







现在是第三篇,后面的顺序是从输出层,到隐层,然后到输入层的顺序来写,最后在写一下整个框架。这篇介绍输出层的实现,整个程序非常关键的是矩阵相乘的函数,所以在看整个输出层实现之前,非常有必要详细的介绍一下里面反复用到的矩阵相乘函数的各个参数的含义。先看一下FastMatrixMatrixMultiply这个函数,如下:
inline void FastMatrixMatrixMultiply(
const float alpha,
const float a[],
const bool transpose_a,
const int rows_a,
const int columns_a,
const float b[],
const bool transpose_b,
const int columns_b,
float c[]) {
cblas_sgemm(CblasColMajor, //表示列主序,即二维数组中第i行第j列的表示是a[j][i]
transpose_a ? CblasTrans : CblasNoTrans, //表示a是否转置
transpose_b ? CblasTrans : CblasNoTrans, //表示b是否转置
rows_a, //a, c的行数
columns_b, //b, c的列数
columns_a, //a的列数, b的行数
alpha, //c = alpha*a*b + beta*c, 这是计算公式,alpha指定其中相乘法的系数
a, //矩阵a
transpose_a ? columns_a : rows_a, //因为是列主序,如果a是转置的,这里结果是a的列数
b, //矩阵b
transpose_b ? columns_b : columns_a, //因为是列主序,如果b是转置的,这里结果是a的列数
1.0f, //c = alpha*a*b + beta*c, 这是计算公式,参数的结果是beta, 指定其中相乘法的系数
c, //矩阵c
rows_a); //矩阵c的行数
}各个矩阵参数的详细含义见上面的注释,对上面的函数它完成的功能即(简要的忽略了行列):
c = alpha * a * b + beta * c
举一个实现中的例子来仔细分析其功能,代码如下:
FastMatrixMatrixMultiply(1.0, //alpha
class_weights_, //a
false, //a不转置
num_classes_, //rows_a,即a, c的行数
input_dimension(), //columns_a,即a的列数, b的行数
x, //b
false, //b不转置
slice.size(), //b, c的列数
class_b_t_); //c上面完成的功能用下面的数学式子来描述:

这里谈一下自己的理解,从纯数学的角度看,就是一个行为num_classes_列为input_dimension()的矩阵a,乘以行为input_dimension()列为slice.size()的矩阵b,得到一个行为num_classes_列为slice.size()的矩阵c。这种看法是不考虑任何存储的,如果考虑用一维数组存储的话可以有两种方式,第一种是行m列n对应起来存储,即一维数组分为m块,每块有n个元素,这属于行主序。另一种是一维数组分为n块,每块有m个元素这属于列主序。这两者的区别是任意一者转置可以得到另一者。这里采用的是列主序,之所以必须这么详细了解,是因为后面对数组的操作是精确到每一个位上的,因此必须了解数组每个位置对应实际的数学矩阵含义才能更清楚。整个程序用的都是列主序,可能和平常有点感觉不一样,所以特别注意后面矩阵在一维数组中位置的存储顺序问题。为了加深理解,我在这个函数上做了一个小例子,能更方便的理解。考虑下面的两个矩阵(数学形式):
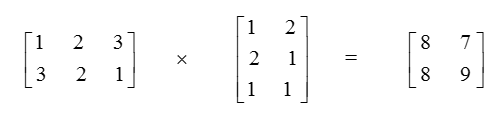
我们用上面的函数来计算这个结果,因为是列主序的,所以存储前面两个矩阵到数组里面需要转置后存储:
double a[] = {1., 3., 2., 2., 3., 1.};
double b[] = {1., 2., 1., 2., 1., 1.};
double c[4] = {0};执行该函数为:
FastMatrixMatrixMultiply(1.0, a, false, 2, 3, b, false, 2, c);结果是c: 8 8 7 9
要把c恢复到矩阵的数学形式上来,需要再转置,就得到等式右边了。其实就是存储的方式问题。
然后在使用这个函数时,我们可以不用关心它的存储方式,只需要知道矩阵的数学形式,以及行,列是多少即可。但是如果一旦要用到数组中的位,就必须弄明白每一位对应的是矩阵中哪个元素了。另外上面那个函数如果指定了矩阵为转置,那么对应的行列应该是该矩阵转置后的行列。而在FastMatrixVectorMultiply函数中,则有点不同,如果第一个矩阵指定为转置,那么后面的行列应该是该矩阵未被转置时的行列。我觉的这样两个函数用起来确实让人不方便,为啥不统一下诶。
好啦,矩阵的相乘差不多就这样了,矩阵和向量乘之类的在注释中有写,在output.cc文件实现中,有一个很关键的数据结构,虽然只是线性的一维数组,但这个一维数组里面隐含着丰富的非线性结构信息,在上代码注释之前,把图放上来,第一幅图是word_bias_的结构,第二幅图是神经网络输出层的大概结构,第三幅图是一维数组所代表的信息,注意前面分析过了,矩阵的存储方式是列索引的,所以一维数组里面的信息转置一下就是第三张图了。

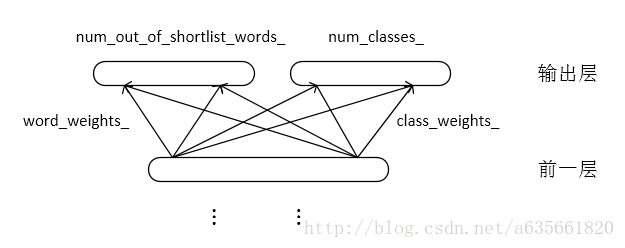
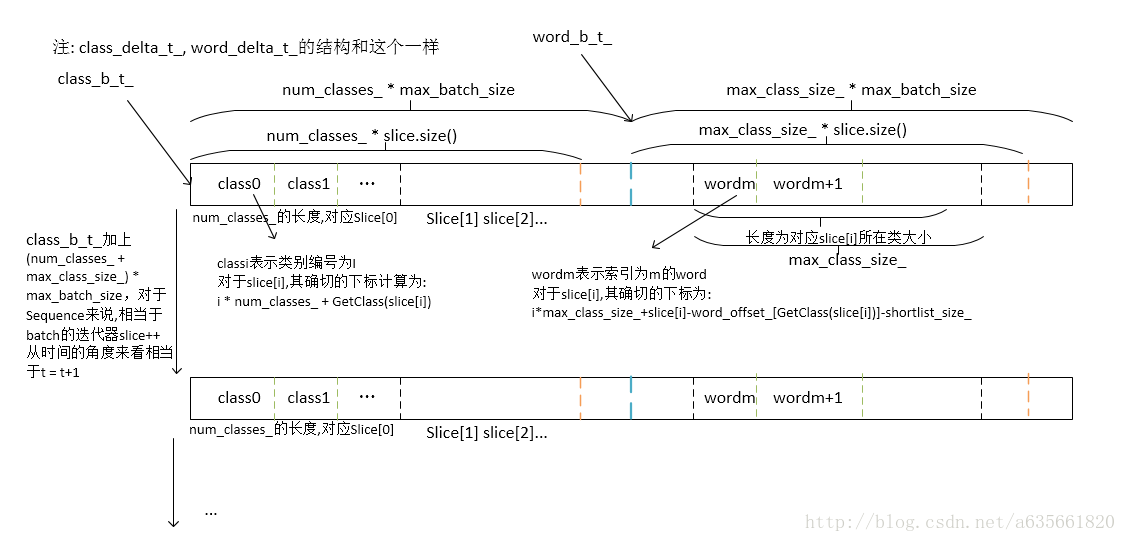
下面就是源代码的注释了,很多分析在里面有写了,直接上代码吧,注意代码并不是完整的output.cc,只放了核心的代码注释。好!这样本篇就完了。
#include <boost/functional/hash.hpp>
#include <iomanip>
#include <iostream>
//#include <numeric> // only for checking normalization
#include "output.h"
//构造函数 初始化
//input_dimension指的是前一层的大小
Output::Output(const int input_dimension,
const int max_batch_size,
const int max_sequence_length,
//num_oovs当vocabulary未包含所有的word时,指定的oov的数量
//默认值是0
const int num_oovs,
//use_bias指示是否使用偏置向量,默认值是1
const bool use_bias,
ConstVocabularyPointer vocabulary,
ActivationFunctionPointer activation_function)
: Function(
input_dimension,
//functional的output_dimension即词典大小加类别数目(至少包含2个word的类别)
vocabulary->GetVocabularySize() + vocabulary->GetNumClasses() -
vocabulary->ComputeShortlistSize(),
max_batch_size,
max_sequence_length),
//std::move是c++ 11新特性,了解不多,网上参考的:将一个左值强制转化为右值引用
activation_function_(std::move(activation_function)),
num_classes_(vocabulary->GetNumClasses()),
max_class_size_(vocabulary->GetMaxClassSize()),
num_oovs_(num_oovs),
//计算含有至少2个word的类别的数量
num_out_of_shortlist_words_(vocabulary->GetVocabularySize() -
vocabulary->ComputeShortlistSize()),
shortlist_size_(vocabulary->ComputeShortlistSize()),
vocabulary_(vocabulary) {
//max_class_size_是类别中包含最多的word的数目
//std::cout << "input_dimension:\t" << input_dimension << std::endl;
//std::cout << "num_oovs:\t" << num_oovs << std::endl;
//std::cout << "use_bias:\t" << use_bias << std::endl;
//std::cout << "output_dimension\t" << vocabulary->GetVocabularySize() << " + " << vocabulary->GetNumClasses() << " - " << vocabulary->ComputeShortlistSize() << std::endl;
//std::cout << "vocabulary->GetMaxClassSize():\t" << vocabulary->GetMaxClassSize() << std::endl;
//分开来看,先考虑num_classes_,这部分单纯表示一个sequence下输出层(class部分)的大小,这里的作用是计算保存神经元的输入输出
//然后考虑max_batch_size,也就是有max_batch_size个num_classes_,这里一个max_batch_size里面每个sequence的输出层class部分都分配了
//然后考虑max_sequence_length,如果神经元的输入是当前第一个word,那么下一次输入时是第二个word,这些不同的输入环境都分配好了输出层class部分的空间
//最后考虑 max_class_size_部分,它表示输出层的word部分,作用仍然是计算神经元的输入输出,各个分配同理于class部分
class_b_ = FastMalloc((num_classes_ + max_class_size_) * max_batch_size *
max_sequence_length);
//这个和上面的分析是一致的,这里表示的保存到达本层的误差,以及本层的误差
class_delta_ = FastMalloc((num_classes_ + max_class_size_) * max_batch_size *
max_sequence_length);
//输出层的类别层部分到前一层的权重
class_weights_ = FastMalloc(num_classes_ * input_dimension);
//输出层的类别层部分到前一层的偏置向量
class_bias_ = use_bias ? FastMalloc(num_classes_) : nullptr;
std::cout << "num_classes_:\t" << num_classes_ << std::endl;
//输出层的类别层部分到前一层的momentum权重,用来累加权重的改变
momentum_class_weights_ = FastMalloc(num_classes_ * input_dimension);
momentum_class_bias_ = use_bias ? FastMalloc(num_classes_) : nullptr;
//表示输出层的word部分,这里并不是一个sequence下某个word作为输入的输出层部分,前面分析了,后面就不再强调了
word_b_ = class_b_ + num_classes_ * max_batch_size;
word_delta_ = class_delta_ + num_classes_ * max_batch_size;
//分别输出层的word层部分到前一层的权重,以及偏置向量
word_weights_ = FastMalloc(num_out_of_shortlist_words_ * input_dimension);
//word_bias_的结构的内部排列的含义见图
word_bias_ = use_bias ? FastMalloc(num_out_of_shortlist_words_) : nullptr;
std::cout << "num_out_of_shortlist_words_:\t" << num_out_of_shortlist_words_ << std::endl;
//word_offset_的作用:
//输出层word部分的排列就是word_bias_图的排列
//所以为了输出层分解为word + class,这是为了加快计算速度,那么在计算word部分时,只需要计算expected word所属类别的word
//于是就会有这样一个需要:给定一个word,确定它所属类别在一维数组的起始位置: word_offset_[class[word]]
int sum = 0;
for (int i = 0; i < num_classes_; ++i) {
std::cout << "sum:\t" << sum << std::endl;
word_offset_.push_back(sum);
const int class_size = vocabulary_->GetClassSize(i);
// we do not need weights for shortlist words
if (class_size != 1)
sum += class_size;
}
}
//计算输出层的输出,分为class,word两部分实现
//x表示前一层的输出
const Real *Output::Evaluate(const Slice &slice, const Real x[]) {
//std::cout << "This is in Evaluate in output.h\n";
const Real *result = class_b_t_;
// class part
//输出层class部分存在偏置向量
if (class_bias_) {
for (size_t i = 0; i < slice.size(); ++i)
//将class_bias_的num_classes_大小块全部复制到class_b_t_ + i * num_classes_
FastCopy(class_bias_, num_classes_, class_b_t_ + i * num_classes_);
}
for (size_t i = 0; i < slice.size(); ++i) {
//std::cout << "slice:\t" << vocabulary_->GetWord(slice[i])<< std::endl;;
}
//std::cout << "\n";
//这里是对每一个sequence,计算输出层(class部分)的输入,共有slice.size()个sequence
//class_b_t_ [num_classes_*slice.size()] = class_weights_ [num_classes_*input_dimension()] * x [input_dimension()*slice.size()] + class_b_t_
FastMatrixMatrixMultiply(1.0,
class_weights_,
false,
num_classes_,
input_dimension(),
x,
false,
slice.size(),
class_b_t_);
//这里是对每一个sequence,计算输出层(class部分)的输出,共有slice.size()个sequence
activation_function_->Evaluate(num_classes_, slice.size(), class_b_t_);
//下一个输入word
class_b_t_ += GetOffset();
//输出层的word部分
#pragma omp parallel for
for (int i = 0; i < static_cast<int>(slice.size()); ++i) {
const int clazz = vocabulary_->GetClass(slice[i]),
class_size = vocabulary_->GetClassSize(clazz);
// shortlist class会被直接跳过
if (class_size > 1) {
//使用了偏置向量
if (class_bias_) {
//将word_bias_ + word_offset_[clazz]的前class_size个单位复制到word_b_t_ + i * max_class_size_
//这里作用就是为后面矩阵与向量相乘加上这部分偏置
FastCopy(word_bias_ + word_offset_[clazz],
class_size,
word_b_t_ + i * max_class_size_);
}
//完成的功能即:y <- ax + y,这里计算输出层word部分的输入
FastMatrixVectorMultiply(
word_weights_ + word_offset_[clazz] * input_dimension(), //要算的那部分word的起始地址,记为矩阵a
false, //a不转置
class_size, //a的行
input_dimension(), //a的列
x + i * input_dimension(), //x表示前一层的输出,这里记作列向量b,维度是input_dimension()
word_b_t_ + i * max_class_size_); //最后的相乘的结果保存在这儿,维度为class_size,记作y向量
//这里计算输出层word部分的输出
activation_function_->Evaluate(class_size, 1,
word_b_t_ + i * max_class_size_);
}
}
//下一个word,这里具体指向变换见图
word_b_t_ += GetOffset();
return result;
}
//Evaluate()和ComputeDelta()的执行顺序关系是:
//在一个batch内,对所有的sequence先执行Evaluate(),一直执行到sequence最后
//然后在执行ComputeDelta(),AddDelta(),这个时候从sequence最后往前一直计算到sequence开头
//slice里面装的是期望输出的word集合,该函数功能计算输出层的误差信号
void Output::ComputeDelta(const Slice &slice, FunctionPointer f) {
//std::cout << "This is in ComputeDelta in output.h\n";
class_b_t_ -= GetOffset();
word_b_t_ -= GetOffset();
//#pragma omp parallel for
for (int i = 0; i < static_cast<int>(slice.size()); ++i) {
const int clazz = vocabulary_->GetClass(slice[i]),
class_size = vocabulary_->GetClassSize(clazz);
//设置期望输出类别为1,其余是为0的
class_delta_t_[i * num_classes_ + clazz] = 1.;
// for (int m=i * num_classes_; m<num_classes_; m++) {
// std::cout << class_b_t_[m] << "\t";
// }
// std::cout << "\n";
if (class_size == 1)
continue;
//word_delta_t_期望输出词的定位是k = slice[i] - word_offset_[clazz] - shortlist_size_
//因为word的索引是按照word所属类别从小到大排列的,k表示当前word在它所在类别中的偏移位置
word_delta_t_[i * max_class_size_ + slice[i] - word_offset_[clazz] -
shortlist_size_] = 1.;
//输出层是softmax函数, 里面的函数是FastSub(b_t, dimension * batch_size, delta_t, delta_t);
//下面的代码完成功能是word_delta_t_ <= word_b_t_ - word_delta_t_
//这里计算的是输出层word部分的误差
//从这里也能看出来,目标函数就是最小化交叉熵
activation_function_->MultiplyDerivative(
class_size,
1,
word_b_t_ + i * max_class_size_,
word_delta_t_ + i * max_class_size_);
}
//这里计算输出层class部分的误差信号,和上面一样
//ps:这里最开始我看的时候白痴的把MultiplyDerivative()对应到sigmoid文件里面实现里面了,觉的怎么都不对
//纠结了好久,还跟作者发了邮件问了下,现在想来实在傻...
activation_function_->MultiplyDerivative(num_classes_, slice.size(),
class_b_t_, class_delta_t_);
}
//这个函数是计算输出层传到上一层的误差,放在delta_t里面
void Output::AddDelta(const Slice &slice, Real delta_t[]) {
//std::cout << "This is in AddDelta in output.h\n";
// class part
//将输出层class部分误差传到delta_t
//delta_t <- class_weights_^T * class_delta_t_
//delta_t是input_dimension() * slice.size()的
FastMatrixMatrixMultiply(1.0,
class_weights_,
true, //注意在使用转置时,下面指定行列的参数是指转置后的行列
input_dimension(),
num_classes_,
class_delta_t_,
false, //同样如此,如果这里为true,则后面指定矩阵的列时指转置后的列
slice.size(),
delta_t);
//下一个word,这里空间位置与实际的对应的word顺序应该是从sequence的最后往前面数
class_delta_t_ += GetOffset();
// word part
//将输出层word部分的误差传到上一层
#pragma omp parallel for
for (int i = 0; i < static_cast<int>(slice.size()); ++i) {
const int clazz = vocabulary_->GetClass(slice[i]),
class_size = vocabulary_->GetClassSize(clazz);
// shortlist class?
if (class_size == 1)
continue;
//c <= aT*b + c
FastMatrixVectorMultiply(
word_weights_ + word_offset_[clazz] * input_dimension(), //a
true,
class_size, // rows of A, not op(A)! //注意这个函数和上面的区别,如果这里取转置,对应的行列应该是矩阵未被转置时的行列
input_dimension(),
word_delta_t_ + i * max_class_size_, //b
delta_t + i * input_dimension()); //c
}
//下一个word
word_delta_t_ += GetOffset();
}
//x表示前一层的输出
//调整权值
const Real *Output::UpdateWeights(const Slice &slice,
const Real learning_rate,
const Real x[]) {
std::cout << "This is in UpdateWeights in output.h\n";
const Real *result = class_b_t_;
// class part
class_delta_t_ -= GetOffset();
if (class_bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
//b <= -learning_rate*a + b,即输出层的误差信号乘以负的学习率
FastMultiplyByConstantAdd(-learning_rate,
class_delta_t_ + i * num_classes_, //a
num_classes_,
momentum_class_bias_); //b
}
}
//c <= -alpha*a*x + c
//momentum_class_weights_是num_classes_ * input_dimension()的
//这里并未直接作用在class_weights_上,目前momentum_class_weights_保存的是改变的权值累计和
FastMatrixMatrixMultiply(-learning_rate, //-alpha
class_delta_t_, //a
false,
num_classes_,
slice.size(),
x,
true,
input_dimension(),
momentum_class_weights_); //c
class_b_t_ += GetOffset();
// word part
word_delta_t_ -= GetOffset();
for (size_t i = 0; i < slice.size(); ++i) {
const int clazz = vocabulary_->GetClass(slice[i]),
class_size = vocabulary_->GetClassSize(clazz);
if (class_size == 1)
continue;
if (class_bias_) {
//b <= -alpha*a + b 这里调整输出层word的偏置向量,这里我只是在翻译代码功能了,我觉的这里更新偏置向量的算法也不对
//有些地方我确实没弄明白,像上面整个代码都看不到计算输出层的误差,这里更新偏置也是比较不解,真心希望明白的朋友告知一下。
FastMultiplyByConstantAdd(-learning_rate, //-alpha
word_delta_t_ + i * max_class_size_, //a
class_size,
word_bias_ + word_offset_[clazz]); //b
}
//[]内表示矩阵的行列,a [size_x * size_y]<=alpha* x [size_x * 1] * y [1 * size_y]
//即 word_weights_ <= -learning_rate * word_delta_t_ * x
//这里调整输出部分word的权值
FastOuterProduct(
-learning_rate, //alpha
word_delta_t_ + i * max_class_size_, //x
class_size, //size_x
x + i * input_dimension(), //y
input_dimension(), //size_y
word_weights_ + word_offset_[clazz] * input_dimension()); //a
}
word_b_t_ += GetOffset();
return result;
}
//注意这里的执行顺序: 是先执行UpdateWeights所有后,才执行一次UpdateMomentumWeights
void Output::UpdateMomentumWeights(const Real momentum) {
std::cout << "This is in UpdateMomentumWeights in output.h\n";
//这里才调整class_weight的权值
//功能如下: c <= c + a
FastAdd(momentum_class_weights_, //a
num_classes_ * input_dimension(),
class_weights_, //c
class_weights_);
//a <= a*value,对于带有momentum更新参数的方式我不是太熟悉,所以这里也主要以翻译代码功能为主啦
//但是从代码完成的功能来看,我是这样理解的:class_weights的权重改变和先累加起来放在momentum_class_weights_
//累加到一定程度后,比如slice.size()后开始改变class_weights,所以单词叫momentum,有一种蓄势的感觉,然后
//不可能momentum_class_weights一直这样保存累加下去,momentum因子起了一定的缓冲作用。
FastMultiplyByConstant(momentum_class_weights_, //a
num_classes_ * input_dimension(), //size
momentum, //value
momentum_class_weights_); //a
//这里就是针对bias的了
if (class_bias_) {
FastAdd(momentum_class_bias_,
num_classes_,
class_bias_,
class_bias_);
FastMultiplyByConstant(momentum_class_bias_,
num_classes_,
momentum,
momentum_class_bias_);
}
}
//注意如果训练时的生成的结果模型没有删除,那么在执行相同命令时,会直接读取上次训练的结果
//并不会重新执行训练过程
void Output::Read(std::ifstream *input_stream) {
//std::cout << "This is in Read in output.h\n";
input_stream->read(reinterpret_cast<char *>(class_weights_),
num_classes_ * input_dimension() * sizeof(Real));
input_stream->read(reinterpret_cast<char *>(momentum_class_weights_),
num_classes_ * input_dimension() * sizeof(Real));
if (num_out_of_shortlist_words_ > 0) {
input_stream->read(
reinterpret_cast<char *>(word_weights_),
num_out_of_shortlist_words_ * input_dimension() * sizeof(Real));
}
if (class_bias_) {
input_stream->read(reinterpret_cast<char *>(class_bias_),
num_classes_ * sizeof(Real));
input_stream->read(reinterpret_cast<char *>(momentum_class_bias_),
num_classes_ * sizeof(Real));
if (num_out_of_shortlist_words_ > 0) {
input_stream->read(reinterpret_cast<char *>(word_bias_),
num_out_of_shortlist_words_ * sizeof(Real));
}
}
}
//slice是当前输入的期望输出,x表示输出层的输出,是经过sotfmax后的
//返回以e为底的对数概率值,这个是在一个slice上面对数概率累加
Real Output::ComputeLogProbability(const Slice &slice,
const Real x[],
const bool verbose,
ProbabilitySequenceVector *probabilities) {
//std::cout << "This is in ComputeLogProbability in output.h\n";
Real log_probability = 0.;
if (!slice.empty()) {
const int offset = num_classes_ * max_batch_size();
for (size_t i = 0; i < slice.size(); ++i) {
const int clazz = vocabulary_->GetClass(slice[i]),
class_size = vocabulary_->GetClassSize(clazz);
//类的概率,即p1(当前网络输入|期望输出词所属类)
Real probability = x[num_classes_ * i + clazz];
/*
assert(clazz < num_classes_);
assert(clazz >= 0);
const double z = std::accumulate(x + num_classes_ * i, x + num_classes_ * (i + 1), 0.);
assert(z > 0.99999 && z < 1.00001);
*/
if (vocabulary_->HasUnk() &&
slice[i] == vocabulary_->GetIndex(vocabulary_->unk()))
probability /= num_oovs_ + 1.; // <unk> may represent multiple words
log_probability += log(probability);
if (class_size > 1) {
//word的概率,即p2(当前网络输入,所属类别| 期望输出word)
const Real word_probability = x[offset + max_class_size_ * i +
slice[i] - word_offset_[clazz] -
shortlist_size_];
/*
const int start = offset + max_class_size_ * i,
word = slice[i] - word_offset_[clazz] - shortlist_size_;
assert(word >= 0);
assert(word < max_class_size_);
const double z = std::accumulate(x + start, x + start + max_class_size_, 0.);
assert(z > 0.99999 && z < 1.00001);
*/
//p(当前网络输入|期望输出词) = p1*p2 (p1,p2是上面的注释)
probability *= word_probability;
//对数概率,以e为底的,在这个函数内的累加和表示的是一个slice的累加
log_probability += log(word_probability);
}
if (probabilities) {
probabilities->at(i).push_back(probability);
}
if (verbose) {
std::cout << "\tp( " << vocabulary_->GetWord(slice[i]) <<
" | ... ) \t = [1gram] " << std::setprecision(8) <<
probability << " [ " << std::setprecision(5) <<
log(probability) / log(10.) << " ]\n";
}
}
}
return log_probability;
}
}















 1896
1896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









