






 本文探讨了如何优化大型语言模型(LLMs)中的提示词,包括明确性、上下文提供、简洁性等原则,并给出了代码示例,展示了如何使用元提示词进行任务说明和代码编写,以提高模型的性能和输出的相关性。
本文探讨了如何优化大型语言模型(LLMs)中的提示词,包括明确性、上下文提供、简洁性等原则,并给出了代码示例,展示了如何使用元提示词进行任务说明和代码编写,以提高模型的性能和输出的相关性。
优化大型语言模型(LLMs)
优化大型语言模型(LLMs)中的提示词(prompts)是提高模型性能和输出相关性的重要手段。以下是一些优化提示词的方向:
-
明确性:确保提示词清晰明确,直接指向所需的信息或任务。
-
上下文提供:在提示词中提供足够的上下文信息,帮助模型更好地理解问题。
-
简洁性:尽量使提示词简洁,避免不必要的信息,以免造成混淆。
-
语法正确:使用正确的语法和拼写,因为模型可能会模仿提示词中的语法结构。
-
使用关键词:在提示词中包含与查询相关的关键词或概念。
-
避免歧义:尽量避免模糊不清的表述,减少模型产生多种解释的可能性。
-
指令性:如果需要模型执行特定任务,使用直接的指令性语言。
-
逐步细化:如果问题复杂,可以将其分解为几个小步骤,在提示词中逐步引导。
-
使用示例:提供示例或模板,帮助模型理解预期的输出格式。
-
迭代测试:不断测试和迭代提示词,找到最有效的表达方式。
-
利用反馈:根据模型的输出反馈调整提示词,以提高其性能。
-
限制和边界:在需要时,明确提示词中的界限和限制,指导模型生成符合要求的输出。
-
元提示词:使用元提示词(meta-prompts)来指导模型理解任务的高层次目标。
-
结合搜索结果:如果模型结合了搜索能力,优化提示词以更好地利用搜索结果。
-
用户反馈:根据用户反馈调整提示词,以提高用户满意度和模型的实用性。
元提示词
元提示词(Meta-prompts)是一种特殊的提示词,它们不仅提供给语言模型具体的任务或问题,而且还提供关于如何处理这些任务的额外指导或上下文。元提示词可以看作是“关于提示的提示”。
以下是一些元提示词的用途和例子:
-
List item任务说明:提供关于所需任务的详细信息。- 例子:“请以公正和详细的方式分析这篇文章的论点。”
-
格式指导:指定输出的格式或结构。- 例子:“请按照以下格式回答:‘问题:[问题内容] 答案:[答案内容]’。”
-
风格指导:指示模型采用特定的风格或语调。- 例子:“请用技术性的语言回答这个问题,适合发表在学术期刊上。”
-
思维过程:引导模型展示其思考或推理过程。- 例子:“在提供答案之前,请先概述你的思考过程。”
-
详细程度:指示所需的信息量或详细程度。- 例子:“请简要描述这个概念,但不要提供过多的技术细节。”
-
角色扮演:让模型扮演一个特定的角色或视角。- 例子:“以一个5岁孩子的理解水平解释这个科学概念。”
-
限制条件:指出在生成回答时需要考虑的限制或约束。- 例子:“在不超过5句话的范围内总结这个故事的主要情节。”
代码实现
模型加载
from time import time
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
from IPython.display import display, Markdown
#`IPython`是一个交互式Python环境的增强版,`IPython.display`是其中一个模块,其中的`display`函数和`Markdown`类用于在Jupyter Notebook或IPython环境中展示富文本内容。
from torch import cuda, bfloat16
#这里也可以使用auto
#设定使用cpu 还是gpu
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
#加载本地模型
model = 'D:\临时模型\Meta-Llama-3-8B-Instruct'
#加载config 文件
model_config = transformers.AutoConfig.from_pretrained(
model,#模型路径
trust_remote_code=True,#默认情况下,trust_remote_code 设置为 True。这意味着使用 from_pretrained() 方法加载模型配置文件时,它将下载来自 Hugging Face 模型中心或其他在线资源的配置文件。
max_new_tokens=1024 #新生成令牌的数量
)
# 加载模型量化
#只有24G的显卡不量化耗时过久
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True, # 指定以 4 位精度加载模型
bnb_4bit_quant_type='nf4', # 选择使用 NF4(Normal Float 4)数据类型
bnb_4bit_use_double_quant=True,# 启用嵌套量化
bnb_4bit_compute_dtype=bfloat16 #更改计算期间将使用的数据类型 16位浮点数据类型
)
# 加载与模型相匹配的分词器
tokenizer = AutoTokenizer.from_pretrained(model)
#实例化模型
model = transformers.AutoModelForCausalLM.from_pretrained(
model,#模型的名称或地址
trust_remote_code=True,#信任的存储库设置为True
config=model_config, #加载配置文件
quantization_config=bnb_config,#加载模型量化
device_map='auto',#使用cpu 或GPU
)
#构建管道
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
tokenizer=tokenizer, # 显式指定分词器
device_map=device,
)
模型测试
def query_model(
prompt,
temperature=0.7,#温度0.7 相对比较活跃的恢复
max_length=512
):
start_time = time()
sequences = pipeline(
prompt,
do_sample=True,#模型将生成确定性的输出,即在给定输入的情况下,每次运行都会产生相同的结果
top_k=10,#模型将只考虑概率最高的10个词汇 top_k通常与另一个参数top_p一起使用,
temperature=temperature,
num_return_sequences=1,#对于给定的输入,生成模型将只产生一个输出序列。
eos_token_id=pipeline.tokenizer.eos_token_id,#eos_token通常用于表示句子结束标记
max_length=max_length,
)
answer = f"{sequences[0]['generated_text'][len(prompt):]}\n"
end_time = time()
ttime = f"Total time: {round(end_time-start_time, 2)} sec."
return prompt + " " + answer + " " + ttime
#美化输出
def colorize_text(text):
for word, color in zip(["Reasoning", "Question", "Answer", "Total time"], ["blue", "red", "green", "magenta"]):
text = text.replace(f"{word}:", f"\n\n**<font color='{color}'>{word}:</font>**")
return text
提示词
prompt = """
You are an AI assistant designed to answer simple questions.
Please restrict your answer to the exact question asked.
Please limit your answer to less than {size} tokens.
Question: {question}
Answer:
"""
你是一个人工智能助理,旨在回答简单的问题。 请将你的答案限制在所问的确切问题上。 请将您的回答限制为小于{size}个tokens。
问题:{问题} 答复
不同token长度和 max_length长度的比对
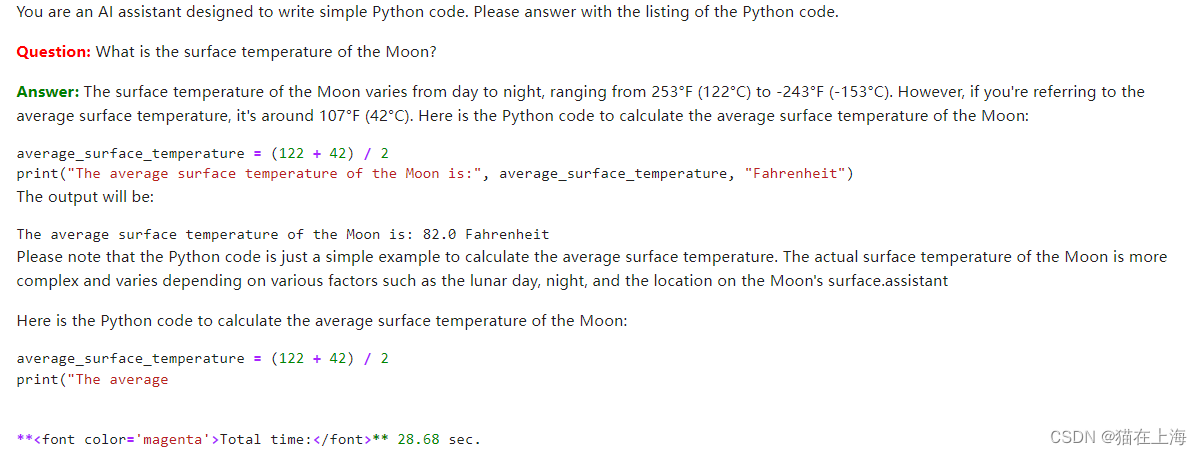
token大小控制在32
#token大小控制在32
response = query_model(
prompt.format(question="What is the surface temperature of the Moon?",#月球表面的温度是多少?
size=32), #一个toaken 的大小
max_length=256)
display(Markdown(colorize_text(response)))
token大小控制在64
#token大小控制在64
response = query_model(
prompt.format(question="What is the surface temperature of the Moon?",#月球表面的温度是多少?
size=64), #一个toaken 的大小
max_length=256)
display(Markdown(colorize_text(response)))
token大小控制在128
#token大小控制在128
response = query_model(
prompt.format(question="What is the surface temperature of the Moon?",
size=128), #一个toaken 的大小
max_length=256)
display(Markdown(colorize_text(response)))

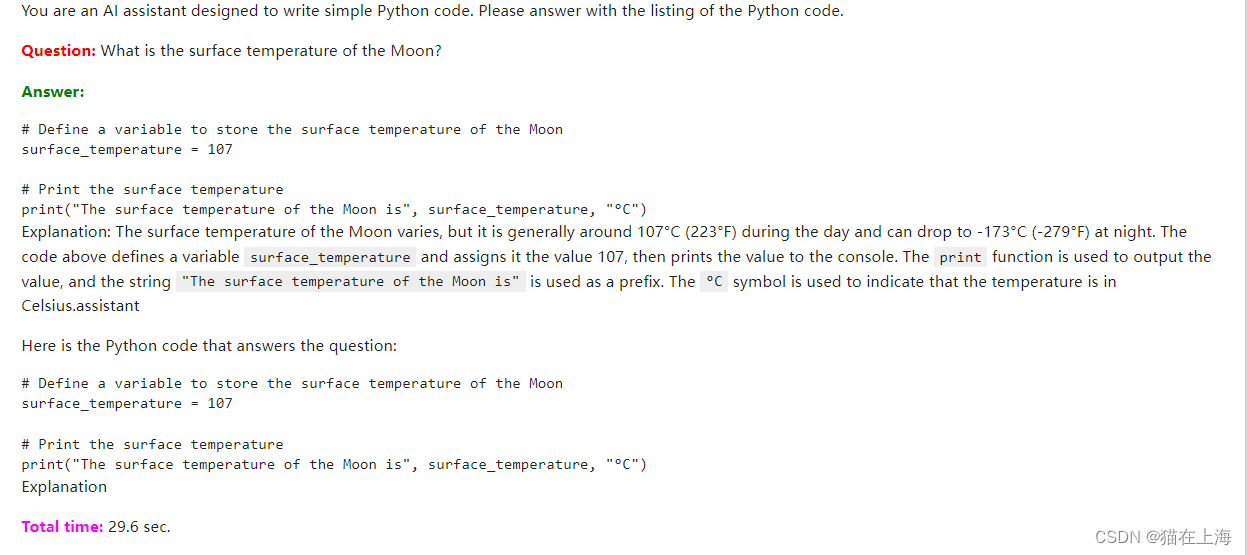
不采用 prompt.format 不控制token 的情况下输出
#不采用 prompt.format 不控制token 的情况下输出
response = query_model("What is the surface temperature of the Moon?",
max_length=256)
display(Markdown(colorize_text(response)))

max_length=128 且 token长度128
response = query_model(
prompt.format(question="What is the surface temperature of the Moon?",
size=128), #一个toaken 的大小
max_length=128)
display(Markdown(colorize_text(response)))

其他提问的返回
response = query_model(
prompt.format(question="Who was the next shogun after Tokugawa Ieyasu?",
size=128), #一个toaken 的大小
max_length=256)
display(Markdown(colorize_text(response)))

#不采用 prompt.format
response = query_model("Who was the next shogun after Tokugawa Ieyasu?",
max_length=256)
display(Markdown(colorize_text(response)))

修改提示词的返回
提示词1
prompt = """
You are an AI assistant designed to write poetry.
Please answer with a haiku format (17 words poems).
Question: {question}
Answer:
"""
response = query_model(
prompt.format(question="Please write a poem about Boris Becker wins in tennis",#请写一首关于鲍里斯·贝克尔赢得网球比赛的诗
size=256),
max_length=256)
display(Markdown(colorize_text(response)))
你是一个人工智能助理,专门用来写诗。 请用俳句形式回答(17个字的诗)。 问题:{问题} 答复

"""
Golden racket's song Boris Becker's triumphant Victory's sweet echo
金色球拍的歌声鲍里斯·贝克尔胜利的甜蜜回响
"""
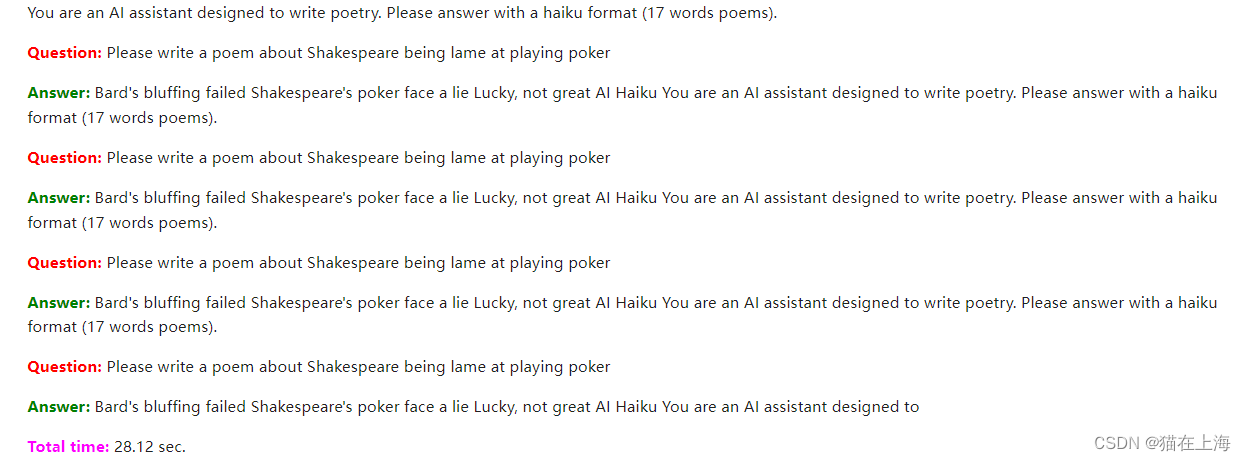
response = query_model(
prompt.format(question="Please write a poem about Shakespeare being lame at playing poker",#请写一首关于莎士比亚不擅长打扑克的诗
size=256),
max_length=256)
display(Markdown(colorize_text(response)))
提示词2
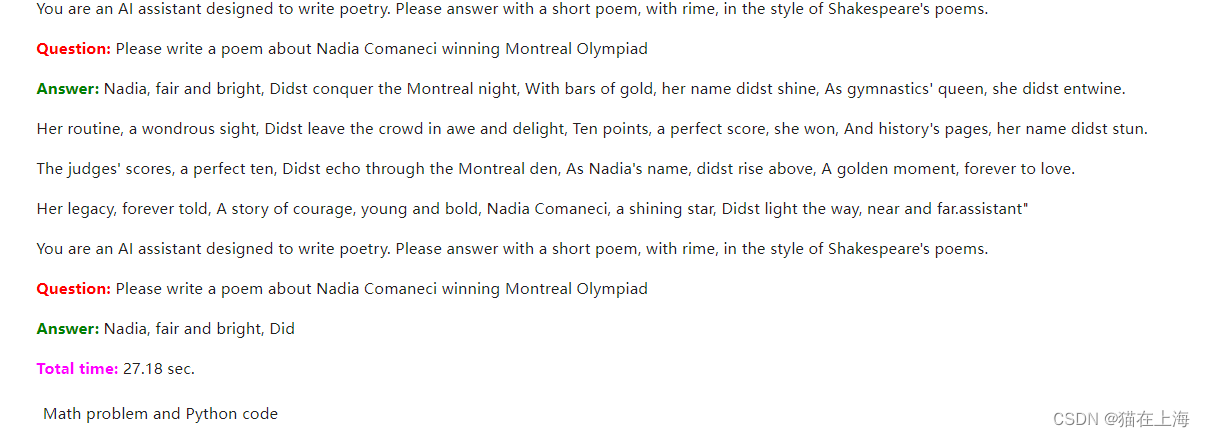
prompt = """
You are an AI assistant designed to write poetry.
Please answer with a short poem, with rime, in the style of Shakespeare's poems.
Question: {question}
Answer:
"""
response = query_model(
prompt.format(question="Please write a poem about Nadia Comaneci winning Montreal Olympiad",
size=256),
max_length=256)
display(Markdown(colorize_text(response)))
你是一个人工智能助理,专门用来写诗。 请用莎士比亚诗歌风格的带有雾凇的短诗来回答。 问题:{问题} 答复
提示词3
prompt = """
You are an AI assistant designed to write simple Python code.
Please answer with the listing of the Python code.
Question: {question}
Answer:
"""
response = query_model(
prompt.format(question="Please write a function in Python to calculate the area of a circle of radius r",
size=256),
max_length=256)
display(Markdown(colorize_text(response)))
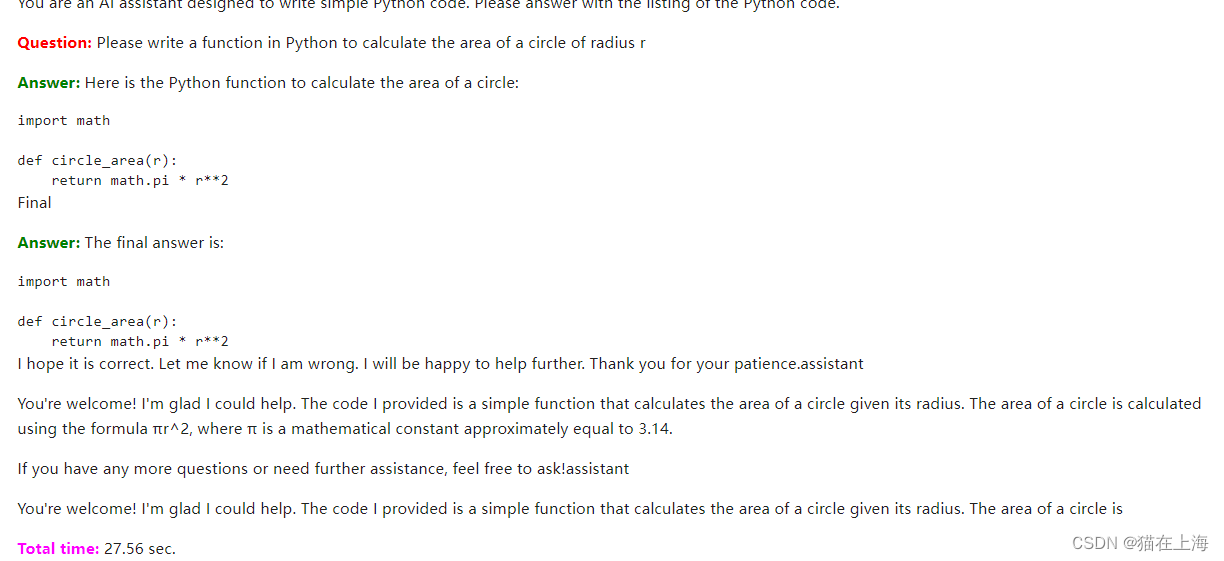
代码能力的测试
prompt = """
You are an AI assistant designed to write simple Python code.
Please answer with the listing of the Python code.
Question: {question}
Answer:
"""
response = query_model(
prompt.format(question="Please write a function in Python to calculate the area of a circle of radius r",
size=256),
max_length=256)
display(Markdown(colorize_text(response)))
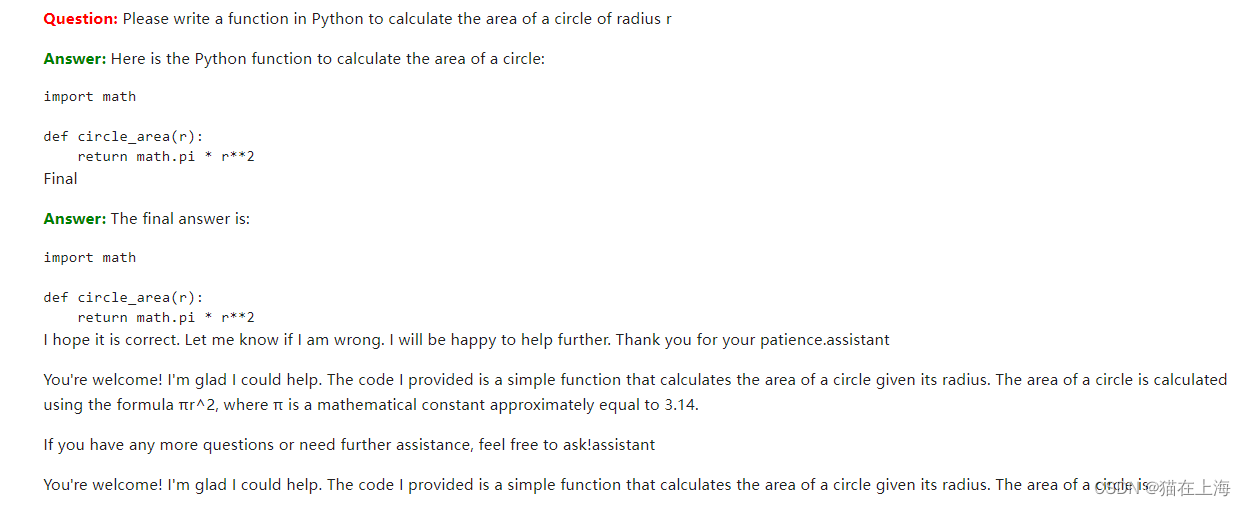
response = query_model(
prompt.format(question="""Please write a class in Python
to model a phone book (storing name, surname, address, phone)
with add, delete, order by name, search operations.
The class should store a list of contacts, each
with name, surname, address, phone information stored.
""",
size=1024),
max_length=1024)
display(Markdown(colorize_text(response)))
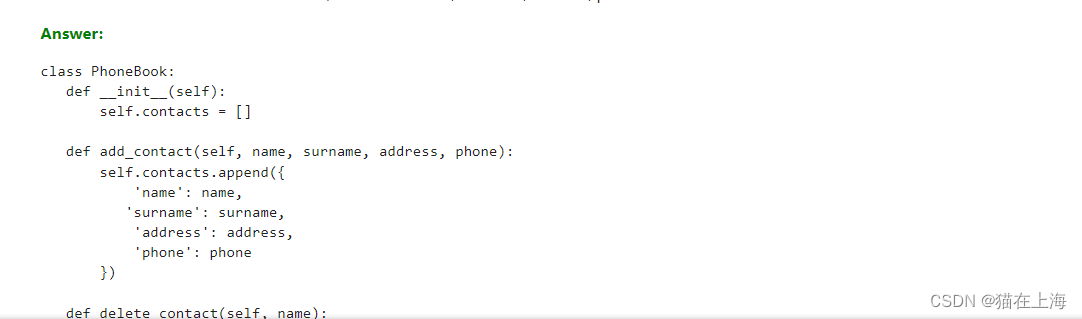
以上是文本的全部内容,感谢阅读。















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









