









题目描述:
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
输入:
输入可能包含多个测试样例,对于每个测试案例,
输入的第一行为两个整数m和n(1<=m,n<=1000):代表将要输入的矩阵的行数和列数。
输入的第二行包括一个整数t(1<=t<=1000000):代表要查找的数字。
接下来的m行,每行有n个数,代表题目所给出的m行n列的矩阵(矩阵如题目描述所示,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。
输出:
对应每个测试案例,
输出”Yes”代表在二维数组中找到了数字t。
输出”No”代表在二维数组中没有找到数字t。
比如书中给的数组
1 2 8 9
2 4 9 12
4 7 10 13
6 8 11 15
方案一:
我自己的思路,如何才能找的快?一层一层遍历的话,肯定是最麻烦的。那好,通过对角线的递增沿主对角线走的话,增大最快。先考虑普通情况在考虑边缘情况。
普通情况:我们找到第一个大于关键字key的位置,arr[i,i]>key。那么k的范围可定不在arr[0...i-1,0...i-1]之间(太小了),也不在(i,i)点的右下角(更大了)。这时,要向左遍历和向上遍历。这时是很麻烦的,一看就无从下手了。其实不然,当我们拿到一个很复杂的问题的时候,最好画一下图,然后一步一步走,这样很多细节就有了,也会为我们解题打开思路。比如向左遍历的时候,我们在i行(从第0行开始计数),那么小于i-1的行已经都比key小了,我们只看第i行向左遍历就好了,如果依然比key大就继续向左,因为向下的就更大了。当不巧遍历到某一点比key小了,证明该行中没有key,那么我们向下遍历,与刚才讲的同样的理论。直到找到或者数组越界查找失败为止。对于向上向右查找同样的道理。
特殊情况:
(1)我们需要考虑二维数组是否等宽,如果不等宽,当沿主对角线(i,i)走的时候,已经到达某一行或某一列的边界,如果依然比key小,就应该向又走或者向下走。
(2)如果二维数组为空,或者传递的参数行列都不符合要求,要返回错误。
按照这个思路写出如下的代码
#include <stdio.h>
#define COL 4
#define TRUE 1
#define FALSE 0
int find_key(int arr[][COL],int row,int key);
int find_up_right(int arr[][COL],int row,int nrow,int ncol,int key);
int find_left_down(int arr[][COL],int row,int nrow,int ncol,int key);
int main(void)
{
int arr[][COL] = {
{1,2,8,9},
{2,4,9,12},
{4,7,10,13},
{6,8,11,15},
}; //数组结尾要加分号
int key;
printf("please input your key:");
while(scanf("%d",&key)){
int n = find_key(arr,4,key);
printf("n=%d\n",n);
printf("please input your key:");
}
return 0;
}
int find_key(int arr[][COL],int row,int key)
{
int i=0; //必须初始化!!!
while(i<row && i<COL && arr[i][i]<key){ //找到大于key的第一个主对角结点
++i;
}
if(arr[i][i] == key)
return TRUE;
//下面两种情况处理,当row和col不相等时,并且arr[i][i]依然小于key的情况
if(i==row){
while(i<COL && arr[row-1][i]<key){ //row<col时,向右找到第一个大于key的点
++i;
}
if(arr[row-1][i] == key)
return TRUE;
if(i == COL) //搜索到头,证明查找失败
return FALSE;
else
return find_up_right(arr,row,row-1,i,key);
}
if(i==COL){
while(i<row && arr[i][COL-1] < key)
++i;
if(arr[i][COL-1] == key)
return TRUE;
if(i==row)
return FALSE;
else
return find_left_down(arr,row,i,COL-1,key);
}
//下面处理在数组内部找到比key大的点
int n1 = find_up_right(arr,row,i,i,key);
int n2 = find_left_down(arr,row,i,i,key);
return n1||n2;
}
//由于是一个单元格一个单元格走的,当key小于arr[i][j]时,先向上查找,找到小于关键字的时候,就要向右查找,交替进行
int find_up_right(int arr[][COL],int row,int nrow,int ncol,int key)
{
int i = nrow;
int j = ncol;
/* 方法1,从《数据结构》算法6.5中获得启发,循环一趟中处理不同情况的差异,最后再下一趟循环
while(j<COL && arr[i][j]>key){
while(--i && i>=0 && arr[i][j]>key)
;
if(i<0) //要判断边界条件!!!
return FALSE;
if(arr[i][j] == key)
return TRUE;
while(++j && j<COL && arr[i][j]<key)
;
if(j==COL)
return FALSE;
if(arr[i][j] == key)
return TRUE;
}
*/
while(i>=0 && j<COL){
if(arr[i][j] > key)
--i;
else if(arr[i][j] < key)
++j;
else
return TRUE;
}
return FALSE;
}
//当key小于arr[i][j]时,先向左查找,找到小于关键字的时候,就要向下查找,交替进行
int find_left_down(int arr[][COL],int row,int nrow,int ncol,int key)
{
int i = nrow;
int j = ncol;
/*
while(i<row && arr[i][j]>key){
while(--j && j>=0 && arr[i][j]>key)
;
if(j<0)
return FALSE;
if(arr[i][j] == key)
return TRUE;
while(++i && i<row && arr[i][j]<key)
;
if(i==row)
return FALSE;
if(arr[i][j] == key)
return TRUE;
}
*/
//方法二
while (i<row && j>=0){
if(arr[i][j] > key)
--j;
else if(arr[i][j] < key)
++i;
else
return TRUE;
}
return FALSE;
}
注释:
(1)要对变量初始化!在find_key()函数中,用到i但没初始化就直接比较,引起内存越界访问。在c++中很强调这一点,在c中也应该保持这种习惯。
(2)find_up_right()和find_left_down()两个函数中用了两种方法,第一种方法比较繁琐,在遍历第一遍的时候会产生分支先向左再向下,为了到第二趟遍历入口一致,就在循环体中引入了两次循环来处理这种差异。第二种方法,是《剑指offer》上用到的方法,很简单,只是在循环中通过if...else...语句,根据不同情况,选择不同处理即可。主要原因是,while循环的入口设置的不合理。
方案二
其实在方案一中,向左向下遍历已经可以使我们得到启发:我们先比较第一行最后一个元素,如果比key大,就向左遍历,因为向下的元素肯定也比key大,这时就相当于排除了这一列。当遇到比key小的时候,就应该向下遍历。思想跟我上面用到的思想一致。
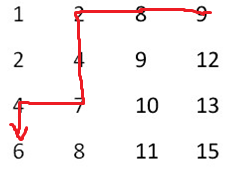
精炼的构思:1、将value值同二维数组右上角元素比较,分三种情况考虑;
2、==,则找到; <value,则‘删掉’行; >value,则‘删掉’列;
3、直到二维矩阵‘空’。
代码如下:
int find_key_book(int arr[][COL],int row,int key)
{
int i=0;
int j=COL-1;
while(i<row && j>=0){
if(arr[i][j] > key)
--j;
else if(arr[i][j] < key)
++i;
else
return TRUE;
}
return FALSE;
}代码很简洁啊!比我用的方法好多了。当碰到一个题目时应该深入研究,如果可以找到一个好方法的话,可以很方便的写出代码,并且不易出错。
方案三:
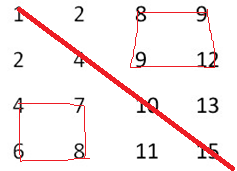
分治法,分为四个矩形,配以二分查找,如果要找的数是6介于对角线上相邻的两个数4、10,可以排除掉左上和右下的两个矩形,而递归在左下和右上的两个矩形继续找,如下图所示:
另外还有一种方法,可以看看:剑指offer面试题3
扩展题目:有序矩阵的中位数算法
给定 n×n 的实数矩阵,每行和每列都是递增的,求这 n2 个数的中位数。
使用类似Tarjan的线性中位数的方法,每次找每列中位数,然后找中位数的中位数,之后可以删除前一半列的上半部分或者后一半列的下半部分,这样可以实现复杂性 O(nlog2n) 。
但是这个问题是有 O(n) 的算法的,在Top Language Google Group的Obtuse Sword的指点下,找到了这个问题的原始论文:Generalized Selection and Ranking: Sorted Matrices。事实上这篇论文证明了更强的结论:
算法的基本思路是将矩阵依次对半划分成更小的子矩阵,然后删除不可能包含所求中位数的子矩阵。通过对每次划分后子矩阵个数的估计,发现此算法时间复杂度为 O(nlog2m/n) 。
使用同样的技巧,可以证明更更强的结论(这个算法具体过程就没细看了):
一堆 ni×mi ( ni≤mi )的矩阵,若每个矩阵的每行和每列都是递增的,则selection problem(即找第 k 大的数)的时间复杂度为 O(∑nilog2mi/ni) 。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









