







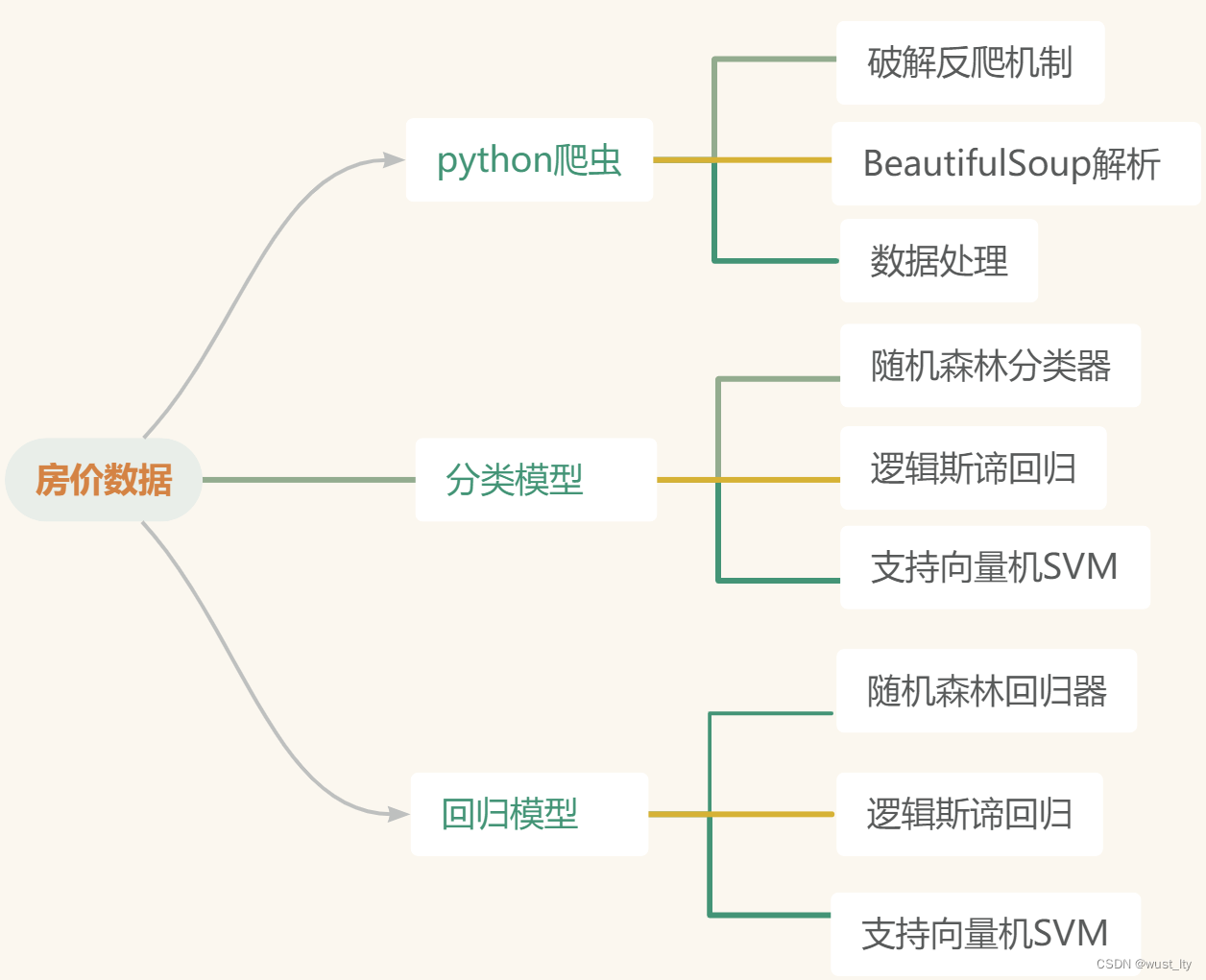
往期精彩内容:
Python房价分析(三)支持向量机SVM分类模型-CSDN博客
1.常见的房价数据网站如58同城、安居客、房天下都有一定反爬措施,注意构建用户代理池和ip池来避免反爬机制
2.以武汉市为例,爬取武汉市 区域 位置 户型 建筑面积 均价等房价相关数据
3.采用经典的 BeautifulSoup 方法借助from bs4 import BeautifulSoup,然后通过soup = BeautifulSoup(html, "lxml")将文本转换为特定规范的结构,利用find系列方法进行解析,代码如下
4.代码:
(1)首先构建User-Agent池
def get_user_agent):
import random
user_agents = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729',
]
user_agent = random.choice(user_agents) # 随机抽取对象
return user_agent(2) 获取网页信息
def get_page_data(data_url):
headers = {'User-Agent': get_ua()}
req = urllib.request.Request(data_url, headers=headers)
content = urllib.request.urlopen(req).read().decode('utf-8') # python3
page = BeautifulSoup(content, 'html.parser')
return page(3)数据解析
def analyse_data(page):
list_content = page.find('div', attrs={'class': 'key-list imglazyload'})
if list_content == None:
print('error:反爬失败')
return None
else:
item_content = list_content.find_all('div', class_='item-mod')
df_data = pd.DataFrame(columns=['city','quyu','address','house_type','area','price'])
count = 0
for item in item_content:
if item.find('div', class_='infos').find('a',class_='address') is None:
continue
index_data = item.find('div', class_='infos')
# 位置区域
all_address = index_data.find('a',class_='address').find('span').text.split()
city = all_address[1]
quyu = all_address[2]
address = all_address[4]
# 户型面积Item
house_item = index_data.find('a', class_='huxing')
if house_item is not None:
# 有户型 有建筑面积 没户型 有建筑面积
house_type = index_data.find('a', class_='huxing').find('span').text
area = index_data.find('a', class_='huxing').find('span', class_='building-area').text
else:
# 没有户型且尚未开盘
house_type = '尚未开盘'
area = 0
# 房价Item
item_price = item.find('a', class_='favor-pos')
if item_price.find('p', class_='price') is not None:
# 均价
price = item_price.find('p', class_='price').find('span').text
else:
if item_price.find('p', attrs={'class': 'favor-tag around-price'}) is not None:
# 周边均价
price = item_price.find('p', attrs={'class': 'favor-tag around-price'}).find('span').text
else:
# 售价待定
price = 0
df_data.loc[count] = [address, house_type, area, price]
count += 1
return df_data(4)把数据写入文件中
if __name__ == '__main__':
page_list = []
# 页面总页数
ALL_page = 37
for i in range(ALL_page):
page_list.append(str(i+1))
# 读取空文件
wuhan = pd.read_csv('wuhan.csv')
for page in page_list:
url = 'https://wh.fang.anjuke.com/loupan/all/p' + page + '/'
# url = "https://wh.fang.anjuke.com/loupan/all/"
page = get_page_data(url)
df_data = analyse_data(page)
# 写入CSV文件
wuhan = pd.concat([wuhan, df_data])
print(len(wuhan))
wuhan.set_index('address', inplace=True)
wuhan.to_csv('wuhan.csv')
print(wuhan)5.数据样例
















 5619
5619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











