







 本文深入探讨了缓存与内存管理的重要概念和技术细节,包括CPU密集型与IO密集型的区别,缓存一致性的原理,以及如何通过缓存行填充等方式避免伪共享。
本文深入探讨了缓存与内存管理的重要概念和技术细节,包括CPU密集型与IO密集型的区别,缓存一致性的原理,以及如何通过缓存行填充等方式避免伪共享。
Cpu密集型 & IO密集型
- Cpu密集型也叫计算密集型: 在系统运行期间,性能瓶颈主要在Cpu,此时Cpu高负载或高使用率。通常在加解密等大量复杂运算场景。
- IO密集型:此时性能瓶颈受限制于硬盘/内存的IO读写,没有充分利用Cpu能力。此时线程的空闲时间多,可以适当提高线程数。
IO密集型核心线程数 = Cpu核数 / (1- 阻塞系数)
Cpu密集型核心线程数 = Cpu核数
阻塞系数 = Cpu等待时间 : Cpu总时间 , 通常会假定: " 等待时间 : 运行时间 = 1 : 1 ",
所以: 线程数 = 2 * Cpu 核心数。(也有文章说要: 2 * Cpu核心数 + 1)。
// java获取核心数
Runtime.getRuntime().availableProcessors()为什么要缓存
在系统工程中, 无论是在数据库、系统内存等对于数据的访问,通常存在部分数据在时间上、空间上大概率的再次访问现象 ,所谓的二八原则
- 时间局部性现象。 如果一个主存数据正在被访问,那么在近期它被再次访问的概率非常大。 80%的时间在运行20% 的代码
- 空间局部性现象。CPU使用到某块内存区域数据,这块内存区域后面临近的数据很大概率立即会被使用到。 例如数组、集合经常会顺序访问(内存地址连续或邻近)。
因此, 缓存能大大提高热数据的访问效率。
Linux内核的文件预读readahead
由于磁盘的访问更慢,所以一般从磁盘中拿数据不是按需,而是按页预读,一次会读一页的数据,每次加载更多的数据,如果未来要读取的数据就在此页中,可以避免未来的磁盘IO,提高效率 。
操作系统一页数据是4K,MySQL的一页是16K
高速缓存
最快是 CPU 的寄存器 :指令寄存器(IR)、程序计数器(PC)、地址寄存器(AR)、数据寄存器(DR)等。
其次是 CPU 的高速缓存。由近到远分为L1缓存 -> L2缓存 ->L3缓存,离得越远,速度越慢,容量越大。
- 每核心都有一个私有的 L1 缓存,但对同核内的多线程是共享的。
- 大多数多核 CPU 的各核都各自拥有一个 L2 缓存,但也有多核共享 L2 缓存的设计;
- L3 在现代多核机器中更普遍,更大,更慢,并且被单个插槽上的所有 CPU 核共享 。
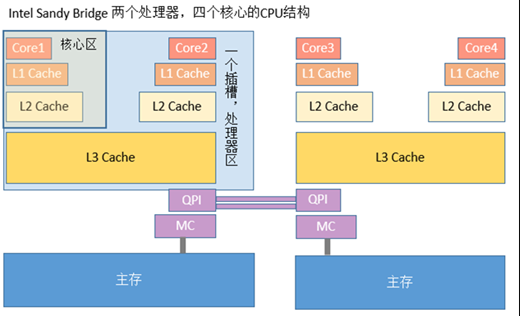
缓存一致性
当 Cpu执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后再去主内存拿。走得越远,运算耗费的时间就越长。所以如果需更快的处理,要确保数据在 L1 缓存中。
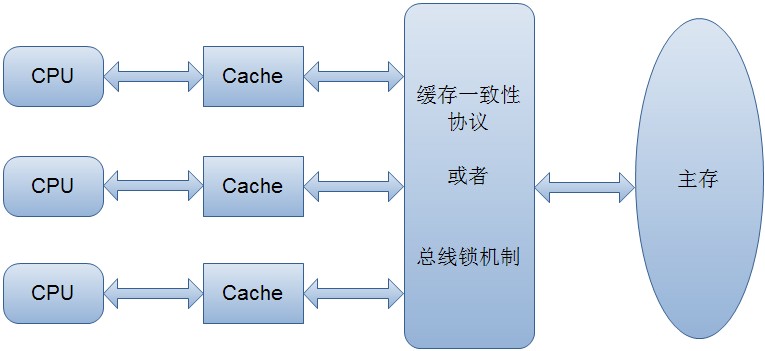
总线负责了Cpu与外设的通讯。在多核Cpu架构上,它们共用一条总线的来和主内存进行数据交互。
当多个线程访问的变量为共享变量(主存中)时,因每个线程栈都存在私有的 Cpu 缓存变量副本,就不可避免会遇到缓存一致性问题 。
于是就出现了缓存一致性协议,最出名的就是 Intel 的 MESI 协议。MESI 协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是: modified(修改)、exclusive(互斥)、share(共享)、invalid(无效)。
简单的说:写能同步更新到主存中,其他线程再读时,缓存副本失效需要从主存中拿更新后的数据。
- CPU1 使用共享数据时会先数据拷贝到 CPU1 缓存中,然后置为独占状态 (E)
- 这时 CPU2 也使用了共享数据,也会拷贝也到 CPU2 缓存中。通过总线嗅探机制,当该 CPU1 监听总线中 CPU2 对内存中共享变量也拷贝了,此时共享变量在 CPU1 和 CPU2 两个缓存中的状态会被标记为共享状态 (S);
- 若 CPU1 将变量通过缓存回写到主存中,需要先锁住缓存行,此时状态切换为修改(M),向总线发消息告诉其他在嗅探的 CPU 该变量已经被 CPU1 改变并回写到主存中。接收到消息的其他 CPU 会将共享变量状态从(S)改成无效状态(I),缓存行失效。
- 此时若其他 CPU 需要再次操作共享变量则需要重新从内存读取。
解决缓存不一致性问题的方式:
- 通过缓存一致性协议 -> 优先 锁缓存行
- 通过在总线加LOCK#锁的方式 -> 影响整个通讯,优先级最低
- 其他: 关中断、锁北桥
失效的情况:
- 共享变量大于缓存行大小,MESI 无法进行缓存行加锁;
- Cpu 并不支持缓存一致性协议
其他缓存一致性协议:其主要目的是解决“基于点到点的全互连处理器系统”的Cache共享一致性问题,而不是“基于共享总线的处理器系统”的Cache共享一致性问题。
- AMD opteron: MOESI 协议 ,允许 CPU Cache 间同步数据,于是也降低了对内存的操作 Owner(宿主),用于标记"我是更新数据的源"
- Intel i7 : MESIF 协议 ,其中的 F 是 Forward,同样是把更新过的数据转发给别的 CPU Cache 但是,MOESI 中的 Owner 状态 和MESIF 中的 Forward 状态有一个非常大的不一样—— Owner状态下的数据是dirty的,还没有写回内存,Forward状态下的数据是clean的,可以丢弃而不用另行通知。
嗅探机制
每个处理器会通过嗅探器来监控总线上的数据来检查自己缓存内的数据是否过期,如果发现自己缓存行对应的地址被修改了,就会将此缓存行置为无效。当处理器对此数据进行操作时,就会重新从主内存中读取数据到缓存行。
总线风暴
总线的通信能力是固定的,如果有大量的缓存一致性协议信号流量,嗅探机制 造成总线流量激增。
在 java 中使用unsafe实现CAS,其底层由CPP调用汇编指令实现的,如果是多核 cpu 是使用lock cmpxchg指令,单核 cpu 使用cmpxchg指令。
缓存行
数据在各级缓存中以缓存行为单位来存储和读写的,有效地引用主内存中的一块连续地址 ,通常是 64 字节 。
在多个线程之间能够被共享访问的变量被称为共享变量, 包括所有的实例变量,静态变量和数组元素。<肯定不在栈中,可能在堆或元空间内>,Volatile 只作用于共享变量。每个线程有自己私有的工作内存,保存主存中共享变量的副本,线程对其的读写操作都必须先在私有工作内存中完成,再同步到主存!
| 内存屏障 | Memory Barriers | 是一组处理器指令,用于实现对内存操作的顺序限制。 |
| 缓冲行 | Cache line | 缓存中可以分配的最小存储单位。 |
| 原子操作 | Atomic operations | 不可中断、不可分割的一个或一系列操作。 |
| 缓存行填充 | cache line fill | 当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个缓存行到适当的缓存(L1,L2,L3 的或所有) |
| 缓存命中 | cache hit | 处理器能从缓存中读取操作数 |
| 写命中 | write hit | 当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作被称为写命中。 |
| 写缺失 | write misses the cache | 一个有效的缓存行被写入到不存在的内存区域。 |
一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。 如果访问一个 long 数组,当数组中的一个值被加载到缓存中,它会额外加载另外 7 个,因此能非常快地遍历这个数组。事实上,可以非常快速的遍历在连续的内存块中分配的任意数据结构。 因此如果数据结构中的项在内存中不是彼此相邻的(链表),将得不到免费缓存加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中。
同时也有一个弊端。
设想 long 类型的数据只是一个单独的head变量;然后再设想在类中有另一个变量tail紧挨着它。现在,当加载head到缓存的时候,也免费加载了tail。 这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程并发使用。 如果更新了 head变量值, 缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。 CPU 以整个缓存行作为单位来处理 ,标记数据为无效 。
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。这种并发访问效率很低 。
缓存行填充
对于上述的 “伪共享”(同一缓存行内有多个不相关的共享变量数据被多个线程并发访问操作),就需要 “缓存行填充” 的方式来避免因和其它无关变量的意外冲突造成不必要的缓存未命中。
Java8 实现字节填充避免伪共享 :
JVM 启动开启 -XX:-RestrictContended + @sun.misc.Contended用于注解类或属性字段分组的 申明,自动填充字节齐缓存行。
像 Disruptor,通过增加补全来确保RingBuffer的序列号不会和其他同时存在于一个缓存行中。
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
Java 内存中实例对象的结构 https://my.oschina.net/u/3434392/blog/4792575结合上文里对实例数据存储策略及对象头结构的描述可知:填充字段都是引入在基本类型后面 。这种将 Value 放在中间的方式来填充,保证任何时候都不会出现伪共享。
https://my.oschina.net/u/3434392/blog/4792575结合上文里对实例数据存储策略及对象头结构的描述可知:填充字段都是引入在基本类型后面 。这种将 Value 放在中间的方式来填充,保证任何时候都不会出现伪共享。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









