







spark概念
spark是针对于大规模数据处理的统一分析引擎(注意:spark本身不负责存储)
spark是在hadoop的基础上改造的,spark基于MR算法实现分布式计算,拥有 hadoop MR所具有的有点。
但不同与MR的是,spark的job中间输出结果可以保存在内存中,从而不再需要在中间读取HDFS。
因此spark能更好的适用于属于挖掘和机器学习等需要迭代的MR算法
spark四大特性
速度快
spark的计算速度约是hadoop mr的100倍。
hadoop官网hadoop spark速度对比图

spark比MapReduce快的主要原因可参考
spark比MapReduce快的主要原因
易用性
spark支持java/scala/python/R/SQL等多种语言

通用性
spark不是一个简单的框架,而是一个生态系统,内部包好了多种模块,可以在不同的应用场景选择适合的模块
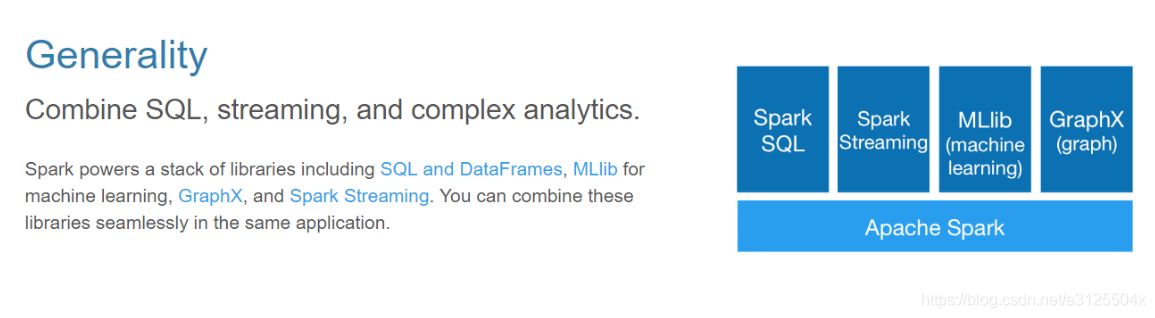
- sparkSQL
- 通过sparkSQL程序可以进行一些离线分析
- sparkStreaming
- sparkSreaming主要用适用于实时计算场景
- Mlib
- 它封装了一些机器学习的算法库
- Gragpx
- 图计算
兼容性

- Spark程序是一个计算逻辑程序,执行任务所需要的资源(内存、CPU、磁盘)等可以通过提交到多种不同资源调度平台来获得。spark程序提交到哪个资源调度平台就在哪运行。
- Spark支持3种平台
- standAlone
- spark自带的独立运行模式,整个任务的资源分配由spark集群的老大HMaster负责
- yarn
- spark支持提交到hadoop的yarn,整个任务的资源分配由yarn集群的老大ResourceManager负责
- mesos
- apache开源的一个类似于yarn的资源调度平台














 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









