






目录
一.创建一个新目录
- 创建 LXML目录
- 新建python文件
- 命名python文件名
二.打开终端
- 使用pip 安装lxml
- 完成后lxml库导入etree包
lxml库是Python中一一个强大的XML处理库,支持HTML和XML的解析,支持XPath解析方式。
LXML库的主要优点是易于使用,在解析大型文档时速度非常快,归档的也非常好,并且提供了简单的转换方法来将数据转换为Python数据类型,从而使文件操作更容易。
3.先打个包
4.利用for循环的方式来设置需要爬取的数据量
5.发生请求
6.提取数据
7.用xpath提取数据,列表类型
小编先分享几个关于爬虫的基础知识的网站
| 崔庆才爬虫博客(先看) http://cuiqingcai.com/1052.html 廖雪峰python学习网站 http://www.liaoxuefeng.c/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000 爬虫实例http://cuiqingcai.com/4352.html 知乎小白爬虫具体案例+分析 https://www.zhihu.com/collection/159805421 知乎爬虫之知识集锦 (遇到问题时再看) https://zhuanlan.zhihu.com/p/21479334 |
问题描述:我有一个朋友,最近想买房,想要与自己的房子度过一生。于是我作为朋友两肋插刀,正义的化身,决定为其充满魔幻现实的人生再添加一抹亮色,让她深陷其中无法自拔,帮她用Python获取了属于自己的house。
- 首先我们先新建LXMl目录
 并且将目录命名为LXML
并且将目录命名为LXML
2.在LXML目录下新建python文件

命名python文件名为爬取具体房价(小编这里是不建议大家中文命名的哈!!很容易报错)
3.打开终端
- 用pip安装lxml,requests,pandas
pip install lxml
pip install requests
pip install pandas

lxml库是Python中一一个强大的XML处理库,支持HTML和XML的解析,支持XPath解析方式。
LXML库的主要优点是易于使用,在解析大型文档时速度非常快,归档的也非常好,并且提供了简单的转换方法来将数据转换为Python数据类型,从而使文件操作更容易。
- 等待三个库安装完毕

- 使用requests库请求网页内容

- 导入lxml库的etree包
![]()
- 使用pandas库快速分析数据

- 利用for循环的方式来设置需要爬取的数据量

- 获取url地址 目标地址

-
因为字符和网页网址不能同步存在所以需要用str
- 发生请求

- 提取数据
- 1:用etree的方式获取数据

- 2:用xpath的方法获取数据

- 设置一个空的列表,作为爬取信息的容器

- 开始爬取信息

- 运行一下 成功!!
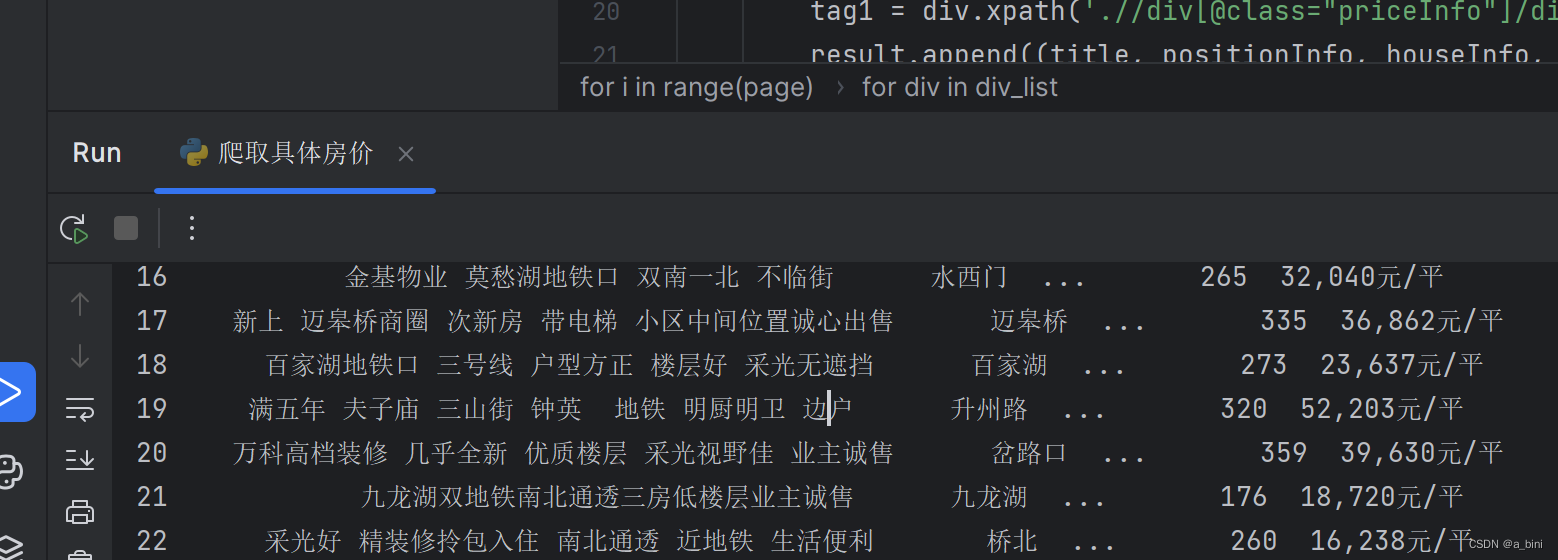
- 完整代码

这样我们就成功爬虫house价格咯!!
今天的分享就到此为止咯!谢谢大家的喜欢,我们下周再见!














 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









