







 文章介绍了如何通过两种方法利用Python爬虫:一是直接在请求头中添加已登录的cookie,二是先登录并保存cookie到HTTPCookieProcessor,来模拟用户登录状态并访问登录后页面。使用了requests库和抓包工具如Fiddler或Charles作为示例。
文章介绍了如何通过两种方法利用Python爬虫:一是直接在请求头中添加已登录的cookie,二是先登录并保存cookie到HTTPCookieProcessor,来模拟用户登录状态并访问登录后页面。使用了requests库和抓包工具如Fiddler或Charles作为示例。
爬虫可以通过请求的头部信息中添加 cookie 来模拟用户登录状态,从而实现登录后才能访问的页面的爬取。
cookie使用方法1
拿到已登录的cookie 去实现已登录状态
具体步骤如下:
-
首先需要获取登录页面的 cookie,可以使用抓包工具(如 Fiddler、Charles)或浏览器的开发者工具,在登录页面登录账号后查看请求头部的 cookie 信息。
-
在爬虫代码中,使用 requests 库发送 GET 或 POST 请求时,可以通过 headers 参数设置请求头部信息,将 cookie 添加到 headers 中
小编在自己电脑上配置了禅道,登录获取cookie
http://127.0.0.1:81/zentao/my.html

代码实现:
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
url ='https://www.baidu.com/'
headers ={
'User-Agent':UserAgent().chrome,
'Cookie':'BIDUPSID=250F6FB782F1BF9E52508AF599106646; PSTM=1697427759; BAIDUID=250F6FB782F1BF9EA13030855DCC0C4A:FG=1; BD_UPN=12314753; BAIDUID_BFESS=250F6FB782F1BF9EA13030855DCC0C4A:FG=1; ZFY=sitKLA4V93qeAy9tPmkFigcXZMfT:Bm0VpslSfvwy:BAs:C; COOKIE_SESSION=653_0_8_9_3_14_1_0_8_9_2_1_5444289_0_0_0_1710724946_0_1710748354%7C9%230_3_1702273558%7C1; H_WISE_SIDS=40008_39662_40206_40211_40217_40080_40365_40351_40369_40379_40410_40415_40301_40465_40459_40469_40482; H_PS_PSSID=40080_40369_40379_40415_40301_40465_40459_40482_40317_39661_40512_40397_60025_60039_60033_60048_60060; BA_HECTOR=0g2lala10120258g0184842ktqo7ab1j09lq01t; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDUSS=H5MSGVkdmRtU04xNjZKd0RPQWhYOHplQWVtQWpNbld2TmdiOHE4VWdNNjlaU3htSUFBQUFBJCQAAAAAAAAAAAEAAACPZnYVYTI3MjMyOTg3NAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAL3YBGa92ARmS; BDUSS_BFESS=H5MSGVkdmRtU04xNjZKd0RPQWhYOHplQWVtQWpNbld2TmdiOHE4VWdNNjlaU3htSUFBQUFBJCQAAAAAAAAAAAEAAACPZnYVYTI3MjMyOTg3NAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAL3YBGa92ARmS'
}
req = Request(url,headers=headers)
opener = build_opener()
resp = opener.open(req)
print(resp.read().decode())执行结果:
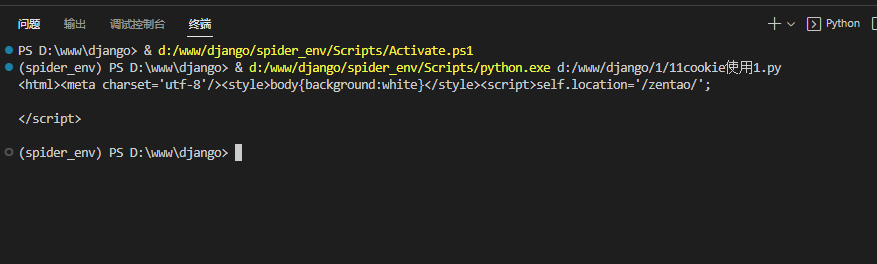
cookie使用方法2
先登录,然后把cookie保存到 HTTPCookieProcessor,然后再实现已登录状态
代码实现:
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
from urllib.parse import urlencode
from urllib.request import HTTPCookieProcessor
login_url ='http://127.0.0.1:81/zentao/user-login-L3plbnRhby8=.html'
args = {
'account': 'admin',
'password': '2671785144d04dd0d95c4b36b6a52d63',
'passwordStrength': '1',
'referer': '/zentao/',
'verifyRand': '804786735',
'keepLogin': '1',
'captcha': ''
}
headers ={
'User-Agent':UserAgent().chrome,
}
login_req = Request(login_url,headers=headers,data=urlencode(args).encode())
# 创建一个可以保存cookie的控制器对象
handler = HTTPCookieProcessor()
# 构造发送请求的对象
opener = build_opener(handler)
# 登录
login_resp = opener.open(login_req)
print(f'登录<br>')
print(login_resp.read().decode())
'''
------------------------------------------------------------------------
'''
index_url ='http://127.0.0.1:81/zentao/my.html'
index_req = Request(index_url,headers=headers)
index_resp = opener.open(index_req)
print(f'首页<br>')
print(index_resp.read().decode())
执行结果:
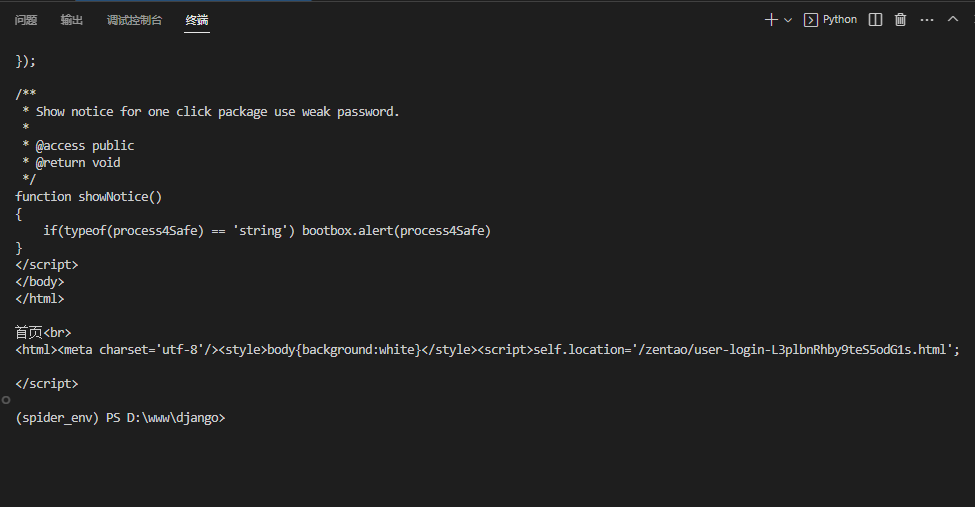
















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









