







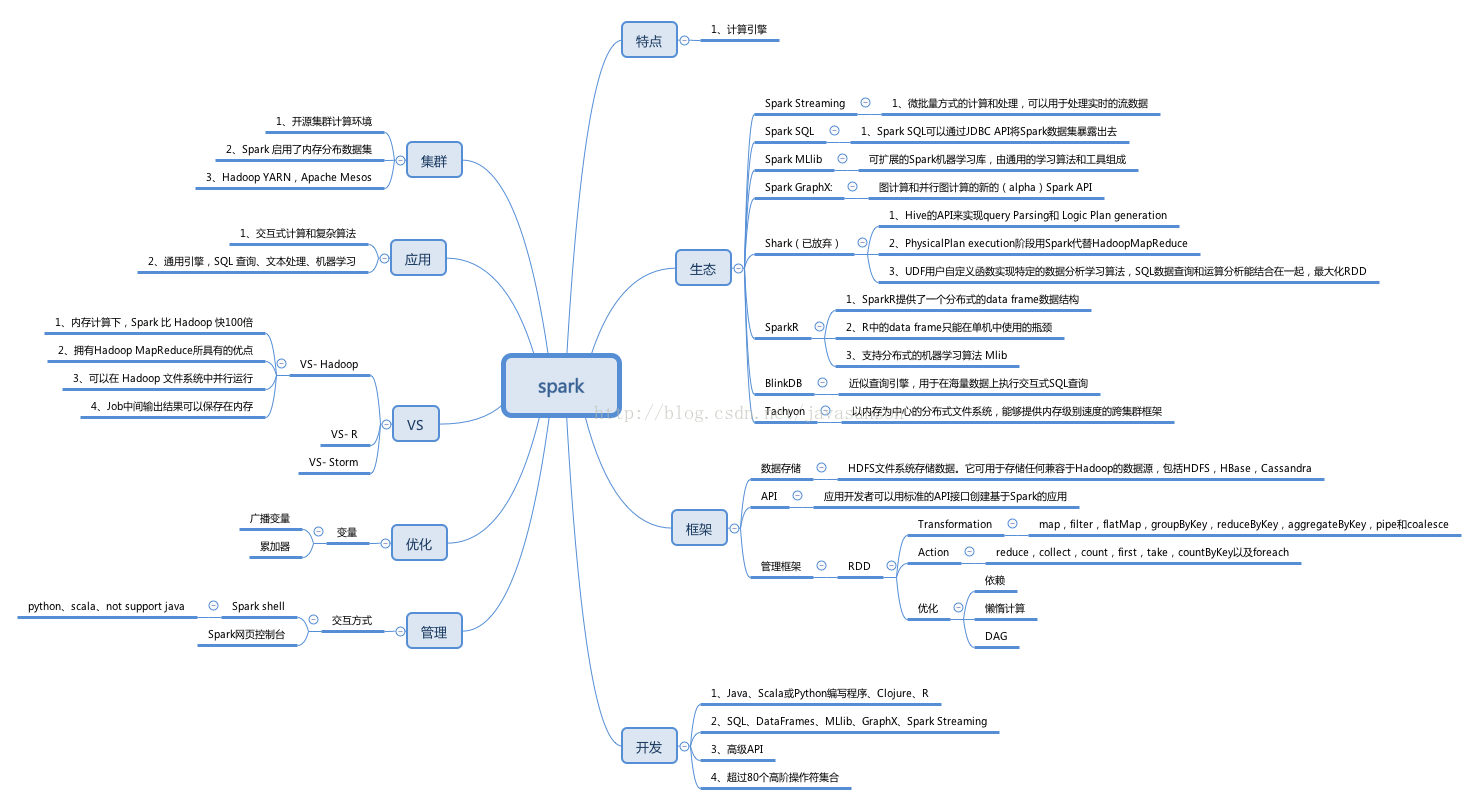
spark
特点
1、计算引擎
生态
Spark Streaming
1、微批量方式的计算和处理,可以用于处理实时的流数据
Spark SQL
1、Spark SQL可以通过JDBC API将Spark数据集暴露出去
Spark MLlib
可扩展的Spark机器学习库,由通用的学习算法和工具组成
Spark GraphX:
图计算和并行图计算的新的(alpha)Spark API
Shark(已放弃)
1、Hive的API来实现query Parsing和 Logic Plan generation
2、PhysicalPlan execution阶段用Spark代替HadoopMapReduce
3、UDF用户自定义函数实现特定的数据分析学习算法,SQL数据查询和运算分析能结合在一起,最大化RDD
SparkR
1、SparkR提供了一个分布式的data frame数据结构
2、R中的data frame只能在单机中使用的瓶颈
3、支持分布式的机器学习算法 Mlib
BlinkDB
近似查询引擎,用于在海量数据上执行交互式SQL查询
Tachyon
以内存为中心的分布式文件系统,能够提供内存级别速度的跨集群框架
框架
数据存储
HDFS文件系统存储数据。它可用于存储任何兼容于Hadoop的数据源,包括HDFS,HBase,Cassandra
API
应用开发者可以用标准的API接口创建基于Spark的应用
管理框架
RDD
Transformation:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe和coalesce
Action:reduce,collect,count,first,take,countByKey以及foreach
优化
依赖
懒惰计算
DAG
开发
1、Java、Scala或Python编写程序、Clojure、R
2、SQL、DataFrames、MLlib、GraphX、Spark Streaming
3、高级API
4、超过80个高阶操作符集合
管理
交互方式
Spark shell:python、scala、not support java
Spark网页控制台
优化
变量
广播变量
累加器
VS
VS- Hadoop
1、内存计算下,Spark 比 Hadoop 快100倍
2、拥有Hadoop MapReduce所具有的优点
3、可以在 Hadoop 文件系统中并行运行
4、Job中间输出结果可以保存在内存
VS- R
VS- Storm
应用
1、交互式计算和复杂算法
2、通用引擎,SQL 查询、文本处理、机器学习
集群
1、开源集群计算环境
2、Spark 启用了内存分布数据集
特点
1、计算引擎
生态
Spark Streaming
1、微批量方式的计算和处理,可以用于处理实时的流数据
Spark SQL
1、Spark SQL可以通过JDBC API将Spark数据集暴露出去
Spark MLlib
可扩展的Spark机器学习库,由通用的学习算法和工具组成
Spark GraphX:
图计算和并行图计算的新的(alpha)Spark API
Shark(已放弃)
1、Hive的API来实现query Parsing和 Logic Plan generation
2、PhysicalPlan execution阶段用Spark代替HadoopMapReduce
3、UDF用户自定义函数实现特定的数据分析学习算法,SQL数据查询和运算分析能结合在一起,最大化RDD
SparkR
1、SparkR提供了一个分布式的data frame数据结构
2、R中的data frame只能在单机中使用的瓶颈
3、支持分布式的机器学习算法 Mlib
BlinkDB
近似查询引擎,用于在海量数据上执行交互式SQL查询
Tachyon
以内存为中心的分布式文件系统,能够提供内存级别速度的跨集群框架
框架
数据存储
HDFS文件系统存储数据。它可用于存储任何兼容于Hadoop的数据源,包括HDFS,HBase,Cassandra
API
应用开发者可以用标准的API接口创建基于Spark的应用
管理框架
RDD
Transformation:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe和coalesce
Action:reduce,collect,count,first,take,countByKey以及foreach
优化
依赖
懒惰计算
DAG
开发
1、Java、Scala或Python编写程序、Clojure、R
2、SQL、DataFrames、MLlib、GraphX、Spark Streaming
3、高级API
4、超过80个高阶操作符集合
管理
交互方式
Spark shell:python、scala、not support java
Spark网页控制台
优化
变量
广播变量
累加器
VS
VS- Hadoop
1、内存计算下,Spark 比 Hadoop 快100倍
2、拥有Hadoop MapReduce所具有的优点
3、可以在 Hadoop 文件系统中并行运行
4、Job中间输出结果可以保存在内存
VS- R
VS- Storm
应用
1、交互式计算和复杂算法
2、通用引擎,SQL 查询、文本处理、机器学习
集群
1、开源集群计算环境
2、Spark 启用了内存分布数据集
3、Hadoop YARN,Apache Mesos















 2589
2589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









