







 本文介绍了segmentation_models_pytorch库,它支持9种语义分割网络和多种编码器,包括Unet++, FPN等。此外,文章提及MMSegmentation库作为更全面的选择,但因其封装过于完善而限制了用户自定义空间。smp库的模型构建简单,只需指定模型、编码器、输入和输出通道数。模型结构包含encoder、decoder和segmentation_head,支持多种损失函数和评估指标。
本文介绍了segmentation_models_pytorch库,它支持9种语义分割网络和多种编码器,包括Unet++, FPN等。此外,文章提及MMSegmentation库作为更全面的选择,但因其封装过于完善而限制了用户自定义空间。smp库的模型构建简单,只需指定模型、编码器、输入和输出通道数。模型结构包含encoder、decoder和segmentation_head,支持多种损失函数和评估指标。
segmentation_models_pytorch(后文简称smp)是一个用于语义分割的高级模型库,支持9种语义分割网络,400多座编码器,本来对这只支持个别网络的模型库博主是不感兴趣的。但是,在查看到好几个竞赛的top方案都是使用unet++(efficientnet做编码器),博主心动了。如果想要使用更多更全的语义分割模型还是推荐使用MMSegmentation,把MMSegmentation作为语义分割模型库使用可以参考pytorch 24 把MMSegmentation的作为pytorch的语义分割模型库使用(已实现模型的训练与部署)_万里鹏程转瞬至的博客-CSDN博客_mmsegmentation 使用MMSegmentation是商汤科技推出的语义分割库套件,属于 OpenMMLab 项目的一部分,里面有很多的语义分割模型。为什么博主会有这样的骚操作想法呢?原因有二,第一点:MMSegmentation的封装太完善了,作为一个依赖于pytorch的模型库在训练上却不一样,用户的自由发挥空间很小(比如自定义loss、自定义学习率调度器、自定义数据加载器,啥都要重新学),这让博主很难接受;第二点:github上给出了的其他pytorch模型库太拉胯了,支持的模型数量有限,大多只支持2020年以前的模型,这对 https://hpg123.blog.csdn.net/article/details/124459439回到正题,接下来描述smp的使用与构造。smp的项目地址为:https://github.com/qubvel/segmentation_models.pytorch
https://hpg123.blog.csdn.net/article/details/124459439回到正题,接下来描述smp的使用与构造。smp的项目地址为:https://github.com/qubvel/segmentation_models.pytorch
安装smp:
pip install segmentation-models-pytorch
1、基本介绍
9种模型架构(包括传奇的Unet):
- Unet [paper] [docs]
- Unet++ [paper] [docs]
- MAnet [paper] [docs]
- Linknet [paper] [docs]
- FPN [paper] [docs]
- PSPNet [paper] [docs]
- PAN [paper] [docs]
- DeepLabV3 [paper] [docs]
- DeepLabV3+ [paper] [docs]
113个可用编码器(以及来自timm的400多个编码器,所有编码器都具有预先训练的权重,以更快更好地收敛):主要为以下网络的多种版本
ResNet
ResNeXt
ResNeSt
Res2Ne(X)t
RegNet(x/y)
GERNet
SE-Net
SK-ResNe(X)t
DenseNet
Inception
EfficientNet
MobileNet
DPN
VGG
训练常规的常用的损失:支持的loss如下所示(在segmentation_models_pytorch.losses中)
from .jaccard import JaccardLoss
from .dice import DiceLoss
from .focal import FocalLoss
from .lovasz import LovaszLoss
from .soft_bce import SoftBCEWithLogitsLoss
from .soft_ce import SoftCrossEntropyLoss
from .tversky import TverskyLoss
from .mcc import MCCLoss训练常规的常用的指标:在segmentation_models_pytorch.metrics中
from .functional import (
get_stats,
fbeta_score,
f1_score,
iou_score,
accuracy,
precision,
recall,
sensitivity,
specificity,
balanced_accuracy,
positive_predictive_value,
negative_predictive_value,
false_negative_rate,
false_positive_rate,
false_discovery_rate,
false_omission_rate,
positive_likelihood_ratio,
negative_likelihood_ratio,
)2、模型的构建
smp中模型的构建十分便捷,输入解码器类型,权重类型,输入通道数、输出通道数即可。
import segmentation_models_pytorch as smp
model = smp.Unet(
encoder_name="resnet34", # choose encoder, e.g. mobilenet_v2 or efficientnet-b7
encoder_weights="imagenet", # use `imagenet` pre-trained weights for encoder initialization
in_channels=1, # model input channels (1 for gray-scale images, 3 for RGB, etc.)
classes=3, # model output channels (number of classes in your dataset)
)但是有的时候,需要对网络结构进行修改,可以指定更为详细的参数(如网络的深度,是否需要辅助头【这里默认的辅助头都是分类头】)。需要注意的是,在unet网络中编码器深度与解码器的stage个数必须相同(stage中的filter num可以按情况修改)
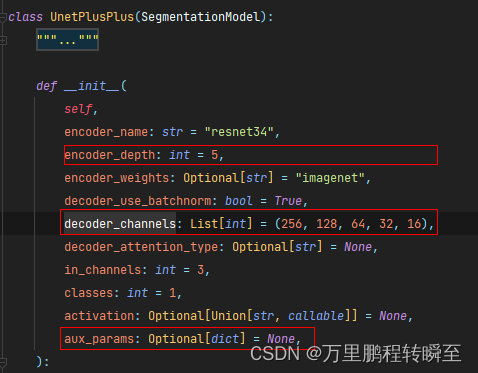
3、模型的具体结构
在smp中,所有的模型都具备以下结构(encoder,decoder和segmentation_head)。encoder是通过传参控制(encoder输出的也不是一个单纯的feature map,而是包含了各阶段下的feature map,是一个list),decoder由具体的model类确定(所有smp模型decoder的输出都是一个tensor,不存在list【如pspnet的多尺度特征,在decoder输出前用conv进行了融合】),segmentation_head由传入的classes确定(只是一个简单的conv层)
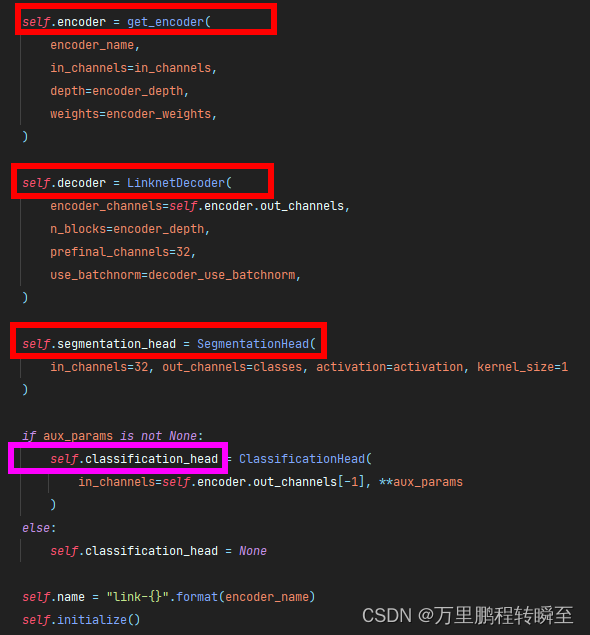
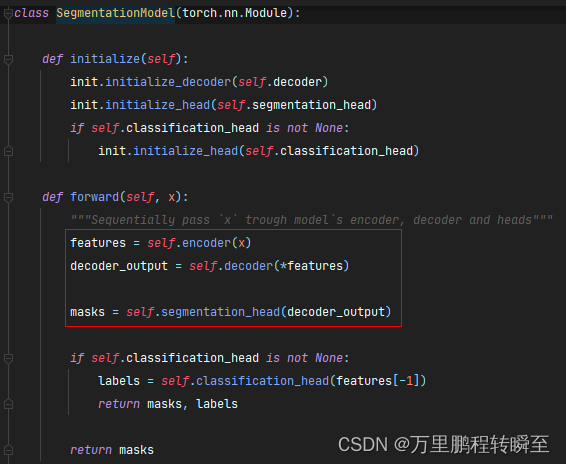
所有smp模型的forward流程都如下图所示
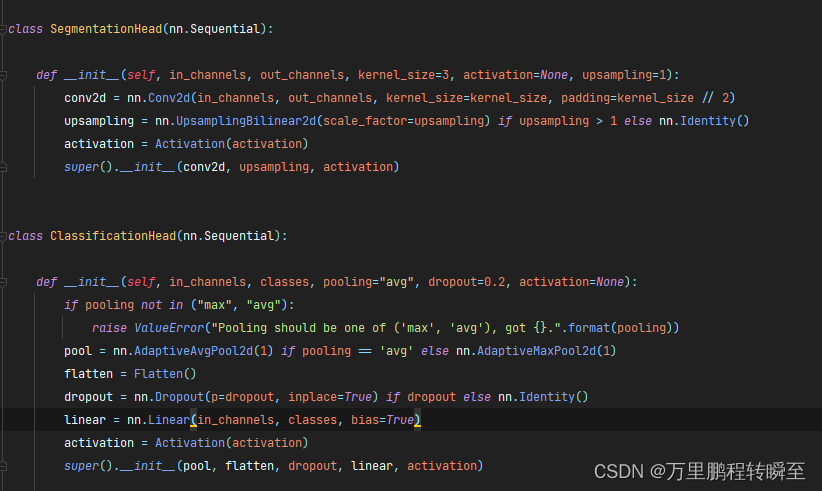
语义分割头与分类赋值头


















 3877
3877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











