







特征工程是机器学习中一个非常重要的步骤,它直接影响模型的性能和准确性。特征工程的目标是从原始数据中提取、转换和选择适当的特征,使得机器学习算法可以更好地学习和做出预测。以下是特征工程的原理、方法和用法的详细讲解。
特征工程的原理
特征工程的原理在于将原始数据转换成更适合机器学习算法处理的形式。好的特征能够捕捉数据中的模式和规律,帮助模型更好地进行预测。特征工程主要包括以下几个方面:
- 特征提取:从原始数据中提取有用的信息。
- 特征转换:将特征转换成适合模型使用的形式。
- 特征选择:选择对模型有用的特征,去除冗余和无用的特征。
特征工程的方法
1. 特征提取
-
数值特征提取:从数值型数据中提取有意义的特征。
- 示例:在时间序列数据中,可以提取均值、方差、最大值、最小值等统计特征。
-
类别特征提取:从类别型数据中提取特征。
- 示例:使用独热编码(One-Hot Encoding)将类别型特征转换成数值特征。
2. 特征转换
-
标准化(Standardization):将特征缩放到均值为0,标准差为1的标准正态分布。
- 示例:
sklearn.preprocessing.StandardScaler。
- 示例:
-
归一化(Normalization):将特征缩放到特定范围(通常是[0, 1])。
- 示例:
sklearn.preprocessing.MinMaxScaler。
- 示例:
-
对数变换(Log Transformation):对数变换可以减小数据的尺度,尤其适用于长尾分布的数据。
- 示例:
np.log1p(data)。
- 示例:
-
Box-Cox变换:用于处理非正态分布的数据,使其更接近正态分布。
- 示例:
scipy.stats.boxcox(data)。
- 示例:
3. 特征选择
-
过滤法(Filter Method):根据统计指标选择特征,如方差、相关系数、卡方检验等。
- 示例:
sklearn.feature_selection.SelectKBest。
- 示例:
-
包装法(Wrapper Method):通过模型训练选择特征,如递归特征消除(RFE)。
- 示例:
sklearn.feature_selection.RFE。
- 示例:
-
嵌入法(Embedded Method):特征选择过程由算法自身完成,如 Lasso 回归、决策树等。
- 示例:
sklearn.linear_model.Lasso。
- 示例:
特征工程的用法
下面是一个特征工程的实际例子,使用 Python 和 scikit-learn 进行特征提取、转换和选择。
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.model_selection import train_test_split
# 示例数据集
data = pd.DataFrame({
'age': [25, 32, 47, 51, 62],
'salary': [50000, 54000, 58000, 60000, 62000],
'city': ['New York', 'San Francisco', 'San Francisco', 'New York', 'Chicago'],
'target': [1, 0, 1, 0, 1]
})
# 特征和目标变量
X = data.drop('target', axis=1)
y = data['target']
# 处理数值特征
numeric_features = ['age', 'salary']
scaler = StandardScaler()
X[numeric_features] = scaler.fit_transform(X[numeric_features])
# 处理类别特征
categorical_features = ['city']
encoder = OneHotEncoder(drop='first')
encoded_features = encoder.fit_transform(X[categorical_features]).toarray()
# 获取编码后的特征名称
encoded_feature_names = encoder.get_feature_names_out(categorical_features)
# 删除类别型特征
X = X.drop(categorical_features, axis=1)
# 将独热编码后的特征添加到原始数据中
X[encoded_feature_names] = encoded_features
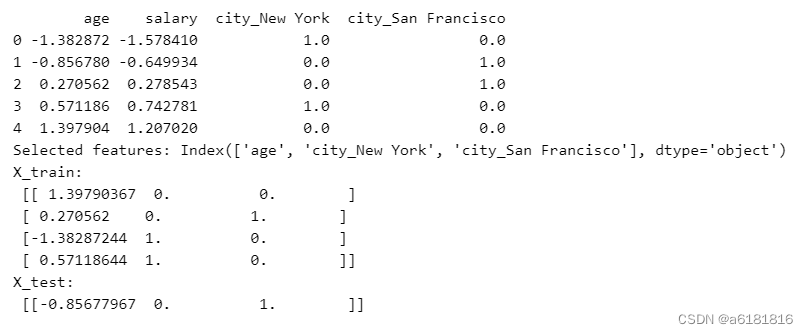
print(X)
# 特征选择
selector = SelectKBest(score_func=f_classif, k=3)
X_selected = selector.fit_transform(X, y)
selected_feature_names = X.columns[selector.get_support(indices=True)]
print("Selected features:", selected_feature_names)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=0.2, random_state=42)
# 打印结果
print("X_train:\n", X_train)
print("X_test:\n", X_test)
输出:
总结
特征工程是机器学习中的关键步骤,通过特征提取、特征转换和特征选择,可以显著提升模型的性能。了解不同的方法和工具,并在实际项目中应用这些技术,能够帮助你构建更强大和准确的模型。















 6233
6233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









