






首先,让我们来全面了解一下这个项目。
项目名称:我们称之为“迅捷绿植”内部员工知识库问答系统。
项目背景:“迅捷绿植”是一个大型的在线绿植销售平台,它拥有自己的业务流程、规范以及针对员工的标准操作程序(SOP)手册。新员工在入职培训时会接收到这些信息,但这些信息往往分散在内部网站和人力资源(HR)部门的各个目录中,查询起来很不方便。有时,由于文档过于冗长,员工难以快速找到所需内容;有时,公司政策已经更新,但员工手中的文档还是旧版本。
基于这些需求,我们将开发一个基于内部知识手册的“Doc-QA”系统。这个系统将充分利用LangChain框架,处理员工手册中产生的各种问题。这个问答系统能够准确理解员工的问题,并基于最新的员工手册提供精确的答案。
项目及实现框架
开发框架:下面的图片展示了通过LangChain框架实现知识库文档系统的整体架构。
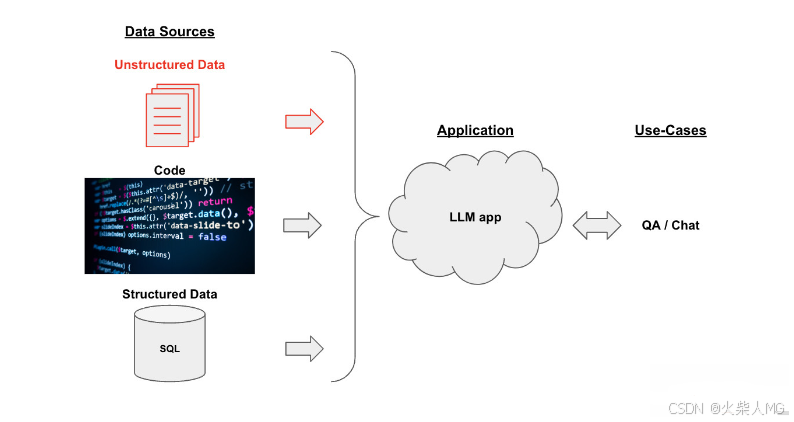
整个架构分为三个主要部分:
-
数据源(Data Sources):数据可以是多种形式的,包括非结构化数据(如PDF)、结构化数据(如SQL)以及代码(如Python、Java等)。在这个项目中,我们将重点关注非结构化数据的处理。
-
大模型应用(LLM App):以大模型为逻辑引擎,生成所需的回答。
-
用例(Use-Cases):大模型生成的回答可以用于构建QA系统、聊天机器人等。
核心实现机制:这个项目的核心实现机制是下面的数据处理管道(Pipeline)。
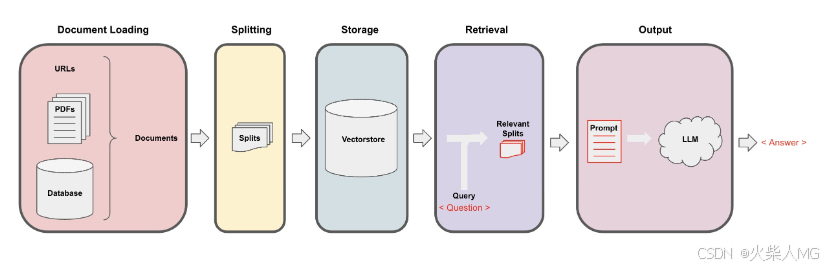
在这个管道的每一步中,LangChain都提供了相应的工具,让你能够轻松实现基于文档的问答功能。
具体流程分为以下五步:
-
加载(Loading):文档加载器将文档加载为LangChain能够读取的格式。
-
分割(Splitting):文本分割器将文档切割成指定大小的片段,我们称之为“文档块”或“文档片段”。
-
存储(Storage):将分割好的“文档块”以“嵌入”(Embedding)的形式存储到向量数据库(Vector DB)中,形成一个个的“嵌入片段”。
-
检索(Retrieval):应用程序从存储中检索分割后的文档(例如,通过比较余弦相似度找到与输入问题相似的嵌入片段)。
-
输出(Output):将问题和相似的嵌入片段传递给语言模型(LLM),使用包含问题和检索到的分割片段的提示生成答案。
数据的准备和载入
“迅捷绿植”的内部资料包括PDF、Word和TXT格式的文件。我们将使用LangChain中的document_loaders来加载这些不同格式的文本文件。在这一步中,我们将从PDF、Word和TXT文件中加载文本,并将这些文本存储在一个列表中。(注意:你可能需要安装PyPDF、python-docx等库来读取这些文件。)
以下是加载文档的示例代码:
import os
# 设置你的OpenAI API密钥(这里为了示例,我省略了具体的API密钥)
os.environ["OPENAI_API_KEY"] = '你的OpenAI API密钥'
# 导入文档加载器
from langchain.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoader
# 加载文档
base_dir = '.\GreenPlant' # 文档存放的目录
documents = []
for file in os.listdir(base_dir):
# 构建文件的完整路径
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path)
documents.extend(loader.load())首先,我们导入了OpenAI的API Key,这是因为后续我们将利用OpenAI的两种模型来完成关键任务:一是使用OpenAI的Embedding模型为文档生成嵌入表示;二是调用OpenAI的GPT模型来生成问答系统中的回答。值得一提的是,LangChain框架的灵活性极高,它不仅仅支持OpenAI的模型,你还可以根据需求,将Embedding模型和生成回答的语言模型替换为其他开源模型。
在运行相关程序时,除了需要正确配置OpenAI的API Key外,还需要确保安装了所有必要的工具包。LangChain在处理不同任务时,往往会依赖各种特定的工具包。例如,你提供的代码片段中就用到了PyPDF和Docx2txt等工具来加载不同格式的文档。如果程序运行时提示缺少某个包,只需通过pip install命令安装相应的包即可。
文本的分割
接下来,我们进入文本的分割阶段。这一步的目的是将加载的文本切割成更小的块,以便进行后续的嵌入和向量存储。在此,我们使用了LangChain提供的RecursiveCharacterTextSplitter来进行文本分割。
# 2. Split: 将Documents切分成块以便后续进行嵌入和向量存储
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 初始化文本分割器,设置块大小和重叠字符数
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
# 对文档进行分割
chunked_documents = text_splitter.split_documents(documents)现在,我们的文档已经被切割成了一个个大约200字符的文档块,并且这些块之间有一定的字符重叠,以确保信息的完整性。这一步是为了后续将这些文档块存储到向量数据库中做准备。
向量数据库存储
紧接着,我们将这些分割后的文本转换成嵌入的形式,并将其存储在一个向量数据库中。在这个例子中,我们使用了 OpenAIEmbeddings 来生成嵌入,然后使用 Qdrant 这个向量数据库来存储嵌入(这里需要pip install qdrant-client)。
如果文本的“嵌入”这个概念对你来说有些陌生的话,你可以看一下下面的说明。
文本的“嵌入”在自然语言处理和机器学习领域中,指的是将文本(如单词、短语、句子或整个文档)转换为一个固定长度的连续向量表示。这个向量通常是一个高维空间中的点,其中向量的每个维度都代表文本某种特定的特征或属性。
嵌入的目的是为了捕捉文本之间的语义关系。在嵌入空间中,语义上相似或相关的文本会被映射到相近的位置,即它们的向量表示之间的距离(如欧氏距离或余弦距离)会相对较小。相反,语义上不相关的文本则会被映射到较远的位置。
嵌入技术通常基于深度学习模型进行训练,这些模型会学习如何将文本映射到嵌入空间中。训练过程中,模型会尝试最小化一个损失函数,该函数衡量了模型生成的嵌入向量与真实语义关系之间的不一致性。
对于单词嵌入,一个著名的例子是Word2Vec,它通过学习单词的上下文来生成单词的向量表示。对于句子或文档嵌入,则可以使用更复杂的模型,如BERT、GPT系列模型等,这些模型能够捕捉更丰富的语义信息。
一旦生成了嵌入,它们就可以被用于各种自然语言处理任务中,如文本分类、情感分析、机器翻译、问答系统等。在这些任务中,嵌入通常作为输入特征被提供给机器学习模型,以帮助模型更好地理解文本数据并做出准确的预测或生成。
相关信息的获取
当内部文档存储到向量数据库之后,我们需要根据问题和任务来提取最相关的信息。此时,信息提取的基本方式就是把问题也转换为向量,然后去和向量数据库中的各个向量进行比较,提取最接近的信息。
向量之间的比较通常基于向量的距离或者相似度。在高维空间中,常用的向量距离或相似度计算方法有欧氏距离和余弦相似度。
- 欧氏距离:这是最直接的距离度量方式,就像在二维平面上测量两点之间的直线距离那样。在高维空间中,两个向量的欧氏距离就是各个对应维度差的平方和的平方根。
- 余弦相似度:在很多情况下,我们更关心向量的方向而不是它的大小。例如在文本处理中,一个词的向量可能会因为文本长度的不同,而在大小上有很大的差距,但方向更能反映其语义。余弦相似度就是度量向量之间方向的相似性,它的值范围在-1到1之间,值越接近1,表示两个向量的方向越相似。
这两种方法都被广泛应用于各种机器学习和人工智能任务中,选择哪一种方法取决于具体的应用场景。
欧式距离,作为度量空间中两点间绝对距离的指标,它直接反映了向量在各个维度上的绝对差异。因此,当我们需要关注数据的具体数值大小时,欧式距离是一个合适的选择。比如,在物品推荐系统中,用户的购买量、评分等具体数值可能直接反映了他们的偏好强度,此时使用欧式距离可以更准确地衡量用户之间的偏好差异。
然而,在很多自然语言处理和机器学习任务中,我们更关心的是数据的方向和语义相似性,而不是具体的数值大小。这时,余弦相似度就成了一个更好的选择。余弦相似度通过计算两个向量的夹角的余弦值来度量它们的相似性,它更关注的是向量的方向而不是大小。在处理文本数据或其他高维稀疏数据时,余弦相似度特别有用,因为文本数据通常被表示为高维的词向量,而这些词向量的方向更能反映其语义相似性。
总的来说,选择欧式距离还是余弦相似度,取决于我们关注的数据特性和任务需求。在实际应用中,我们可以通过实验和对比来选择最合适的度量方法。
在这里,我们正在处理的是文本数据,目标是建立一个问答系统,需要从语义上理解和比较问题可能的答案。因此,我建议使用余弦相似度作为度量标准。通过比较问题和答案向量在语义空间中的方向,可以找到与提出的问题最匹配的答案。
在这一步的代码部分,我们会创建一个聊天模型。然后需要创建一个 RetrievalQA 链,它是一个检索式问答模型,用于生成问题的答案。
在RetrievalQA 链中有下面两大重要组成部分
- LLM是大模型,负责回答问题。
- retriever(vectorstore.as_retriever())负责根据问题检索相关的文档,找到具体的“嵌入片”。这些“嵌入片”对应的“文档块”就会作为知识信息,和问题一起传递进入大模型。本地文档中检索而得的知识很重要,因为从互联网信息中训练而来的大模型不可能拥有“迅捷绿植”作为一个私营企业的内部知识。
# 4. Retrieval 准备模型和Retrieval链 importlogging# 导入Logging工具 from langchain.chat_models import ChatOpenAI # ChatOpenAI模型 from langchain.retrievers.multi_query import MultiQueryRetriever # MultiQueryRetriever工具 from langchain.chains import RetrievalQA # RetrievalQA链 # 设置Logging logging.basicConfig() logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO) # 实例化一个大模型工具 - OpenAI的GPT-3.5 llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) # 实例化一个MultiQueryRetriever retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm) # 实例化一个RetrievalQA链 qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)生成回答并展示
这一步是问答系统应用的主要UI交互部分,这里会创建一个 Flask 应用(需要安装Flask包)来接收用户的问题,并生成相应的答案,最后通过 index.html 对答案进行渲染和呈现。
在这个步骤中,我们使用了之前创建的 RetrievalQA 链来获取相关的文档和生成答案。然后,将这些信息返回给用户,显示在网页上。
# 5. Output 问答系统的UI实现 from flask import Flask, request, render_template app = Flask(__name__) # Flask APP @app.route('/', methods=['GET', 'POST']) def home(): if request.method == 'POST': # 接收用户输入作为问题 question = request.form.get('question') # RetrievalQA链 - 读入问题,生成答案 result = qa_chain({"query": question}) # 把大模型的回答结果返回网页进行渲染 return render_template('index.html', result=result) return render_template('index.html') if __name__ == "__main__": app.run(host='0.0.0.0',debug=True,port=5000)相关HTML网页的关键代码如下:
<body> <div class="container"> <div class="header"> <h1>迅捷绿植内部问答系统</h1> <img src="{{ url_for('static', filename='flower.png') }}" alt="flower logo" width="200"> </div> <form method="POST"> <label for="question">Enter your question:</label><br> <input type="text" id="question" name="question"><br> <input type="submit" value="Submit"> </form> {% if result is defined %} <h2>Answer</h2> <p>{{ result.result }}</p> {% endif %} </div> </body>运行程序之后,我们跑起一个网页 http://127.0.0.1:5000/。与网页进行互动时,可以发现,问答系统完美生成了专属于迅捷绿植内部资料的回答。

















 1978
1978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









