






存储器的层次结构
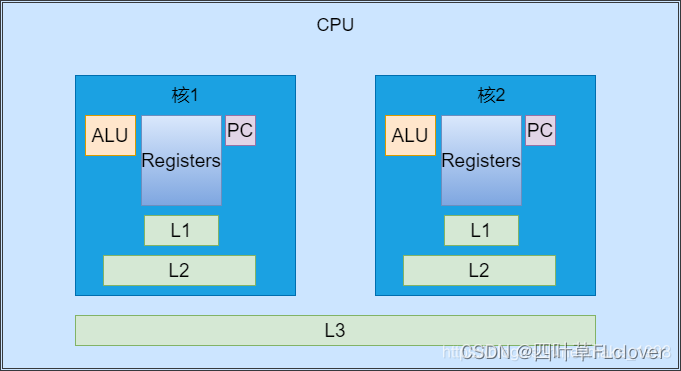
当使用一个程序,程序从硬盘中加载到内存当中,然后CPU将程序中的下一条指令地址读取到PC中,然后将相关数据存储到Registers(寄存器)中。
-
PC (Program Counter 程序计数器)
记录这一个地址存放下一条执行的指令在哪里,cpu执行完一条就去内存取下一条。 -
Register寄存器
执行指令中的数据放到CPU执行,存储数据的就是寄存器 -
ALU(Arithmetic Logic Unit)运算单元
数据放到寄存器之后使用运算单元alu来运算,运算完写回到寄存器,寄存器再写回到内存里面去。
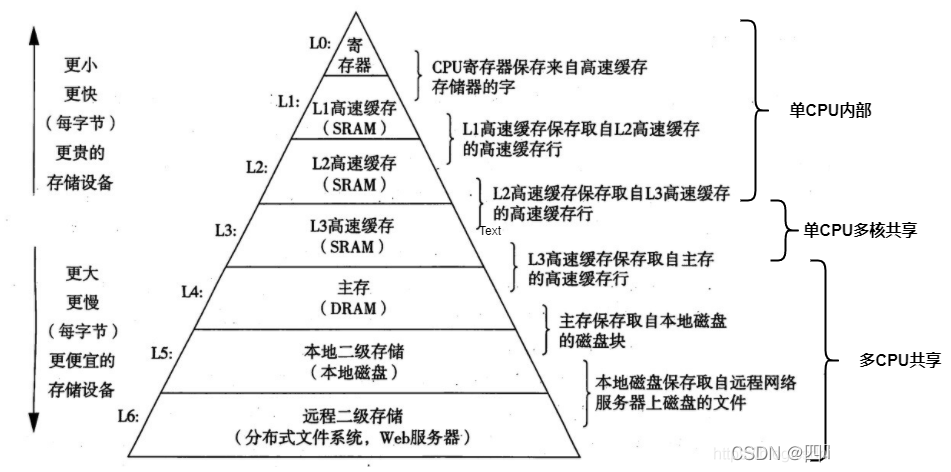
计算机从磁盘读取到CPU中的过程很慢,所以我们的计算机中有好几层存储结构,会将磁盘中的数据进行缓存,而不是每次都重新读取。
存储器的层次结构
| 存储器 | 访问时间 |
|---|---|
| 寄存器 | 1个周期 <1ns |
| L1 | ~3个周期 ~1ns |
| L2 | ~12个周期 ~3ns |
| L3 | ~38个周期 ~12ns |
| 主存 | >100个周期 ~65ns |
寄存器、L1、L2数据由CPU单核独占
L3数据在同个CPU内部多核共享
L4、L5、L6数据由CPU共享
有数据共享,必然有数据一致性问题,一般使用缓存一致性协议+总线锁的方式来保证多线程访问时CPU的数据一致性。
注:大多数情况使用缓存一致性协议,缓存一致性协议处理不了的情况就会使用总线锁的方式。
缓存一致性协议:补充链接
总线锁:补充链接
缓存行(cache line)
什么是缓存行
Cache中的数据是按块读取的,当CPU访问某个数据时,会假设该数据附近的数据以后会被访问到,因此,第一次访问这一块区域时,会将该数据连同附近区域的数据(共64字节)一起读取进缓存中,那么这一块数据称为一个Cache Line 缓存行。
缓存系统是以缓存行为单位存储的。目前主流的CPU Cache的Cache Line大小都是64字节。
注: 并不是所有数据都会被缓存,比如一些较大的数据,缓存行无法容下,那么就只能每次都去主内存中读取。
什么是伪共享
定义
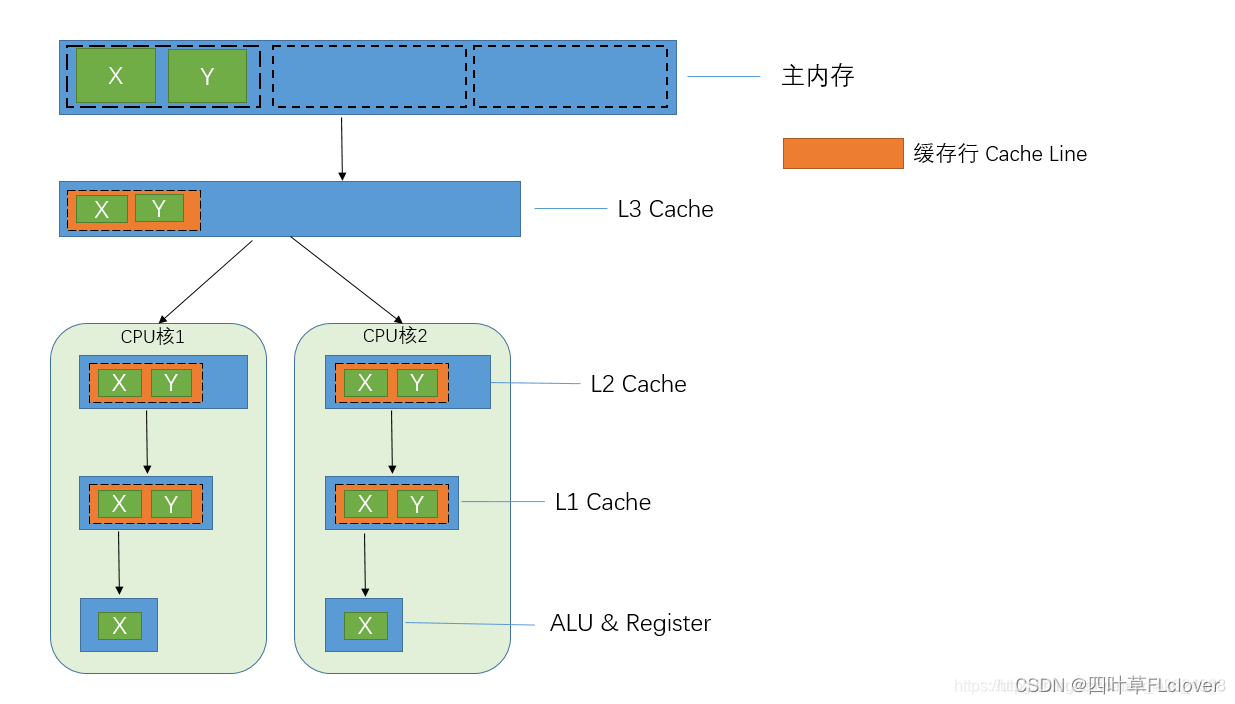
缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
如上图所示:一个缓存行中含有变量X、Y,若CPU1中有线程频繁修改X,CPU2中有线程频繁修改Y。由于缓存一致性协议,当其中一个CPU中的变量X或Y修改后,会使另一个CPU中的L1、L2缓存行的数据失效,需要重新取读取。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
因此,当两个以上CPU都要访问同一个缓存行大小的内存区域时,就会引起冲突,这种情况就叫“伪共享”
如何解决伪共享带来的竞争冲突
追加字节使缓存行对齐:以一个缓存行64字节为例,例如下面代码使用了15个无用变量p0~pe(一个Object占4个字节)追加到了64个字节,使X一定不会和其他变量(例如Y)在同一个缓存行中,这样就有效的解决了伪共享带来的竞争冲突。
注:只有频繁写需要做这种优化,读多写少的情况不需要做优化,毕竟追加字节增加了内存空间的开销。
static final class PaddedAtomicReference <T> extends <AtomicReference T> {
Object X;
// 使用很多4个字节的引用追加到64个字节
Object p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;
PaddedAtomicReference(T r) {
super(r);
}
}
CPU乱序执行
CPU在进行读等待的同时执行指令,是CPU乱序的根源。不是乱,而是提高效率。
CPU在执行A指令的时候,指令B也在执行,甚至B指令执行完了A指令还在执行。例如:A指令去内存读数据,等待返回期间,B指令可以优先执行。(AB指令不能存在依赖关系,可以提升效率)
CPU合并写技术:https://www.cnblogs.com/liushaodong/p/4777308.html
如何保证特定情况下不乱序
硬件内存屏障 X86
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









