






 本文介绍了阿里通义XR实验室的Motionshop项目,一个基于Transformer的AI工具,能进行人物检测、目标跟踪、视频分割、姿势估计和渲染,实现实时角色替换和视频合成。尽管存在排队时间长和渲染问题,但整体展示了强大的AI视频处理能力。
本文介绍了阿里通义XR实验室的Motionshop项目,一个基于Transformer的AI工具,能进行人物检测、目标跟踪、视频分割、姿势估计和渲染,实现实时角色替换和视频合成。尽管存在排队时间长和渲染问题,但整体展示了强大的AI视频处理能力。
在GitHub上发现一个挺有意思的仓库,一看是阿里通义XR实验室出品的,感觉还挺有意思,这里试玩一下。
一、仓库介绍
这里是仓库地址:Motionshop
据官方网页介绍,这个AI工具的工作原理大致如下:
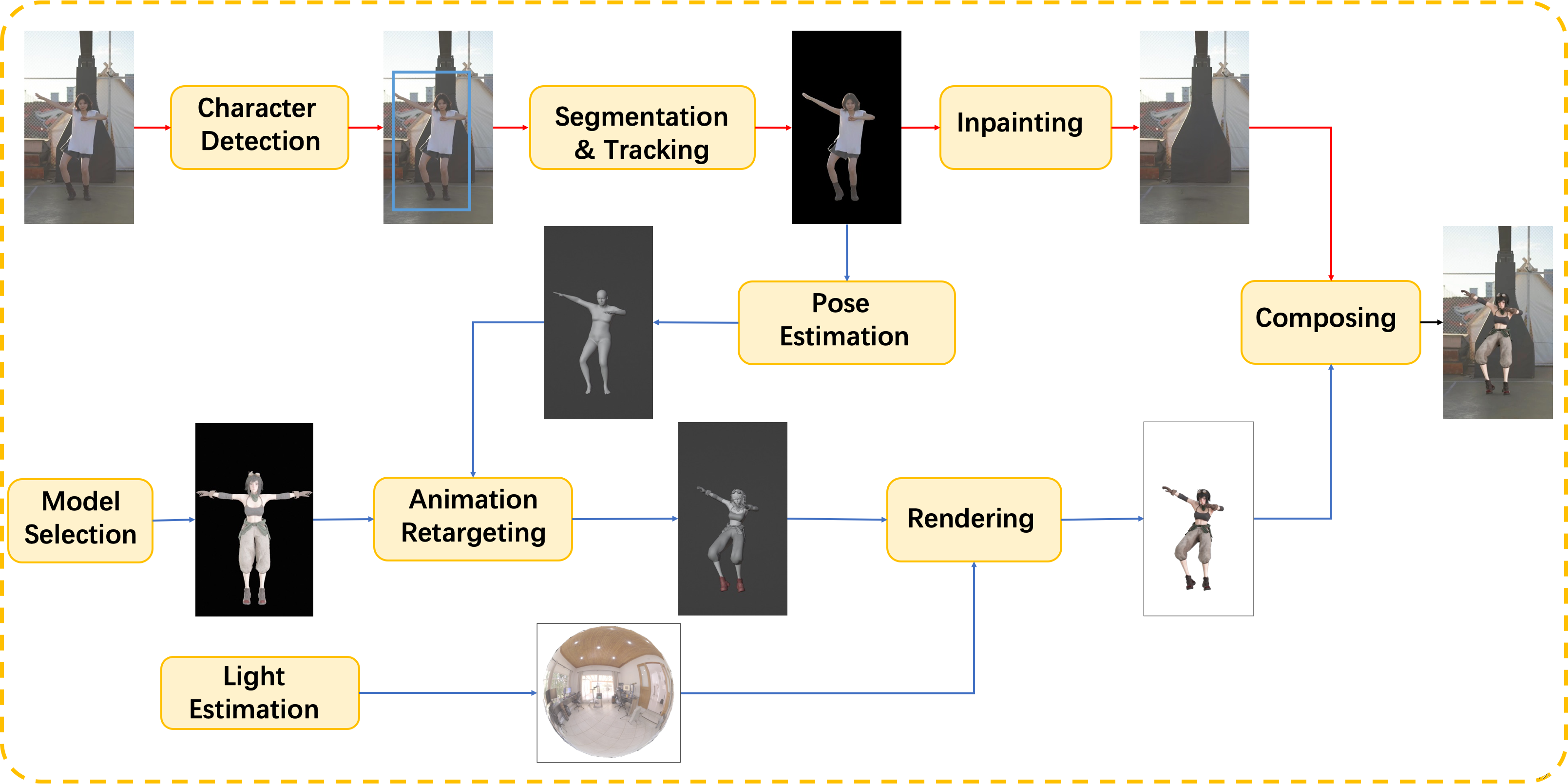
人物检测
通过将文本信息与现有的闭集检测器使用基于Transformer的框架进行紧密融合,零样本目标检测也能够表现良好。感兴趣的目标候选者通过一种开集目标检测方法进行检测,随后采用主导选择方法确定最终的目标区域。
分割与跟踪
一旦目标成功检测,像素级目标区域将通过视频对象分割跟踪方法进行跟踪,该方法由广泛使用的零样本分割方法(Segment Anything Model,SAM)初始化和精化。与直接使用SAM相比,时间对应关系被提升,以更好地处理视频分割任务。
修补
剩余的图像区域通过视频修补完成。具体而言,采用了循环流完成以恢复受损的流场,采用了在图像和特征领域上进行的双域传播,以增强全局和局部的时间一致性,此外,考虑到仅使用令牌的子集,提高了效率,减少了内存消耗,同时保持性能。
姿势估计
给定角色视频序列,应用姿势估计方法CVFFS来估计稳定的人体姿势。SMPL人体模型用于表示3D人体,这是一种广泛使用的参数化模型,用于人体形状和姿势估计。
动画重定向
估计的形状和姿势被映射到所选的3D模型上。然后,该模型可以像原始视频中的角色一样自然而流畅地播放。即使原始角色和新模型之间存在显著差异,也能取得满意的结果。
光照估计
当新的3D模型替换感兴趣的角色时,光照条件需要与原始视频保持一致。我们应用光照估计来更好地整合新的3D模型和原始场景。未来,我们还将使用光照估计进行阴影。
渲染
使用路径追踪渲染引擎TIDE来渲染新的3D模型。它与精确的材料系统相结合,辅以运动模糊、时间反锯齿和时间去噪等算法。这个引擎将逼真性与速度结合起来,为用户更有效地获取视频奠定了坚实的基础。
合成
最后,渲染的图像与原始视频合成,生成最终的视频。
(注:以上信息来自官网,由GPT翻译)
二、试玩
从Bilibili找到一小段舞蹈小视频,视频要求不超过15s。上传完成之后,模型会识别出里边的人物并框出。

底下可以选择几个角色形象,选择完成后点击生成视频,右侧会显示排队中。等待完成即可。
以下是使用可莉的结果:

以下是使用旅行者荧的结果:

Gif图太大了,图中的模糊都是因为压缩导致的,原视频是没有这个问题的。原视频:
可莉
荧
三、感想
可以看到,角色动作被完整的捕捉下来,视频的背景也被完整的保留下来。美中不足的有两点:
1、排队等待时间太长了
2、渲染本身好像有点问题,有个黑色的辫子穿模
但是不得不说,现在AI的效果真的挺厉害的。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











