







在机器学习中,模型评估与选择是至关重要的步骤。这一过程包括评估模型的性能、选择最适合的模型,以及对模型进行优化,以确保在实际应用中达到最佳效果。以下是详细的讲解:
一、模型评估
模型评估的目的是衡量模型在数据上的表现,以便了解模型的泛化能力(即在未见过的数据上的性能)。常用的评估方法包括:
在机器学习中,经验误差(Empirical Error)和过拟合(Overfitting)是两个重要的概念,理解它们对于构建有效的模型至关重要。以下是对这两个概念的详细讲解:
经验误差(Empirical Error)
定义
经验误差是模型在训练数据上的错误率,也称为训练误差(Training Error)。它是通过将模型应用于训练数据集来计算的,衡量的是模型在已知数据上的表现。
公式
对于一个监督学习模型,经验误差可以通过以下公式计算:
对于分类问题,经验误差通常表示为分类错误率:
Error
train
=
1
n
∑
i
=
1
n
I
(
y
i
≠
y
^
i
)
\text{Error}_{\text{train}} = \frac{1}{n} \sum_{i=1}^{n} \mathbb{I}(y_i \neq \hat{y}_i)
Errortrain=n1i=1∑nI(yi=y^i)
其中,( n ) 是训练样本的数量,( y_i ) 是第 ( i ) 个样本的真实标签,( hat{y}_i ) 是模型对第 ( i ) 个样本的预测标签,(mathbb{I}(cdot)) 是指示函数,当括号内条件为真时,值为1,否则为0。
对于回归问题,经验误差通常表示为均方误差(Mean Squared Error, MSE):
MSE
train
=
1
n
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
\text{MSE}_{\text{train}} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
MSEtrain=n1i=1∑n(yi−y^i)2
作用
经验误差用于衡量模型在训练数据上的拟合程度。较低的经验误差意味着模型在训练数据上的预测效果较好。
过拟合(Overfitting)
定义
过拟合是指模型在训练数据上表现很好,但在未见过的测试数据或验证数据上表现较差的现象。这意味着模型捕捉到了训练数据中的噪声和细节,而不是数据的整体模式,从而导致泛化能力较差。
原因
过拟合的主要原因包括:
- 模型复杂度过高:使用了过于复杂的模型,如深度过大的决策树或过多的特征。
- 训练数据量不足:训练数据不足以支持复杂模型的学习。
- 训练时间过长:模型在训练数据上反复优化,过度拟合训练数据。
识别过拟合
过拟合可以通过以下方式识别:
- 高训练精度,低验证精度:模型在训练数据上的误差很低,但在验证数据上的误差较高。
- 学习曲线:绘制训练误差和验证误差随训练样本数量变化的学习曲线。如果训练误差持续下降,而验证误差在某个点后上升,则可能发生过拟合。
防止过拟合的方法
- 交叉验证:使用交叉验证评估模型性能,选择最能泛化的模型。
- 正则化:引入正则化项,如L1正则化和L2正则化,限制模型复杂度。
- 简化模型:选择较为简单的模型,减少特征数量或降低模型复杂度。
- 增加训练数据:通过获取更多的数据或数据增强技术,增加训练数据量。
- 提前停止(Early Stopping):在验证误差不再降低时停止训练,避免过度拟合。
1. 交叉验证(Cross-Validation)
交叉验证是一种常用的模型评估方法,用于减少过拟合的风险并提供模型性能的更可靠估计。
常见类型:
-
K折交叉验证(K-Fold Cross-Validation):
将数据集划分为K个子集,依次选择一个子集作为验证集,其余K-1个子集作为训练集,重复K次,最终将K次的结果平均。
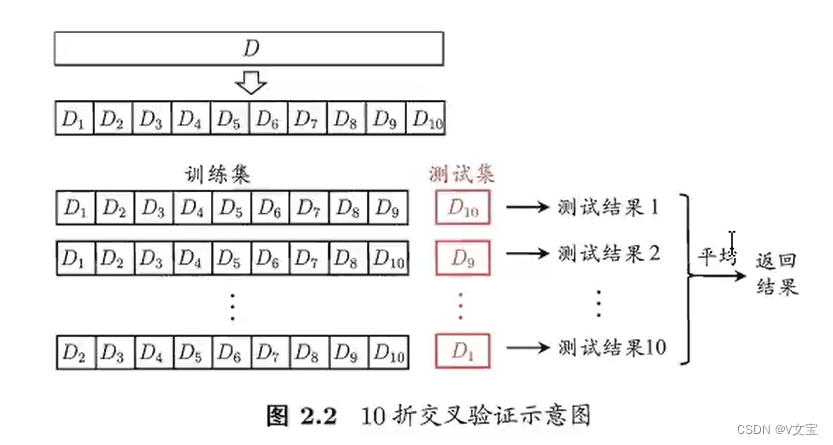
-
留一法交叉验证(Leave-One-Out Cross-Validation,LOOCV):
每次选择一个样本作为验证集,剩余的样本作为训练集,重复N次(数据集大小为N),最终将N次结果平均。
2. 性能评估指标
根据任务类型的不同,常用的评估指标包括:
分类问题:
- 准确率(Accuracy):正确分类的样本数占总样本数的比例。
- 精确率(Precision):即查准率,正类预测为正类的样本数占所有预测为正类样本数的比例。
- 召回率(Recall):即查全率,正类预测为正类的样本数占所有实际正类样本数的比例。
- F1分数(F1-Score):精确率和召回率的调和平均数。
- ROC曲线和AUC(ROC Curve and AUC):绘制真阳性率(TPR)和假阳性率(FPR)的关系图,AUC值越大表示模型性能越好。
查准率(Precision)和查全率(Recall)是分类模型性能评估的重要指标,特别是在不平衡数据集的情况下,它们分别衡量模型在正类预测中的准确性和全面性。以下是对查准率和查全率的详细解释,包括它们的定义、公式和区别。
定义
查准率(Precision)
查准率衡量的是模型预测为正类的样本中,实际为正类的比例。换句话说,查准率关注的是模型预测结果的准确性。
公式:
Precision
=
TP
TP
+
FP
\text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}}
Precision=TP+FPTP
其中:
- TP(True Positive):预测为正类且实际为正类的样本数。
- FP(False Positive):预测为正类但实际为负类的样本数。
查全率(Recall)
查全率衡量的是实际为正类的样本中,被模型正确预测为正类的比例。换句话说,查全率关注的是模型对正类样本的覆盖能力。
公式:
Recall
=
TP
TP
+
FN
\text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}}
Recall=TP+FNTP
其中:
- TP(True Positive):预测为正类且实际为正类的样本数。
- FN(False Negative):预测为负类但实际为正类的样本数。
区别
- 查准率(Precision) 主要关注模型预测结果的正确性,即在所有被预测为正类的样本中,有多少是真正的正类。查准率高意味着较少的假正例(FP)。
- 查全率(Recall) 主要关注模型的覆盖能力,即在所有实际为正类的样本中,有多少被正确预测为正类。查全率高意味着较少的假负例(FN)。
例子
假设我们有一个分类模型预测癌症患者,数据如下:
| 实际\预测 | 正类(有癌症) | 负类(无癌症) |
|---|---|---|
| 正类(有癌症) | TP = 80 | FN = 20 |
| 负类(无癌症) | FP = 10 | TN = 90 |
计算查准率和查全率:
-
查准率(Precision):
Precision = T P T P + F P = 80 80 + 10 = 0.888 \text{Precision} = \frac{TP}{TP + FP} = \frac{80}{80 + 10} = 0.888 Precision=TP+FPTP=80+1080=0.888 -
查全率(Recall):
Recall = T P T P + F N = 80 80 + 20 = 0.800 \text{Recall} = \frac{TP}{TP + FN} = \frac{80}{80 + 20} = 0.800 Recall=TP+FNTP=80+2080=0.800
F1 分数
为了同时考虑查准率和查全率,可以使用F1分数,它是查准率和查全率的调和平均数。
公式:
F1 Score
=
2
×
Precision
×
Recall
Precision
+
Recall
\text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}
F1 Score=2×Precision+RecallPrecision×Recall
F1分数在查准率和查全率之间找到一个平衡点,特别适用于不平衡数据集。
示例代码
以下是一个简单的代码示例,使用Python的scikit-learn库计算查准率和查全率:
from sklearn.metrics import precision_score, recall_score
# 示例数据
y_true = [1, 1, 0, 1, 0, 1, 0, 0, 0, 0] # 实际标签
y_pred = [1, 0, 0, 1, 0, 1, 1, 0, 0, 0] # 预测标签
# 计算查准率
precision = precision_score(y_true, y_pred)
print("Precision:", precision)
# 计算查全率
recall = recall_score(y_true, y_pred)
print("Recall:", recall)
在这个例子中,y_true 是实际标签,y_pred 是模型预测标签。使用 precision_score 和 recall_score 函数分别计算查准率和查全率。
查准率和查全率是衡量分类模型性能的重要指标,它们分别关注预测结果的准确性和覆盖能力。查准率衡量的是在预测为正类的样本中有多少是真正的正类,查全率衡量的是在所有实际为正类的样本中有多少被正确预测为正类。通过了解和使用这些指标,可以更全面地评估模型性能,尤其是在处理不平衡数据集时。
回归问题:
- 均方误差(Mean Squared Error, MSE):预测值与实际值的平方差的平均值。
- 均方根误差(Root Mean Squared Error, RMSE):MSE的平方根。
- 平均绝对误差(Mean Absolute Error, MAE):预测值与实际值的绝对差的平均值。
- R²(R-squared):解释回归模型中解释变量的比例。
二、模型选择
模型选择的目的是从多个候选模型中选择性能最佳的模型。常用的方法包括:
1. 网格搜索(Grid Search)
网格搜索是一种系统地遍历所有可能的超参数组合,以找到最佳参数组合的方法。
步骤:
- 定义超参数的候选值范围。
- 使用交叉验证对每个组合进行评估。
- 选择表现最好的参数组合。
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 加载数据
data = load_iris()
X, y = data.data, data.target
# 定义模型和参数网格
model = RandomForestClassifier(random_state=42)
param_grid = {
'n_estimators': [10, 50, 100],
'max_depth': [None, 10, 20]
}
# 执行网格搜索
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X, y)
# 输出最佳参数和最佳得分
print("Best parameters:", grid_search.best_params_)
print("Best cross-validation accuracy:", grid_search.best_score_)
2. 随机搜索(Random Search)
随机搜索在指定的参数范围内随机选择参数组合进行评估。相比网格搜索,随机搜索更高效,尤其在参数空间较大时。
from sklearn.model_selection import RandomizedSearchCV
# 定义模型和参数分布
param_dist = {
'n_estimators': [10, 50, 100],
'max_depth': [None, 10, 20],
'max_features': ['auto', 'sqrt', 'log2']
}
# 执行随机搜索
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist, n_iter=10, cv=5, scoring='accuracy', random_state=42)
random_search.fit(X, y)
# 输出最佳参数和最佳得分
print("Best parameters:", random_search.best_params_)
print("Best cross-validation accuracy:", random_search.best_score_)
3. 集成学习(Ensemble Learning)
集成学习通过结合多个基学习器的预测结果来提高整体预测性能。
常见方法:
- Bagging:通过对数据进行有放回抽样,训练多个模型,最后对预测结果进行平均或投票(如随机森林)。
- Boosting:逐步训练多个弱学习器,每个模型都尝试修正前一个模型的错误(如AdaBoost和梯度提升)。
- Stacking:使用多个基学习器的预测结果作为新的特征,训练一个元学习器进行最终预测。
三、模型优化
模型优化的目的是在选择最佳模型后,通过调整超参数和进一步调优以提高模型性能。
1. 学习曲线(Learning Curve)
通过绘制训练集和验证集的性能随训练数据量变化的曲线,可以帮助判断模型的偏差和方差情况。
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
import numpy as np
# 生成学习曲线
train_sizes, train_scores, test_scores = learning_curve(model, X, y, cv=5, scoring='accuracy', train_sizes=np.linspace(0.1, 1.0, 10))
# 计算平均值和标准差
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
# 绘制学习曲线
plt.figure()
plt.title("Learning Curve")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")
plt.legend(loc="best")
plt.show()
2. 正则化(Regularization)
通过在损失函数中加入正则化项,可以防止模型过拟合,提高泛化能力。常见的正则化方法包括L1正则化(Lasso)和L2正则化(Ridge)。
from sklearn.linear_model import Ridge
# 定义模型
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
3. 特征选择(Feature Selection)
通过选择最重要的特征,可以减少模型的复杂性,提高模型的解释性和性能。
常见方法:
- 过滤法(Filter Method):根据特征的统计指标选择特征。
- 包装法(Wrapper Method):使用特定算法进行特征选择。
- 嵌入法(Embedded Method):在训练过程中选择特征(如L1正则化)。
from sklearn.feature_selection import SelectKBest, f_classif
# 特征选择
selector = SelectKBest(score_func=f_classif, k=2)
X_new = selector.fit_transform(X, y)
总结
模型评估与选择是机器学习中的重要环节。通过交叉验证和多种评估指标,可以全面评估模型的性能。通过网格搜索、随机搜索和集成学习,可以选择最佳模型。进一步通过学习曲线、正则化和特征选择,可以优化模型性能。掌握这些方法和技巧,有助于构建高效、可靠的机器学习模型。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









