







手写数据结构———-HashMap
百度百科解释
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代 collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
相信看上面的解释肯定有点懵逼,我们来总结下:
- 基于哈希表
- 允许使用 null 值和 null 键
- 不保证映射的顺序
- 提供基本的操作
我们来一张图来先认识下haspmap的结构:
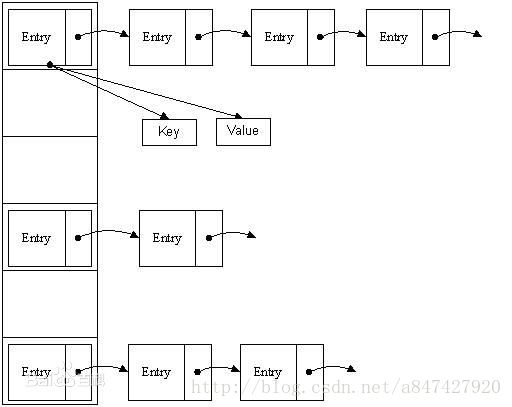
我们看到haspmap其实就是一个数组,每个数值又对应是一个单向链表。就这么简单,了解起来没有那么的难,但是也不要高兴的太早,因为写起来就不那么简单了,代码中涉及到一些小的算法,我们一起来看下吧!
想要实现haspmap数据结构,首先得先完成结构的组成元素。所以我们先实现基本的元素类StoneHashMapEntry:
/**
* hashmap 中的(链表)元素
* @param <K>
* @param <V>
*/
static class StoneHashMapEntry<K,V> implements Map.Entry<K,V>{
public K key;
public V value;
//hash值(数组下表)
public int hash;
//链表下一个元素
public StoneHashMapEntry next;
public StoneHashMapEntry(K key,V value, int hash,StoneHashMapEntry next){
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override
public int hashCode() {
return ((key==null)?0:key.hashCode())^((value==null)?0:value.hashCode());
}
@Override
public String toString() {
return "StoneHashMapEntry{" +
"key=" + key +
", value=" + value +
", hash=" + hash +
", next=" + next +
'}';
}
}
基本的元素类StoneHashMapEntry 中最主要的元素就是key(键),value(值),hash,next(指针,指向链表的下个元素)。
有了StoneHashMapEntry,我们继续来看HashMap:
public class StoneHashMap<K,V> {
//数值最小容量
private static final int MINIMUM_CAPACITY = 4;
//数值最大容量
private static final int MAXIMUM_CAPACITY = 1<<30;
//初始化数组
private static final Map.Entry[] EMPTY_TABLE = new StoneHashMapEntry[MINIMUM_CAPACITY>>1];
//元素个数
private int size;
//扩容阈值
private int threshold;
//数组
private StoneHashMapEntry<K,V>[] table;
//key 为null的元素
private StoneHashMapEntry<K,V> entryForNullKey;
public StoneHashMap(){
table = (StoneHashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1;
}
public StoneHashMap(int capacity){
if(capacity < 0 ){
throw new IllegalArgumentException("Capacity:"+capacity);
}
if(capacity == 0){
StoneHashMapEntry<K, V>[] tab = (StoneHashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if(capacity < MINIMUM_CAPACITY){
capacity = MINIMUM_CAPACITY;
}else if(capacity > MAXIMUM_CAPACITY){
capacity = MAXIMUM_CAPACITY;
}else {
//取大于且最接近capacity的2的幂
capacity = roundUpToPowerOfTwo(capacity);
}
makeTable(capacity);
}
//创建数值
private StoneHashMapEntry<K,V>[] makeTable(int capacity) {
StoneHashMapEntry<K,V>[] newTable = new StoneHashMapEntry[capacity];
table = newTable;
threshold = (capacity>>1) + (capacity>>2); //3/4
return newTable;
}
/**
* 获取值
* @param key
* @return
*/
public V get(Object key) {
if(key == null){
StoneHashMapEntry<K, V> entry = this.entryForNullKey;
return entry==null?null:entry.getValue();
}
int hash = secondaryHash(key.hashCode());
StoneHashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
StoneHashMapEntry<K, V> entry = tab[index];
for (StoneHashMapEntry<K,V> e=entry;e!=null;e=e.next){
if(key == e.key || (hash == e.hash && key.equals(e.key))){
return e.getValue();
}
}
return null;
}
/**
* 移除元素
* @param key
* @return
*/
public V remove(Object key) {
if (key == null) {
return removeNullKey();
}
int hash = secondaryHash(key.hashCode());
StoneHashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
StoneHashMapEntry<K, V> entry = tab[index];
//使用双指针,实现移除元素
for (StoneHashMapEntry<K,V> e=entry,prev = null;e!=null;prev=e, e=e.next ){
if((hash == e.hash && key.equals(e.key))){
if(prev == null){
tab[index] = e.next;
}else {
prev.next=e.next;
}
size--;
return e.getValue();
}
}
return null;
}
/**
* 移除key为null的元素
* @return
*/
private V removeNullKey() {
StoneHashMapEntry<K, V> e = entryForNullKey;
if (e == null) {
return null;
}
entryForNullKey = null;
size--;
return e.value;
}
/**
* 存值
* @param key
* @param value
* @return
*/
public V put(K key, V value){
if(key == null){
return putValueForNullKey(value);
}
StoneHashMapEntry<K,V>[] tab = table;
//二次hash增加离散概率
int hash = secondaryHash(key.hashCode());
//元素下标
int index = hash&(tab.length-1);
//遍历下标为index的链表
for (StoneHashMapEntry<K,V> entry = tab[index] ;entry!=null ;entry= entry.next){
if(entry.hash == hash && key.equals(entry.key)){
return entry.setValue(value);
}
}
//元素大于阈值,扩容
if(size++ > threshold ){
//扩容
tab = doubleCapacity();
//扩容后,下标重新计算
index = hash&(tab.length-1);
}
addNewEntry(key,value,hash,index);
return null;
}
public int size(){
return size;
}
/**
* 添加新元素
* @param key
* @param value
* @param hash
* @param index
*/
private void addNewEntry(K key, V value, int hash, int index) {
table[index] = new StoneHashMapEntry<>(key,value,hash,table[index]);
}
/**
* 扩容 核心
* @return
*/
private StoneHashMapEntry<K, V>[] doubleCapacity() {
StoneHashMapEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
if(oldCapacity == MAXIMUM_CAPACITY){
return oldTable;
}
int newCapacity = oldCapacity * 2;
StoneHashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if(size == 0){
return newTable;
}
Log.e("StoneHashMap","==========>扩容");
//对老的元素进行新的存储
for (int i = 0; i < oldCapacity; i++) {
StoneHashMapEntry<K, V> entry = oldTable[i];
if(entry == null){
continue;
}
//因为oldCapacity是2的幂(1000...),所以highBit要么是0,要么是oldCapacity
int highBit = entry.hash & oldCapacity;
//i 是 entry在老数组中的下标,所以highBit|i ,结果就是i或者是(oldCapacity+i)
//扩容后,减少原来数组中链表元素的个数,达到离散的目的
newTable[highBit | i] = entry;
//指向上一个指针,维护链表
StoneHashMapEntry<K, V> broken = null;
//entry指向前一个元素,e指向当前元素,双指针实现遍历,将元素链表分开
for(StoneHashMapEntry<K,V> e = entry.next ; e!=null;entry = e,e = e.next){
int nextHighBit = e.hash & oldCapacity;
if(nextHighBit != highBit){
if(broken == null){
//rg上面highBit | i 是i ,则这里就是 (oldCapacity+i)
newTable[i | nextHighBit] = e;
}else {
//链接上当前元素
broken.next=e;
}
//指向上一个指针
broken = entry;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}
return newTable;
}
//二次hash增加离散概率
private int secondaryHash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
/**
* 存key为null 的元素
* @param value
* @return
*/
private V putValueForNullKey(V value) {
StoneHashMapEntry<K,V> entry = entryForNullKey;
if(entry == null){
entryForNullKey = new StoneHashMapEntry<>(null,value,0,null);
size++;
return null;
}
return entryForNullKey.setValue(value);
}
//取大于且最接近capacity的2的幂
private int roundUpToPowerOfTwo(int i) {
i--;
i|=i>>>1;
i|=i>>>2;
i|=i>>>4;
i|=i>>>8;
i|=i>>>16;
return i++;
}
/**
* 存储结构
*/
public void showStorgeStructure(){
StoneHashMapEntry<K, V>[] tab = this.table;
for (int i = 0; i < tab.length; i++) {
StoneHashMapEntry<K, V> entry = tab[i];
Log.e("StoneHashMap","=========================================>"+i);
for (StoneHashMapEntry<K,V> e = entry;e != null;e = e.next){
Log.e("StoneHashMap","==========>"+e);
}
}
}
}
上面就是实现的方法,注释相对还是比较全的,下面我们来看下使用:
StoneHashMap<String,String> map =new StoneHashMap<>();
map.put("111","aaaa");
map.put("222","aaaa");
map.put("333","aaaa");
map.put("444","aaaa");
map.put("555","aaaa");
map.put("666","aaaa");
map.put("777","aaaa");
map.put("888","aaaa");
map.put("999","aaaa");
map.put("000","aaaa");
Log.e("MainActivity","=================>"+map.get("555")+"-----size:"+map.size());
//看存储结构
map.showStorgeStructure();














 1438
1438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









