






目录
一、引言
在数据科学项目中,数据的质量直接影响到最终模型的性能。因此,数据质量与清洗以及特征工程成为了数据科学家们不可忽视的重要环节。本文将介绍数据质量的重要性、数据清洗的步骤以及特征工程的方法,并提供一些Python代码示例,帮助读者更好地理解和处理实际数据问题。
二、数据质量的重要性
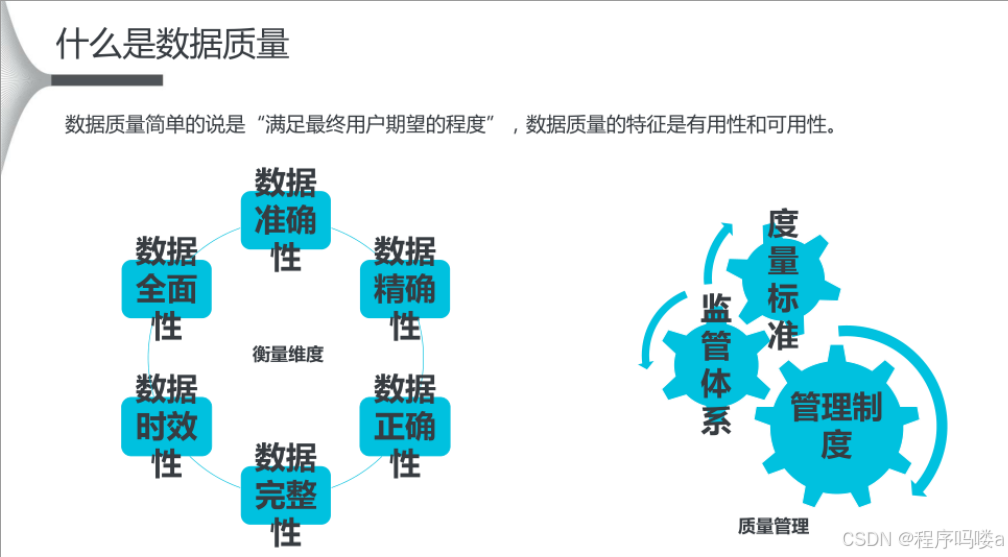
数据质量是指数据的一致性、准确性、完整性、及时性和可靠性。高质量的数据对于构建准确可靠的预测模型至关重要。低质量的数据可能导致以下问题:
- 不准确的预测:如果数据包含错误或缺失值,则模型的预测结果可能不准确。
- 偏差:数据偏差可能导致模型在某些群体上的表现不佳。
- 过度拟合:低质量的数据可能导致模型在训练集上表现良好但在新数据上表现较差。
因此,在开始建模之前,进行数据清洗和特征工程是非常必要的。
三、数据清洗
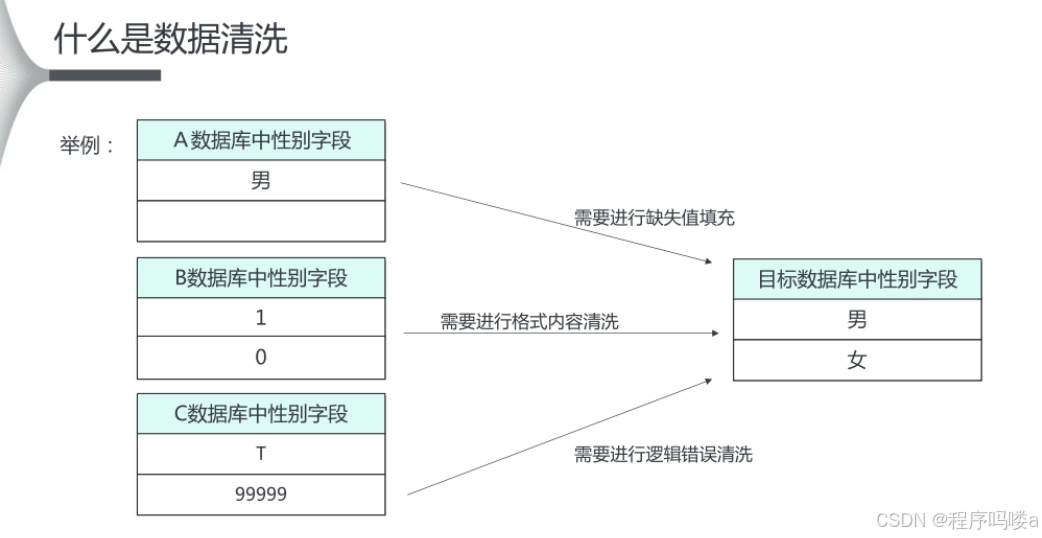
数据清洗是数据预处理的一个关键步骤,旨在识别并修正数据集中的错误或不一致的地方。以下是数据清洗的一些常见步骤及代码示例:
1. 处理缺失值
数据集中可能存在缺失值,这些值可能是由于记录错误、设备故障或人为因素造成的。
示例代码:
import pandas as pd
# 创建一个带有缺失值的数据框
data = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [None, 5, 6, 7],
'C': [8, 9, 10, 11]
})
print("Original Data:\n", data)
# 方法一:删除含有缺失值的行
data_cleaned_dropna = data.dropna()
print("\nData after dropping rows with missing values:\n", data_cleaned_dropna)
# 方法二:填充缺失值
data_cleaned_fillna = data.fillna(data.mean())
print("\nData after filling missing values with mean:\n", data_cleaned_fillna)2. 异常值检测
异常值是指与其他观测值相比显著不同的观测值。这些值可能是由于测量误差或数据录入错误造成的。
示例代码:
import numpy as np
def detect_outliers_iqr(df):
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
return ~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)
# 应用异常值检测
outliers_removed = data[~detect_outliers_iqr(data)]
print("\nData without outliers:\n", outliers_removed)3. 重复记录
重复记录会导致模型学习到错误的模式。
示例代码:
# 删除重复记录
data_unique = data.drop_duplicates()
print("\nUnique records:\n", data_unique)4. 数据类型转换
确保数据类型的正确性也很重要。
示例代码:
# 将字符串类型的日期转换为datetime格式
data['A'] = pd.to_datetime(data['A'], errors='coerce')
print("\nData after converting string dates to datetime format:\n", data)四、特征工程

特征工程是从原始数据中提取有意义的信息,以便机器学习模型能够更好地理解数据。有效的特征工程可以显著提高模型的性能。以下是特征工程的一些步骤及代码示例:
1. 特征选择
特征选择是为了挑选出最有影响力的特征。
示例代码:
from sklearn.feature_selection import SelectKBest, f_regression
# 选择最好的特征
selector = SelectKBest(score_func=f_regression, k=2)
selected_features = selector.fit_transform(data, target_variable)
print("\nSelected features:\n", selected_features)2. 特征构造
特征构造是通过组合现有特征或创建新特征来增强模型表现。
示例代码:
# 创建新的特征
data['A_times_B'] = data['A'] * data['B']
print("\nData with new feature A_times_B:\n", data)3. 特征编码
对于类别特征,需要将其转换为数值形式以便模型可以处理。
示例代码:
from sklearn.preprocessing import OneHotEncoder
# 对类别特征进行独热编码
encoder = OneHotEncoder()
encoded_features = encoder.fit_transform(data[['category']]).toarray()
print("\nEncoded categorical features:\n", encoded_features)4. 特征缩放
特征缩放是为了确保所有特征在相同尺度上。
示例代码:
from sklearn.preprocessing import StandardScaler
# 对数值特征进行标准化
scaler = StandardScaler()
scaled_features = scaler.fit_transform(data[['numeric_feature']])
print("\nScaled numeric features:\n", scaled_features)5.高级特征工程技术
降维技术
降维技术如主成分分析(PCA)、t-SNE或Autoencoders可以帮助减少特征的数量,同时保留最重要的信息。
时序特征
对于涉及时间序列的数据,可以构造基于时间窗口的特征,如滑动平均、累积和等。
交叉验证
在特征工程中,使用交叉验证来评估特征的有效性,可以防止过拟合并提高模型的泛化能力。
高级编码技术
除了独热编码和标签编码,还可以使用目标编码、权重编码(WOE)或特征哈希(Feature Hashing)等技术来处理类别特征。
五、结论
在本文中,我们探讨了数据质量与清洗以及特征工程在数据科学中的重要性,并通过具体的Python代码示例展示了如何有效地进行数据清洗和特征工程。通过数据清洗,我们能够识别并修正数据集中的错误或不一致之处,提高数据的质量;而特征工程则帮助我们从原始数据中提取出更有意义的信息,使机器学习模型能够更好地理解和预测目标变量。
具体而言,我们学习了如何处理缺失值、检测和移除异常值、去重、转换数据类型、选择和构造特征、编码类别变量以及缩放数值特征。每一步都是构建可靠模型不可或缺的基础工作。正确实施这些步骤,可以显著提升模型的性能,并且有助于避免过拟合、偏差等问题。

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









