







我思故我在:
当key的大小写不一致时,按首字母排序会发生错误
favorite_langues={ 'Kim':'python', 'Tom':'C', 'Amy':'ruby', 'Jone':'C++', } for name in sorted(favorite_langues.keys()): print(name.title() + ',thank you for taking poll!')
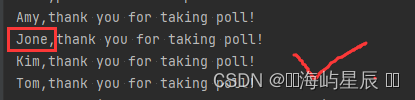
favorite_langues={ 'Kim':'python', 'Tom':'C', 'Amy':'ruby', 'jone':'C++', }for name in sorted(favorite_langues.keys()): print(name.title() + ',thank you for taking poll!')

课本重点代码:
#字典:大括号
aline_0={'color':'green','points':5}
print(aline_0['color'])
print(aline_0['points'])
#访问字典中的元素:中括号
new_points=aline_0['points']
print('You just earned '+str(new_points)+' points !')
#添加字典中的元素:中括号
print(aline_0)
aline_0['x_pointition']=0
aline_0['y_pointition']=25
print(aline_0)
#改变字典中的元素:中括号
print("The aline is "+aline_0['color']+".") #当前颜色
aline_0['color']="yellow" #改变颜色为黄色
print("The aline is now "+aline_0['color']+".")
#对字典中的元素值做出改变
aline_0={'x_pointition': 0, 'y_pointition': 25,'speed':'medium'}
print('Original x-position '+str(aline_0['x_pointition'])+".")
if aline_0['speed']=='slow':
x_increment=1
elif aline_0['speed']=='medium':
x_increment=2
else:
x_increment=3
aline_0['x_pointition']=aline_0['x_pointition'] + x_increment
print('New x-position '+str(aline_0['x_pointition'])+".")
#删除
aline_0={'color':'green','points':5}
del aline_0['color']
print(aline_0)
#字典中的其他格式:注意换行的位置,最后多加一个逗号
favorite_languages={
'kim':'python',
'Tom':'C',
'Amy':'ruby',
'jone':'C++',
}
print(favorite_languages)
#遍历字典:把前边这个单词,含义分别打印出来
user_0={
'user_name':'efermi',
'first':'enrico',
'last':'fermi',
}
for key,value in user_0.items():
print('\nkey:'+key)
print('\nvalue:'+value)
#生词解释分开用
favorite_languages={
'kim':'python',
'Tom':'C',
'Amy':'ruby',
'jone':'C++',
}
for name,language in favorite_languages.items(): #.变量items():提出来key、value
print(name.title()+"'s favoritelangues is "+language.title())
for name in favorite_languages.keys(): #变量.keys():提出来key
print(name.title())
#对于字典中的人,打出名字,如果这个人在friends里边,多打出一句话
favorite_languages={
'Kim':'python',
'Tom':'C',
'Amy':'ruby',
'Jone':'python',
}
friends=['kim','jone']
for name in favorite_languages.keys(): #变量.keys():提出来key
print(name.title())
if name in friends:
print('Hi, '+name.title()+',I see your favorite langues is '+language.title()+'!')
#如果这个人不在偶喜欢语言这个列表里,说明他没有参加采访,告诉他情投票
if 'phil' not in friends:
print("Phil,please take our poll!")
#按顺序:想用一定的顺序打印,需要用sorted()
for name in sorted(favorite_languages.keys()):
print(name.title() + ',thank you for taking poll!')
#按原来字典中的字母顺序打印出来这个人名:可能会存在重复打印
print("The following languages have been mention:")
for language in favorite_languages.values():
print(language.title()) #会打印出2个python
#不重复打印:set(~~)
print("The following languages have been mention:")
for language in set(favorite_languages.values()):
print(language.title()) #会打印出1个python
#嵌套: 列表=['字典0','字典1','字典2']
aline_0={'color':'green','points':5}
aline_1={'color':'yellow','points':10}
aline_2={'color':'red','points':15}
alines=[aline_0,aline_1,aline_2]
for aline in alines:
print(aline)
#生成30个外星人
alines=[]
for aline_number in range(30): #从0——29取30次
new_aline={'color':'green','points':5,'speed':'medium' }
##但这个外星人的变好在循环中并没有使用
alines.append(new_aline)
for aline in alines[:5]:
print(aline) #打印出前5个
print(".....") #后边的省略
##打印外星人的数量,用len()
print("Total number of alines: "+str(len(alines)))
#改变前3个字典中的内容(颜色、速度、分度值)
for aline in alines[:3]:
if aline['color']=='green':
aline['color']='yellow'
aline['speed']='fast'
aline['points']=20
#打印出前5个
for aline in alines[:5]:
print(aline) #打印出前5个
print(".....") #后边的省略
#前5个外星人升级
for aline in alines[:5]:
if aline['color']=='green':
aline['color']='yellow'
aline['speed']='fast'
aline['points']=10
elif aline['color']=='yellow':
aline['color']='red'
aline['speed']='slow'
aline['points']=15
#打印出前5个
for aline in alines[:5]:
print(aline) #打印出前5
print(".....") #后边的省略
#字典={'单词1':'解释1','单词2':['解释1','解释2',]}
pizzas={
'crust':'thick',
'topping':['mushroons','extra cheese'],
}
print('You ordered a '+pizzas['crust']+'-crust pizza'+" with the following toppings:")
for topping in pizzas['topping']: #这里把toppings值取出来
print('\t-'+topping)
#字典中的多个列表
favorite_languages={
'kim':['python','C'],
'Tom':['C','ruby'],
'Amy':['ruby'],
'jone':['C++','go'],
}
#元素分开name取成值,languages取成列表
for name,languages in favorite_languages.items():
print('\n'+name.title()+"'s favorite languages are:")
##从列表再提出元素
for language in languages:
print('\t-'+language.title()) #会打印出1个python
#字典中的字典 字典={字典0,字典1}
#字典={'新华字典':{'我':'美丽'},'牛津字典':{'me':'beautiful'},'Le petit Nicola':{'Moi':'La plus belle'},}
users={
'aeinstein':{
'first':'albert',
'last':'ainstein',
'location':'princeton',
},
'murie':{
'first': 'marie',
'last': 'curie',
'location': 'paris',
},
}
for username,user_info in users.items():
print('\nUsername:' + username)
full_name=user_info['first']+user_info['last']
location=user_info['location']
print('\tFull_name: '+full_name.title())
print('Locatio: '+ location.title())
课后习题:
# 6-1 人:使用字典来存储一个熟人的信息,包括名、姓、年龄 和居住的城市。将存储在该字典中的每项信息都打印出来。
messages={'first_name':'Freya','last_name':'Qin','age':23, 'city':'London',}
for key,value in messages.items():
print('\nkey:'+key)
print('value:'+str(value))
# 6-2 喜欢的数字:使用字典来存储一些人喜欢的数字。5个人的名字作字典中的键;每个人喜欢的一个数字,并将这些数字作为值存储在字典中。打印每个人的名字 和喜欢的数字。
favorite_digits={'Freya':12,'alice':56, 'kim':78, 'koko':99,}
for key,value in favorite_digits.items():
print('\nname:' + key)
print('favorite_digit:' + str(value))
#6-3 词汇表1:想出你在前面学过的5个编程词汇,将它们用作词汇表中的键,并将它们的含义作为值存储在词汇表中。
# 以整洁的方式打印每个词汇及其含义。为此,你可以先打印词汇,在它后面加上一个冒号,再打印词汇的含义;
# 也可在一行 打印词汇,再使用换行符(\n )插入一个空行,然后在下一 行以缩进的方式打印词汇的含义。Vocabulary=['code lay out':''代码布局','Whitespaces in Expressions':'表达式中的空格','Naming Convertion':'命名规范','pop':"弹出",'Programming recommendations':'编程建议',]
Vocabulary={'code lay out':'代码布局','whitespace in expression':'表达式中的空格','Naming Coventions':'命名规范','Programming recommendations':'编程建议'}
for word,interpretation in Vocabulary.items():
print(word+':' )
print(interpretation)
# #6-4 词汇表2:练习6-3而编写的代码,将其中一系列print语句替换为一个遍历字典中的键和值的循环。
# 再在词汇表中添加5个Python术语,这些新术语及其含义将自动包含在输出中。
Vocabulary={'code lay out':'代码布局','whitespace in expression':'表达式中的空格','Naming Coventions':'命名规范','Programming recommendations':'编程建议'}
Vocabulary['global variable names']='全局变量名'
Vocabulary['function annotation']='功能注释'
Vocabulary['indentation']='缩进'
Vocabulary['binary operator']='运算符'
Vocabulary['string quotes']='字符串引号'
for word,interpretation in Vocabulary.items():
print(word+':' )
print(interpretation)
#6-5 河流:创建一个字典,在存储三条大河流及其流经的国家。
# 使用循环为每条河流打印一条消息,如“The Nile runs through Egypt.”。
# 使用循环将该字典中每条河流的名字都打印出来。使用循环将该字典包含的每个国家的名字都打印出来。
rivers={'the Amazon':'Brazil', 'Mississippi River':'America','Yellow rive':'China','Nile': 'Egypt'}
for river,country in rivers.items():
print('The '+river.title()+' runs through ' +country.title()+'.')
for river in rivers.keys():
print(river)
for country in rivers.values():
print(country)
#6-6 调查:在6.3.1节编写的程序favorite_languages.py中执行以下操作。
# 创建一个应该会接受调查的人员名单,有些人已包含在字典中,而其他人未包含在字典中。
# 遍历这个人员名单,对于已参与调查的人,打印一条消息表示感谢。对于还未参与调查的人,打印一条消息邀请他参与调查。
favorite_languages={
'Kim':'python',
'Tom':'C',
'Amy':'ruby',
'Jone':'python',
}
investigations=['Kim','Jone']
for name in favorite_languages.keys():
if name in investigations:
print('Thanks, '+name.title()+'!')
else:
print(name.title()+",please take our poll!")
#6-7 人:在6-1中,再创建两个表示人的字典,然后将这三个字典都存储在一个名为people的列表中。
# 遍历这个列表,将其中每个人的所有信息都打印出来。
messages_1={'first_name':'Freya','last_name':'Qin','age':23, 'city':'London',}
messages_2={'first_name':'Ge','last_name':'kaixin','age':23, 'city':'England',}
messages_3={'first_name':'WANG','last_name':'Amy','age':23, 'city':'England',}
peoples=[messages_1,messages_2,messages_3]
for people in peoples:
for key,value in people.items():
print('\nkey:'+key)
print('value:'+str(value))
#6-8 宠物:创建多个字典,对于每个字典,都使用一个宠物的名称 来给它命名;在每个字典中,包含宠物的类型及其主人的名字。
#将这些字典存储在一个名为pets的列表中,再遍历该列表,并将宠物的所有信息都打印出来。
dog={'type':'dog','owner':'Kim'}
cat={'type':'cat','owner':'Freya'}
monkey={'type':'monkey','owner':'Amy'}
pig={'type':'pig','owner':'koko'}
pets=[dog,cat,monkey,pig]
for pet in pets:
for key,value in pet.items():
print('\n'+key+':')
print('——'+value)
# #6-9 喜欢的地方:创建一个名为favorite_places 的字典。在这个字典中,将三个人的名字用作键;
# 对于其中的每个人,都存储他喜欢的1~3个地方。
# 为让这个练习更有趣些,可让一些朋友指出他们喜欢的几个地方。遍历这个字典,并将其中每个人的名字及其喜欢的地方打印出来。
favorite_places={'alice':['Dali','DaLian','Shenzhen'],
'Amy':['Nanjing','Hangzhou','Chongqing'],
'koko':['Shanghai','Beijing','London'],
}
for name,places in favorite_places.items():
print('\n' + name + '喜欢的地方:')
for place in places:
print(place)
#6-10 喜欢的数字:修改6-2,让每个人都可以有多个喜欢的数字,将每个人的名字及其喜欢的数字打印出来。
favorite_digits={'Freya':[12,66,89],
'alice':[56,34,78],
'kim':[78,98],
'koko':[99,65],
}
for name,numbers in favorite_digits.items():
print('\n'+ name.title()+' favorite_digits:')
for number in numbers:
print('——' + str(number))
# 6-11 城市 :创建一个名为cities 的字典,其中将三个城市名用作键;
#对于每座城市,都创建一个字典,并在其中包含该城市所属的国家、人口约数以及一个有关该城市的事实。
#在表示每座城市的字 典中,应包含country 、population 和fact 等键。将每座城市的名字以及有关它们的信息都打印出来。
cities={'Xi an':{'country':'China','population':'15万', 'fact':'Big Wild Goose Pagoda',},
'London':{'country':'England','population':'5万', 'fact':' the London Eye',},
'New york':{'country':'America','population':'10万', 'fact':' Scenic Spot Times Square',},
}
#方式1:
for name, features in cities.items():
print(name + "的情况如下:")
for key,city in features.items():
print("\t" + key + " : " + city)
#方式2:
for name, features in cities.items():
print(name + "的情况如下:")
print(features)
# 6-12 扩展 :本章的示例足够复杂,可以以很多方式进行扩展了。 请对本章的一个示例进行扩展:添加键和值、调整程序要解决的问 题或改进输出的格式。















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









