







KMP算法是一种快速的字符串匹配算法,我们先从暴力字符串匹配算法讲起看怎么对其优化得到KMP算法。
代码转自这篇文章 http://blog.csdn.net/liu940204/article/details/51318281
1、暴力字符串匹配
有如下两个字符串:A:“abcabbcabc”和B:“adfabcabccabcadbcabca”,我们要在B中找到A的匹配位置,暴力匹配的做法就是:把A的第一个元素与B的第一个元素对齐并开始往后遍历比较,遍历的过程中只要有一个字符不匹配,则将A往后移动一位,即将A的第一个元素与B的第二个元素对其开始往后遍历比较,以此类推。
如上述两个字符串A和B的匹配过程如下:
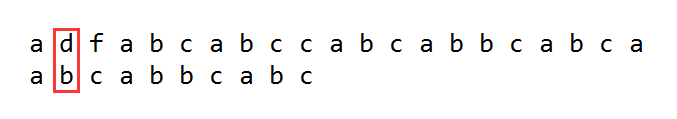
第一个元素匹配,第二个元素d和b不匹配,那么将A串往后移动一位继续匹配如下:
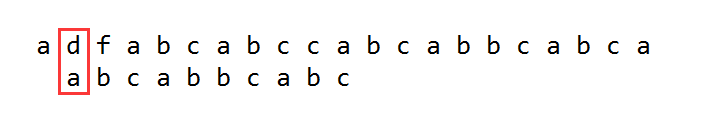
再移动两次后,来到了这个位置:
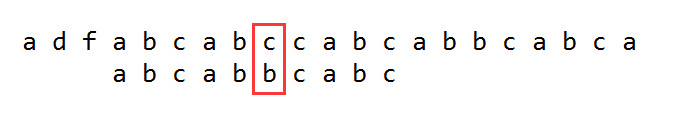
我们可以看到在比较c和b时发现不匹配,但是前面的abcab全是匹配的,而暴力匹配的做法是继续将字符串A移动一位,然后将两个字符串从头开始匹配,知道遍历到如下地方匹配完成:
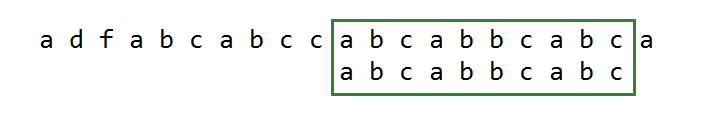
因此得到的暴力匹配算法如下:
int ViolentMatch(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
if (s[i] == p[j])
{
//①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++
i++;
j++;
}
else
{
//②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0
i = i - j + 1;
j = 0;
}
}
//匹配成功,返回模式串p在文本串s中的位置,否则返回-1
if (j == pLen)
return i - j;
else
return -1;
} 暴力匹配算法的时间复杂度为O(m*n)其中m和n分别是两个字符串的长度
2、KMP算法
KMP算法从暴力匹配算法经过优化得到,我们仔细看暴力搜索算法的移动,在上面第三张图中,当b与c发生不匹配时,前面的abcab是已经匹配了的,如下:

既然前面的已经匹配过了,那么我们就知道,此时只将A移动一位,肯定是不匹配的,通过观察我们发现,应当将A移动到如下地方:

这样就可以省掉了不比较的字符比较,即在某个字符匹配失败时,前面的字符串是匹配成功的,我们可以根据已经匹配成功的字符串,得出下次的匹配从哪里开始。
我们可以看到,上面的字符串之所以可以这样移动,是因为前面已经匹配的字符串abcab中,前面的首尾是一样的,即都是“ab”,所以我们将字符串A的首部直接移动到已经匹配了的地方,然后重新比较上次匹配失败的字符。
那么我们现在要做的就是求出A中当每个字母匹配失败时,下次应该从哪里开始继续匹配,将下标保存在Next[]数组中,即若Next[j]=k,表示在A中当下标j处的元素匹配失败时,继续从下标为K处开始匹配。
首先Next[0]=-1,表示第一个元素就匹配失败,要同时移动A和B一项然后从新开始匹配
Next[1]= 0 ,表示第二个元素匹配失败时,从A的第一个元素开始继续匹配
那么重点开始了,接着上面的,现在开始求Next数组:
Next[j]的值与Next[j-1]的值有关,原因如下:
①当在j处发生不匹配时,若Next[j-1]=0,表示j-1的前面字符串没有首尾一样的,那么只用比较A[0]和A[j-1]
若A[0]=A[j-1],则Next[j]=1,否则Next[j]=0
②当在j处发生不匹配时,若Next[j-1]=k,表示j-1前面的字符串中,首部K个长度和尾部K个长度一样,那么我 们需要比较A[K]和A[j-1],若A[k]=A[j-1],明显此时j前面就有首部k+1个和尾部k+1个是一样的,即 Next[j]=k+1,即Next[j]=Next[j-1]+1
③那么当A[k]≠A[j-1]时,该怎么确定A[j]的值呢(我想很多人迷惑的是这个地方),我们看下图:
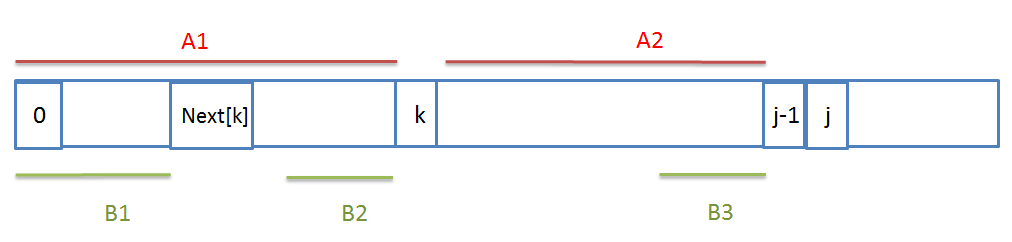
当j处发生不匹配且A[k]≠A[j-1]时,我们已知Next[j-1]=k,即图中A1=A2,那么可以得到B2=B3。同理由K和Next[k]可以得到图中B1=B2,那么就有B1=B3。
因此现在只需要比较A[j-1]与Next[k]的大小就可以了,若相等,则Next[j]=Next[k]+1,否则继续往后找。
那么获取Next数组的代码如下:
void GetNext(char* p,int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
if (k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
} 有了Next数组后,KMP算法的代码就比较容易了,代码如下:
int KmpSearch(char* s, char* p)
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while (i < sLen && j < pLen)
{
//①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
//②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}
if (j == pLen)
return i - j;
else
return -1;
}3、Next数组的优化:
如果当Next[j-1]=A[k]且Next[j]=A[j]时,不能直接使Next[j]=Next[j-1]+1,如下图:
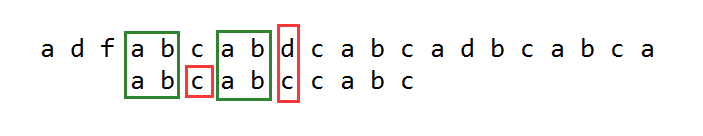
如果直接移动过去,明显下一个比较是不相等的,所以在构造Next数组时还需要一次判断,代码如下:
//优化过后的next 数组求法
void GetNextval(char* p, int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++j;
++k;
//较之前next数组求法,改动在下面4行
if (p[j] != p[k])
next[j] = k; //之前只有这一行
else
//因为不能出现p[j] = p[ next[j ]],所以当出现时需要继续递归,k = next[k] = next[next[k]]
next[j] = next[k];
}
else
{
k = next[k];
}
}
}















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









