







目录
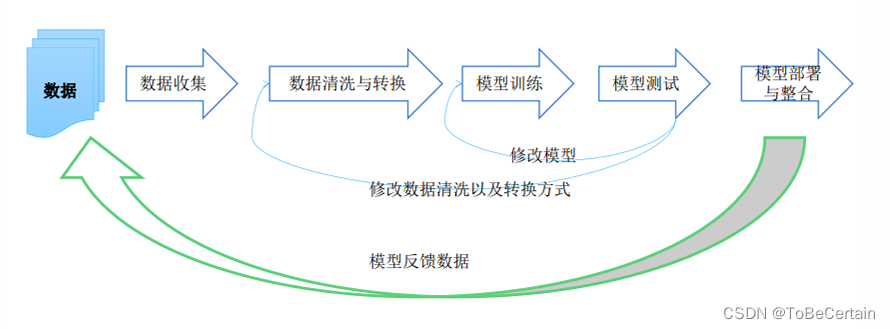
在机器学习开发过程中,对数据的处理是非常重要的:

为什么需要特征工程?
数据和特征决定了机器学习的上限
模型和算法只是逼近这个上限
什么是特征工程?
使得特征能在机器学习算法上发挥更好作用的过程
特征工程会直接影响机器的学习效果
也可以说:所有一切为了让模型效果变的更好的数据处理方式,都可以认为属于特征工程这个范畴中的操作
一. 数据清洗
在数据预处理过程主要考虑两个方面:
选择数据处理工具:关系型数据库或者Python
查看数据的元数据以及数据特征:
1. 查看元数据,包括字段解释、数据来源等一切可以描述数据的信息
2. 抽取一部分数据,通过人工查看的方式,对数据本身做一个比较直观的了解,并且初步发现一些问题,为之后的数据处理做准备
1. 数据清洗:格式内容错误数据清洗
- 时间、日期、数值、半全角等显示格式不一致
- 内容中有不该存在的字符,最常见的问题是在开头、中间和结尾处存在空格:
- 内容与该字段应有的内容不符
2. 数据清洗:逻辑错误清洗
- 数据去重
- 去除/替换不合理的值
- 去除/重构不可靠的字段值(修改矛盾的内容)
3. 数据清洗:去除不需要的数据
一般情况下,我们会尽可能多的收集数据,但并不会全部用于模型
实际上,字段属性越多,模型构建速度就会越慢;因此有时可以考虑删除不必要的字段
注意:在执行此操作时,请务必备份原始数据
4. 数据清洗:关联性验证
如果数据有多个来源,需要进行关联性验证
这通常在多数据源合并过程中使用,以验证数据之间的关联性,从而选择正确的特征属性
二. 异常值的处理
1. 删除
- 按行删除
- 按列删除
2. 填充
- 均值
- 中值
- 众数
- 常
- …
三. 归一化和标准化
- 特征的单位或者大小相差较大
- 某特征的方差相比其他的特征方差要大出几个数量级
这些因素通常容易影响(支配)目标结果,使得一些算法无法学习到其它的特征,因此我们需要用到一些方法进行无量纲化,使不同规格的数据转换到同一规格
1. 归一化
对原始数据进行变换把数据映射到(默认为[0,1])之间
x
′
=
x
−
m
i
n
m
a
x
−
m
i
n
{x}' = \frac{x-min}{max-min}
x′=max−minx−min
然而,归一化操作却存在一个明显的缺陷;最大值最小值受到异常点影响
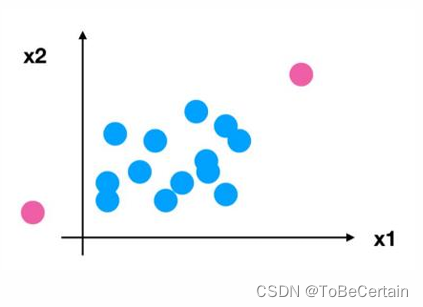
因此,为了解决这种问题,提出了标准化:将数据变换到均值为0,标准差为1的分布
2. 标准化
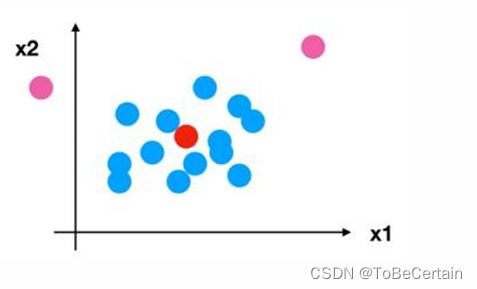
如果出现异常点, 由于具有一定数据量:
少量的异常点对于平均值的影响并不大, 从而方差改变较小
• 归一化:鲁棒性较差,只适合传统精确小数据场景。
• 标准化:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
注意:只有当原始数据为正态分布,通过标准化转换才可以得到标准正态分布
x ′ = x − m e a n σ {x}' = \frac{x-mean}{\sigma } x′=σx−mean
四. 特征提取
将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:
• 字典特征提取(特征离散化)
• 文本特征提取
• 图像特征提取(图片本身就是一个数组数据)
1. One-Hot编码
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位
状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,
并且在任意时候,其中只有一位有效。
编码位数取决于类别种类
2. 字典特征提取(特征离散化)
对字典数据进行特征值化
3. 文本特征提取
3.1 jieba分词处理
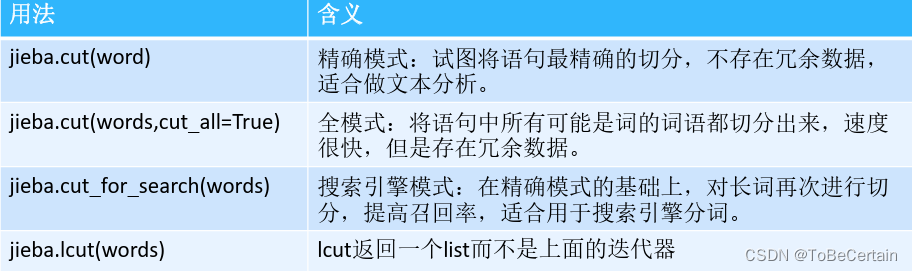
注意:前三种都返回迭代器
3.2 词袋法
将所有文章的所有出现词组成词典,并根据词典统计每篇文章中各个词出现的次数,每篇文章中各个词出现的次数可以反应这篇文章的特征
如果词典有n个词(特征),共m篇文章,则会统计出一个m*n的特征矩阵
3.3 TF-IDF
- 如果一个词在一篇文章中出现的次数越多,则这个词对这篇文章就越重
- 如果一个词在所有的文章中出现的次数越多,则表明这个词在当前文章中越不重要
- 某词在当前文档中的重要程度由TF*IDF决定
TF(Term Frequency,词频)
指某个词条在文本中出现的次数,一般会将其进行归一化处理(该词条数量/该文档中所有词条数量)
IDF(Inverse Document Frequency,逆向文档频率)
指一个词条重要性的度量
一般计算方式为:语料库中总文件数目 / 包含该词语的文件数目
得到的商取对数
词袋法和TF-IDF对比:
- 词袋法和TF-IDF都是一种文本向量化的方式
- 词袋法和TF-IDF都有一个缺点:没有考虑词的顺序和词与词之间的关系。
感谢阅读🌼
如果喜欢这篇文章,记得点赞👍和转发🔄哦!
有任何想法或问题,欢迎留言交流💬,我们下次见!
本文相关代码存放位置
【特征工程操作练习 1】
祝愉快🌟!


















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











