







算法说明
这是一种利用动态规划思想实现的算法,也即是在运算过程中每一次计算都求出一个值,然后将这个值和前面计算的值比较,如果这个值比前面的值更加接近我们需要的结果则存储这个值,否则存储前面计算的值,这样在算法最后我就能得到最优结果。
算法优点
运算效率高
据说科学家DNA相似度的检测都是用这种算法
算法解析
以两个字符串为例,他们分别是“H ELLO”和“HALHELLO”
首先把他们分布在表格两边
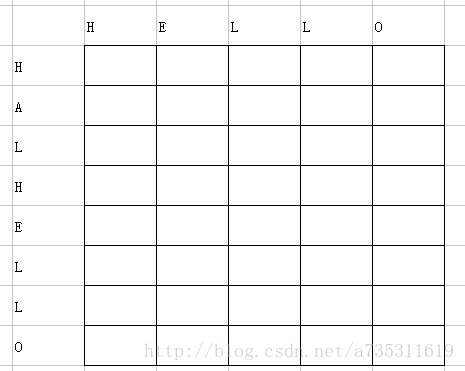
然后开始匹配表格中每一个格子他们对应的字母是否相等
如果相等:那么这个表格里就填一个他们左上角格子数字+1的数字,在这里我们把这个数字叫做”权值“。
如果不相等:我们就比较这个格子的上方和左的方格子的权值大小,谁的数字大当前这个格子就填哪个权值。
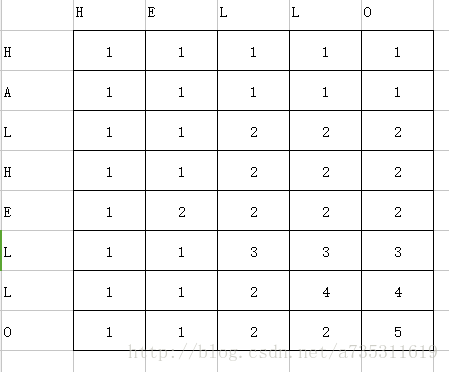
最后得到下表,我们可以明确的看到在最右下角权值是最大的,这个权值也就是两个字符串的最大权值(这个权值越大说明两个字符串的相似度越高)。
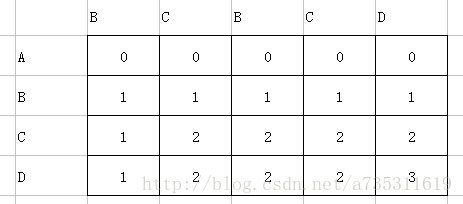
如果是列的数量大于行的数量的另外一种情况呢,最大的权值还会不会在最右下角?
答案是:YES
如下图所示
实现代码
以下是一个匹配字符串相似度的算法。
采用C++编写
#include<iostream>
#include<string>
using namespace std;
int main() {
string src1, src2;
src1 = "HELLO";
src2 = "HALHELLO";
//cin>>src1>>src2;
//先动态申请一个二维数组用来存储权值
int **grid = new int*[src1.length()+1]; //多申请一行(防止访问越界)
for (size_t i = 0; i < src1.length()+1;i++) {
grid[i] = new int[src2.length()+1];
}
//为了不影响正确的权值把多申请一行一列的权值赋值为0
for (size_t i = 0; i < src1.length()+1;i++) {
grid[i][0] = 0;
}
for (size_t i = 0; i < src2.length()+1; i++) {
grid[0][i] = 0;
}
//开始计算权值
for (size_t i = 1; i < src1.length()+1; i++)
{
for (size_t j = 1; j < src2.length()+1; j++)
{
//因为多申请了一行一列所以字符串要-1,否则访问越界
if (src1.at(i-1) == src2.at(j-1)) {
//相同时,取左上角的权值+1
grid[i][j] = grid[i - 1][j - 1] + 1;
}
else {
//当不相同时,上边和左边的权值谁大就取谁
if (grid[i-1][j] > grid[i][j-1])
{
grid[i][j] = grid[i - 1][j];
}
else {
grid[i][j] = grid[i][j-1];
}
}
}
}
//因为我们在申请内存的时候多申请了一行,所以length不用减1
cout << "两个字符串的最大权值为:" << grid[src1.length()][src2.length()] << endl;
return 0;
}运行结果
两个字符串的最大权值为:5














 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









