






MedicalGPT[1] 是一个开源项目,旨在辅助医疗领域大模型的训练。它具备以下功能:
-
增量预训练:通过持续学习,提升模型对医疗数据的理解。
-
有监督微调:利用标注数据对模型进行精确调整,以适应特定医疗任务。
-
RLHF:结合奖励建模和强化学习训练,优化模型的决策过程。
-
DPO:直接偏好优化,确保模型的输出更符合用户期望。
MedicalGPT 已发布的模型

shibing624/vicuna-baichuan-13b-chat 推理示例
MedicalGPT 特点
MedicalGPT 基于 ChatGPT 训练流程,实现了医疗行业语言大模型的训练:
-
阶段一(可选):增量预训练(Continue PreTraining),在海量领域文档数据上二次预训练 GPT 模型,以增强模型对特定领域数据的理解。
-
阶段二:有监督微调(Supervised Fine-tuning),构造指令微调数据集,在预训练模型基础上做指令精调,以对齐指令意图。在微调过程中,将特定领域的知识融入模型,使模型能够更好地适应特定行业的应用需求,增强其在该领域的专业性和实用性。
-
阶段三:
-
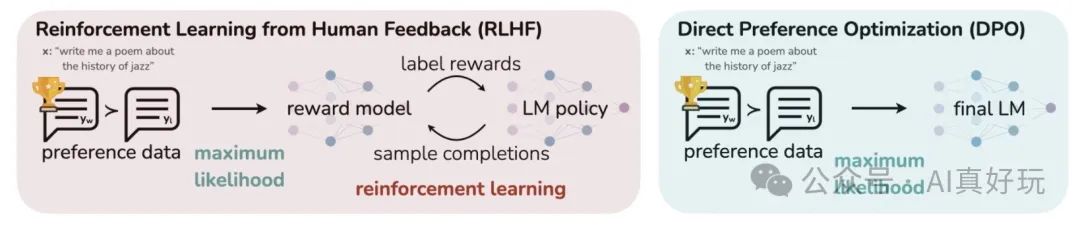
基于人类反馈对语言模型进行强化学习(Reinforcement Learning from Human Feedback):
-
奖励模型建模(Reward Model),构造人类偏好排序数据集,训练奖励模型,用来建模人类偏好。
-
强化学习(Reinforcement Learning),用奖励模型来训练 SFT 模型,SFT 模型在训练过程中,根据奖励或惩罚信号来调整其生成策略。通过不断学习和适应奖励反馈,模型学习生成更高质量的文本。最终目标是使模型生成的文本不仅质量高,而且更贴近人类的表达习惯和偏好。
-
直接偏好优化方法(Direct Preference Optimization),DPO 通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好,DPO 相较于 RLHF 更容易实现且易于训练,效果更好。
-
不需要参考模型的优化方法,通过 ORPO,LLM 可以同时学习指令遵循和满足人类偏好。
MedicalGPT 快速上手
1.克隆项目
git clone https://github.com/shibing624/MedicalGPT
2.安装依赖
cd MedicalGPT pip install -r requirements.txt --upgrade
3.启动服务
MedicalGPT 提供了一个简洁的基于 gradio 的 Web 界面,启动服务后,可通过浏览器访问,输入问题,模型会返回答案。
CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --model_type base_model_type --base_model path_to_llama_hf_dir --lora_model path_to_lora_dir
-
--model_type {base_model_type}:预训练模型类型,如llama、bloom、chatglm 等。 -
--base_model {base_model}:存放 HF 格式的 LLaMA 模型权重和配置文件的目录。 -
--lora_model {lora_model}:LoRA 文件所在目录,也可使用 HF Model Hub 模型调用名称。若 lora权重已经合并到预训练模型,则删除--lora_model参数。 -
--tokenizer_path {tokenizer_path}:存放对应 tokenizer 的目录。若不提供此参数,则其默认值与--base_model相同。 -
--template_name:模板名称,如 vicuna、alpaca 等。若不提供此参数,则其默认值是 vicuna。 -
--only_cpu: 仅使用 CPU 进行推理。 -
--resize_emb:是否调整 embedding 大小,若不调整,则使用预训练模型的 embedding 大小,默认不调整。
MedicalGPT 训练 Pipeline

-
chatpdf.py[2]:基于知识库文件的LLM问答功能(RAG)。
-
run_training_dpo_pipeline.ipynb[3]:完整 PT+SFT+DPO 全阶段串起来训练的 pipeline。
-
run_training_ppo_pipeline.ipynb[4]:完整 PT+SFT+RLHF 全阶段串起来训练的 pipeline。
支持的模型列表:

MedicalGPT 模型推理
训练完成后,运行以下脚本,即可加载训练好的模型,来验证模型生成文本的效果。
CUDA_VISIBLE_DEVICES=0 python inference.py \ --model_type base_model_type \ --base_model path_to_model_hf_dir \ --tokenizer_path path_to_model_hf_dir \ --lora_model path_to_lora \ --interactive
此外,也支持多卡推理:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 inference_multigpu_demo.py --model_type baichuan --base_model shibing624/vicuna-baichuan-13b-chat
既然大模型现在这么火热,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“雷军曾说过:站在风口,猪都能飞起来”可以说现在大模型就是当下风口,是一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









