







本文利用这里提到的方法,进行改进,从而批量获取所有股票的数据,并对股票数据进行了简单的统计。
首先使用该程序需要用到一个csv文件,记录了各个股票的名称和代码。
格式如下:
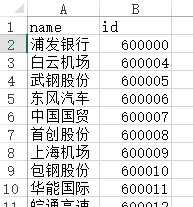
至于制作的话,还是挺简单的,百度一下股票代码,或者直接到这里,可以轻松获得所有股票代码,然后放进excel按空格分割,处理一下就可以了。这里有一份我做好的,不过只有上海的股票有兴趣可以拿去stockid.csv。
注意,如果是其他的股票的话,请参考我前面提到的博文相应修改代码,
上证代码是 ss,深证代码是 sz,港股代码是 hk
比如茅台:6000519.ss,万科 000002.sz,长江实业 0001.hk
代码中的'.ss'要改成其他。
library(quantmod)
stock=read.csv('F:/Program Files/RStudio/stockid.csv',stringsAsFactors=F)
data=list()
for(i in 1:length(stock$id)){
try(setSymbolLookup(TEMP=list(name=paste0(stock$id[i],'.ss'))))
try(getSymbols("TEMP",warnings=F))
try(data[stock$name[i]]<-list(TEMP))
}这时候的data是一个list,它存放了你的csv中所有的股票数据,可以通过比如data$浦发银行 ,来得到该股票的信息。
数据样例:
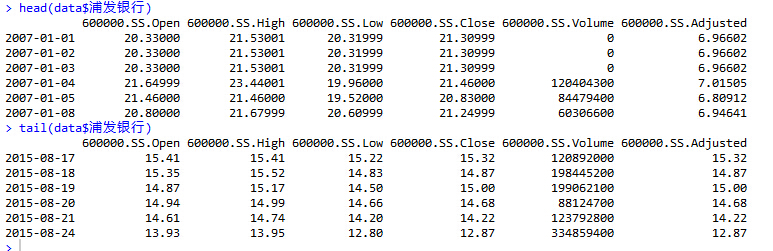
今天是2015年8月25号,所以获取的数据都是最新的历史数据。
可以看到一共有6列数据,它们的意思分别是:
- Open price 开盘价
- High price 最高价
- Low price 最低价
- Close price 收盘价
- volume 交易量
- Adjusted price 调整价格
这里稍微对股市稍微统计一下,提供一个例子给大家。将所有股票的收盘价提取出来,然后计算各个股票收盘价的最大最小均值等等。
library(plyr)
closedata<-lapply(data,function(x){
x=as.data.frame(x)
return(list(x[,4])) #提取第4列,即收盘价
})
ldply(closedata,function(x)summary(x[[1]])) #对每个股票求summary部分运行结果:
> ldply(closedata,function(x)summary(x[[1]]))
.id Min. 1st Qu. Median Mean 3rd Qu. Max.
1 浦发银行 7.11 9.610 13.890 17.760 21.80 61.59
2 白云机场 5.97 7.050 8.920 10.060 11.37 23.03
3 武钢股份 1.99 2.730 4.605 6.106 7.67 22.86
4 东风汽车 2.42 3.130 4.530 4.948 5.97 15.19
5 中国国贸 6.00 9.790 10.800 11.950 12.84 25.58
6 首创股份 3.73 5.705 6.720 8.073 8.18 23.45
7 上海机场 10.35 12.930 14.170 17.880 19.35 42.62
8 包钢股份 2.09 3.910 4.630 4.971 5.95 10.12
9 华能国际 4.06 5.640 6.710 7.508 8.11 18.73
10 皖通高速 3.36 4.240 5.215 5.792 6.49 20.05

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









