






LangChain的基本安装特别简单。
pip install langchain这是安装 LangChain 的最低要求。这里我要提醒你一点,LangChain 要与各种模型、数据存储库集成,比如说最重要的OpenAI的API接口,比如说开源大模型库HuggingFace Hub,再比如说对各种向量数据库的支持。默认情况下,是没有同时安装所需的依赖项。
也就是说,当你 pip install langchain 之后,可能还需要 pip install openai、pip install chroma(一种向量数据库)……
用下面两种方法,我们就可以在安装 LangChain 的方法时,引入大多数的依赖项。
安装LangChain时包括常用的开源LLM(大语言模型) 库:
pip install langchain安装完成之后,还需要更新到 LangChain 的最新版本,这样才能使用较新的工具。
pip install langchain如果你想从源代码安装,可以克隆存储库并运行:
pip install langchainOpenAI API
当然,要使用OpenAI API,你需要先用科学的方法进行注册,并得到一个API Key。
有了OpenAI的账号和Key,你就可以在面板中看到各种信息,比如模型的费用、使用情况等。下面的图片显示了各种模型的访问数量限制信息。其中,TPM和RPM分别代表tokens-per-minute、requests-per-minute。也就是说,对于GPT-4,你通过API最多每分钟调用200次、传输40000个字节。
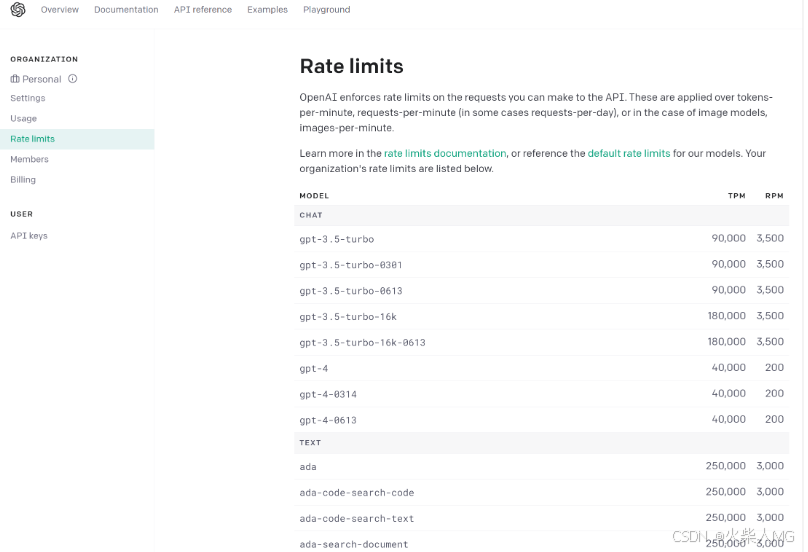
这里,我们需要重点说明的两类模型,就是图中的Chat Model和Text Model。这两类Model,是大语言模型的代表。当然,OpenAI还提供Image、Audio和其它类型的模型,目前它们不是LangChain所支持的重点,模型数量也比较少。
- Chat Model,聊天模型,用于产生人类和AI之间的对话,代表模型当然是gpt-3.5-turbo(也就是ChatGPT)和GPT-4。当然,OpenAI还提供其它的版本,gpt-3.5-turbo-0613代表ChatGPT在2023年6月13号的一个快照,而gpt-3.5-turbo-16k则代表这个模型可以接收16K长度的Token,而不是通常的4K。(注意了,gpt-3.5-turbo-16k并未开放给我们使用,而且你传输的字节越多,花钱也越多)
- Text Model,文本模型,在ChatGPT出来之前,大家都使用这种模型的API来调用GPT-3,文本模型的代表作是text-davinci-003(基于GPT3)。而在这个模型家族中,也有专门训练出来做文本嵌入的text-embedding-ada-002,也有专门做相似度比较的模型,如text-similarity-curie-001。
上面这两种模型,提供的功能类似,都是接收对话输入(input,也叫prompt),返回回答文本(output,也叫response)。但是,它们的调用方式和要求的输入格式是有区别的
调用Text模型
第1步,先注册好你的API Key。
第2步,用 pip install openai 命令来安装OpenAI库。
第3步,导入 OpenAI API Key。
导入API Key有多种方式,其中之一是通过下面的代码:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'OpenAI库就会查看名为OPENAI_API_KEY的环境变量,并使用它的值作为API密钥。
也可以像下面这样先导入OpenAI库,然后指定api_key的值。
import openai
openai.api_key = '你的Open API Key'或者在操作系统中定义环境变量,比如在Linux系统的命令行中使用:
export OPENAI_API_KEY='你的Open API Key' 第4步,导入OpenAI库,并创建一个Client。
from openai import OpenAI
client = OpenAI()第5步,指定 gpt-3.5-turbo-instruct(也就是 Text 模型)并调用 completions 方法,返回结果。
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
temperature=0.5,
max_tokens=100,
prompt="请给我的公司起个名")第6步,打印输出大模型返回的文字。
print(response.choices[0].text.strip())调用Chat模型
整体流程上,Chat模型和Text模型的调用是类似的,只是前面加了一个chat,然后输入(prompt)和输出(response)的数据格式有所不同。
示例代码如下
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a creative AI."},
{"role": "user", "content": "请给我的花店起个名"},
],
temperature=0.8,
max_tokens=60
)这段代码中,除去刚才已经介绍过的temperature、max_tokens等参数之外,有两个专属于Chat模型的概念,一个是消息,一个是角色!
先说消息,消息就是传入模型的提示。此处的messages参数是一个列表,包含了多个消息。每个消息都有一个role(可以是system、user或assistant)和content(消息的内容)。系统消息设定了对话的背景(你是一个很棒的智能助手),然后用户消息提出了具体请求(请给我的花店起个名)。模型的任务是基于这些消息来生成回复。
再说角色,在OpenAI的Chat模型中,system、user和assistant都是消息的角色。每一种角色都有不同的含义和作用。
- system:系统消息主要用于设定对话的背景或上下文。这可以帮助模型理解它在对话中的角色和任务。例如,你可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的AI助手。系统消息通常在对话开始时给出。
- user:用户消息是从用户或人类角色发出的。它们通常包含了用户想要模型回答或完成的请求。用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。
- assistant:助手消息是模型的回复。例如,在你使用API发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文。然而,请注意在对话的最后一条消息应始终为用户消息,因为模型总是要回应最后这条用户消息。
在使用Chat模型生成内容后,返回的响应,也就是response会包含一个或多个choices,每个choices都包含一个message。每个message也都包含一个role和content。role可以是system、user或assistant,表示该消息的发送者,content则包含了消息的实际内容。
一个典型的response对象可能如下所示:
{
'id': 'chatcmpl-2nZI6v1cW9E3Jg4w2Xtoql0M3XHfH',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-4',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': '你的花店可以叫做"花香四溢"。'
},
'finish_reason': 'stop',
'index': 0
}
]
}通过LangChain调用Text和Chat模型
调用Text模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.llms import OpenAI
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0.8,
max_tokens=60,)
response = llm.predict("请给我的花店起个名")
print(response)这只是一个对OpenAI API的简单封装:先导入LangChain的OpenAI类,创建一个LLM(大语言模型)对象,指定使用的模型和一些生成参数。使用创建的LLM对象和消息列表调用OpenAI类的__call__方法,进行文本生成。生成的结果被存储在response变量中。没有什么需要特别解释之处。
调用Chat模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model="gpt-4",
temperature=0.8,
max_tokens=60)
from langchain.schema import (
HumanMessage,
SystemMessage
)
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="请给我的花店起个名")
]
response = chat(messages)
print(response)通过导入LangChain的ChatOpenAI类,创建一个Chat模型对象,指定使用的模型和一些生成参数。然后从LangChain的schema模块中导入LangChain的SystemMessage和HumanMessage类,创建一个消息列表。消息列表中包含了一个系统消息和一个人类消息。你已经知道系统消息通常用来设置一些上下文或者指导AI的行为,人类消息则是要求AI回应的内容。之后,使用创建的chat对象和消息列表调用ChatOpenAI类的__call__方法,进行文本生成。生成的结果被存储在response变量中。

















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









