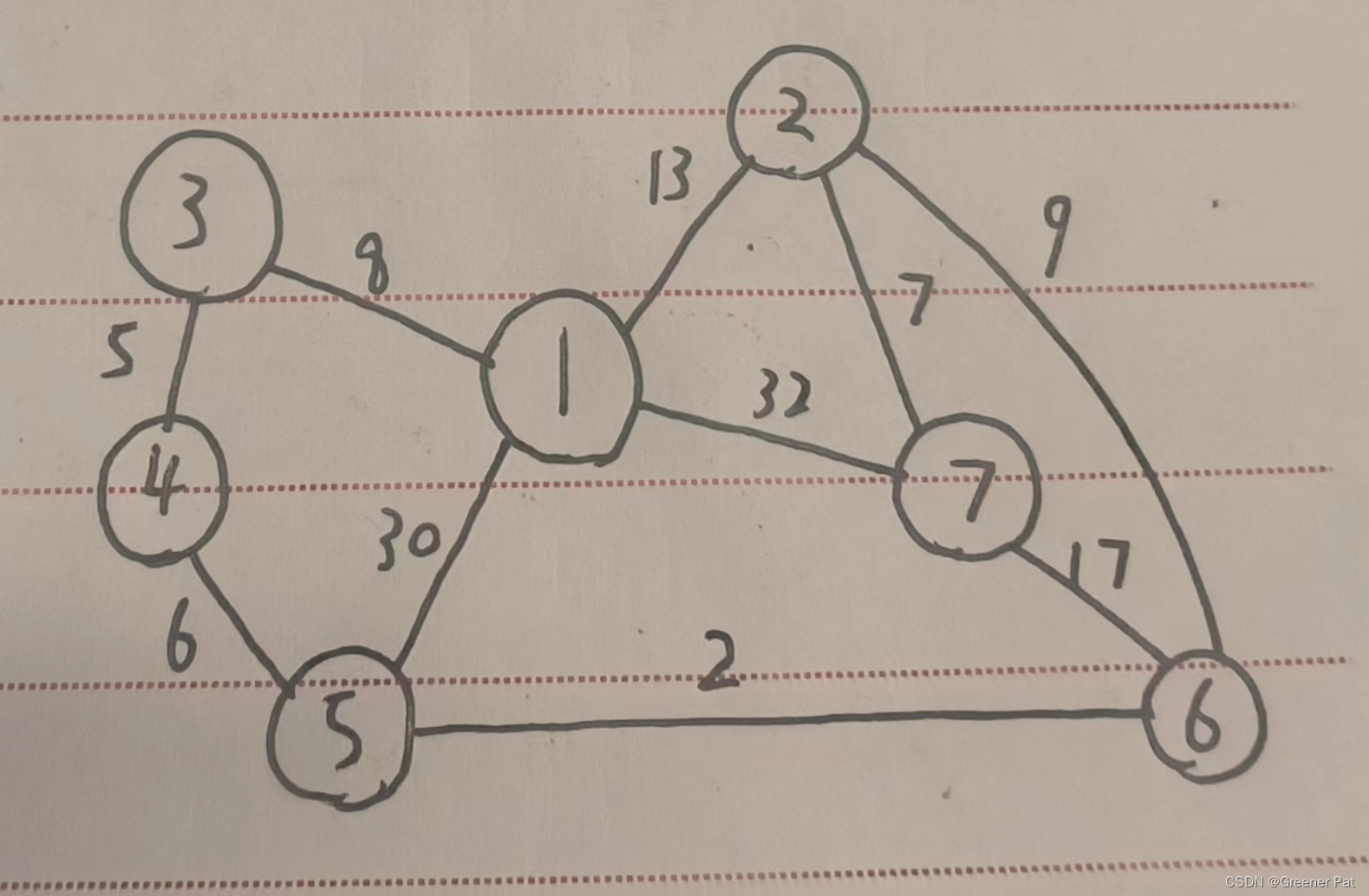
1. Dijkstra算法
I. 适用情景:单源(即从一个点出发,到任意点的最短路)无负权边的最短路问题
II. 算法步骤
a. 初始化集合S及长度标记数组L,父节点数组fa,将源点(记为src)的长度L[src]标记为0,fa标记为空,其他的点都标记为正无穷
b. 选取G-S中L最小的点记为add,将add加入到S,更新add的所有不在S中的邻点i,若L[i] <= L[add] + d(add, i),则保持;反之则将L[i]修改为L[add] + d(add, i),并令fa[i] = add
c. 重复上述步骤直到G-S中不再有点,得到的L即是每个点到源点的最短路径长,fa标记这条最短路上的上一个节。如果某个点的L未标记的无穷大,则说明没有从源点到这个点的路
III.证明(HBD)——数学归纳法
IV. 具体实现(堆优化):
#define NO_WAY 100000000
typedef pair<int, int> T; //前一个是长度,后一个是索引
void dijkstra(const vector<vector<T> >& ways, vector<int>& dis, vector<int>& fa, int src){
int n = ways.size();
vector<bool> chosen(n, false);
dis = vector<int>(n, NO_WAY);
fa = vector<int>(n, -1);
dis[src] = 0;
priority_queue<T, vector<T>, greater<T> > heap;
heap.push(make_pair(0, src));
int add;
while(!heap.empty()){
T top = heap.top();
heap.pop();
add = top.second;
chosen[add] = true;
//不用再设置距离和父节点,之前已经做好
int len = ways[add].size();
for(int i = 0; i < len; i++){
int near = ways[add][i].second;
if(!chosen[near]){
//更新
if(dis[near] > dis[add] + ways[add][i].first){
dis[near] = dis[add] + ways[add][i].first;
fa[near] = add;
}
heap.push(make_pair(dis[near], near));
}
}
//必须在最后面清理,不然会多查一次重复的
while(!heap.empty() && chosen[heap.top().second]) heap.pop();
}
}V. 测试效果:
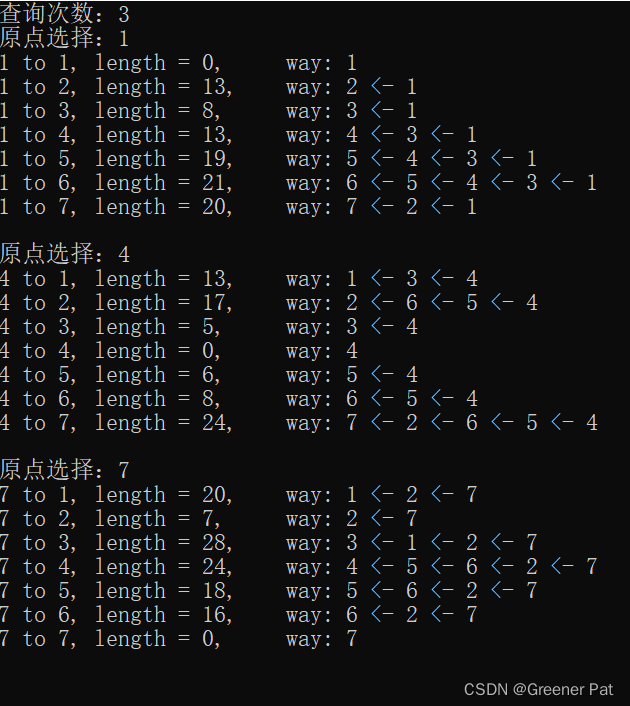
VI. 性能分析:
无堆优化:O(V^2)——找出dis最小的点每次需要遍历所有点,时间开销为O(n),一共有n此这样的操作,而更新邻点的总时间复杂度为O(E),又因为O(V^2) >= O(E),故总时间复杂度为O(V^2)
堆优化:O(ElogE)——每条边都会入堆一次,出堆次数最多O(E),故总时间复杂度为O(ElogE)
//注:不同于求生成树,这里图可以不连通
2. Floyd算法
I. 使用情景:图中任意两点之间的最短路,路可以是负权
II. 算法步骤:
a. 初始化两个N * N 的矩阵dis 和 fa,分别用来保存任意两点之间的最短路径长,和这条路径上的前一个结点
b. 设置k从1到n进行n次循环,每次循环中,如果i、j之间有一条/或多条只经过(不包括端点)编号为1-k的点的路,则将dis和fa的对应位置标记为对应的值
III. 证明(HBD)
IV. 具体实现:
//有负权路时必须加一个下界有效判断VALID,以判断最终结果是否有效
#define NO_WAY 10000
#define VALID 1000 //以下才是有效范围
void floyd(const vector<vector<T> >& ways, vector<vector<int> >& dis, vector<vector<int> >& fa){
int n = ways.size();
//矩阵中[i][j]表示i->j
dis = vector<vector<int> >(n, vector<int>(n, NO_WAY));
fa = vector<vector<int> >(n, vector<int>(n, -2));
for(int i = 0; i < n; i++){
int len = ways[i].size();
for(int j = 0; j < len; j++){
int des = ways[i][j].second;
dis[i][des] = ways[i][j].first;
fa[i][des] = des;
}
dis[i][i] = 0;
}
for(int k = 0; k < n; k++){
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
if(dis[i][j] > dis[i][k] + dis[k][j]){
dis[i][j] = dis[i][k] + dis[k][j];
fa[i][j] = fa[i][k];
}
}
}
}
//有效性判断
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
if(dis[i][j] > VALID){
dis[i][j] = NO_WAY;
fa[i][j] = -2;
}
}
}
}V. 测试效果(数据同Dijstra算法):
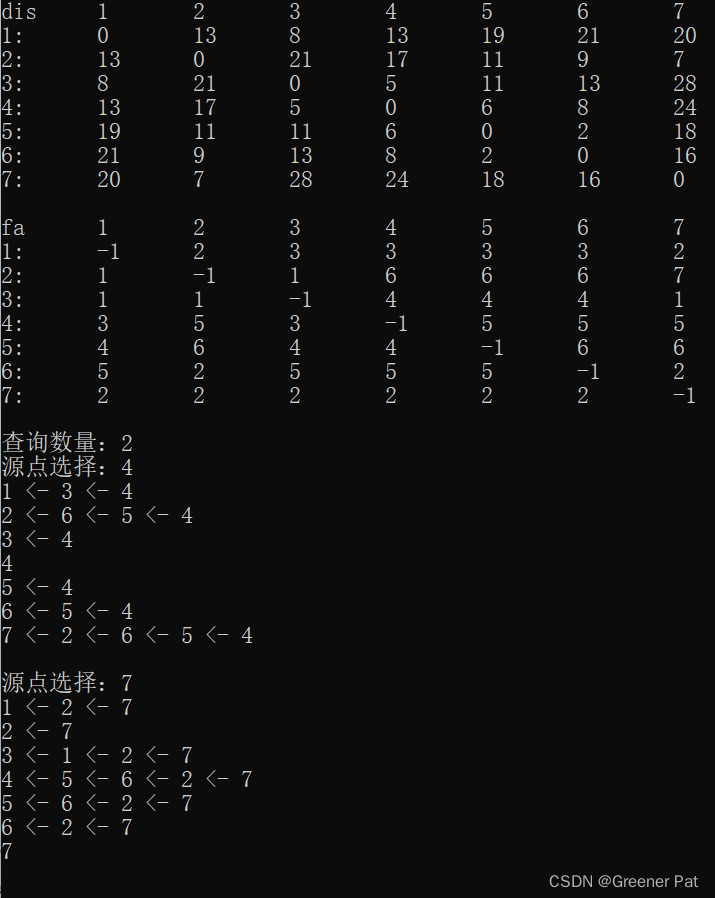
VI. 性能分析:
时间复杂度:O(V^3)——三重循环,简单易写,常数小
3.Bellman_Ford算法
I.使用情景:单源有负权最短路
II.算法步骤:
a.初始化一个n*n的connection数组——记录两两点之间的道路长度(可有向),和一个n*(n-1)的dist数组——dist[i][j]记录从原点出发,最多经过j+1条边(因为下标从0开始),达到顶点i所需的最短路程,以及一个1*n的向量fa以记录每个点对应最短路上的上一个父节点
b.用邻接表填充connection(或者本来就是邻接矩阵),以及dist的第一列
c.迭代n-2次,遍历i:0->n-1, j:0->n-1,dist[i][k] = min(dist[i][k-1], dist[j][k-1] + connection[j][i]),并更新fa //有方向要求connection即是从j->i
d.停止迭代时,fa即是最终的父节点向量,dist的第n-1列(索引为n-2)即是源点到每个点的最短路
III.证明(HBD)
IV.具体实现:
//同样需要加上VALID以规定有效“更短路”
#define NO_WAY 10000
#define VALID 1000 //以下才是有效范围
typedef pair<int, int> T; //前一个是长度,后一个是索引
void bellman_ford(const vector<vector<T> >& ways, vector<int>& dis, vector<int>& fa, int src){
int n = ways.size();
fa = dis = vector<int>(n, -1);
vector<vector<int> > dist(n, vector<int>(n - 1, NO_WAY));
vector<vector<int> > connection(n, vector<int>(n, NO_WAY));
for(int i = 0; i < n; i++){
int len = ways[i].size();
for(int j = 0; j < len; j++){
int des = ways[i][j].second;
connection[i][des] = ways[i][j].first;
if(i == src){
dist[des][0] = ways[i][j].first;
fa[des] = src;
}
}
connection[i][i] = 0;
}
dist[src][0] = 0;
for(int k = 1; k < n - 1; k++){
for(int i = 0; i < n; i++){
dist[i][k] = dist[i][k-1];
for(int j = 0; j < n; j++){
if(dist[i][k] > dist[j][k-1] + connection[j][i]){
dist[i][k] = dist[j][k-1] + connection[j][i];
fa[i] = j;
}
}
}
}
for(int i = 0; i < n; i++){
if(dist[i][n-2] > VALID){
dis[i] = NO_WAY;
fa[i] = -1;
}
else dis[i] = dist[i][n-2];
}
}V. 测试结果:
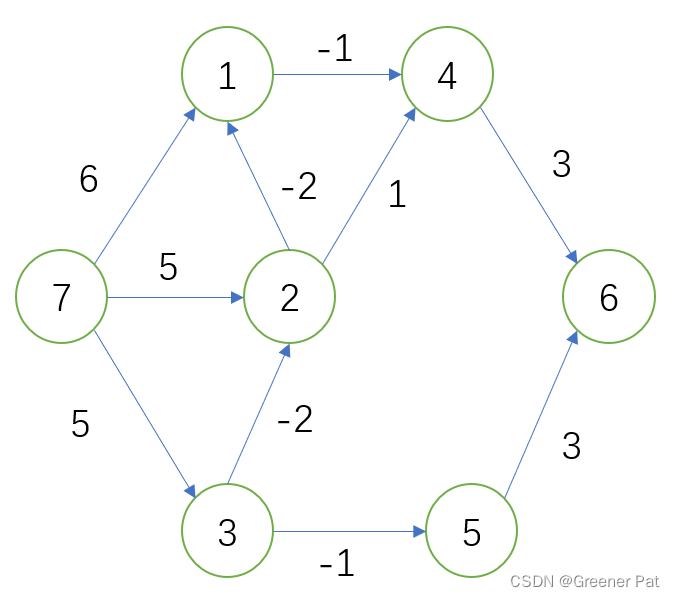
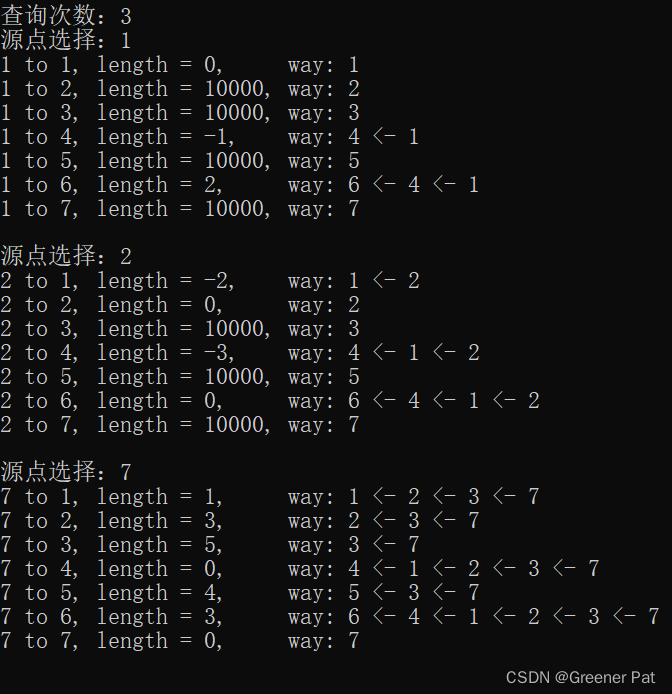
VI.性能分析:
时间复杂度:O(V^3),主要是三层循环决定的
注:一般不必要用Bellman_Ford,因为正权单源下Dijkstra复杂度更低,负权时同样复杂度Floyd可做任意两点(而且好写/狗头)
6.2.4 拓扑排序与关键路径
背景概念:
过程、流程等都是“工程”,一般吧工程分为若干个叫做“活动”的子工程,完成这些活动,工程即可完成
1. AOV上的拓扑排序
I.概念:
a.AOV网络:用有向图表示一个工程,顶点表示活动,有向边(Vi, Vj)表示活动i必须先于活动j完成,这种以定点为活动的有向图叫做AOV网络(Activity On Vertices)
//AOV网络中不能出现有向回路,否则工程不可能完成。所以对给定的AOV网络,必须先判断是否有有向环
b.拓扑有序序列:将各个顶点排列成一个线性有序序列,是各顶点前驱后继关系都能被满足。排序过程即叫拓扑排序,这是一种检测AOV网络是否有环的有效方式
II.排序算法
a.初始化一个记录排序顺序的向量order
b.选择一个没有直接前驱的点,加入order,并删除从其出发的所有边
c.重复b,直到不再有这样的点。如果所有点均加入order,则完成拓扑排序,否则则说明存在有向环
III.具体实现:
void AOV_sort(const vector<vector<T> >& graph, vector<int>& res){
//AOV拓扑排序只考虑顺序,不考虑长度
int n = graph.size();
vector<vector<bool> > tag(n); //记录一条边是否被删过
res = vector<int>(n);
vector<int> count(n); //记录入度,入读归0后模拟栈
int top = -1, tmp_top; //栈顶“指针“,和暂存的栈顶
int pos = 0; //记录有多少个元素已排序
for(int i = 0; i < n; i++){
int len = graph[i].size();
for(int j = 0; j < len; j++){
count[graph[i][j].second]++;
}
}
//最初的入栈
for(int i = 0; i < n; i++){
if(count[i] == 0){
count[i] = top;
top = i;
}
}
//栈非空循环
while(top != -1){
res[pos++] = top;
tmp_top = top;
//栈顶出栈
top = count[top];
int len = graph[tmp_top].size();
for(int i = 0; i < len; i++){
//这里必须用tmp_top,因为后续元素入栈会导致栈顶改变
if(--count[graph[tmp_top][i].second] == 0){
count[graph[tmp_top][i].second] = top;
top = graph[tmp_top][i].second;
}
}
}
if(pos != n) res.clear();
}IV. 测试结果:

V. 性能分析:
时间复杂度:O(V+E)——建立count需要遍历一遍边,但至少也会查看每个点是否有边O(V+E),之后将count为0的点入栈O(V),排序时每次将从栈顶出发的边删除,且对所有点O(V+E)。故总时间复杂度为O(V+E),连通图中既可作O(E)
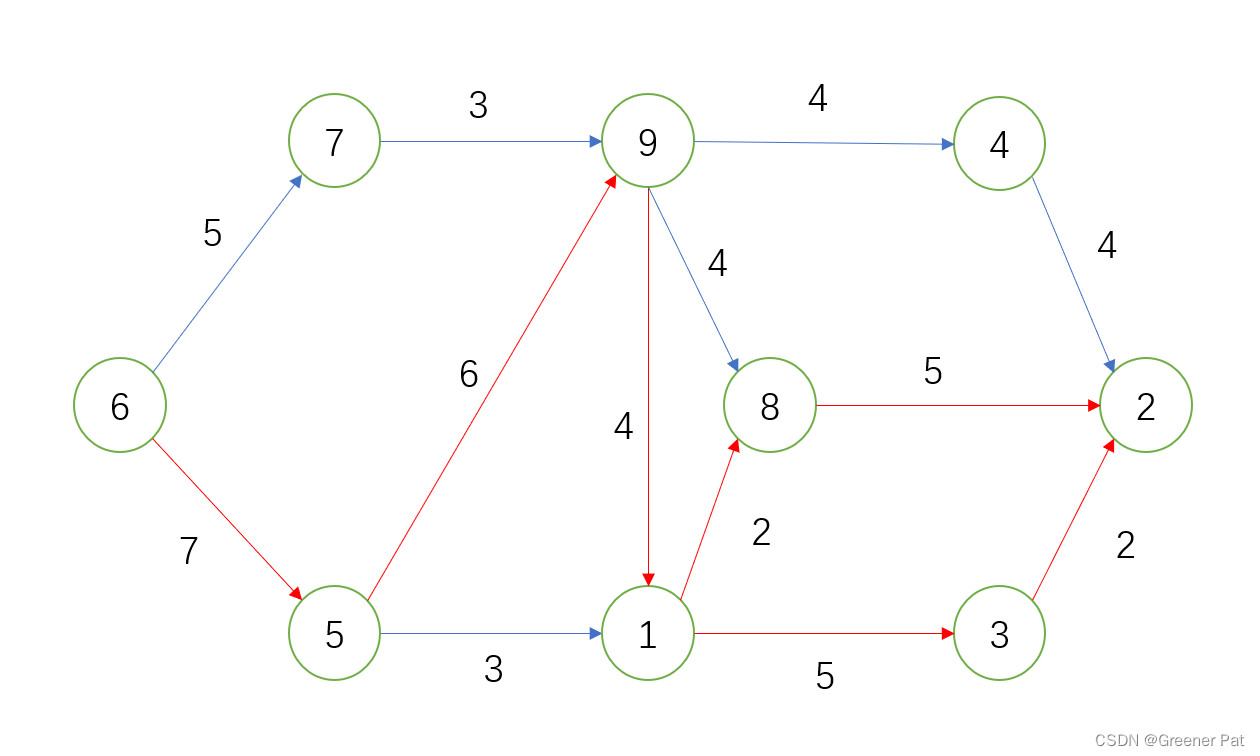
2. AOE上的关键路径
I. 概念:
a. AOE网络:在无有向环的带权图中,有向边表示工程中的活动,权值表示活动的持续时间,顶点表示事件(可理解成某项活动完成),这样的有向图称为AOE网络(Activity On Edges)
b. 源点和汇点:由于AOE网络要求无有向环,所以一定有顶点入度为0——源点,或出度为0——汇点
c. 关键路径:只有所有活动均完成,工程才算结束,所以工程进行的时间取决于源点到汇点的最长路径。这样的路径(准确说应该是路网——可能不止一条),即叫做关键路径
d. 关键活动:及不按期完成就会影响整个工程完成的活动,事实上关键路径上所有边都是关键活动
II. 相关量及计算规则
相关量:
ee[i]:事件Vi最早可能开始的时间, earlist event
le[i]:事件Vi最迟允许开始的时间(在不影响工程最快完成的情况下), latest event
e[k]:活动Ek最早可能开始时间, earlist
l[k]:活动Ek最迟允许开始时间, latest
规则(Ek = (Vi, Vj)):
a. 关键活动即是e[k] = l[k]的活动
b. e[k] = ee[i], l[k] = le[j] - |Ek|
III. 关键路径算法:
a. 拓扑排序预处理,得到活动先后顺序
b. 从前向后遍历,计算出每个事件的ee;再从后向前遍历(不需逆邻接表),计算出每个事件的le
c. 遍历边(不要求顺序),计算判断每个活动的e和l是否相同,同时构建关键路网
VI. 具体实现(拓扑排序即沿用上文的):
#define LE_MAX 10000
vector<vector<T> > AOE_critical_path(const vector<vector<T> >& graph){
int n = graph.size();
//拓扑排序
vector<int> seq;
AOV_sort(graph, seq);
if(seq.size() != n){
cout << "There's a loop in the graph!";
exit(1);
}
//初始化ee, le
vector<int> ee(n, 0), le(n, LE_MAX);
//从前向后遍历seq,求出ee
for(int i = 0; i < n; i++){
int len = graph[seq[i]].size();
for(int j = 0; j < len; j++){
T tmp = graph[seq[i]][j];
ee[tmp.second] = max(ee[tmp.second], ee[seq[i]] + tmp.first);
}
}
//从后先前遍历seq,求le
for(int i = n - 1; i > -1; i--){
int tmp = seq[i];
int len = graph[tmp].size();
if(len == 0) le[tmp] = ee[tmp]; //汇点
else{
for(int j = 0; j < len; j++){
le[tmp] = min(le[tmp], le[graph[tmp][j].second] - graph[tmp][j].first);
}
}
}
//遍历边,构建关键路径
vector<vector<T> > res(n);
for(int i = 0; i < n; i++){
int len = graph[i].size();
for(int j = 0; j < len; j++){
//直接比较,省去计算e[k]和l[k]的中间过程
if(ee[i] == le[graph[i][j].second] - graph[i][j].first) res[i].push_back(graph[i][j]);
}
}
cout << "关键路径:\n";
for(int i = 0; i < n; i++){
int tmp = seq[i];
cout << tmp + 1 << ": ";
int len = res[tmp].size();
for(int j = 0; j < len; j++){
cout << res[tmp][j].second + 1 << " ";
}
cout << "\n";
}
return res;
}V. 测试结果:
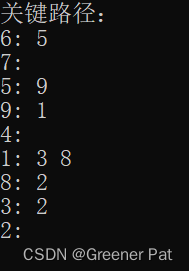
VI. 性能分析:
时间复杂度:O(V+E)——首先拓扑排序O(V+E),每一遍历都是以点为索引,对边的遍历O(V+E)
第七章 内排序
基本概念:内排序,即在内存中进行的排序操作,要求排序的元素是一个全序集(两两之间都可比,而非成图的拓扑结构),主要区分于外排序(在外部存储设备中的排序)。后者重点考虑访存的次数,要求其尽可能少,前者则更重视时间复杂度的分析。不过需要注意的是,由于近年来计算机cache技术的快速发展,仅通过时间复杂度分析不能考虑到cache与内存之间的巨大速度差异,所以不一定能分析得到算法具体运行时的正确结果——具体情况,具体实验分析
7.1 基于比较的排序
基本概念:基于比较的排序在排序过程中在元素之间进行一系列的比较,然后再通过位置交换等操作得到有序的序列
// 以下排序的区间均是[l, r)
7.1.1 简单排序
1. 简介:简单排序其实是对一系列排序算法的总称,其共同特点是时间复杂度为O(n^2),主要包括冒泡排序,选择排序,插入排序,及对这三者的各种优化(冒泡改进,Shell排序等),但是在大规模数据排序上都被高级排序薄纱,因而除了在小数据量上作为高级排序的“结束分支”,意义并不太大。而简单排序中,其实只有插入排序在上述情境下有实际的使用价值,故只介绍此
2. 基本步骤(从小到大排序):
维护一个长为k的排序数组,k从1开始,每一次考察新加入的元素,并将其插入到原排序数组中保持从小到大,得到长为k+1的数组。插入时先用tmp保存新元素,然后逐个与前面的元素比较,若更小则将前面的元素后移一位,比较在与前一个元素比较,直到大于前一个元素,即将tmp放到移出的空位中
3. 具体实现:
template <class T>
void insertion_sort(vector<T>& nums, int l, int r){
for(int k = l + 1; k < r; k++){
T tmp = nums[k];
int count = k;
while(count > l && nums[count-1] > tmp){
nums[count] = nums[count-1];
count--;
}
nums[count] = tmp;
}
}4. 测试效果:

5. 性能分析:
最好时间复杂度:O(n)——已经有序,每一个只用和前面一个比
最坏时间复杂度:O(n^2)——倒序,每一个都需移至最前方
平均时间复杂度:O(n^2)
稳定性:由于插入过程是稳定的,所以插入排序是稳定排序
// 以下均为高级排序 ——(平均)时间复杂度为O(logn)
7.1.2 快速排序
1. 基本思路:
快速排序基于分治的思想,先选择一个基准点,将比其小的元素移至左侧,比其大的元素移至右侧,之后在分别对左右递归做相同操作,操作区间长度小于等于1时返回
2. 具体实现:
// 后面的优化代码中如果没有自定义,则使用的partition函数和swap函数仍是此处的
template <class T>
void swap(T& a, T& b){
T tmp = a;
a = b;
b = tmp;
}
//快速排序
template <class T>
int partition(vector<T>& nums, int l, int r){
//随机化以减小退化可能
int pivot_id = rand() % (r - l) + l;
swap(nums[pivot_id], nums[r-1]);
T pivot = nums[r-1];
int less = l;
for(int i = l; i < r; i++){
if(nums[i] < pivot) swap(nums[less++], nums[i]);
}
swap(nums[less], nums[r-1]);
return less;
}
template <class T>
void quick_sort(vector<T>& nums, int l, int r){
if(l >= r - 1) return; // 返回判断
int less = partition(nums, l, r);
quick_sort(nums, l, less);
quick_sort(nums, less + 1, r);
}3. 优化
I. 减少空间占用
背景:快速排序在平均情况下空间复杂度为O(logn),但在退化或半退化情况下,由于划分不均而导致的长序列一直在栈中“叠塔”,空间复杂度会接近/等于O(n),有可能使得系统栈空间不足
// 注:需要改成自己维护栈的非递归,这样才能在进行子partition时把之前占用的空间先释放掉;或者也可采用递归调用中的尾递归消除,使最长的一段始终在“底层”操作
非递归 + 短子序列优先:
// 非递归 + 短子序列优先
template <class T>
void quick_short_first1(vector<T>& nums, int l, int r){
stack<pair<int, int> > stk; // pair即保存区间端点
stk.push(make_pair(l, r));
pair<int, int> top;
int part;
while(!stk.empty()){
top = stk.top();
stk.pop();
if(top.first >= top.second - 1) continue;
part = partition(nums, top.first, top.second);
if(part - top.first > top.second - part - 1){
stk.push(make_pair(part + 1, top.second));
stk.push(make_pair(top.first, part));
}else{
stk.push(make_pair(top.first, part));
stk.push(make_pair(part + 1, top.second));
}
}
}尾递归消除 + 短子序列优先:
// 尾递归消除 + 短子序列优先
template <class T>
void quick_short_first2(vector<T>& nums, int l, int r){
while(l < r - 1){
int less = partition(nums, l, r);
if(less - l > r - less - 1){
quick_short_first2(nums, less + 1, r);
r = less;
}else{
quick_short_first2(nums, l, less);
l = less + 1;
}
}
}II. 改善划分基准
目的:避免划分不均而导致快排退化
常用手段:
a. 三数取中法:在[l, r]的首尾中三数中取出中位数作为pivot,对该区间进行划分
b. 随机化:令pivot = rand() % (r - l + 1) + l
但上述两种方法都不能保证退化情况严格不发生……好的一面是,还有高手,只是这种划分会使得快排不快了(对于另外两种高级排序而言)
III. 段子序列特殊处理
目的:利用插入排序在短序列上的时间优势进一步优化
// STL中的sort将阈值设为16
#define THRESHOLD 16
// 短子序列插入排序 + 短子序列优先
template <class T>
void quick_insertion(vector<T>& nums, int l, int r){
while(r - l > THRESHOLD){
int less = partition(nums, l, r);
if(less - l > r - less){
quick_short_first2(nums, less + 1, r);
r = less;
}else{
quick_short_first2(nums, l, less);
l = less + 1;
}
}
insertion_sort(nums, l, r);
}IV. 三路划分
目的:处理重复值较多的情况——将重复的元素全部集中在中间
// 三路划分 + 短子序列优先 + 插入排序
template <class T>
void partition_three_way(vector<T>& nums, int l, int r, int& less, int& greater){
T pivot = nums[rand() % (r - l) + l];
less = l, greater = r - 1;
for(int i = l; i <= greater; i++){
if(nums[i] < pivot) swap(nums[less++], nums[i]);
else if(nums[i] > pivot) swap(nums[greater--], nums[i--]); //这里必须将i--,否则会跳过检验刚换来的这个元素
}
}
template <class T>
void quick_three_way(vector<T>& nums, int l, int r){
int less, greater;
while(r - l > THRESHOLD){
partition_three_way(nums, l, r, less, greater);
if(less - l > r - greater - 1){
quick_short_first2(nums, greater + 1, r);
r = less;
}else{
quick_short_first2(nums, l, less);
l = greater + 1;
}
}
insertion_sort(nums, l, r);
}4. 性能分析:
最坏时间复杂度:O(n^2)——每一次pivot均选到区间内最值导致退化,不过可通过改进partition函数保证不退化,及最坏时间复杂度仍为O(nlogn)
最好时间复杂度:O(nlogn)——基于比较的排序算法时间复杂度下界
平均时间复杂度:O(nlogn)——只要每一次划分不过于倾斜即可满足(an:bn无论a, b差得多大都行,只要不是an:b——比例偏斜[可],常数偏斜[否])
空间复杂度(主要考虑的是递归所使用的系统栈空间):最坏O(n)——退化情况,最好O(logn),不过可通过非递归+短子序列优先/尾递归消除+短子序列优先使得最坏也只到O(logn)
稳定性:由于partition中交换元素是不稳定的,所以快速排序不是稳定排序
7.1.3 归并排序(优化III + 自底向上 HBD)
1.简介:归并排序也采用分治的思想。即先不断递归二分序列,最终将极限划分出的将每个长度不大于2的子序列排序后返回,每到一层便将两个已排序的二分子序列合并,最终返回时即得到已排序的序列
2. 具体实现:
//归并排序 + 插入排序
template <class T>
void merge(vector<T>& nums, int l, int mid, int r){
if(l >= r - 1 || mid > 0 && nums[mid-1] <= nums[mid]) return; // 有可能已经有序
static vector<T> tmp(nums.size()); // 静态化以节省空间(不用每次调都分配)
for(int i = l; i < r; i++){
tmp[i] = nums[i];
}
int count = l, pos1 = l, pos2 = mid;
while(count < r){
if(pos1 < mid && (pos2 >= r || tmp[pos1] <= tmp[pos2])) nums[count++] = tmp[pos1++];
else nums[count++] = tmp[pos2++];
}
}
template <class T>
void merge_sort(vector<T>& nums, int l, int r){
if(r - l <= THRESHOLD){
insertion_sort(nums, l, r);
return;
}
int mid = (r - l) / 2 + l;
//模板函数可以直接把参数加在函数名后面!
merge_sort(nums, l, mid);
merge_sort(nums, mid, r);
merge(nums, l, mid, r);
}3. 优化:
I. 对短子序列采用插入排序(已实现)
II. 合并子序列前先检查两者是否已经有序(已实现)
III. 减少拷贝次数——即拷贝一次,然后用两个数组交替做“原数组”(HBD)
//注:
I. 归并排序除自顶向下——不断拆分,达到极限再合并外;还有自底向上的方式——逐步将长为2,4,8,16……的子序列排序并合并。这样即可较为有效的减少边界情况下合并数量减少使得效率略降的情况
II. STL库中归并排序为stable_sort(),但内存空间不足时用采用inplace_merge(),使得空间复杂度变为O(1)(原本为O(n)),但时间复杂度从O(nlogn)变为O(n(logn)^2)
III. 归并排序还可以通过简单的改造来求序列中的逆序数
4. 性能分析:
时间复杂度:严格O(nlogn)——每一次将区间二分,层数O(logn),每一层合并时间复杂度O(n),故总时间复杂度O(nlogn)
空间复杂度:O(n)——需要复制一遍整个序列,但如果空间不足转成inplace_merge,空间复杂度变为O(1),但时间复杂度变为O(n(logn)^2)
稳定性:由于merge是稳定的,所以归并排序是稳定排序,也是STL中stable_sort的实现
7.1.4 堆排序
1. 简介:堆排序主要运用堆的性质,相当于动态地维护一个堆结构,不断取出堆顶排成一列以实现排序
2. 具体实现:
//堆排序(大根堆)
//只用到shift_down,因为不会再后面插入元素所以用不到shift_up
//当堆顶不是从0开始时,一定要先减出相对位置,否则直接*2+1/2并不是堆的结构
template <class T>
void shift_down(vector<T>& nums, int pos, int l, int r){
while((pos - l) * 2 + 1 + l < r){
if((pos - l) * 2 + 2 + l < r && nums[(pos-l)*2+2+l] > nums[pos] && nums[(pos-l)*2+2+l] > nums[(pos-l)*2+1+l]){
swap(nums[(pos-l)*2+2+l], nums[pos]);
pos = (pos - l) * 2 + 2 + l;
}else if(nums[(pos-l)*2+1+l] > nums[pos]){
swap(nums[(pos-l)*2+1+l], nums[pos]);
pos = (pos - l) * 2 + 1 + l;
}else break;
}
}
template <class T>
void heap_sort(vector<T>& nums, int l, int r){
//建堆(全部自顶向下)
for(int i = r - 1; i >= l; i--){
shift_down(nums, i, l, r);
}
int limit = r - 1;
while(limit > l){
swap(nums[l], nums[limit]);
shift_down(nums, l, l, limit--);
}
}也可以用STL库中的priority_queue来实现堆,只是这样的空间复杂度会从O(1)变为O(n)
//优先队列版堆排序
template <class T>
void priority_queue_sort(vector<T>& nums){
priority_queue<T, vector<T>, less<T> > heap(nums.begin(), nums.end());
int pos = nums.size() - 1;
while(!heap.empty()){
nums[pos--] = heap.top();
heap.pop();
}
}3. 性能分析
时间复杂度:O(nlogn)——建堆O(n),每一次取出堆顶用末尾元素代替后shift_down用时O(logn),取n次,故总时间复杂度为O(nlogn)
空间复杂度:O(1)——原地进行即可
稳定性:由于堆的shift_down还有顶底交换,堆排是不稳定的排序
7.1.5 内省排序
1.前言:很久以前,不满于快速排序退化的程序员们对快排采用PUA优化——“在退化之前能不能先反思一下自己,这么多年数据集一直是这样的好不好,为什么别人都不退化只有你会退化,是不是应该先思考一下自身的问题?”于是,内省排序:“啊对对对……”
2. 简介:内省排序即是STL库中sort()的实现,它是快速排序,堆排序和插入排序的结合,可谓是高级排序中的集大成者。当快速排序达到一定深度(sort中使用2*logn)时,即认为发生了退化,这是便调用堆排序处理这个子序列;如果没有被判断为退化而达到了长度下界阈值,在最后(不是当时)对已经比较有序的整个序列做优化后的插入排序
3. 具体实现:
int log(int x){
int res = 0;
while((x >>= 1) > 0) res++;
return res;
}
//内省排序
template <class T>
void intro_loop(vector<T>& nums, int l, int r, int max_depth){
while(r - l > THRESHOLD){
if(max_depth == 0){
//判定为退化,调堆排
heap_sort(nums, l, r);
return;
}
max_depth--;
int less = partition(nums, l, r);
//尾递归消除,一般保留前一段
intro_loop(nums, less + 1, r, max_depth);
r = less;
}
}
template <class T>
void unguarded_insertion_sort(vector<T>& nums, int l, int r){
for(int k = l + 1; k < r; k++){
T tmp = nums[k];
int count = k;
//与insertion_sort唯一的区别在于内部循环没有了对count的边界检测,因为前面一定保证有更小的
//泪目:工具级函数的性能优化
while(tmp < nums[count-1]){
nums[count] = nums[count-1];
count--;
}
nums[count] = tmp;
}
}
template <class T>
void final_insertion_sort(vector<T>& nums, int l, int r){
if(r - l > THRESHOLD){
insertion_sort(nums, l, l + THRESHOLD);
unguarded_insertion_sort(nums, l + THRESHOLD, r);
}else insertion_sort(nums, l, r);
}
template <class T>
void intro_sort(vector<T>& nums, int l, int r){
intro_loop(nums, l, r, log(r - l) * 2);
//最后统一在已经比较有序的序列上整体插入排序
final_insertion_sort(nums, l, r);
}3. 性能分析
时间复杂度:严格O(nlogn)——在快排退化时调堆排,O(n(每层操作)*2logn(层数)) + O(nlogn)(堆排时间)=> 总时间复杂度O(nlogn)
空间复杂度:严格O(logn)
稳定性:由于使用不稳定的快排和堆排,所以内省排序不是稳定排序
7.2 基于分配的排序
基本概念:基于分配的排序将序列中的元素划分为一个个的按顺序排放的组,除了组内部外不对元素做两两之间的比较,最后将组中元素依次取出即得到有序序列
7.2.1 计数排序
1. 基本思路:假设n个输入是0-k之间的整数,用一个长为k的数组保存每个数出现多少次,然后可以计算出每一个数前面有多少个数(包括与自己相同的),之后再将这些数依次取出放到对应位置即可(先要用一个临时序列保存一下)
2. 具体实现:
//计数排序
//k一般是外部根据实际情况给的
void counting_sort(vector<int>& nums, int k){
int len = nums.size();
vector<int> count(k, 0);
vector<int> res(len);
//记录每个数出现多少次
for(int i = 0; i < len; i++){
count[nums[i]]++;
}
//计算每个数前面有多少个数(包括自己)
//即自己排在第几个(从1开始数)
for(int i = 1; i <= k; i++){
count[i] += count[i-1];
}
//取出,放到对应的位置
//从后向前是为了保证稳定性
for(int i = len - 1; i > -1; i--){
res[--count[nums[i]]] = nums[i];
}
//复制回原数组
for(int i = 0; i < len; i++){
nums[i] = res[i];
}
}
3. 性能分析
时间复杂度:O(n+k)——只有几次遍历操作
空间复杂度:O(n+k)——一个k位的count数组,一个n位的辅助储存数组
稳定性:重拍时的从后向前遍历保证了计数排序是稳定排序,也为基数排序的正确性做了保证
7.2.2 基数排序
1.背景:元素按照关键字进行排序,关键字有d位,关键字的大小比较满足从高位开始逐位向下比(有时关键字是人为创造的)
2. 基本思路:利用计数排序的稳定性,将关键字从低到高逐步排序
3. 具体实现:
template <class T>
void my_swap(T& a, T& b){
T tmp = a;
a = b;
b = tmp;
}
//对于一般整数,直接按位划分
vector<vector<int> > division(vector<int>& nums, int d){
int n = nums.size();
vector<vector<int> > res(n, vector<int>(d));
for(int i = 0, tmp; i < n; i++){
tmp = nums[i];
for(int j = d - 1; j > -1; j--){
res[i][j] = tmp % 10;
tmp /= 10;
}
}
return res;
}
//按位再合并
void merge(vector<vector<int> >& div, vector<int>& nums, int d){
int n = nums.size();
for(int i = 0; i < n; i++){
nums[i] = 0;
for(int j = 0; j < d; j++){
nums[i] = nums[i] * 10 + div[i][j];
}
}
}
//基数排序
template <class T>
void radix_sort(vector<vector<T> >& nums, int d, int k){
int n = nums.size();
if(n < 1) return;
vector<vector<T> > aux(n, vector<T>(nums[0].size()));
vector<vector<T> > *p1 = &nums, *p2 = &aux;
vector<int> count;
for(int i = d - 1; i > -1; i--){
count = vector<int>(k, 0);
for(int j = 0; j < n; j++){
count[(*p1)[j][i]]++;
}
for(int j = 1; j < k; j++){
count[j] += count[j-1];
}
//倒着遍历,保证稳定性
for(int j = n - 1; j > -1; j--){
(*p2)[--count[(*p1)[j][i]]] = (*p1)[j];
}
my_swap(p1, p2); //直接用指针,使得只在最后复制一次即可
}
nums = (*p1);
}3. 性能分析:
时间复杂度:O(d(n+k))——对每位关键字计数排序O(n+k),一共d次,故时间复杂度为O(d(n+k)) //这里使用的是LSD,即从低位到高位进行排序(正确性由计数排序的稳定性保证);如果是MSD则是分-分-分-……-合的形式,层数可能更少,但计数排序的次数会极大地增加,时间复杂度不易分析,但实际试验中性能远差于LSD
空间复杂度:O(n+k)——LSD只用一个计数排序的空间,且不涉及递归
稳定性:由于每一次计数排序是稳定的,故总的基数排序也是稳定的
7.2.3 桶排序
1. 基本思路:构建一系列覆盖一定区间,互不相交,且按区间顺序放置的桶。将序列中元素依次通过映射函数放入对应的桶中,桶内用链表维护元素顺序,最终依次从桶中取出元素得到有序序列
2. 具体实现:
//桶排序
template <class T>
struct Node{
Node():next(NULL){}
Node(T t): val(t), next(NULL){}
T val;
Node* next;
};
template <class T>
class bucket{
public:
bucket():head(new Node<T>){}
void free(){
Node<T>* tmp;
while(head != NULL){
tmp = head->next;
delete head;
head = tmp;
}
}
bool empty(){
return head->next == NULL;
}
T top(){
return head->next->val;
}
void pop(){
Node<T>* tmp = head->next;
head->next = tmp->next;
delete tmp;
}
void push_back(T& t){
Node<T>* root = head;
Node<T>* node = new Node<T>(t);
while(root->next != NULL){
//相同的插后面,保证稳定性
if(root->next->val <= node->val) root = root->next;
else break;
}
node->next = root->next;
root->next = node;
}
void print(){
Node<T>* tmp = head->next;
while(tmp != NULL){
cout << tmp->val << " ";
tmp = tmp->next;
}
cout << "\n";
}
Node<T>* head;
};
#define BUCKET_NUM 100
//注:以下映射函数以及通的相关参数只是针对一定范围的整数,具体情况可以另设
template <class T>
void bucket_sort(vector<T>& nums, int d){
//d表示有多少位
//这里设置100个桶
bucket<T> buckets[BUCKET_NUM];
int n = nums.size();
int div = 1;
for(int i = 0; i < d - 2; i++, div *= 10);
for(int i = 0, id; i < n; i++){
id = nums[i] / div;
buckets[id].push_back(nums[i]);
}
int count = 0;
for(int i = 0; i < BUCKET_NUM; i++){
while(!buckets[i].empty()){
nums[count++] = buckets[i].top();
buckets[i].pop();
}
buckets[i].free();
}
}3. 性能分析(一般选取k=n):
最坏时间复杂度:O(n^2)——全在一个桶里便成了普通的插入排序
平均时间复杂度:O(n),且在桶的层面上易于实现并行
空间复杂度:O(n)
稳定性:由于桶内部的插入是稳定的,所以桶排序是稳定的排序
7.3 排序算法一览表

第八章 查找与索引
基本概念:
1. 查找:
查找是数据处理中最常见的一项操作,即给定一个值k,在数据结构中找出与之对应的元素或其性质,如果这样的元素不存在,则返回一个失败标志
基于不同标准,查找主要有静态vs动态,内存vs外存两种分类。与静态相比,动态查找要考虑插入删除元素所带来的时间开销;内存中主要关注关键码的比较次数,而外存中则更重视平均磁盘的读写次数
2. 索引:
在数据结构中,索引是用于快速定位数据的一种结构,它主要通过预先计算和储存某个属性的值和对应数据项之间的关系,来减少查找和访问的时间复杂度,或减少访存的开销
8.1 线性表查找
顾名思义,数据储存在线性表中的查找
8.1.1 顺序查找
1. 基本思路:无脑遍历
2. 适用情况:无序数组/没有索引结构的链表
3. 时间复杂度:O(n)
// 以下均基于线性表有序且能够随机访问
8.1.2 折半查找
1. 基本思路(从小到大排序):即二分查找,每次将查找值与查找区间的中点比较,如果查找值更大便且该区间的右半继续查找,若更小则取左半
2. 时间复杂度:O(logn)
3. 具体实现:
//二分查找,找到则返回在向量中的索引,否则返回-1
template <class T>
int binary_search(vector<T>& nums, T val){
int low = 0, high = nums.size() - 1, mid;
int search_times = 0;
while(high >= low){
search_times++;
mid = (high - low) / 2 + low;
if(nums[mid] == val) break;
else if(nums[mid] < val) low = mid + 1;
else high = mid - 1;
}
cout << "折半查找,search_times = " << search_times << endl;
if(nums[mid] != val){
mid = -1;
cout << "查询失败,该序列中不含该元素\n";
}else cout << "查询成功,元素" << val << "位于第" << mid << "位\n";
cout << endl;
return mid;
}//一般来说,如果向量中没有查找元素且不加最后的判断,返回索引的对应的值可能是恰比查找值大或其比查找值小的相邻元素,需根据情况具体处理
8.1.3 插值查找
1. 基本思路:根据查找数据取值的预估其在数据结构中的位置
2. 适用情景:已知数据的分布情况(从而用快速定位代替简单二分提高效率),一般是数据分布比较均匀;在数据不均匀或存在大量重复元素时性能不如二分查找
3. 具体实现:
//插值查找
template <class T>
int interpolation_search(vector<T>& nums, T val){
int low = 0, high = nums.size() - 1, inter;
int search_times = 0;
while(high >= low){
search_times++;
inter = (val - nums[low]) * (high - low) / (nums[high] - nums[low]) + low;
if(inter > high || inter < 0 || nums[inter] == val) break;
else if(nums[inter] < val) low = inter + 1;
else high = inter - 1;
}
cout << "插值查找,search_times = " << search_times << endl;
if(nums[inter] != val){
inter = -1;
cout << "查询失败,该序列中不含该元素\n";
}else cout << "查询成功,元素" << nums[inter] << "位于第" << inter << "位\n";
cout << endl;
return inter;
}插值 vs 折半
在一定情况下:插值的表现要优于折半
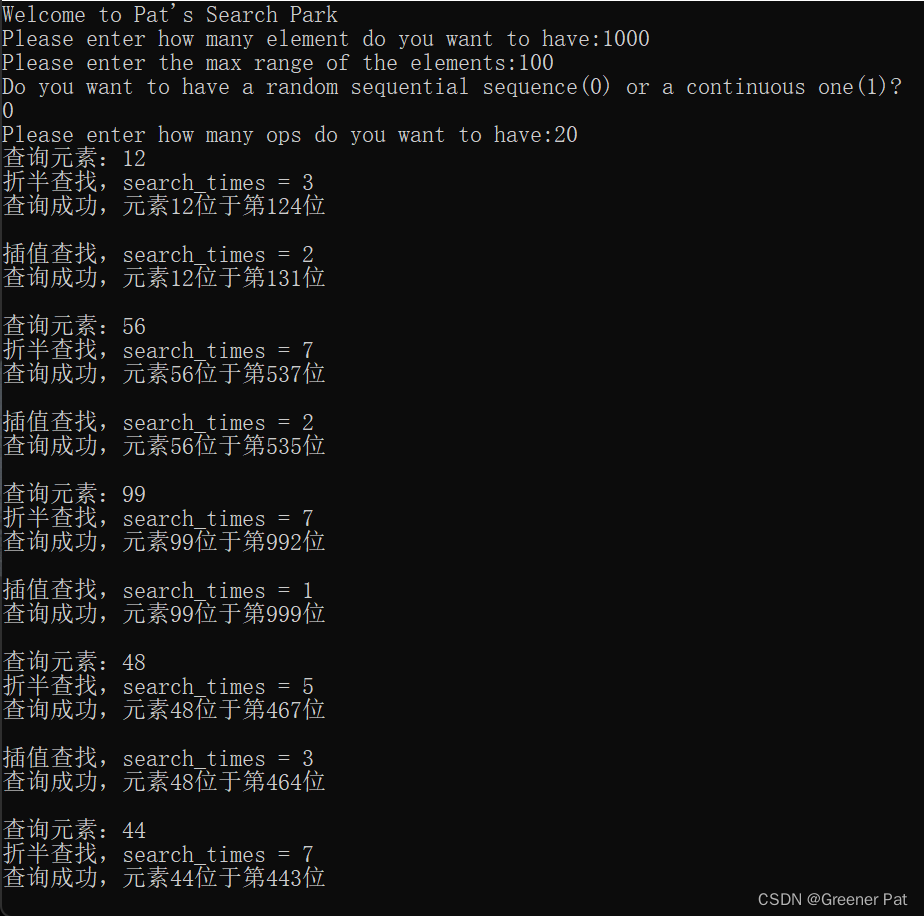
测试代码:
int main(){
int size, range, mode, ops;
vector<int> nums;
cout << "Welcome to Pat's Search Park" << endl;
cout << "Please enter how many element do you want to have:";
cin >> size;
cout << "Please enter the max range of the elements:";
cin >> range;
nums = vector<int>(size);
cout << "Do you want to have a random sequential sequence(0) or a continuous one(1)?" << endl;
cin >> mode;
srand(time(NULL));
for(int i = 0; i < size; i++){
if(mode == 1) nums[i] = i;
else nums[i] = rand() % range;
}
if(mode == 0) sort(nums.begin(), nums.end());
cout << "Please enter how many ops do you want to have:";
cin >> ops;
for(int i = 0, tmp; i < ops; i++){
cout << "查询元素:";
cin >> tmp;
binary_search(nums, tmp);
interpolation_search(nums, tmp);
}
return 0;
}8.1.4* 斐波拉切查找
1. 基本思路:为追求更好的平均性能,使用斐波拉切数计算mid,即将长为F(n)的区间划分为F(n-2),F(n-1)的两个区间进一步比较(需要一定的取整操作)
2. 性能分析:在斐波拉切查找中查找空间缩减速度近乎黄金分割的比例,所以在大部分情况下有比较好的性能
8.2 二叉查找树
基本概念:二叉查找树中将每一个数据都保存在树的一个节点中,树满足这两条的基本性质
a. 左子树中的值均小于根节点的值,右子树的值均大于根节点的值
b. 左右子树仍然是二叉查找树
8.2.1 动态二叉查找树
1. 基本思路:即普通的二叉查找树,并提供了插入和删除的功能,插入元素会被加入成叶子节点,删除后树的结构会对应调整
2.具体实现:
To be continued……















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









