






一、文件读取
整个文件的遍历方法:
1、直接使用read函数
#遍历文本的方法一
fname = input("请输入要打开文件的名称:")
fo = open(fname,"r")
txt = fo.read()
#对全文txt进行处理
fo.close()
优点为简单、容易,便于理解;缺点是若是读取十分大的文件,比如几个G的文件,会占用十分大的内存去读取。
2、按数量处理,逐步读入
#遍历文本的方法二
fname = input("请输入要打开文件的名称:")
fo = open(fname,"r")
txt = fo.read(2)
while txt !="":
#对txt进行逐步处理的条件
txt=fo.read(2)
fo.close()
对处理大文件,这是一种很好的方法。
3、对分行的文件利用分行遍历
#逐行遍历文件方法一
fname = input("请输入要打开文件的名称:")
fo = open(fname,"r")
for line in fo.readlines():
print(line)
fo.close()
以每一行为元素,生成一个列表。
4、逐行处理方法二
#逐行遍历文件方法二
fname = input("请输入要打开文件的名称:")
fo = open(fname,"r")
for line in fo():
print(line)
fo.close()
对极大文件的有效处理。
二、文件写入
1、.write(s),向文件写入一个字符串或者字节流。
2、.writelines(lines),将一个元素群为字符串的列表写入文件,但输入文件后无换行或者空格,而是字符串的直接拼接。-
3、.seek(offset),改变当前文件操作指针的位置,offset含义如下:0—文件开头,1—文件的当前位置,2—文件结尾。
在这里我们做一个实例:
fo=open("hhh.txt","w+")
ls=["three"," kingdom"," battle"]
fo.writelines(ls)
for line in fo:
print(line)
fo.close
运行以上代码,我们预期得到的文本hhh.txt中应该有three kingdom battle的字符,但是运行程序后并没有任何变化。


再运行以下代码:
fo=open("hhh.txt","w+")
ls=["three"," kingdom"," battle"]
fo.writelines(ls)
fo.seek(0)
for line in fo:
print(line)
fo.close
运行结果如下:
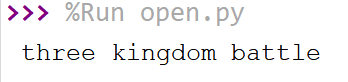

差距在于fo.seek(0),其作用为将指针位置移到文件开始位置。
我们可以想到,通过fo.writelines(ls)写入文件后,当前的指针在文件的最后面,此时利用for in的话,我们得到的结果即什么都没有,所以利用fo.seek(0),将指针移至初始位置。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









