







- commitlog
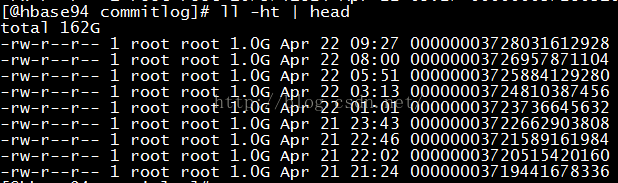
- 存储路径默认为$HOME/store/commitlog,可以在broker启动时通过storePathCommitLog设置,存储的文件如下图所示,默认大小为1G:
-
数据过来如何存储到这些文件里面呢?
消息需要加一些元数据
消息加元数据的结构如下:序号 类型 值 释义 1 int TOTALSIZE 消息+元数据总长度 2 int MAGICCODE 魔数,固定值 3 int BODYCRC 消息crc 4 int QUEUEID 队列id 5 int FLAG flag 6 long QUEUEOFFSET 队列偏移量 7 long PHYSICALOFFSET 物理偏移量 8 long SYSFLAG sysflag 9 long BORNTIMESTAMP 消息产生时间 10 long BORNHOST 消息产生的ip + port 11 long STORETIMESTAMP 消息存储时间 12 long STOREHOSTADDRESS 消息存储的ip + port 13 long RECONSUMETIMES 重新消费的次数 14 long Prepared Transaction Offset 事物相关偏移量 15 int BODY Length 消息体长度 ? body 消息体 16 byte topic length topic长度 ? topic 主题 17 short PROPERTIES LENGTH 属性长度 ? PROPERTIES 属性 那么这些数据如何存到commitlog中呢?首先需要解释一下commitlog的名字,名字长度为20位,左边补零,剩余为起始偏移量
解释一下,比如00000000000000000000代表了第一个文件,起始偏移量为0,长度为1073741824=1g当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824,长度为默认长度1g,
以此类推,第三个文件名字为00000000002147483648,起始偏移量为2147483648
消息存储的时候会顺序写入文件,当文件满了,写入下一个文件。 -
那么,如何查找消息在那个文件中呢?
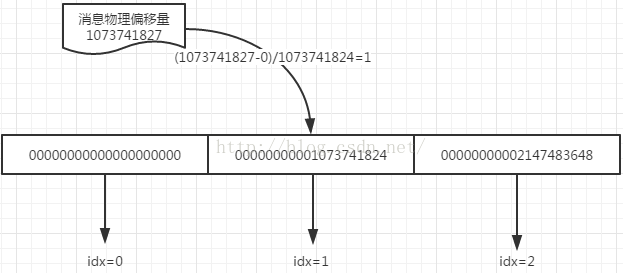
假设我们知道消息的在文件中的起始物理偏移量为1073741827,那么把这些固定大小的commitlog文件看成一个队列,那么上面可以看成有3个文件的队列
可以按如下计算就可以得知其在那个文件中:(消息的起始物理偏移量-最早的文件的起始偏移量)/文件大小,即 (1073741827-0)/1073741824=1,可得知该消息在队列中的第二个文件中:
从文件的那个位置读取呢?1073741827-1073741824=3,即第三个字节开始读取,那么现在需要确定是,消息在文件中的起始偏移量和消息大小为多少?参考consumequeue
- 存储路径默认为$HOME/store/commitlog,可以在broker启动时通过storePathCommitLog设置,存储的文件如下图所示,默认大小为1G:
-
consumequeue
-
存储路径默认为$HOME/store/consumequeue,可以在broker启动时通过storePathConsumeQueue设置,存储的文件如下图所示,默认大小为600万个字节:
其存储目录的结构为topic/queue/消息数据文件
- 这些文件中存储的数据是什么?
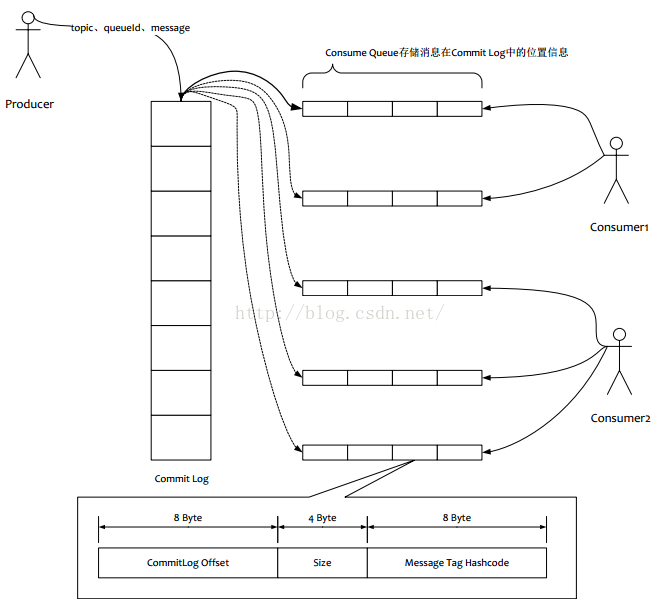
消息的位置:消息的起始物理偏移量physical offset(long 8字节)+消息大小size(int 4字节)+tagsCode(long 8字节),共20个字节,默认一个文件存储30W条数据
这些文件名的命名规则与commitlog一致,所以,这些文件也可以成一个队列 - 那么如何查找消息的位置呢?
查找消息的位置需要知道broker的地址,topic,queue,及offset,前面三个信息容易知道,这里的offset代表消息位置的逻辑偏移量,即消息位置的条数,没有消费过默认为0.
假如offset=23, 那么需要查找第23条消息的位置,那么消息位置的物理偏移量为23*20=460,定位在那个文件中与消息计算类似,(消息位置起始物理偏移量-最早的文件的起始偏移量)/文件大小
即(460-0)/6000000=0,可得知该消息位置数据在第一个文件中,从第一个文件的哪个位置开始读取呢?460-0=460,即第460个自己开始读取,读取20个自己即可获取消息的位置。
好,到这里,可以获取到消息的位置,从消息的位置可以知道小的的起始物理偏移量和消息大小,那么可以从commitLog中获取消息的数据了。
-
- 存储层的java设计
- 存储层包含了两个数据队列,即消息数据队列和消息位置数据队列,而这两个数据的队列的结构是类似的。
- 相关代码级别的分析记录到了csdn上http://blog.csdn.net/a417930422/article/details/50606732#ConsumeQueue
- 为何rocketmq不会因为队列的增加导致waitio的增高?
- 所有的消息数据都串行方式刷入一个文件,完全的顺序写,随机读,所谓的队列只是消息在commit log的位置信息
- rocketmq写文件采用何种方式?
- 最后附一张图来说明其存储情况:














09-29
 1055
1055
1055
05-04
2342
2342
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









