






9 月 13 日,OpenAI 正式公开一系列全新 AI 大模型,传说的“草莓”终于上线,但是正式命名不叫“草莓”,而是o1。
一、为什么叫o1
为什么取名叫o1,OpenAI是这么说的:
For complex reasoning tasks this is a significant advancement and represents a new level of AI capability. Given this, we are resetting the counter back to 1 and naming this series OpenAI o1.
翻译过来就是:
对于复杂的推理任务,这是一项重大进步,代表了 AI 能力的新水平。鉴于此,我们将计数器重置回 1 并将此系列命名为 OpenAI o1。
这次OpenAI的全新AI大模型,不再延续以往的命名规范,直接取名为o1,这意味着这才是一个新的起点,也代表了目前的最高水平。
官方名称:OpenAI o1,不是GPT-o1,为什么?
因为o1跟GPT-4o的目标和技术路线不同。
-
① 4o 是不同模态的大一统, 对于模型智力水平帮助不大; 4o 做不了复杂任务, 指望图片、视频数据大幅提升智力水平不太可能, 4o 弥补的是大模型对多模态世界的感知能力, 而不是认知能力, 后者还是需要LLM文本模型
-
② o1 探索AGI还能走多远; 认知提升的核心在于复杂逻辑推理, 能力越强, 解锁复杂应用场景越多, 大模型天花板越高, 提升文本模型的逻辑推理能力是最重要的事情, 没有之一
二、有什么不同
“慢思考、强逻辑”的能力,为什么这么说呢?
看两组数据:
AIME 2024 数学竞赛中,o1 的预览版达到了 56.7% 的准确率,而正式版更是高达 83.3%。代码竞赛上,o1 的表现也极为抢眼,从 11% 的 GPT-4o 提升到 89%。
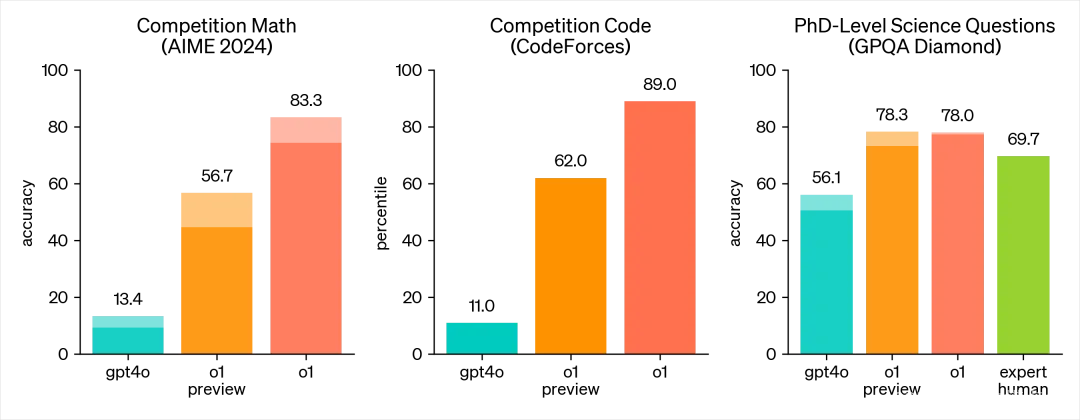
新模型在复杂推理或数学计算等方面的能力,可以说是被打通了任督二脉。
设想下,如果有人问你:
-
简单问题: 意大利首都是哪儿? 你会立即回答罗马
-
复杂问题: 帮我写个商业计划书/小说… 你会停顿片刻,不断自我反思, 思考时间越久, 结果往往越好
这个例子解释了推理的作用,将思考时间转化为更好结果的能力。
其中的一脉是“慢思考”,o1模型在回答问题之前会进行深思熟虑,这个过程可能需要额外的时间,但它能够生成一个内部的长思维链,尝试不同的策略,并识别自身的错误。
另外的一脉是“强逻辑”,o1模型在逻辑推理任务上表现出色,能够处理复杂的科学、数学和编程问题。例如,在国际数学奥林匹克(IMO)的资格考试中,o1模型的正确率高达83%,而之前的GPT-4o模型正确率为13%。
在chatgpt之前的模型中,是不擅长复杂推理的,在简单任务上时表现不错,但一旦遇到多步骤的复杂问题,或者需要更多推理和思考的场景时,模型的表现就开始下滑,而o1在推理上开始解决这个问题。
三、核心是什么
OpenAI的o1模型训练方法的核心原理是一项名为名为自我对弈强化学习(Self-play Reinforcement Learning,简称RL)的训练方法。
这种方法通过模拟环境和自我对抗来提升模型性能,模型在没有外部指导的情况下,通过不断尝试和错误来学习策略和优化决策。这就像是模型在和自己下棋,一边玩一边学,过程中不用别人教,自己尝试、出错、再试,慢慢学会怎样做决策和解决问题。
比如AlphaGo和AlphaZero,使用的就是这种方法。
o1模型系列包括o1-preview和o1-mini两个版本,其中o1-preview注重深度思考与科学推理,而o1-mini则更经济高效,适合STEM领域,尤其是数学和编码任务。
















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











