







线程同步
多个线程对某个数据进行修改,为保证数据正确,需要进行线程同步
import threading
#多个线程对某个数据进行修改,为保证数据正确,需要进行线程同步
#Rlock对象允许一个线程多次进行acquire操作
#mylock = threading.Lock() Lock() 只允许线程一次acquire()操作
mylock = threading.RLock()
num = 0
class myT(threading.Thread):
def __init__(self,name):
threading.Thread.__init__(self,name=name)
def run(self):
global num
while True:
#同步方法挂起
mylock.acquire()
print('%s 锁定,同步修改数据:%d '% (threading.current_thread().name,num))
if num>=4: #如果num等于4的时候释放并退出
mylock.release() #同步释放
print('%s 已经释放,同步修改数据:%d ' % (threading.current_thread().name, num))
print('%s退出'%(threading.current_thread().name))
break
num +=1
print('%s 已经释放,同步修改数据:%d ' % (threading.current_thread().name, num))
mylock.release()
if __name__=='__main__':
t1 = myT('线程1')
t2 = myT('线程2')
t1.start()
t2.start()
- 运行结果

协程

from gevent import monkey;monkey.patch_all()
import gevent
import urllib.request
def run_task(url):
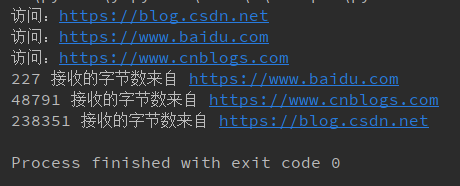
print('访问:%s'% url)
try:
response = urllib.request.urlopen(url)
data = response.read()
print('%d 接收的字节数来自 %s'% (len(data),url))
except Exception as e:
print(e)
return 'url:%s-->完成'% url
if __name__=="__main__":
urls =['https://blog.csdn.net','https://www.baidu.com','https://www.cnblogs.com']
g =[gevent.spawn(run_task,url) for url in urls]
gevent.joinall(g)
- 运行结果
pool限制协程并发数
from gevent import monkey
monkey.patch_all()
import urllib.request
from gevent.pool import Pool
#pool处理高并发协程,限制并发数
def run_task(url):
print('访问:%s'% url)
try:
response = urllib.request.urlopen(url)
data = response.read()
print('%d 接收的字节数来自 %s'% (len(data),url))
except Exception as e:
print(e)
return 'url:%s-->完成'% url
if __name__=="__main__":
pool = Pool(2) #限制并发数为2
urls =['https://blog.csdn.net','https://www.baidu.com','https://www.cnblogs.com']
r =pool.map(run_task,urls)
print(r)
- 运行结果















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









