






实验原理
Pythonzipfile模块用来做zip格式编码的压缩和解压缩的,要进行相关操作,首先需要实例化一个ZipFile对象。ZipFile接受一个字符串格式压缩包名称作为它的必选参数,第二个参数为可选参数,表示打开模式,类似于文件操作,有r/w/a三种模式,分别代表读、写、添加,默认为r,即读模式。
zipfile里有两个非常重要的class,分别是ZipFile和ZipInfo,在绝大多数的情况下,我们只需要使用这两个class就可以了。ZipFile是主要的类,用来创建和读取zip文件而ZipInfo是存储的zip文件的每个文件的信息的。
实验步骤
创建一个/root/python/zip的文件夹
创建一个压缩包
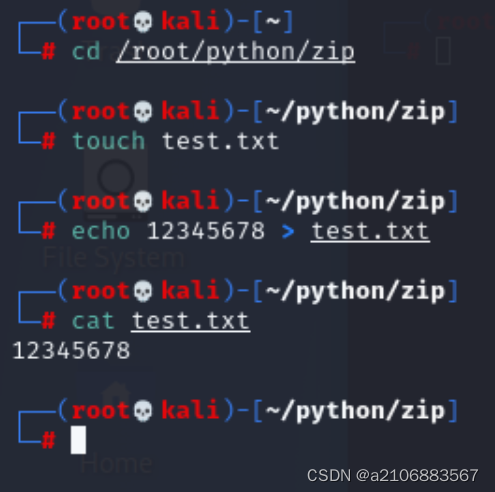
打开终端切换到/root/python/zip文件夹下
输入touch test.txt创建test.txt文件
echo12345678>test.txt向其中输入些内容输入
(echo命令:如果文件不存在,它将创建一个新文件并写入内容;如果文件已存在,它将覆盖原有内容。)
再使用cat test.txt查看一下
然后使用zip命令将test.txt文件压缩成一个zip文件,并为其设置名密码为abc123。命令为zip--passwordabc123test.ziptest.txt,将其压缩为test.zip。

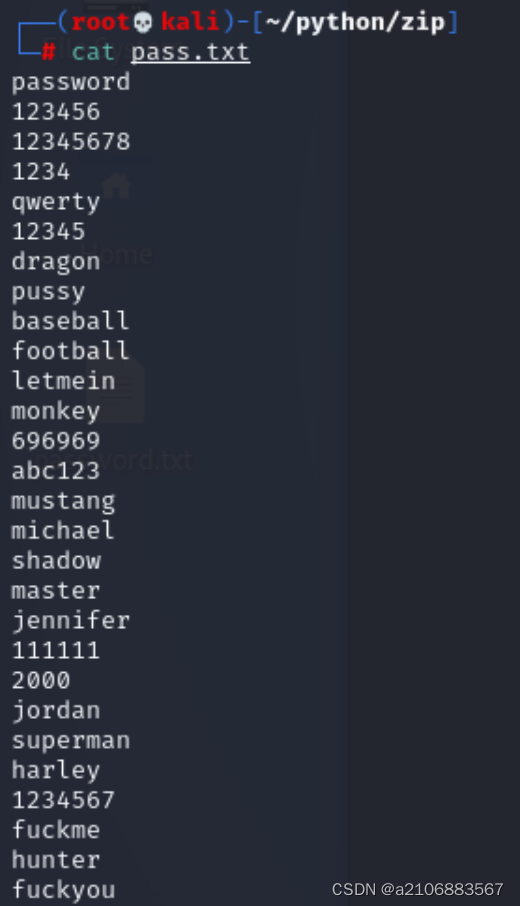
添加完压缩文件后,将原始的test.txt文件删除掉(可以使用命令rm test.txt),防止后面解压正确时产生冲突。准备密码字典文件pass.txt,在python脚本目录下创建密码字典文件:pass.txt,可以自行往其中输入些常用密码,已经在此目录中准备了一个pass.txt文件,文件内容如下图所示
利用python函数来解压zip格式文件
需要自定义一个函数,功能是使用try-except异常处理进行密码字典pass.txt文件的异常处理,若密码错误则打印出密码错误第几次,若密码正确则打印出正确的压缩密码,最后返回password。
编写Zip文件需要从学习zipfile库的使用方法开始,首先在终端中输入python3启动python命令行。
然后输入help(''zipfile)
查看一下extractall()方法

extractall函数中需要三个参数,一个是解压文件的路径,members是要解压的文件名称,是可选的,最后一个是压缩文件的密码,如果不传入的话,密码为空。
先试验一下这个函数
首先用vim编写一个简单的解压脚本初步学习一下zipfile库的使用,其中传入正确的密码abc123。
(vim状态下如何退出
1.先按ESC键确保您处于Command模式。
2.输入“:wq”,然后回车即可保存修改并退出。
3.如果想将文件以不同的名称保存,可以使用“:w filename”命令将内容另存为新的filename。
4.若遭遇错误或无法写入文件时,可以使用“:wq!”命令来强制保存并退出。
5.若仅想保存修改但保持vim编辑器打开,可使用“:w”命令。
6.若您只是想退出vim编辑器并不保存任何更改,可以输入“:q!”命令并回车。)
写入下面代码
import zipfile
zfile=zipfile.ZipFile(r"test,zip")
try:
zfile.extractall(pwd=bytes( "abc123,"utf8"))
except Exception as e:
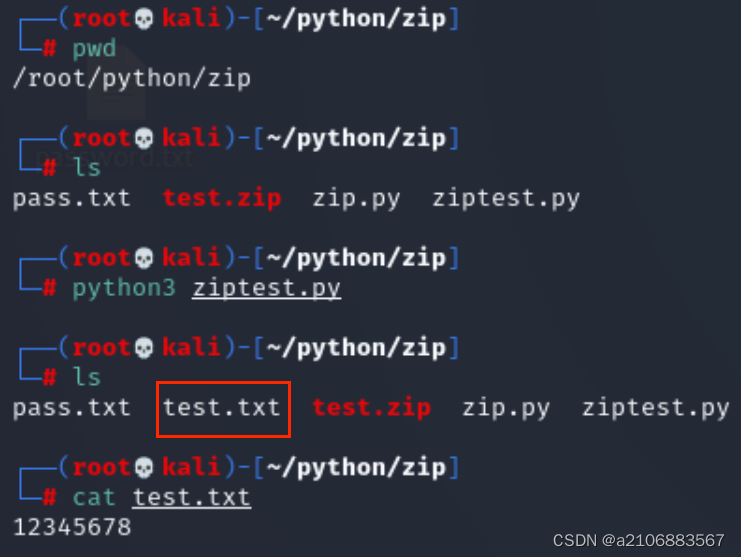
print(e)写完保存以后首先pwd查看路径
然后ls查看当前文件夹下的文件,可以看到没有test.txt
运行脚本后再次使用ls命令就可以看到了test.txt这个文件
将脚本中的密码修改为错误的试一下
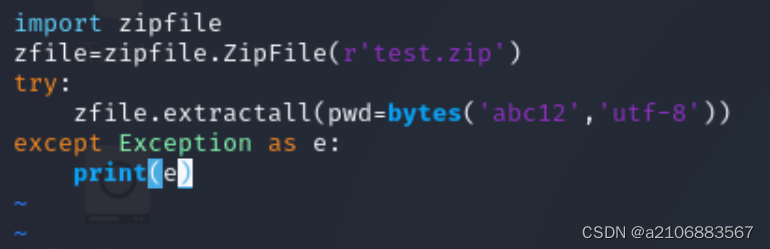
再次运行脚本就可以看见打印信息错误,提示密码错误
开始写函数脚本
结合上面例子,可以利用因口令不正确而抛出的异常来测试字典中是否有Zip文件的口令,遍历字典中的每个单词,如果extractall()函数执行未出错则将正确的口令打印出来,如果抛出口令出错的异常则忽略这个异常并尝试下一个口令。
现在设置下面两个函数:
第一个函数取名main()函数,第一个功能是使用zipfile模块对all.zip文件进行初始化,打开pass.txt文件,再使用for循环对pass.txt进行按行读取,每一行是一个密码,再使用多线程调用extractfile函数,参数为file和password。main()函数代码如下
def main():
zfile=zipfile.ZipFile(r'test.zip')
passfile=open(r'pass.txt')
for line in passfile.readlines():
Password=line.strip('\n')
t=threading.Thread(target=extractfile,args=(zfile,Password))
t.start()
t.join()第二个函数取名extractfile函数。使用try-except异常处理,若密码错误则打印出密码错误第几次,若密码正确则打印出正确的压缩密码并退出,最后返回password,extractfile函数代码如下
def extractfile(zfile,password):
try:
zfile.extractall(pwd=bytes(password,"utf8"))
print("文件解压密码为:",password)
exit(0)
except:
global i
i=i+1
print("密码错误第%s次"%i)最后的脚本如下
import zipfile
import threading
global i
i=0
def extractfile(zfile,password):
try:
zfile.extractall(pwd=bytes(password,"utf8"))
print("文件解压密码为:",password)
exit(0)
except:
global i
i=i+1
print("密码错误第%s次"%i)
def main():
zfile=zipfile.ZipFile(r'test.zip')
passfile=open(r'pass.txt')
for line in passfile.readlines():
Password=line.strip('\n')
t=threading.Thread(target=extractfile,args=(zfile,Password))
t.start()
t.join()#在多线程中,join()方法用于等待当前线程执行完毕后再继续执行其他线程。
它通常与start()方法一起使用,以确保主线程在所有子线程执行完毕后才结束。
if __name__ == '__main__':
main()解析:
- 导入zipfile和threading模块。
- 定义全局变量i,初始值为0。
- 定义extractfile函数,接收两个参数:zfile(压缩文件对象)和password(密码字符串)。
- 在try语句中,尝试使用给定的密码解压压缩文件。如果成功,打印解压密码并退出程序;如果失败,捕获异常并将i加1,打印错误次数。
- 定义main函数,用于执行以下操作: a. 打开名为"test.zip"的压缩文件。 b. 打开名为"pass.txt"的文件,逐行读取其中的密码。 c. 对于每个密码,创建一个新的线程,将压缩文件对象和密码作为参数传递给extractfile函数。 d. 启动线程并等待其完成。
- 如果当前脚本作为主程序运行,调用main函数。
)
运行该脚本
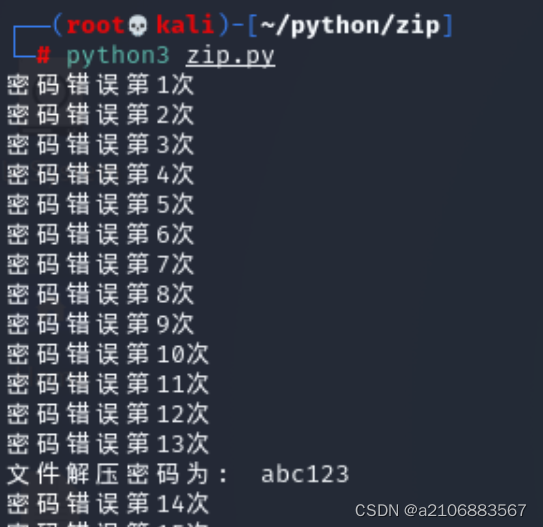















 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









