







今天写第二篇,我的顺序是先仔细阅读这类源码工具,阅读时边注释边读,边运行程序,边作图。由于源码的量还是不小,这样做可能会出现一些自己的疏忽,比如刚开始看某块的时候不是特别明白,注释写的也不是很清楚,整个源码阅读完后可能自己明白了,但是却忘记回去更改原来的注释,所以如造成有任何错误,还请多多指出~
这一篇介绍这个工具的基础数据组织的实现,头文件在data.h中,实现在data.cc中。先详细介绍一下最终的语料数据组织,然后再详细介绍整个Data类的组织以及遍历方式,最终存放于容器中的语料呈现的形式分为三种模式,原论文是这么说的:
- A sequence is defined to be a sentence from the training data. As a result, sequences can be quite different in length, especially in case of conversational speech transcriptions.
- A sequence represents the concatenation of multiple sentences up to a given maximum length. In this way, the neural network can potentially learn across-sentence dependences, and each sequence starts with a sentence begin token.
- A sequence consists of a fixed number of consecutive words. This means that the text is split into sequences at arbitrary positions. The network can learn acrosssentence dependences, and the sequence may start with any word.
第一种模式就是一个Sequence容器里面装入一个句子,第二种模式是可能包含多个句子,可以使训练跨句子,第三种模式是每个Sequence容器的长度固定的。这三种模式的用枚举变量来表示,代码如下:
<span style="font-size:16px;">//语料处理的三种类型:
//kConcatenated: 表示一个Sequence可能包含多个句子,可以使训练跨句子
//kFixed: Sequence都是固定的长度序列
//kVerbatim: 一个Sequence就是语料中一个句子长度
enum WordWrappingType {
kConcatenated, kFixed, kVerbatim
};</span><span style="font-size:16px;">//Sequence指定一个序列,对于语料来说,就是一个句子
typedef std::vector<int> Sequence;
//这里可以理解为存放句子的容器
typedef std::vector<Sequence> SequenceVector;</span>
<span style="font-size:16px;">it 's just down the hall .
I 'll bring you some now .
if there is anything else you need ,
just let me know .
No worry about that .
I 'll take it and you need not wrap it up .
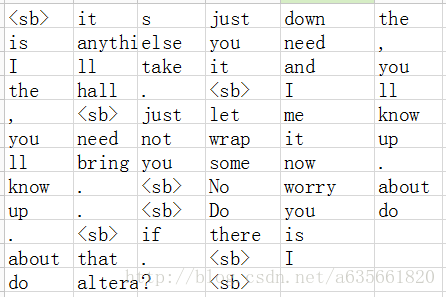
Do you do alterations ?</span>程序执行的参数batch-size设置为4 ,模式设置为verbatim,注意在该模式下面max_sequence_length不起作用,容器Sequence负责装入语料的一个完整句子,不会被max_sequence_length限制,data_的具体内容:

经过SortBatches()排序后,batch-size = 4,则每4个句子都会按句子长度从大到小排列,如下:
然后我又通过改动源码调整成了concatenated,并且命令行参数变动的为:--batch-size 3 --sequence-length 20,内容如下:

经过排序后:

然后再改为fixed的模式,命令行参数变动为:--sequence-length 6,内容如下:
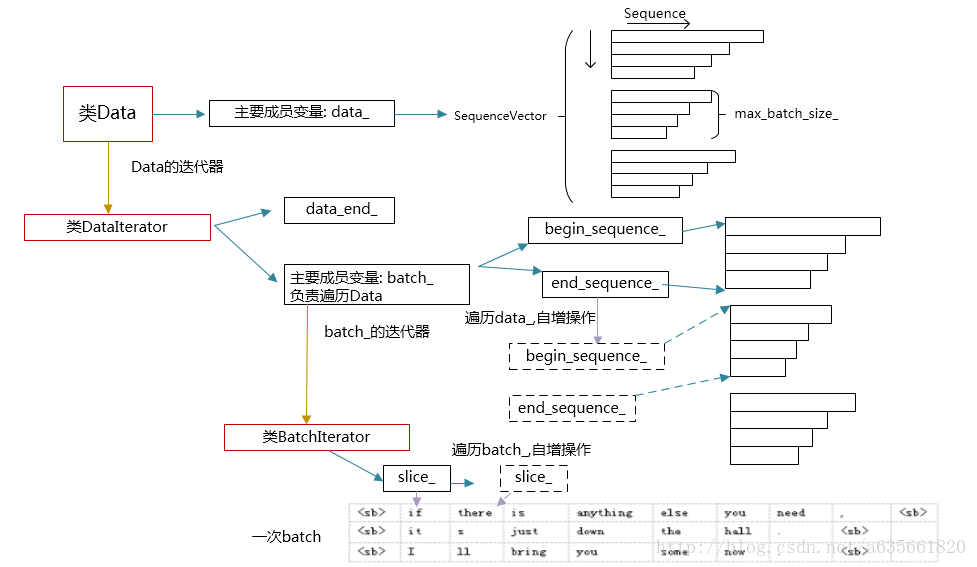
上面介绍了三种完整的语料组织,下面看一下整个数据类以及遍历的组织情况。先可以这样简单描述:定义了Data类,来表示整个语料数据,为了遍历Data,定义了Data的迭代器DataIterator,但实际上负责遍历Data是DataIterator类中的成员变量Batch,为了遍历Batch,定义了BatchIterator,BatchIterator的成员变量slice_负责装入遍历Batch的内容。可见,里面有多层的结构,文字描述远不如图形来的直观,上面的整个组织框架如下图:
<span style="font-size:16px;">//关于iterator_facade的详细说明可以见
//http://www.boost.org/doc/libs/1_54_0/libs/iterator/doc/iterator_facade.html
class BatchIterator : public boost::iterator_facade<BatchIterator,
const Sequence, boost::bidirectional_traversal_tag> {
public:
//构造函数,将position_,offset_初始为0
BatchIterator() : position_(0), offset_(0) {
// forward traversal iterators require default constructor (?7.6.3.1)
}
//构造函数,给定句子容器的起始,结束位置,并给出相关位置量
//并得到slice_的具体内容(slice_见图)
BatchIterator(const SequenceVector::const_iterator &begin,
const SequenceVector::const_iterator &end,
const int position, const int offset)
: begin_(begin), end_(end), position_(position), offset_(offset) {
//这里offset的含义如下:
//offset = 1, slice_会取到sequence最后一个
//offset = 0, slice_不会取到sequence最后一个
//offset这样控制是因为不同的模式sequence最后一个word的含义不同
//比如在kVerbatim模式下,sequence最后一个word是<sb>表示结束,而在
//kConcatenated下就不一定是<sb>了
assert(offset == 0 || offset == 1);
//得到slice_,即图中的部分
for (auto it = begin; it != end && !it->empty(); ++it) {
//static_cast<int>(it->size() - 1)将it->size() - 1强制转换为int类型
if (position >= static_cast<int>(it->size() - 1) + offset)
break;
slice_.push_back(it->at(position));
}
}
private:
friend class boost::iterator_core_access;
//相当于++操作,这里是实现接口,具体效果就是slice_往上面走(见图)
void increment() {
++position_;
slice_.clear();
for (auto it = begin_; it != end_; ++it) {
if (position_ >= static_cast<int>(it->size()) -1 + offset_)
break;
slice_.push_back((*it)[position_]);
}
}
相当于--操作,这里是实现接口,具体效果就是slice_往下面走(见图)
void decrement() {
slice_.clear();
--position_;
for (auto it = begin_; it != end_; ++it) {
if (position_ < offset_ || position_ >=
static_cast<int>(it->size()) - 1 + offset_)
break;
slice_.push_back((*it)[position_]);
}
}
//BatchIterator是否相等,这里只认为position相等即可
//并未要求begin_, end_都相等
bool equal(const BatchIterator &other) const {
return position_ == other.position_;
}
//解引用
const Sequence &dereference() const {
return slice_;
}
//变量含义见前面注释,以及图
int position_;
Sequence slice_;
const int offset_;
const SequenceVector::const_iterator begin_, end_;
};
class Batch {
public:
//构造函数,初始化相关成员变量
Batch(const SequenceVector::const_iterator &begin_sequence,
const SequenceVector::const_iterator &end_sequence)
: begin_sequence_(begin_sequence), end_sequence_(end_sequence) {
}
//返回一个BatchIterator,这个BatchIterator由begin_sequence_,
//end_sequence_, offset初始化
BatchIterator Begin(const int offset) const {
return BatchIterator(begin_sequence(), end_sequence(), offset, offset);
}
//这里返回的BatchIterator指向sequence最后一个word的后面
BatchIterator End(const int offset) const {
//这里是用构造函数直接产生无名对象
return BatchIterator(begin_sequence(), end_sequence(),
begin_sequence()->size() - 1 + offset, offset);
}
//返回一个BatchIterator,它的postion_指向1,sequence第一个word是无效的
//sequence第一个word要么是<sb>,要么就是前面句子的最后一个word
BatchIterator begin() const {
return Begin(1);
}
BatchIterator end() const {
return End(1);
}
private:
friend class DataIterator;
//返回指向句子容器的开始
SequenceVector::const_iterator begin_sequence() const {
return begin_sequence_;
}
//返回指向句子容器的结束
SequenceVector::const_iterator end_sequence() const {
return end_sequence_;
}
//设置指向句子容器的开始
void set_begin_sequence(const SequenceVector::const_iterator &begin_sequence) {
begin_sequence_ = begin_sequence;
}
//设置指向句子容器的结束
void set_end_sequence(const SequenceVector::const_iterator &end_sequence) {
end_sequence_ = end_sequence;
}
SequenceVector::const_iterator begin_sequence_, end_sequence_;
};
class DataIterator : public boost::iterator_facade<DataIterator, const Batch,
boost::incrementable_traversal_tag> {
public:
//构造函数,batch_的指向句子容器结束的指针得依据end - begin >= max_batch_size而定
//如果end超过max_batch_size,则batch_的end指向begin + max_batch_size
DataIterator(const SequenceVector::const_iterator &begin,
const SequenceVector::const_iterator &end,
const int max_batch_size)
: batch_(begin, end - begin >= max_batch_size ?
begin + max_batch_size : end),
data_end_(end),
max_batch_size_(max_batch_size) {
}
private:
friend class boost::iterator_core_access;
//相当于++操作
//这里的效果是一次移动max_batch_size_(见图)
void increment() {
batch_.set_begin_sequence(data_end_ - batch_.begin_sequence() >
max_batch_size_ ? batch_.begin_sequence() +
max_batch_size_ : data_end_);
batch_.set_end_sequence(data_end_ - batch_.end_sequence() >
max_batch_size_ ? batch_.end_sequence() +
max_batch_size_ : data_end_);
}
//两个DataIterator是否相等看batch_.begin_sequence_是否相等
bool equal(const DataIterator &other) const {
return batch_.begin_sequence() == other.batch_.begin_sequence();
}
//相当于解引用
const Batch &dereference() const {
return batch_;
}
const int max_batch_size_;
const SequenceVector::const_iterator data_end_;
Batch batch_;
};
class Data {
public:
//构造函数,这里word_wrapping_type指定哪种模式
Data(const std::string &data_file_name,
const int max_batch_size,
const int max_sequence_length,
const WordWrappingType word_wrapping_type,
//--debug-no-sb
//For debugging purposes, automatic insertion of "<sb>" tokens can be switched off. Use with caution.
//如果未指明--debug-no-sb,则debug_no_sb = 0
const bool debug_no_sb,
ConstVocabularyPointer vocabulary);
Data(const SequenceVector data,
const int max_batch_size,
const int max_sequence_length,
ConstVocabularyPointer vocabulary);
//先打乱所有sequence的顺序,然后在每一个max_batch_size_排序
//每一个max_batch_size_范围内,data_安装Sequence的大小从大到小排序
void Shuffle(Random *random) {
// sort: current shuffling result shall not depend on previous shuffling
std::sort(data_.begin(), data_.end());
std::random_shuffle(data_.begin(), data_.end(), *random);
SortBatches();
}
//返回data_包含多少个word,要除去每一个sequence的第一个token
int64_t CountNumRunningWords() const {
// subtract one for sentence begin token
return std::accumulate(data_.begin(), data_.end(), 0LL,
[](const int64_t sum, const Sequence &s)
{ return sum + s.size() - 1; });
}
//返回有多少个max_batch_size_,不足一个max_batch_size_的也算一个
int GetNumBatches() const {
return (data_.size() + max_batch_size() - 1) / max_batch_size();
}
//获取词典大小
int GetVocabularySize() const {
return vocabulary_->GetVocabularySize();
}
//构造函数直接返回无名的DataIterator对象
DataIterator begin() const {
return DataIterator(data_.begin(), data_.end(), max_batch_size_);
}
DataIterator end() const {
return DataIterator(data_.end(), data_.end(), max_batch_size_);
}
int max_batch_size() const {
return max_batch_size_;
}
private:
friend class GradientTest;
//从训练文件读取句子,在内部就转换为那个图的表示形式
//并且返回所有的word数
int64_t ReadIndices(const std::string &data_file_name,
const ConstVocabularyPointer &vocabulary,
SequenceVector *data);
//concatenate = 1则一个sequence含多个句子,否则就一个句子
void PrepareDataSequenceWise(const std::string &data_file_name,
const bool concatenate);
//一个sequence长度固定
void PrepareDataWithFixedLength(const std::string &data_file_name);
//concatenate = true表示将原生态的句子链接成一个更长的句子,即支持跨句子训练,但不能超过max_length的长度
//concatenate = false表示不链接
void Append(const size_t max_length,
const bool concatenate,
Sequence *current);
//每一个max_batch_size_范围内,data_安装Sequence的大小从大到小排序
void SortBatches();
const int max_batch_size_, max_sequence_length_;
const bool debug_no_sb_;
const ConstVocabularyPointer vocabulary_;
SequenceVector data_;
};
typedef std::shared_ptr<Data> DataPointer;</span>














 8120
8120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









