







下载地址
datax GitHub地址:https://github.com/alibaba/DataX.git
datax web Git地址:https://github.com/WeiYe-Jing/datax-web
datax 下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
datax web界面预览
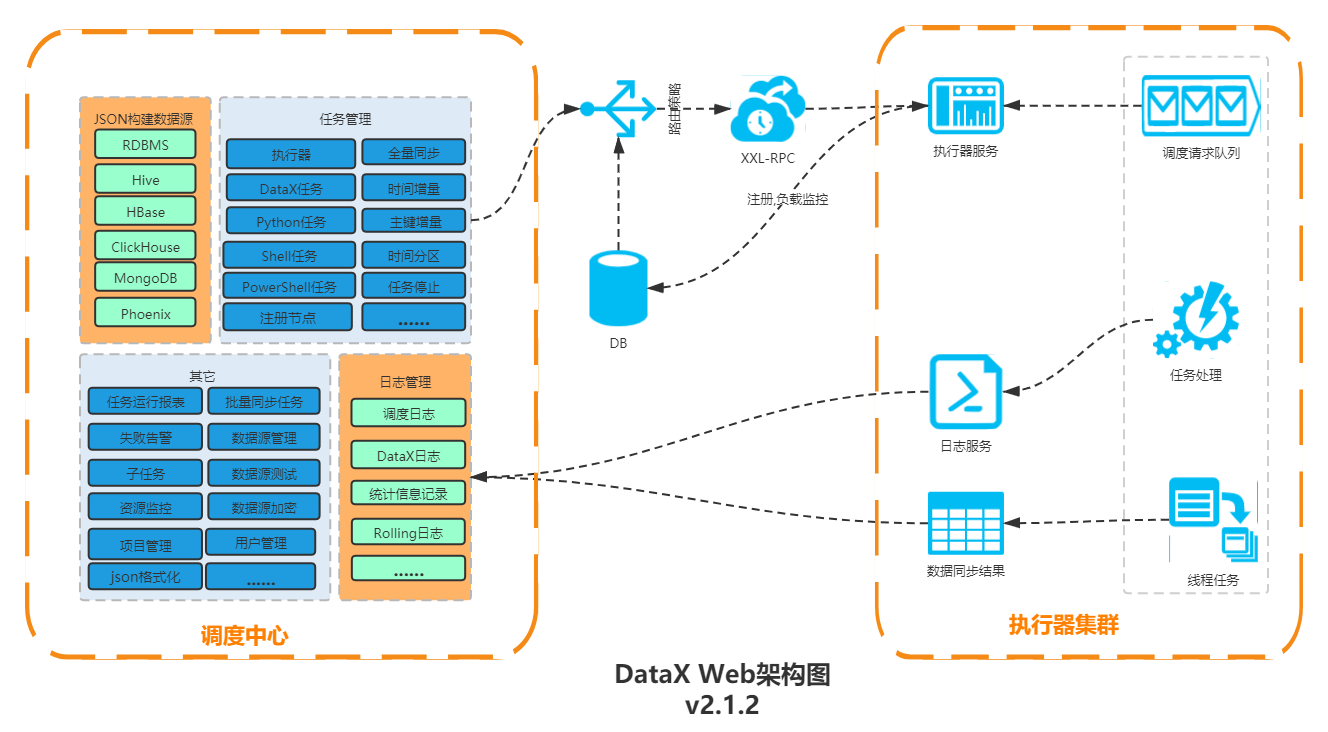
datax web架构图
DataX Web用户手册
一、github下载master分支或者release版本到本地
二、安装DataX
-
方法一、直接下载DataX工具包:DataX下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin $ python datax.py {YOUR_JOB.json}自检脚本:
python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json -
方法二、下载DataX源码,自己编译:DataX源码
(1)、下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git(2)、通过maven打包:
$ cd {DataX_source_code_home} $ mvn -U clean package assembly:assembly -Dmaven.test.skip=true打包成功,日志显示如下:
[INFO] BUILD SUCCESS [INFO] ----------------------------------------------------------------- [INFO] Total time: 08:12 min [INFO] Finished at: 2015-12-13T16:26:48+08:00 [INFO] Final Memory: 133M/960M [INFO] -----------------------------------------------------------------打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home} $ ls ./target/datax/datax/ bin conf job lib log log_perf plugin script tmp -
配置示例:从stream读取数据并打印到控制台
-
第一步、创建创业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
$ cd {YOUR_DATAX_HOME}/bin $ python datax.py -r streamreader -w streamwriter DataX (UNKNOWN_DATAX_VERSION), From Alibaba ! Copyright (C) 2010-2015, Alibaba Group. All Rights Reserved. Please refer to the streamreader document: https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document: https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and use python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json to run the job. { "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "column": [], "sliceRecordCount": "" } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "", "print": true } } } ], "setting": { "speed": { "channel": "" } } } }根据模板配置json如下:
#stream2stream.json { "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "sliceRecordCount": 10, "column": [ { "type": "long", "value": "10" }, { "type": "string", "value": "hello,你好,世界-DataX" } ] } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "UTF-8", "print": true } } } ], "setting": { "speed": { "channel": 5 } } } } -
第二步:启动DataX
$ cd {YOUR_DATAX_DIR_BIN} $ python datax.py ./stream2stream.json同步结束,显示日志如下:
... 2015-12-17 11:20:25.263 [job-0] INFO JobContainer - 任务启动时刻 : 2015-12-17 11:20:15 任务结束时刻 : 2015-12-17 11:20:25 任务总计耗时 : 10s 任务平均流量 : 205B/s 记录写入速度 : 5rec/s 读出记录总数 : 50 读写失败总数 : 0
-
三、Web部署
1.linux环境部署
2.开发环境部署(或参考文档 Debug)
2.1 创建数据库
执行bin/db下面的datax_web.sql文件(注意老版本更新语句有指定库名)
2.2 修改项目配置
1.修改datax_admin下resources/application.yml文件
#数据源
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
修改数据源配置,目前仅支持mysql
# 配置mybatis-plus打印sql日志
logging:
level:
com.wugui.datax.admin.mapper: error
path: ./data/applogs/admin
修改日志路径path
# datax-web email
mail:
host: smtp.qq.com
port: 25
username: xxx@qq.com
password: xxx
properties:
mail:
smtp:
auth: true
starttls:
enable: true
required: true
socketFactory:
class: javax.net.ssl.SSLSocketFactory
修改邮件发送配置(不需要可以不修改)
2.修改datax_executor下resources/application.yml文件
# log config
logging:
config: classpath:logback.xml
path: ./data/applogs/executor/jobhandler
修改日志路径path
datax:
job:
admin:
### datax-web admin address
addresses: http://127.0.0.1:8080
executor:
appname: datax-executor
ip:
port: 9999
### job log path
logpath: ./data/applogs/executor/jobhandler
### job log retention days
logretentiondays: 30
executor:
jsonpath: /Users/mac/data/applogs
pypath: /Users/mac/tools/datax/bin/datax.py
修改datax.job配置
- admin.addresses datax_admin部署地址,如调度中心集群部署存在多个地址则用逗号分隔,执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";
- executor.appname 执行器AppName,每个执行器机器集群的唯一标示,执行器心跳注册分组依据;
- executor.ip 默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 “执行器注册” 和 “调度中心请求并触发任务”;
- executor.port 执行器Server端口号,默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
- executor.logpath 执行器运行日志文件存储磁盘路径,需要对该路径拥有读写权限;
- executor.logretentiondays 执行器日志文件保存天数,过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
- executor.jsonpath datax json临时文件保存路径
- pypath DataX启动脚本地址,例如:xxx/datax/bin/datax.py
如果系统配置DataX环境变量(DATAX_HOME),logpath、jsonpath、pypath可不配,log文件和临时json存放在环境变量路径下。
四、启动项目
1.本地idea开发环境
- 1.运行datax_admin下 DataXAdminApplication
- 2.运行datax_executor下 DataXExecutorApplication
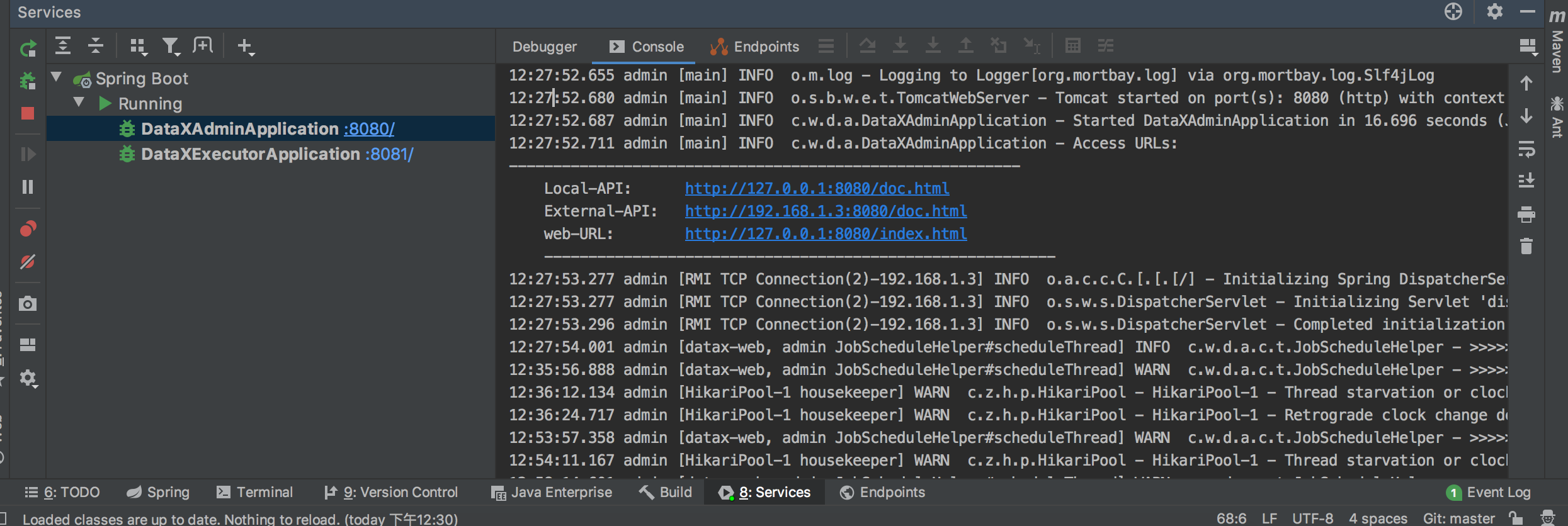
admin启动成功后日志会输出三个地址,两个接口文档地址,一个前端页面地址
五、启动成功
启动成功后打开页面(默认管理员用户名:admin 密码:123456)
http://localhost:8080/index.html#/dashboard
六、集群部署
- 调度中心、执行器支持集群部署,提升调度系统容灾和可用性。
-
1.调度中心集群:
DB配置保持一致;
集群机器时钟保持一致(单机集群忽视); -
2.执行器集群:
执行器回调地址(admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
同一个执行器集群内AppName(executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表。
常见问题
部署过程中遇到的常见问题,其解决方式可参考如下这篇博文:
https://blog.csdn.net/axq19910228/article/details/127730889



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











