







(一) Title
论文:https://arxiv.org/abs/2106.06072
代码:https://github.com/ProbIOU
(二) Summary
研究背景:
目前目标检测算法基本上是通过bounding boxes来编码和表示object的形状和形状的,也就是有边界框的长宽和中心点坐标,general focal loss中也提到过在GT标注时实际上我们的GT并不是理论上的GT,而是认为标注的,有的时候物体的边界不好确定下来,对于模型来说,通过这种方式最多能够学习到一种带有置信度的标注,也就是对预测结果的确信程度。
本文方法:
本文中通过使用Gaussian分布来对目标区域进行模糊表示(fuzzy representation),相当于使用椭圆来表示边界框.接着本文针对高斯分布提出了一个基于Hellinger Distance的相似度度量,可以看成是Probabilistic Intersection-over-Union(ProbIoU),ProbIoU损失函数的优势在于:
- ProbIoU对于尺度缩放是不变的,不会随着尺度的变化导致损失值发生改变。
目前该方法存在的问题是:对于方形w=h目标没有办法给出角度信息。
实验结果:
本文提出的Gaussian representations更加接近annotated segmentation,并且ProbIoU可以处理Gaussian representations的回归问题,ProbIoU能够很方便地添加到object detector中。
(三) Research Object
边界框的表示方式
- HBB,水平边界框,通过4个参数就能够表示,对于大型数据集来说标注比较友好。但是存在的问题是边界框包围的内容中包含了一部分背景,特别是对于拉长和旋转目标来说。
- 二进制Mask表示,通过mask来表示对象,标注时间较长,能够更加精细地表示对象。而且最后需要对应到原图大小上,模型架构比较复杂。
- OBB,旋转边界框,在RoI Transformer(不是Transformer encorder & decorder,仅仅表示一种变换)中将horizontal RoI变换成了OBB RoI,输出带有角度的proposals。
定位损失
- HBB边界框通常使用参数化损失parameter-wise loss components(比如说 l 1 l_1 l1和 l 2 l_2 l2正则,或者smooth l 1 l1 l1),由于参数化损失隐式地假设每一个参数之间都是独立的,也就是一个参数的改变并不会影响另一个参数,因此参数化的损失might not converge consistently to the ground-truth(GT) annotation,
- 基于IoU的损失,IoU loss,GIoU,DIoU,CIoU,PIoU以及GWD
本文探索通过Gaussian Bounding Boxes(GBBs)来编码目标的representations,通过对目标使用GBBs的表示方式,并引入了一个可微分的损失来回归旋转框的参数或者直接回归GBB的参数(mean vector以及协方差矩阵covariance matrix).
(四) Problem Statement
本文提出使用Gaussian Bounding Boxes来表示目标,怎样得到目标的Gaussian Bounding Boxes表示呢?怎样回归边界框呢?
(五) Method
本文的核心思想就是:通过rotated Gaussian distribution来表示object,高斯分布可以参数化成均值向量 μ = ( x 0 , y 0 ) T \mu=\left(x_{0}, y_{0}\right)^{T} μ=(x0,y0)T以及协方差矩阵 Σ \Sigma Σ,构成了一个椭圆,也就相当于使用椭圆来对二维区域进行表示。
- 目标检测的工作实际上是基于预测框和真实框之间的距离差异构建损失函数进行回归,同样在这里也是这样,因为使用了高斯分布来表示目标,所以这里首先需要定义两个分布之间的距离.这个需要探索大量的统计工具来衡量.
- 高斯分布的形式带来了这些度量形式的closed-form differentiable表示,比如Bhatacharyya distance以及Kullback-Leibler divergence.为什么说高斯分布的形式对于这些度量能够可微呢?还是Kullback-Leibler divergence我之前记得貌似是不满足三角不等式的呀!
5.1 如何使用高斯分布来表示边界框
二维高斯分布的均值向量 μ = ( x 0 , y 0 ) T \boldsymbol{\mu}=\left(x_{0}, y_{0}\right)^{T} μ=(x0,y0)T,协方差矩阵 Σ \Sigma Σ,协方差矩阵具有两种表示方式:
Σ = [ a c c b ] = R θ [ a ′ 0 0 b ′ ] R θ T = [ a ′ cos 2 θ + b ′ sin 2 θ 1 2 ( a ′ − b ′ ) sin 2 θ 1 2 ( a ′ − b ′ ) sin 2 θ a ′ sin 2 θ + b ′ cos 2 θ ] \Sigma=\left[\begin{array}{ll} a & c \\ c & b \end{array}\right]=R_{\theta}\left[\begin{array}{cc} a^{\prime} & 0 \\ 0 & b^{\prime} \end{array}\right] R_{\theta}^{T}=\left[\begin{array}{cc} a^{\prime} \cos ^{2} \theta+b^{\prime} \sin ^{2} \theta & \frac{1}{2}\left(a^{\prime}-b^{\prime}\right) \sin 2 \theta \\ \frac{1}{2}\left(a^{\prime}-b^{\prime}\right) \sin 2 \theta & a^{\prime} \sin ^{2} \theta+b^{\prime} \cos ^{2} \theta \end{array}\right] Σ=[accb]=Rθ[a′00b′]RθT=[a′cos2θ+b′sin2θ21(a′−b′)sin2θ21(a′−b′)sin2θa′sin2θ+b′cos2θ]
第一种表示方式一个对称的协方差矩阵,从埃尔米特矩阵的定义来看(矩阵中每一个第i行第j列的元素与第j行第i列的元素的共轭相同),协方差矩阵就是埃尔米特矩阵根据埃尔米特矩阵的性质可知:如果埃尔米特矩阵的特征值都是正数,那么这个矩阵就是正定矩阵,如果他们是非负的,那这个矩阵就是半正定矩阵。
从上面的性质可知, a > 0 , a b − c 2 > 0 , b > 0 a>0,ab-c^2>0,b>0 a>0,ab−c2>0,b>0.

第二种表示方式是使用旋转矩阵进行表示。其中旋转矩阵的表示方式为,给定坐标 ( x 1 , y 1 ) (x_1,y_1) (x1,y1),绕坐标 ( 0 , 0 ) (0,0) (0,0)顺时针旋转 θ \theta θ角度后得到坐标 ( x , y ) (x,y) (x,y),计算方式如下:
[ x y ] = [ x 1 c o s θ − y 1 s i n θ y 1 c o s θ + x 1 s i n θ ] = [ c o s θ − s i n θ s i n θ c o s θ ] [ x 1 y 1 ] = R θ [ x 1 y 1 ] \left[\begin{array}{ll} x \\ y \end{array}\right]=\left[\begin{array}{ll} x_1cos\theta -y_1sin\theta \\ y_1cos\theta+x_1sin\theta \end{array}\right]=\left[\begin{array}{ll} cos\theta & -sin\theta \\ sin\theta & cos\theta \end{array}\right]\left[\begin{array}{ll} x_1 \\ y_1 \end{array}\right]=R_{\theta}\left[\begin{array}{ll} x_1 \\ y_1 \end{array}\right] [xy]=[x1cosθ−y1sinθy1cosθ+x1sinθ]=[cosθsinθ−sinθcosθ][x1y1]=Rθ[x1y1]因此从上面两种表示方式来看,为了得到协方差矩阵可以直接回归 ( a , b , c ) (a,b,c) (a,b,c)或者回归 ( a ′ , b ′ , θ ) (a^{\prime},b^{\prime},\theta) (a′,b′,θ),对于旋转边界框来说,使用 ( a ′ , b ′ , θ ) (a^{\prime},b^{\prime},\theta) (a′,b′,θ)表示是很合适的,而 ( a ′ , b ′ , θ ) (a^{\prime},b^{\prime},\theta) (a′,b′,θ)和 ( b ′ , a ′ , θ + π 2 ) (b^{\prime},a^{\prime},\theta+\frac{\pi}{2}) (b′,a′,θ+2π)表示的都是相同的协方差矩阵,为了 ( a ′ , b ′ , θ ) (a^{\prime},b^{\prime},\theta) (a′,b′,θ)形式下能够有一个独一无二表示方式,这里限制 θ ∈ [ − π 4 , π 4 ] \theta \in [-\frac{\pi}{4},\frac{\pi}{4}] θ∈[−4π,4π],当 a ′ = b ′ a^{\prime}=b^{\prime} a′=b′时,表示的是各项同性的高斯核,此时角度 θ \theta θ取任何值都对应着相同的协方差矩阵。对于方形的矩形框来说,旋转边界框仍然对应着一个角度,然而GBB的表示方式给出的角度却可以是任意的,从而导致了从OBB表示变换成GBB是不可逆的,会存在角度信息的丢失
作者是怎么想到从边界框表示的角度来引入GBB呢?感觉很妙啊,想法很妙,然后接下来的问题是现有的对目标的OBB,HBB以及mask表示中得到目标GBB的表示呢?
- 获取GBB的关键就是得到均值向量和协方差矩阵。首先假设目标区域使用一个2D的binary区域来进行表示,这个区域又是一个概率密度函数(PDF),均值和方差可以通过对区域进行积分进行表示:
μ = 1 N ∫ x ∈ Ω x , Σ = 1 N ∫ x ∈ Ω ( x − μ ) ( x − μ ) T \boldsymbol{\mu}=\frac{1}{N} \int_{\boldsymbol{x} \in \Omega} \boldsymbol{x}, \Sigma=\frac{1}{N} \int_{\boldsymbol{x} \in \Omega}(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^{T} μ=N1∫x∈Ωx,Σ=N1∫x∈Ω(x−μ)(x−μ)T
实际上连续函数的均值和方差的计算方式表示为:
E ( X ) = ∫ − ∞ ∞ x f ( x ) d x Var ( X ) = σ 2 = ∫ ( x − μ ) 2 f ( x ) d x \mathrm{E}(X)=\int_{-\infty}^{\infty} x f(x) \mathrm{d} x \\ \operatorname{Var}(X)=\sigma^{2}=\int(x-\mu)^{2} f(x) d x E(X)=∫−∞∞xf(x)dxVar(X)=σ2=∫(x−μ)2f(x)dx
因此可以得知,均值和协方差计算中的 1 N \frac{1}{N} N1对应着概率密度函数(PDF),其中 N N N表示区域 Ω \Omega Ω的面积。- 对于水平框HBB来说,区域 Ω \Omega Ω是一个矩形,中心点位置为 ( x 0 , y 0 ) (x_0,y_0) (x0,y0),宽为 W W W,高为 H H H,计算出来的均值向量和协方差矩阵为:
μ = ( x 0 , y 0 ) T Σ = 1 W H ∫ − H / 2 H / 2 ∫ − W / 2 W / 2 [ x 2 x y x y y 2 ] d x d y = 1 12 [ W 2 0 0 H 2 ] \boldsymbol{\mu}=(x_0,y_0)^T \\ \Sigma=\frac{1}{W H} \int_{-H / 2}^{H / 2} \int_{-W / 2}^{W / 2}\left[\begin{array}{ll} x^{2} & x y \\ x y & y^{2} \end{array}\right] d x d y=\frac{1}{12}\left[\begin{array}{cc} W^{2} & 0 \\ 0 & H^{2} \end{array}\right] μ=(x0,y0)TΣ=WH1∫−H/2H/2∫−W/2W/2[x2xyxyy2]dxdy=121[W200H2]
对应着第一种表示方式中的协方差矩阵 [ a c c b ] \left[\begin{array}{ll}a & c \\c & b\end{array}\right] [accb],也就是 a = W 2 12 a=\frac{W^2}{12} a=12W2, b = H 2 12 b=\frac{H^2}{12} b=12H2, c = 0 c=0 c=0,对于旋转框来说,首先计算不相关的方差 a ′ , b ′ a^{\prime},b^{\prime} a′,b′,需要同时计算角度 θ \theta θ,对应的协方差矩阵 Σ \Sigma Σ可以使用 R θ [ a ′ 0 0 b ′ ] R θ T R_{\theta}\left[\begin{array}{cc} a^{\prime} & 0 \\ 0 & b^{\prime} \end{array}\right] R_{\theta}^{T} Rθ[a′00b′]RθT表示,如果目标的表示方式是使用参数化的2D形状(多边形),可以通过均值和协方差的计算公式得到高斯分布的均值和方差,如果是目标的表示方式是使用binary分割的mask来表示,采用离散方式计算均值和方差。
如果说最后我们希望输出边界框的中心点和长宽,也可以利用计算出来的均值向量和协方差矩阵反推出来矩形框的中心点和尺寸。- 关于多元高斯分布的一些补充内容为:
马氏平方距离 d 2 ( x ) = ( x − μ ) T Σ − 1 ( x − μ ) d^2(\boldsymbol{x})=(\boldsymbol{x}-\boldsymbol{\mu})^{T} \Sigma^{-1}(\boldsymbol{x}-\boldsymbol{\mu}) d2(x)=(x−μ)TΣ−1(x−μ)表示一个卡方分布(带有两个方向的自由度),然后设置 d 2 ( x ) = r 2 d^2(\boldsymbol{x})=r^2 d2(x)=r2(其中 r r r大于0表示椭圆区域)。考虑HBB情况下对应的方程为:
d 2 ( x ) = ( x − μ ) T Σ − 1 ( x − μ ) = ( x − x 0 ) 2 λ 1 + ( y − y 0 ) 2 λ 2 = r 2 d^2(\boldsymbol{x})=(\boldsymbol{x}-\boldsymbol{\mu})^{T} \Sigma^{-1}(\boldsymbol{x}-\boldsymbol{\mu}) =(x-x_0)^2\lambda_1+(y-y_0)^2\lambda_2=r^2 d2(x)=(x−μ)TΣ−1(x−μ)=(x−x0)2λ1+(y−y0)2λ2=r2
椭圆的表示方程为: x 2 a 2 + y 2 b 2 = 1 \frac{x^{2}}{a^{2}}+\frac{y^{2}}{b^{2}}=1 a2x2+b2y2=1,对应到上面的表示,此时椭圆的semi-axes分别为 r / λ 1 r / \sqrt{\lambda_{1}} r/λ1和 r / λ 2 r / \sqrt{\lambda_{2}} r/λ2,其中 λ 1 \lambda_{1} λ1和 λ 2 \lambda_{2} λ2是 Σ − 1 \Sigma^{-1} Σ−1的特征向量,对于旋转框来说,仅仅是椭圆的主方向换成了 Σ − 1 \Sigma^{-1} Σ−1的特征向量方向,其他的方向并没有发生改变,因此这里还可以变化的是 r r r(这里应该是另一种解释方式,还没有对 r r r进行约束),然后给定一个面积阈值 0 < τ < 1 0<\tau<1 0<τ<1,可以设置 r r r满足 F χ 2 ( r 2 ) = τ F_{\chi^{2}}\left(r^{2}\right)=\tau Fχ2(r2)=τ,其中 F χ 2 F_{\chi^{2}} Fχ2表示卡方分布的累积分布函数(CDF),如果GBB用来计算水平框或者旋转框时,需要生成一个和
μ = ( x 0 , y 0 ) T Σ = 1 W H ∫ − H / 2 H / 2 ∫ − W / 2 W / 2 [ x 2 x y x y y 2 ] d x d y = 1 12 [ W 2 0 0 H 2 ] \boldsymbol{\mu}=(x_0,y_0)^T \\ \Sigma=\frac{1}{W H} \int_{-H / 2}^{H / 2} \int_{-W / 2}^{W / 2}\left[\begin{array}{ll} x^{2} & x y \\ x y & y^{2} \end{array}\right] d x d y=\frac{1}{12}\left[\begin{array}{cc} W^{2} & 0 \\ 0 & H^{2} \end{array}\right] μ=(x0,y0)TΣ=WH1∫−H/2H/2∫−W/2W/2[x2xyxyy2]dxdy=121[W200H2]
面积完全相同的椭圆,此时需要设置 r = 12 / π r=\sqrt{12/\pi} r=12/π,然后对应着的 τ ≈ 0.85 \tau \approx 0.85 τ≈0.85,这里需要解释的包括:卡方分布的CDF以及为什么设置 r = 12 / π r=\sqrt{12/\pi} r=12/π?卡方分布的CDF有什么含义呢?这里还是不理解,为什么是这样呢?
5.2 ProbIoU以及定位损失
给定了GTannotation以及Pred的GBBs表示方式,首先需要定义的是怎么计算两个GBB之间的相似性,本文中考虑的是 Bhattacharyya Coefficient/Distance(巴氏系数/巴氏距离,注意巴氏系数和巴氏距离不是一个东西)可以用来作为一个实际的距离度量。
两个概率密度函数 p ( x ) p(\boldsymbol{x}) p(x)和 q ( x ) q(\boldsymbol{x}) q(x)之间的Bhattacharyya Coefficient定义如下:
B C ( p , q ) = ∫ R 2 p ( x ) q ( x ) d x B_{C}(p, q)=\int_{\mathbb{R}^{2}} \sqrt{p(\boldsymbol{x}) q(\boldsymbol{x})} d \boldsymbol{x} BC(p,q)=∫R2p(x)q(x)dx
用来度量两个分布overlap的程度, B C ( p , q ) ∈ [ 0 , 1 ] B_{C}(p, q) \in[0,1] BC(p,q)∈[0,1],并且当且仅当两个分布完全相同时,才有 B C ( p , q ) = 1 B_{C}(p, q)=1 BC(p,q)=1,而巴氏距离度量两个分布的相似程度,巴氏距离的定义为:
B D ( p , q ) = − ln B C ( p , q ) B_{D}(p, q)=-\ln B_{C}(p, q) BD(p,q)=−lnBC(p,q)对于本文来说,两个分布为高斯分布,即 p ∼ N ( μ 1 , Σ 1 ) p \sim \mathcal{N}\left(\boldsymbol{\mu}_{1}, \Sigma_{1}\right) p∼N(μ1,Σ1)以及 q ∼ N ( μ 2 , Σ 2 ) q \sim \mathcal{N}\left(\boldsymbol{\mu}_{2}, \Sigma_{2}\right) q∼N(μ2,Σ2),并且给出下列表示:
μ 1 = ( x 1 y 1 ) , Σ 1 = [ a 1 c 1 c 1 b 1 ] , μ 2 = ( x 2 y 2 ) , Σ 2 = [ a 2 c 2 c 2 b 2 ] \boldsymbol{\mu}_{1}=\left(\begin{array}{l} x_{1} \\ y_{1} \end{array}\right), \Sigma_{1}=\left[\begin{array}{ll} a_{1} & c_{1} \\ c_{1} & b_{1} \end{array}\right], \boldsymbol{\mu}_{2}=\left(\begin{array}{l} x_{2} \\ y_{2} \end{array}\right), \Sigma_{2}=\left[\begin{array}{ll} a_{2} & c_{2} \\ c_{2} & b_{2} \end{array}\right] μ1=(x1y1),Σ1=[a1c1c1b1],μ2=(x2y2),Σ2=[a2c2c2b2]
从而能够得到 B D B_D BD的close-form表示为:
B D = 1 8 ( μ 1 − μ 2 ) T Σ − 1 ( μ 1 − μ 2 ) + 1 2 ln ( det Σ det Σ 1 det Σ 2 ) , Σ = 1 2 ( Σ 1 + Σ 2 ) B_{D}=\frac{1}{8}\left(\boldsymbol{\mu}_{1}-\boldsymbol{\mu}_{2}\right)^{T} \Sigma^{-1}\left(\boldsymbol{\mu}_{1}-\boldsymbol{\mu}_{2}\right)+\frac{1}{2} \ln \left(\frac{\operatorname{det} \Sigma}{\sqrt{\operatorname{det} \Sigma_{1} \operatorname{det} \Sigma_{2}}}\right), \Sigma=\frac{1}{2}\left(\Sigma_{1}+\Sigma_{2}\right) BD=81(μ1−μ2)TΣ−1(μ1−μ2)+21ln(detΣ1detΣ2detΣ),Σ=21(Σ1+Σ2)
多维正态分布的概率密度函数为:
f x ( x 1 , … , x k ) = 1 ( 2 π ) k ∣ Σ ∣ e − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) f_{\mathrm{x}}\left(x_{1}, \ldots, x_{k}\right)=\frac{1}{\sqrt{(2 \pi)^{k}|\Sigma|}} \mathrm{e}^{-\frac{1}{2}(\mathrm{x}-\mu)^{\mathrm{T}} \Sigma^{-1}(\mathrm{x}-\mu)} fx(x1,…,xk)=(2π)k∣Σ∣1e−21(x−μ)TΣ−1(x−μ)
然后按照上面的公式计算 B D B_D BD得到的是:
B D = 1 8 ( μ 1 − μ 2 ) T Σ − 1 ( μ 1 − μ 2 ) + 1 2 ln ( det Σ det Σ 1 det Σ 2 ) , Σ = 1 2 ( Σ 1 + Σ 2 ) B_{D}=\frac{1}{8}\left(\boldsymbol{\mu}_{1}-\boldsymbol{\mu}_{2}\right)^{T} \Sigma^{-1}\left(\boldsymbol{\mu}_{1}-\boldsymbol{\mu}_{2}\right)+\frac{1}{2} \ln \left(\frac{\operatorname{det} \Sigma}{\sqrt{\operatorname{det} \Sigma_{1} \operatorname{det} \Sigma_{2}}}\right), \Sigma=\frac{1}{2}\left(\Sigma_{1}+\Sigma_{2}\right) BD=81(μ1−μ2)TΣ−1(μ1−μ2)+21ln(detΣ1detΣ2detΣ),Σ=21(Σ1+Σ2)
接着将 B D B_D BD拆开,分成 B 1 B_1 B1和 B 2 B_2 B2,然后将 p p p和 q q q分布的参数带入到 B D B_D BD中得到了:
B 1 = 1 4 ( a 1 + a 2 ) ( y 1 − y 2 ) 2 + ( b 1 + b 2 ) ( x 1 − x 2 ) 2 + 2 ( c 1 + c 2 ) ( x 2 − x 1 ) ( y 1 − y 2 ) ( a 1 + a 2 ) ( b 1 + b 2 ) − ( c 1 + c 2 ) 2 , B 2 = 1 2 ln ( ( a 1 + a 2 ) ( b 1 + b 2 ) − ( c 1 + c 2 ) 2 4 ( a 1 b 1 − c 1 2 ) ( a 2 b 2 − c 2 2 ) ) , \begin{array}{c} B_{1}=\frac{1}{4} \frac{\left(a_{1}+a_{2}\right)\left(y_{1}-y_{2}\right)^{2}+\left(b_{1}+b_{2}\right)\left(x_{1}-x_{2}\right)^{2}+2\left(c_{1}+c_{2}\right)\left(x_{2}-x_{1}\right)\left(y_{1}-y_{2}\right)}{\left(a_{1}+a_{2}\right)\left(b_{1}+b_{2}\right)-\left(c_{1}+c_{2}\right)^{2}}, \\ B_{2}=\frac{1}{2} \ln \left(\frac{\left(a_{1}+a_{2}\right)\left(b_{1}+b_{2}\right)-\left(c_{1}+c_{2}\right)^{2}}{4 \sqrt{\left(a_{1} b_{1}-c_{1}^{2}\right)\left(a_{2} b_{2}-c_{2}^{2}\right)}}\right), \end{array} B1=41(a1+a2)(b1+b2)−(c1+c2)2(a1+a2)(y1−y2)2+(b1+b2)(x1−x2)2+2(c1+c2)(x2−x1)(y1−y2),B2=21ln(4(a1b1−c12)(a2b2−c22)(a1+a2)(b1+b2)−(c1+c2)2),
B D = B 1 + B 2 B_D=B_1+B_2 BD=B1+B2,因此, B C B_C BC的close-form表示为 B C = e − B D B_C=e^{-B_D} BC=e−BD,并且 B 2 B_2 B2仅仅跟协方差矩阵参数相关,而跟均值参数无关,因此,中心点和形状可以分别考虑,然后 B 1 B_1 B1和 B 2 B_2 B2可以增加不同的系数进行来进行不同的考虑。然而巴氏距离并不满足三角不等式,使用Hellinger distance(海林格距离)可以满足距离度量
H D ( p , q ) = 1 − B c ( p , q ) H_{D}(p, q)=\sqrt{1-B_{c}(p, q)} HD(p,q)=1−Bc(p,q)
并且可以表示成高斯分布参数的函数,并且 0 ≤ H D ( p , q ) ≤ 1 0 \leq H_{D}(p, q) \leq 1 0≤HD(p,q)≤1,对于高斯分布来说,总是有 H D ( p , q ) > 0 H_{D}(p, q) >0 HD(p,q)>0,当 p ≠ q p \neq q p=q时,并且由于高斯分布是无穷的,因此 B C ( p , q ) B_C(p,q) BC(p,q)总是严格正的。在本文中提出使用 1 − H D ( p , q ) 1-H_D(p,q) 1−HD(p,q)来表示两个高斯分布之间的相似性,并记作ProbIoU,解决了GWD中的一些问题.
本文中给定预测边界框 p = ( x 1 , y 1 , a 1 , b 1 , c 1 ) \boldsymbol{p}=\left(x_{1}, y_{1}, a_{1}, b_{1}, c_{1}\right) p=(x1,y1,a1,b1,c1)和真实边界框 q = ( x 2 , y 2 , a 2 , b 2 , c 2 ) \boldsymbol{q}=\left(x_{2}, y_{2}, a_{2}, b_{2}, c_{2}\right) q=(x2,y2,a2,b2,c2)之间的基于ProbIoU的损失函数为:
L 1 ( p , q ) = H D ( p , q ) = 1 − ProbIoU ( p , q ) ∈ [ 0 , 1 ] , L 2 ( p , q ) = B D ( p , q ) = − ln ( 1 − L 1 2 ( p , q ) ) ∈ [ 0 , ∞ ] , \mathcal{L}_{1}(\boldsymbol{p}, \boldsymbol{q})=H_{D}(\boldsymbol{p}, \boldsymbol{q})=1-\operatorname{ProbIoU}(\boldsymbol{p}, \boldsymbol{q}) \in[0,1] , \\ \mathcal{L}_{2}(\boldsymbol{p}, \boldsymbol{q})=B_{D}(\boldsymbol{p}, \boldsymbol{q})=-\ln \left(1-\mathcal{L}_{1}^{2}(\boldsymbol{p}, \boldsymbol{q})\right) \in[0, \infty] , L1(p,q)=HD(p,q)=1−ProbIoU(p,q)∈[0,1],L2(p,q)=BD(p,q)=−ln(1−L12(p,q))∈[0,∞],
上面有两个基于ProbIoU的损失函数,首先第一个损失 L 1 ( p , q ) \mathcal{L}_{1}(\boldsymbol{p}, \boldsymbol{q}) L1(p,q)当GBBs之间相距很远时, L 1 ( p , q ) \mathcal{L}_{1}(\boldsymbol{p}, \boldsymbol{q}) L1(p,q)的值非常接近1,产生的梯度值非常小,导致收敛很慢。 L 2 ( p , q ) \mathcal{L}_{2}(\boldsymbol{p}, \boldsymbol{q}) L2(p,q)并不存在这个问题,不过不能很好地表示和IoU之间的关系。当前的训练方式为:首先采用 L 2 ( p , q ) \mathcal{L}_{2}(\boldsymbol{p}, \boldsymbol{q}) L2(p,q)进行训练,然后再采用 L 1 ( p , q ) \mathcal{L}_{1}(\boldsymbol{p}, \boldsymbol{q}) L1(p,q)进行训练
对于HBB边界框时:
- 协方差矩阵中的 c c c变成了0,然后对于协方差矩阵的要求变成了 a > 0 , b > 0 a>0,b>0 a>0,b>0
- 对于HBB边界框参数 p B = ( x 1 , y 1 , W 1 , H 1 ) \boldsymbol{p}_{B}=\left(x_{1}, y_{1}, W_{1}, H_{1}\right) pB=(x1,y1,W1,H1),基于之前提到的计算均值和协方差矩阵的方式能够得到GBB的表示方式 p G = ( x 1 , y 1 , a 1 , b 1 ) = f ( p B ) = ( x 1 , y 1 , W 1 2 / 12 , H 1 2 / 12 ) \boldsymbol{p}_{G}=\left(x_{1}, y_{1}, a_{1}, b_{1}\right)=\boldsymbol{f}\left(\boldsymbol{p}_{B}\right)=\left(x_{1}, y_{1}, W_{1}^{2} / 12, H_{1}^{2} / 12\right) pG=(x1,y1,a1,b1)=f(pB)=(x1,y1,W12/12,H12/12),同样对于GT边界框进行相同的变换得到 q G = ( x 2 , y 2 , a 2 , b 2 ) = f ( q B ) = ( x 2 , y 2 , W 2 2 / 12 , H 2 2 / 12 ) \boldsymbol{q}_{G}=\left(x_{2}, y_{2}, a_{2}, b_{2}\right)=\boldsymbol{f}\left(\boldsymbol{q}_{B}\right)=\left(x_{2}, y_{2}, W_{2}^{2} / 12, H_{2}^{2} / 12\right) qG=(x2,y2,a2,b2)=f(qB)=(x2,y2,W22/12,H22/12),
- 上面提到的两个损失中包含的 B D ( p , q ) B_D(p,q) BD(p,q)项对于旋转框就可以简化成:
B D ( p G , q G ) = 1 4 ( ( x 1 − x 2 ) 2 a 1 + a 2 + ( y 1 − y 2 ) 2 b 1 + b 2 ) + 1 2 ln ( ( a 1 + a 2 ) ( b 1 + b 2 ) ) − 1 4 ln ( a 1 a 2 b 1 b 2 ) B_{D}\left(\boldsymbol{p}_{G}, \boldsymbol{q}_{G}\right)=\frac{1}{4}\left(\frac{\left(x_{1}-x_{2}\right)^{2}}{a_{1}+a_{2}}+\frac{\left(y_{1}-y_{2}\right)^{2}}{b_{1}+b_{2}}\right)+\frac{1}{2} \ln \left(\left(a_{1}+a_{2}\right)\left(b_{1}+b_{2}\right)\right)-\frac{1}{4} \ln \left(a_{1} a_{2} b_{1} b_{2}\right) BD(pG,qG)=41(a1+a2(x1−x2)2+b1+b2(y1−y2)2)+21ln((a1+a2)(b1+b2))−41ln(a1a2b1b2)
当使用上面的损失函数进行梯度反向传播时,需要计算 ∂ B D / ∂ p G \partial B_{D} / \partial \boldsymbol{p}_{G} ∂BD/∂pG,并且有 ∂ B D / ∂ p G = 0 ⇔ p G = q G ⇔ p B = q B \partial B_{D} / \partial \boldsymbol{p}_{G}=\mathbf{0} \Leftrightarrow \boldsymbol{p}_{G}=\boldsymbol{q}_{G} \Leftrightarrow \boldsymbol{p}_{B}=\boldsymbol{q}_{B} ∂BD/∂pG=0⇔pG=qG⇔pB=qB,没有弄明白为什么when L 2 \mathcal{L}_2 L2用于localization loss时不能出现梯度消失呢?关于收敛慢的原因由于 L 1 = 1 − exp ( − B D ) \mathcal{L}_{1}=\sqrt{1-\exp \left(-B_{D}\right)} L1=1−exp(−BD)导致梯度计算中存在指数项,当预测边界框和真实边界框相差很远时,此时 B C ( p , q ) ≈ 0 , B D ( p , q ) → inf B_C(p,q)\approx0,B_D(p,q)\rightarrow\inf BC(p,q)≈0,BD(p,q)→inf,从而指数项的梯度值很小,通过 L 2 \mathcal{L}_2 L2引入指数函数倒数将指数项去掉来进行收敛。因此这里采用的是two-stage training protocol首先采用 L 2 \mathcal{L}_2 L2先训练一会,然后再 切换到 L 1 \mathcal{L}_1 L1进行训练,那么什么时候是最佳的切换时机呢?
(六) Experiments
训练中的设置,仅仅替换掉损失函数,其他的保持相同,对于两种loss切换的设置为:使用 L 2 L_2 L2损失训练总epoch数的一半,剩下的一半切换到 L 1 L_1 L1,并且 L 1 L_1 L1损失和 L 2 L_2 L2损失在同分类损失结合时,分别有 w 1 w_1 w1和 w 2 w_2 w2参数,在作者的实验中设置的是 w 2 ≈ 5 w 1 w_2 \approx5w_1 w2≈5w1,来保持从 L 2 L_2 L2切换到 L 1 L_1 L1时具有相同的梯度,因此这里设置了一个超参数 w w w,令 w 1 = w , w 2 = 5 w w_1=w,w_2=5w w1=w,w2=5w
效果好的我都有点儿怀疑~,真的能够有这么大的提升嘛?
不过在旋转框中的表现效果看着并没有GWD出色啊~
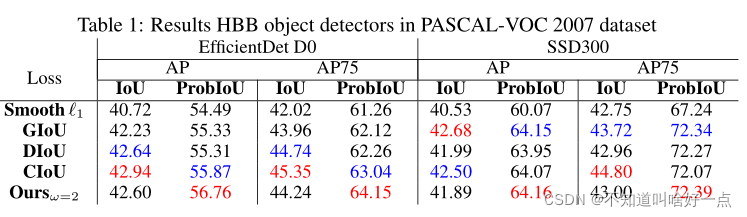
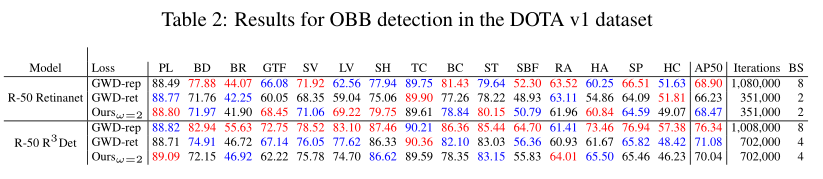
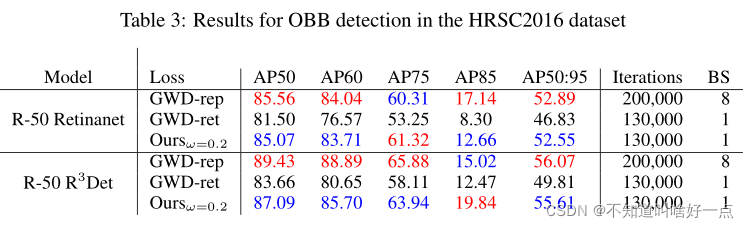
(七) Conclusion
本文引入了对于目标描述的GBB表示,能够用在mask,HBB以及OBB任务上,并且提出了用于损失计算的ProbIoU。














 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









