







本文主要通过对两个浮点数组中的数据进行相加,并将其结果放入第三个数组中。其算法分别在CPU、GPU上分别执行,并比较了所需时间,强烈感受到GPU的并行计算能力。这里,每个数组的元素大小为30000000个。
一、实现代码
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <math.h>
// For the CUDA runtime routines (prefixed with "cuda_")
#include <cuda_runtime.h>
//该函数声明为了__global__,表示由GPU调用执行.
//其功能为将数组pA、pB中对应位置的数据相加,并将结果放入数组pC的对应位置上
//每个数组的索引大小为size
__global__
void add(const float * pA, const float * pB, float * pC, unsigned int size)
{
int index = blockIdx.x * blockDim.x + threadIdx.x; //计算当前数组中的索引
if (index < size) //确保是一个有效的索引
pC[index] = pA[index] + pB[index];
}
int main()
{
unsigned int numElement = 30000000;
int totalSize = sizeof(float)* numElement;
//init
float *pA = (float*)malloc(totalSize);
float *pB = (float*)malloc(totalSize);
float *pC = (float*)malloc(totalSize);
for (int i = 0; i < numElement; ++i)
{
*(pA + i) = rand() / (float)RAND_MAX;;
*(pB + i) = rand() / (float)RAND_MAX;
}
//cpu segment
//begin use cpu comput
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < numElement; ++i)
{
*(pC + i) = *(pA + i) + *(pB + i);
}
endTime = clock();
//end use cpu comput
printf("use cpu comput finish!\n");
printf("use total time = %fs\n", (endTime - startTime) / 1000.f);
printf("\n\n");
//gpu segment
float *pD, *pE, *pF;
cudaError_t err = cudaSuccess;
//malloc memory
err = cudaMalloc(&pD, totalSize);
if (err != cudaSuccess)
{
printf("call cudaMalloc fail for pD.\n");
exit(1);
}
err = cudaMalloc(&pE, totalSize);
if (err != cudaSuccess)
{
printf("call cudaMalloc fail for pE.\n");
exit(1);
}
err = cudaMalloc(&pF, totalSize);
if (err != cudaSuccess)
{
printf("call cudaMalloc fail for pF.\n");
exit(1);
}
//copy data from pA pB pC to pD pE pF
err = cudaMemcpy(pD, pA, totalSize, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
printf("call cudaMemcpy fail for pA to pD.\n");
exit(1);
}
err = cudaMemcpy(pE, pB, totalSize, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
printf("call cudaMemcpy fail for pB to pE.\n");
exit(1);
}
//begin use gpu comput
startTime = clock();
int threadPerBlock = 1024;
int numBlock = (numElement - 1) / threadPerBlock + 1;
add << <numBlock, threadPerBlock >> >(pD, pE, pF, numElement);
err = cudaGetLastError();
if (err != cudaSuccess)
{
printf("use gpu comput fail!\n");
exit(1);
}
endTime = clock();
printf("use gpu comput finish!\n");
printf("use time : %fs\n",(endTime - startTime) / 1000.f);
//end use gpu comput
//copu data from device to host
err = cudaMemcpy(pC, pF, totalSize, cudaMemcpyDeviceToHost);
if (err != cudaSuccess)
{
printf("call cudaMemcpy form pF to pC fail.\n");
exit(1);
}
//check data
for (int i = 0; i < numElement; ++i)
{
if (fabs(pA[i] + pB[i] - pC[i]) > 1e-5)
{
printf("%f + %f != %f\n",pA[i],pB[i],pC[i]);
}
}
//释放设备上的内存
cudaFree(pD);
cudaFree(pE);
cudaFree(pF);
//在程序退出前,调用该函数重置该设备,使驱动去清理设备状态,并且在程序退出前所有的数据将被刷出。
err = cudaDeviceReset();
if (err != cudaSuccess)
{
printf("call cudaDeviceReset fail!\n");
exit(1);
}
free(pA);
free(pB);
free(pC);
getchar();
return 0;
}二、运行结果
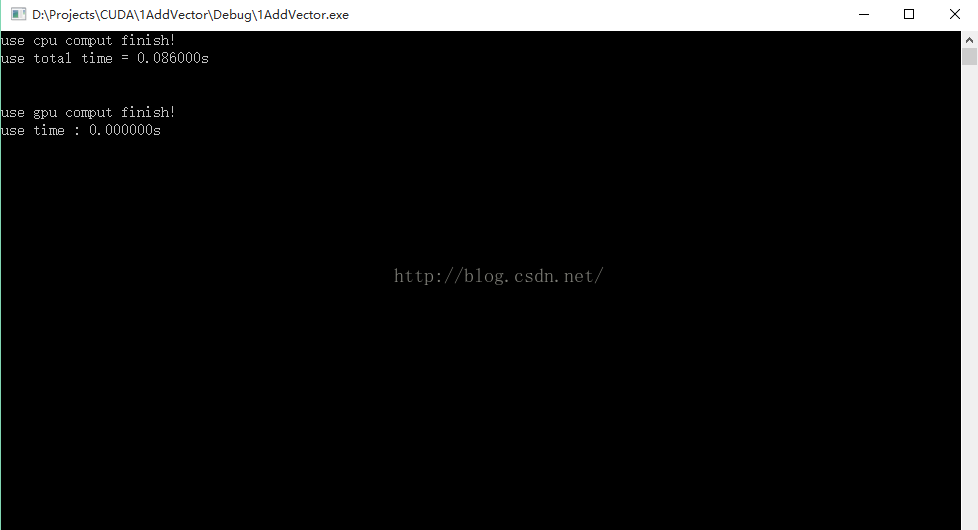
三、部分CUDA函数说明
1、cudaMalloc
__host__ cudaError_t cudaMalloc(void **devPtr, size_t size);
该函数主要用来分配设备上的内存(即显存中的内存)。该函数被声明为了__host__,即表示被host所调用,即在cpu中执行的代码所调用。
返回值:为cudaError_t类型,实质为cudaError的枚举类型,其中定义了一系列的错误代码。如果函数调用成功,则返回cudaSuccess。
第一个参数,void ** 类型,devPtr:用于接受该函数所分配的内存地址
第二个参数,size_t类型,size:指定分配内存的大小,单位为字节
2、cudaFree
__host__ cudaError_t cudaFree(void *devPtr);
该函数用来释放先前在设备上申请的内存空间(通过cudaMalloc、cudaMallocPitch等函数),注意,不能释放通过标准库函数malloc进行申请的内存。
返回值:为错误代码的类型值
第一个参数,void**类型,devPtr:指向需要释放的设备内存地址
3、cudaMemcpy
__host__ cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);
该函数主要用于将不同内存段的数据进行拷贝,内存可用是设备内存,也可用是主机内存
第一个参数,void*类型,dst:为目的内存地址
第二个参数,const void *类型,src:源内存地址
第三个参数,size_t类型,count:将要进行拷贝的字节大小
第四个参数,enum cudaMemcpyKind类型,kind:拷贝的类型,决定拷贝的方向
cudaMemcpyKind类型如下:
enum __device_builtin__ cudaMemcpyKind
{
cudaMemcpyHostToHost = 0, /**< Host -> Host */
cudaMemcpyHostToDevice = 1, /**< Host -> Device */
cudaMemcpyDeviceToHost = 2, /**< Device -> Host */
cudaMemcpyDeviceToDevice = 3, /**< Device -> Device */
cudaMemcpyDefault = 4 /**< Default based unified virtual address space */
}; ::cudaMemcpyHostToHost,
::cudaMemcpyHostToDevice,
::cudaMemcpyDeviceToHost,
::cudaMemcpyDeviceToDevice4、cudaDeviceReset
__host__ cudaError_t cudaDeviceReset(void);
该函数销毁当前进程中当前设备上所有的内存分配和重置所有状态,调用该函数达到重新初始该设备的作用。应该注意,在调用该函数时,应该确保该进程中其他host线程不能访问该设备!
Last:源程序下载地址















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









