







一:User-Agent
它在HTTP请求头部中,发起请求的时候,会把此字符串传递给服务器,服务器以此字符串判断是否是浏览器,许多网页通过User-Agent来禁止所有来自非浏览器的HTTP请求。
二:怎么才能刚好的实现爬虫呢?
当然是把人为的操作模拟的越像浏览器请求越好啦,如果一个账号频繁的发起请求,很有可能被怀疑是是爬虫机器,开发人员为了反正不法人员随意爬取数据会设置验证码,API接口的限制,网站对API接口限制一天只能访问指定的次数。
三:我们如何模仿的更加像浏览器访问网页呢?
①:访问频率不会非常高
②:使用浏览器进行访问
③:网站设置登录需求后仍能使用
④:访问网站可能有随机性,不会依照固定的某个规则或顺序访问网页
⑤:可以完成验证操作
⑥:模拟自然人访问频率,降低爬虫的访问频率,并且访问频率具有随机性。
⑦:把爬虫访问网页,变为从浏览器进行访问
⑧:请求网页时,随机切换不同的ip代理访问
⑨:对验证码进行识别操作
四:对以上问题开始逐步解决
关于settings.py的设置
CONCURRENT_REQUESTS :scrapy downloader 的并发请求的最大值,默认为16,我们可以减少一半左右。
DOWNLOAD_DELAY :爬取时间间隔,以秒为单位设置3到5秒即可。
CONCURRENT_REQUESTS_PER_DOMAIN:对单个网站进行的并发请求的最大值,默认为8。
CONCURRENT_REQUESTS_PER_IP:对单个ip进行并发请求的最大值,默认为0,我一般设置为8。
User-Agent: 可以在DEFAULT_REQUEST_HEADERS里面添加User-Agent字典,也可以直接在末尾添加USER_AGENT = ‘Mozilla/5.0…’
五:建立user-agent池
在settings.py中在DEFAULT_REQUEST_HEADERS中启用自定义的User-Agent中间件类,并且禁用Scrapy默认的User-Agent中间件
在middlewares.py文件中
from Scrapy import signals
import random
class RotateUserAgentMiddleware(object):
def process_request(self,request,spider):
this_ua=random.choice(self.ua)
request.headers['User-Agent']=this_ua
print(request.headers['User-Agent'])
ua=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# settings.py 文件中:
# 下载中间件
DOWNLOADER_MIDDLEWARES = {
'框架名.middlewares.RotateUserAgentMiddleware(上面定义的类名)': 543,
}
五:设置ip代理进行网络请求
使用HTTP代理技术通过代理IP去请求服务器。
流程:
1.在Request请求之前从IP池中随机选取一项设置为Request的IP
2.自定义MyproxiesSpiderMiddleware类,重写process_request()方法
3.在settings.py文件进行设置,在DOWNLOADER_MIDDLEWARES中启用自定义的 MyproxiesSpiderMiddleware类,和Scrapy默认的HTTP代理中间件类,并且前者要高于后者。
在Middlewares.py模块内:
from Scrapy import signals
import random
from Scrapy import signals
class MyproxiesSpiderMiddleware(objct):
def _init_(self,ip="):
self.ip = ip
def process_request(self,request,spider):
thisip=random.choice(self.IPPOOL)
print("this is ip:"+thisip["ipaddr"])
request.mata["proxy"]="http://"+thisip["ipaddr"]
IPPOOL=[
{"ipaddr":"110.52,235,74:9999"},
{"ipaddr":"58.55,129,204:9999"},
{"ipaddr":"113.13,160,102:9999"},
{"ipaddr":"219.228,126,86:8123"},
]
Settings.py模块
DOWNLOADER_MIDDLEWARES={
'Scrapy.contrid.downloadermiddleware.httpproxy.HttpProxyMiddleware':543,
'example2.middlewares.MyproxiesSpiderMiddleware':125
}
六:认识Cookie
一般什么时候用到cookie呢? 在遇到需要用户登录的网站(如果不登录就获取不到数据)在我们登录后网页会产生一个cookie,网站服务器会根据cookie识别用户信息和用户的状态。
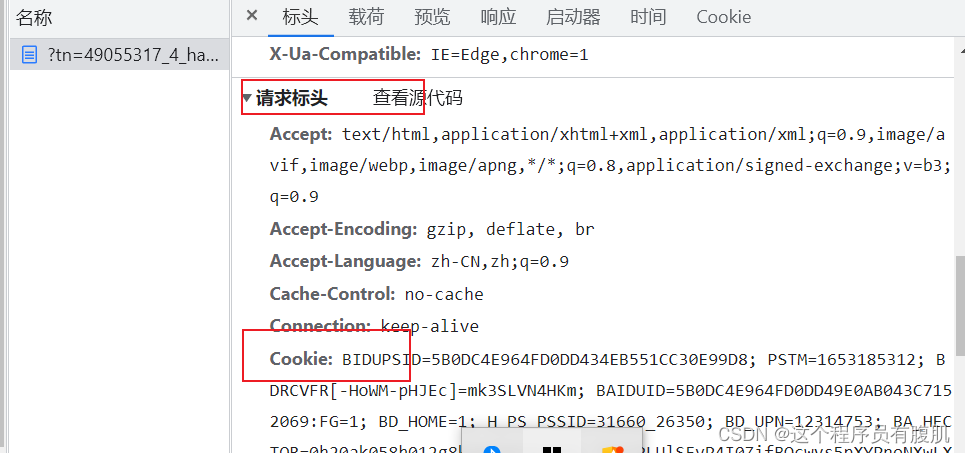
拿到cookie以后需要我们进行处理一下。
import random
# 先生成一个集合,通过遍历
def change_cookie_str_todict(cookie_str):
cookies = {} # 定义存储cookies的字典
print(cookie_str.split(';'))
for i in cookie_str.split(';'): # 去除';'号
key = i.split('=', 1)[0] # 以遇到的第一个 = 进行拆分
v = i.split('=', 1)[1] # 以遇到的第一个 =
cookies[key] = v
return cookies
print(change_cookie_str_todict("你的cookei")
在settings.py设置cookei值 ,在每个键对中通过”=“来区分key 和 valie
# 仅供参考
DEFAULT_COOKIE = {'_uab_collina': '165300331121038431984573',
' acw_tc': '76b20fec16530033085838226e0f625846551dfe4dba860e960aa34c2d9a24',
' guid': '7c35d8a387677cd9ee802279864765f3',
' nsearch': 'jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D',
' search': 'jobarea%7E%60000000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%B4%F3%CA%FD%BE%DD%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21',
' _ujz': 'MjA1OTU0MTgzMA%3D%3D',。。。。。。}
七:在爬虫文件中设置cookei
导入settings.py模块
from …settings import *
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











