







一
构造一个person的列表结构list1,元素为参加调查问卷的人员的名字(不用太多),(建立列表有很多方法,选择一种你喜欢的),命名为3.1.py
从键盘上输入一个人名,判断这个人名是否在list1中。
(1)如果人名在列表中,就输出“您已经参与过调查,感谢参与!!!”。
(2)如果人名不在列表中,输出“您是否已经参加过?是/否”
1)如果用户选择“是”,将用户名字加入list1末尾,输出“抱歉,我们统计有误!,感谢参与!!!”
2)如果用户选择否,输出“,希望您能参与调查”
图示范例结果为:



list1=['周杰伦','超级玛丽','李云迪','乔丹','马拉多纳']
print("名单测试输出:",list1)
a=input("Please input your name:")
if a in list1:
print("{},您已经参与过调查,感谢参与".format(a))
print(list1)
else:
b=input("名单里没有您,请问是否已经参与过?是/否 ")
if b=='是':
list1.append(a)
print("抱歉,我们统计有误!{},感谢参与!".format(a))
print(list1)
else:
print("{},希望您能参与调查".format(a))
print(list1)
实验截图如下:

二
改变我们实验二中的帮老师判卷子的题目,改变后的题目如下:
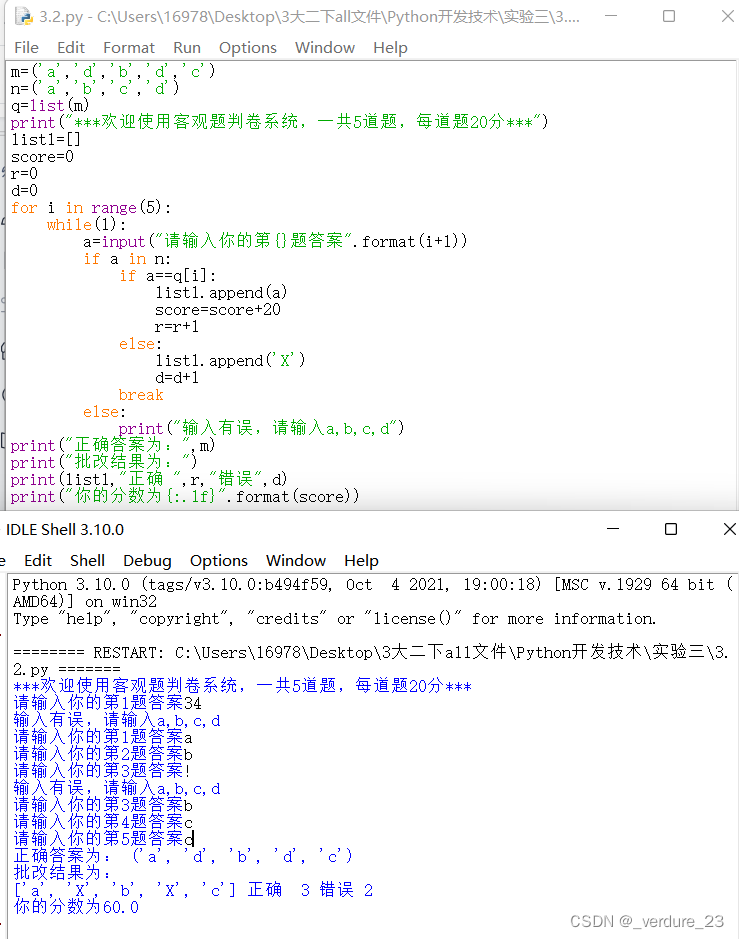
设计一个程序来帮助老师判客观题的单元测试,本次测试题一共5道,已经知道正确答案分别是(‘a’,‘d’,‘b’,‘d’,‘c’),为元组结构。请根据正确答案,找出学生的错误,并且统计正确的和错误的数量,给出最终分数。程序命名为3.2.py。
m=('a','d','b','d','c')
n=('a','b','c','d')
q=list(m)
print("***欢迎使用客观题判卷系统,一共5道题,每道题20分***")
list1=[]
score=0
r=0
d=0
for i in range(5):
while(1):
a=input("请输入你的第{}题答案".format(i+1))
if a in n:
if a==q[i]:
list1.append(a)
score=score+20
r=r+1
else:
list1.append('X')
d=d+1
break
else:
print("输入有误,请输入a,b,c,d")
print("正确答案为:",m)
print("批改结果为:")
print(list1,"正确 ",r,"错误",d)
print("你的分数为{:.1f}".format(score))
实验截图如下:
三
猜单词游戏。已知
WORDS = (“python”, “jumble”, “easy”, “difficult”, “answer”, “continue”
, “phone”, “position”, “position”, “game”)
#上面的结构是个元组,这是互联网中一个经典的例题
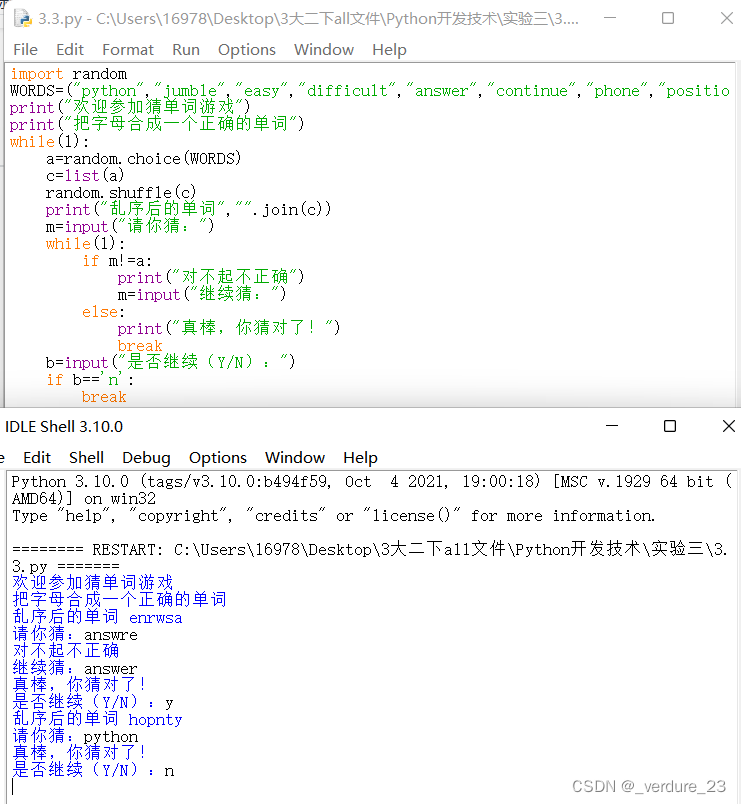
计算机随机从WORDS中选取一个单词,然后打乱顺序,供玩家去猜,效果如下图所示。
提示:随机产生或选取一个单词,需要使用random库中的随机数函数,需要import random库。其中random.choice( )可以从序列中随机选取元素。另外,如何把单词的字母顺序打乱呢,老师提供一种思路:方法是随机从单词字符串中选择一个位置position,把position位置那个字母加入乱序后的单词,同时将原单词中positon位置那个字母删去。多次循环(循环次数是单词的长度),就可以生成新的乱序后单词。(方法不唯一,期待着大家的其他方法)命名为3.3.py

import random
WORDS=("python","jumble","easy","difficult","answer","continue","phone","position","position","game")
print("欢迎参加猜单词游戏")
print("把字母合成一个正确的单词")
while(1):
a=random.choice(WORDS)
c=list(a)
random.shuffle(c)
print("乱序后的单词","".join(c))
m=input("请你猜:")
while(1):
if m!=a:
print("对不起不正确")
m=input("继续猜:")
else:
print("真棒,你猜对了!")
break
b=input("是否继续(Y/N):")
if b=='n':
break
四
根据要求完成程序,命名为3.4.py
(1)用传统的for、if语句方法实现计算1-100之间的素数,把结果放到列表list1里面,并输出。

(2)用列表推导式计算:判断list1里面的元素,如果大于50,就计算他们的和,并放在list2里面,并输出。

list1=[]
for i in range(2,100):
for j in range(2,i):
if i%j==0:
break
else:
list1.append(i)
print("1到100间的素数为:",list1)
list2=[i for i in list1 if i>50]
m=0
for i in list2:
m=m+int(i)
print("大于50的列表:",list2)
print("1到100之间大于50的素数之和为:",m)
实验截图如下:

五
将第一题用字典结构来写,具体要求如下:
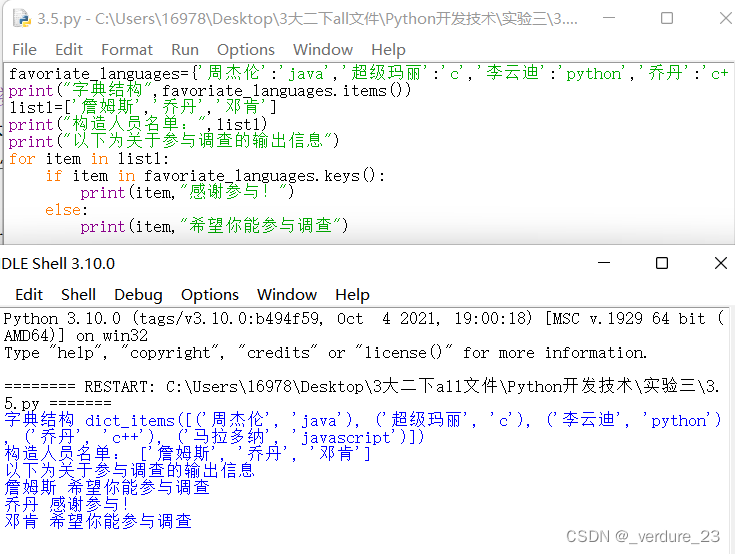
构造一个favorite_languages的字典结构,键为参加调查人员的名字(不用太多),键值为他喜欢的编程语言。命名为5.py
(1)分别输出字典里的键值对,键和值。
(2)创建一个应该会接受调查的人员名单(list结构),其中有些人已经包含在字典中,而其他人未包含在字典中。
(3)遍历这个人员名单,对于已经参与调查的人,打印一条消息表示感谢;对于未参与调查的人,打印一条消息邀请他参与调查。
输出范例:

favoriate_languages={'周杰伦':'java','超级玛丽':'c','李云迪':'python','乔丹':'c++','马拉多纳':'javascript'}
print("字典结构",favoriate_languages.items())
list1=['詹姆斯','乔丹','邓肯']
print("构造人员名单:",list1)
print("以下为关于参与调查的输出信息")
for item in list1:
if item in favoriate_languages.keys():
print(item,"感谢参与!")
else:
print(item,"希望你能参与调查")
实验截图如下:
六
披萨题目的改进:
之前题目原题:我们开了一个pizza店,现在用python写了一个简单的欢迎画面和使用程序
(1)进入系统,使用上节课学习的format格式化函数输出,例如 ******Hello,Welcome to Doraemon pizza store ******,自己设计就可以
(2)询问请用户输入想要几个pizza。
(3)输入每个pizza的税前单价(这个功能有点low)。
(4)然后系统计算出一共多少钱。
(5)1个pizza需要交8%的税,计算出需要交多少税,保留2位小数。
(6)计算出最终用户需要支付的金额,并输出“一共多少钱,其中pizza多少,税多少”。
(7)(选做)请用户输入配送还是自取(0 代表配送 1代表自取)
如果自取,输出大约多长时间请来店取
如果配送,请用户输入配送地址,并提示大约多长时间可以送到
(8)最后输出“谢谢惠顾”字样。
改造一:
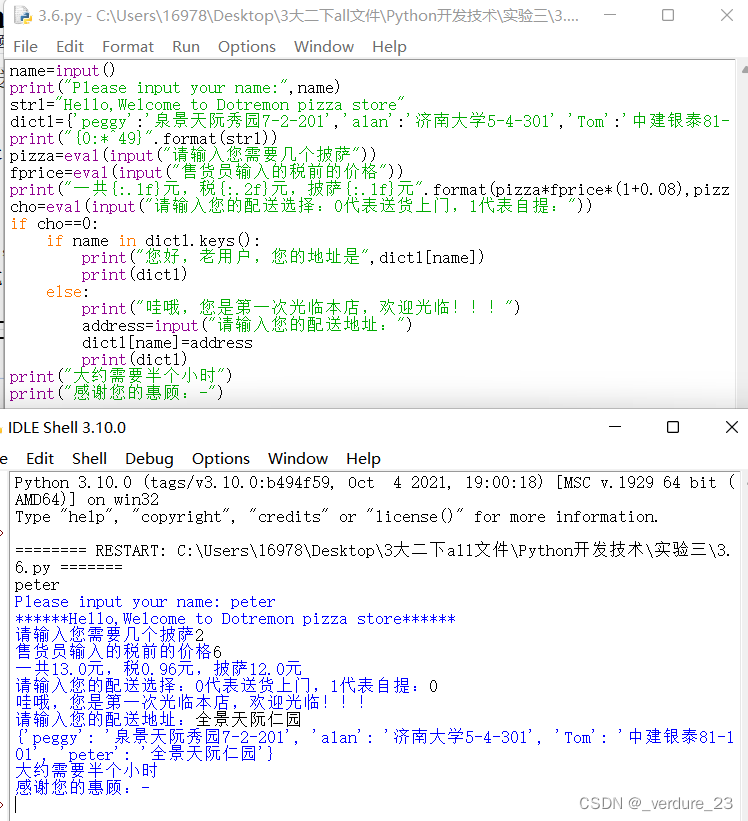
用户,我们可以把用户和他的地址用字典类型来存储,在给用户派送时候,检测是否有用户的地址信息,如果有就从字典里读出来,如果没有,就把新用户加入字典,并完成之前的功能。老师做的显示效果如下图:

name=input()
print("Please input your name:",name)
str1="Hello,Welcome to Dotremon pizza store"
dict1={'peggy':'泉景天阮秀园7-2-201','alan':'济南大学5-4-301','Tom':'中建银泰81-101'}
print("{0:*^49}".format(str1))
pizza=eval(input("请输入您需要几个披萨"))
fprice=eval(input("售货员输入的税前的价格"))
print("一共{:.1f}元,税{:.2f}元,披萨{:.1f}元".format(pizza*fprice*(1+0.08),pizza*fprice*0.08,pizza*fprice))
cho=eval(input("请输入您的配送选择:0代表送货上门,1代表自提:"))
if cho==0:
if name in dict1.keys():
print("您好,老用户,您的地址是",dict1[name])
print(dict1)
else:
print("哇哦,您是第一次光临本店,欢迎光临!!!")
address=input("请输入您的配送地址:")
dict1[name]=address
print(dict1)
print("大约需要半个小时")
print("感谢您的惠顾:-")
实验截图如下:
七
*选做题
模拟一个简单的电影推荐:假设已有若干用户喜欢的电影清单,现有某用户,已看过并喜欢一些电影,现在想找个新电影看看,又不知道看什么好。
思路:根据已有数据,查找与该用户爱好最相似的用户,也就是看过并喜欢的电影与该用户最接近,然后从那个用户喜欢的电影中选取一部当前用户还没看过的电影,进行推荐。
范例图示:

import random
alls=[{'这个杀手不太冷','阿甘正传','我和春天有个约会','暮光之城','霸王别姬','肖申克的救赎'},{'神奇动物在哪里','杜拉拉升职记','小时代'},{'开国大典','建党伟业','杜拉拉升职记'}]
my=set(['阿甘正传','哈利波特','这个杀手不太冷'])
print("我喜欢的电影:",my)
for item in alls:
if item & my !=set():
#print(item & my)
print("和我最相似的是",item)
print("他/她喜欢的还有哪些我没有看过",list(item-my))
print("随机选取一部推荐的电影为:",random.choice(list(item-my)))
实验截图如下:
















 3285
3285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









