







参考自李宏毅课程-人类语言处理
二、BERT和它的家族-介绍和微调

1. What is pre-train model
这里所说的pre-train model是输入一串tokens,能够输出一串vectors,且每个vector可以表示对应的语义的模型,这些vectors也被称作为embeddings。以前常用的模型有word2vec,Glove等,这里并没有详细介绍,之后需要单独去看,由于英文单词太多了,只要来一个新单词,整个embedding的模型就需要重新train,为了解决这个问题,有了fasttext。fasttext是针对英文的,针对中文的则是输入图片,让模型通过图片中文字的偏旁部首去预测出训练时没见过的文字的embedding。这种训练embedding的方式,根据语言的不同会有不同的方法。
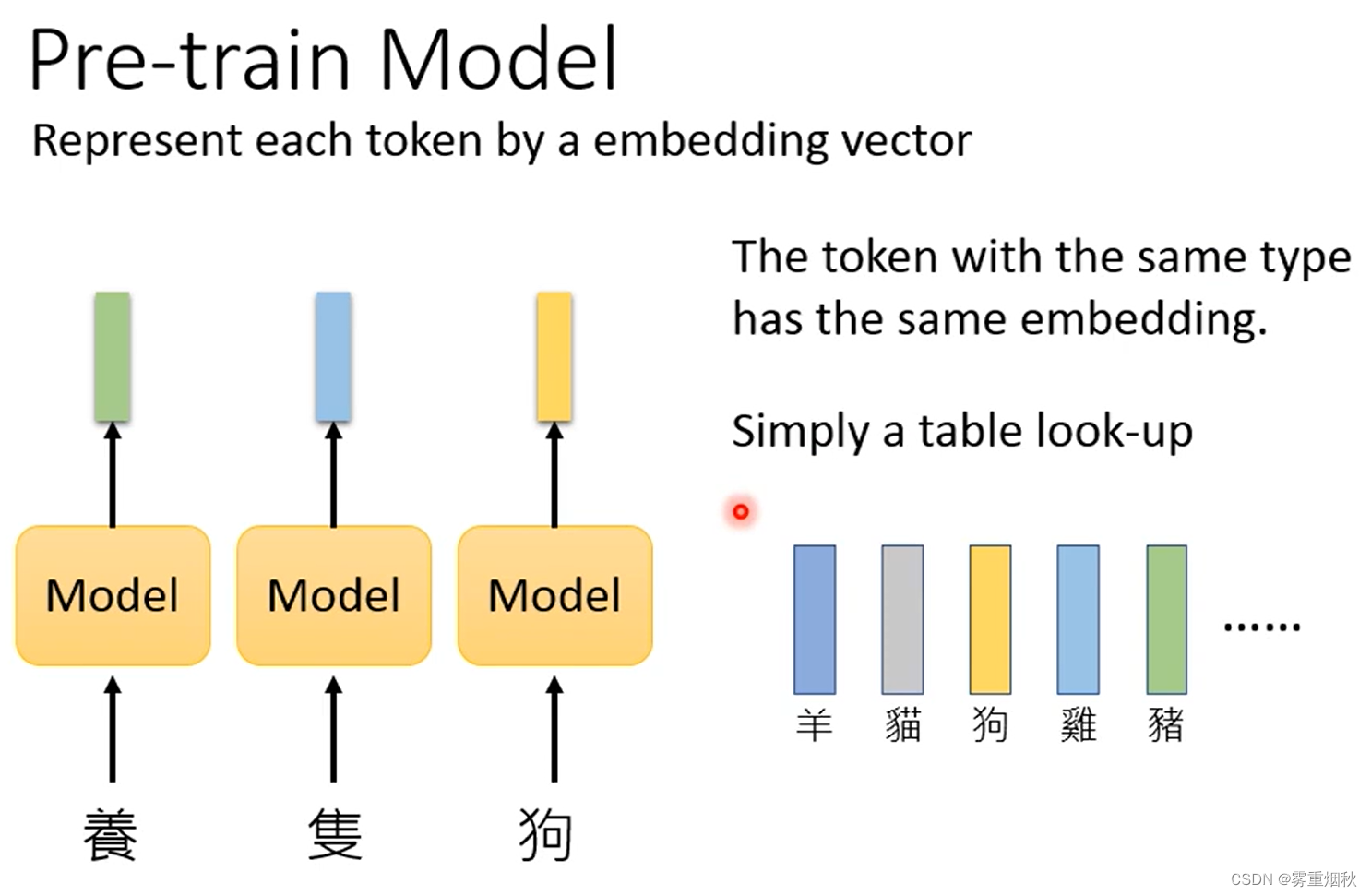
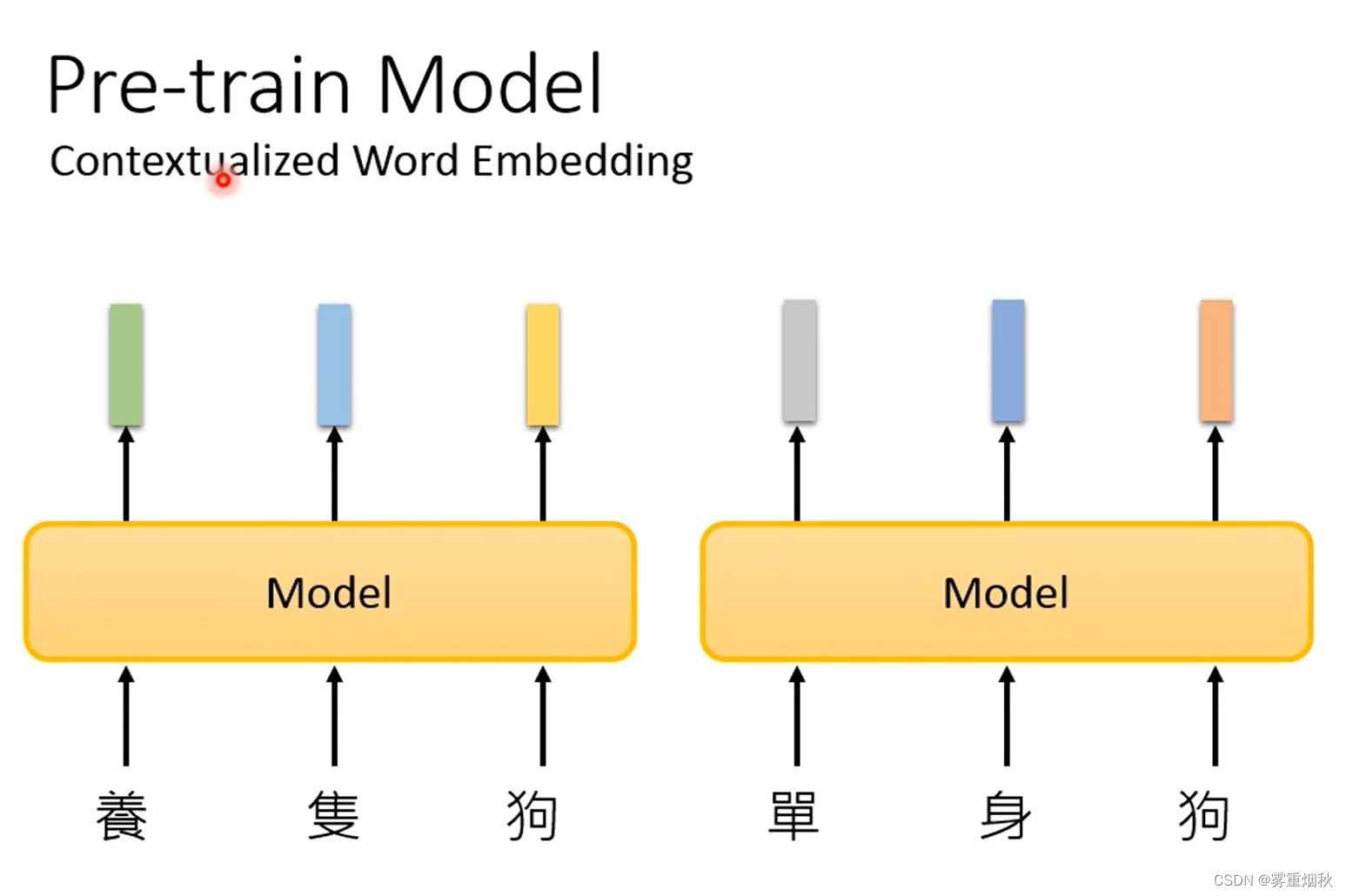
但是有一个问题,如果输入的token是一样的,那么每次出来的vector也一样,所以希望模型可以在输入某个token的embedding的时候,考虑上下文信息,这叫做contextualized word embedding。这样的模型基本就是基于LSTM或者self-attention layer去搭建的一个seq2seq的模型(如Bert,Megatron,Turing NLG等),可以理解为encoder。
为了让模型效果变好,所用的模型越来越大,参数量越来越多,有一些模型压缩方面的技术,比如Distill BERT,Tiny BERT,ALBERT等,这里没有细说。
2. How to fine-tune
将pre-train model应用到各种任务中,这里将任务按照输入和输出分类
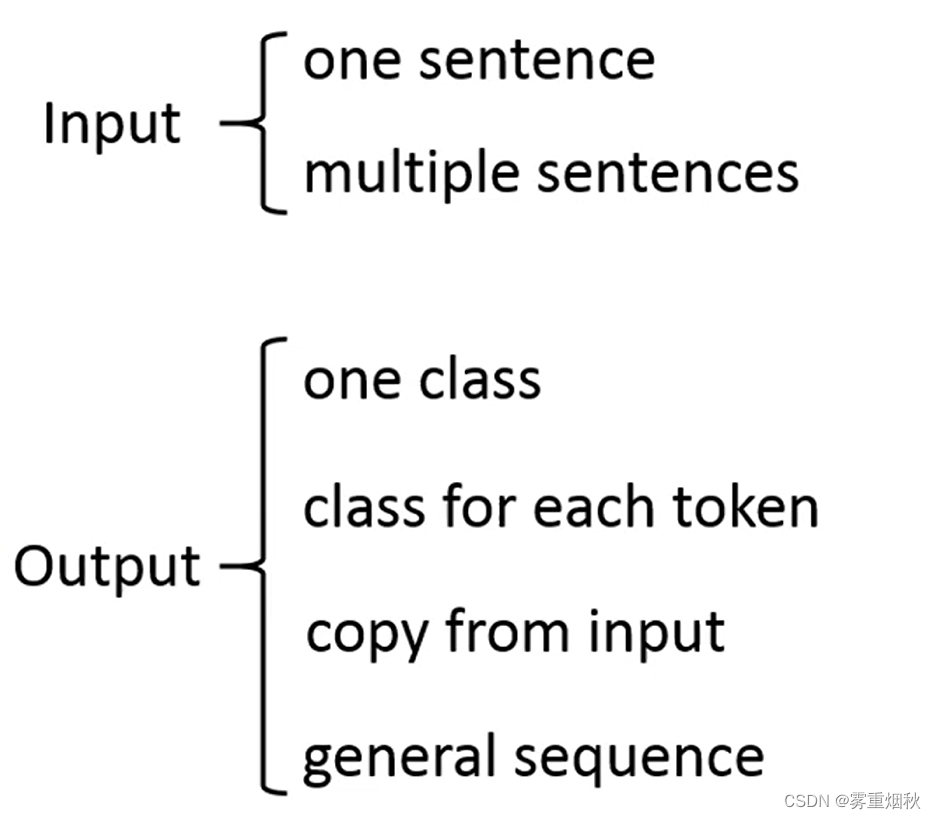
2.1 Input
- one sentence
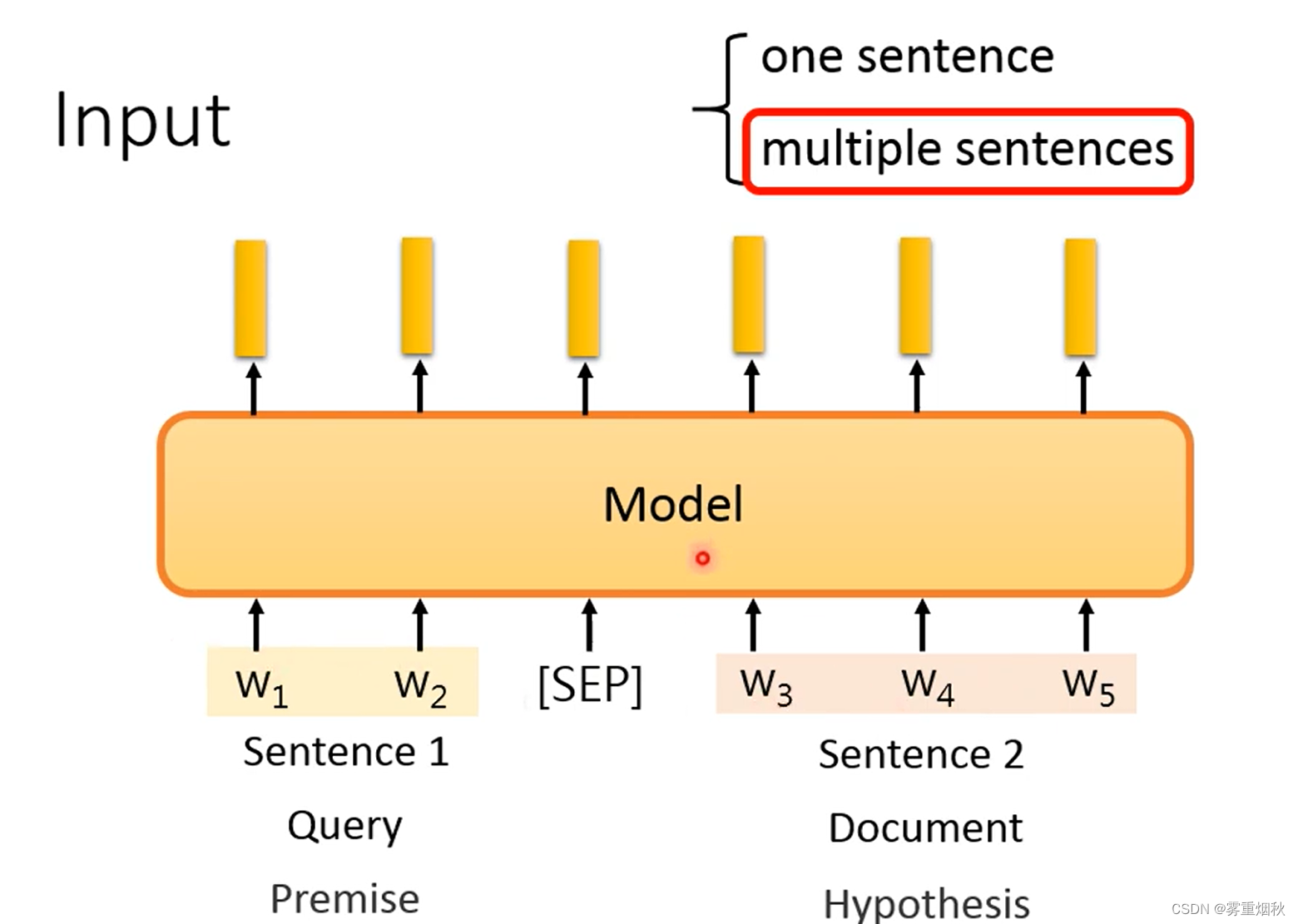
输入只有一个句子时,直接输入就行了,因为pre-train model也是一个句子的输入。 - multiple sentences
输入有多个句子时,用一个叫做“[SEP]”的分隔符将两个句子拼成一个句子,然后再输入。
2.2 Output
- one class
输入只有一个分类的时候,有两种做法,一种做法是,在输入的开头加“[CLS]”token,然后在“[CLS]”对应的输出的embedding后面加一个head,也就是比较浅的神经网络,可以是一层全连接,然后输出想要的类别数量;另一种做法是,把所有token的输出都输入到一个head当中去,然后输出想要的类别数量。
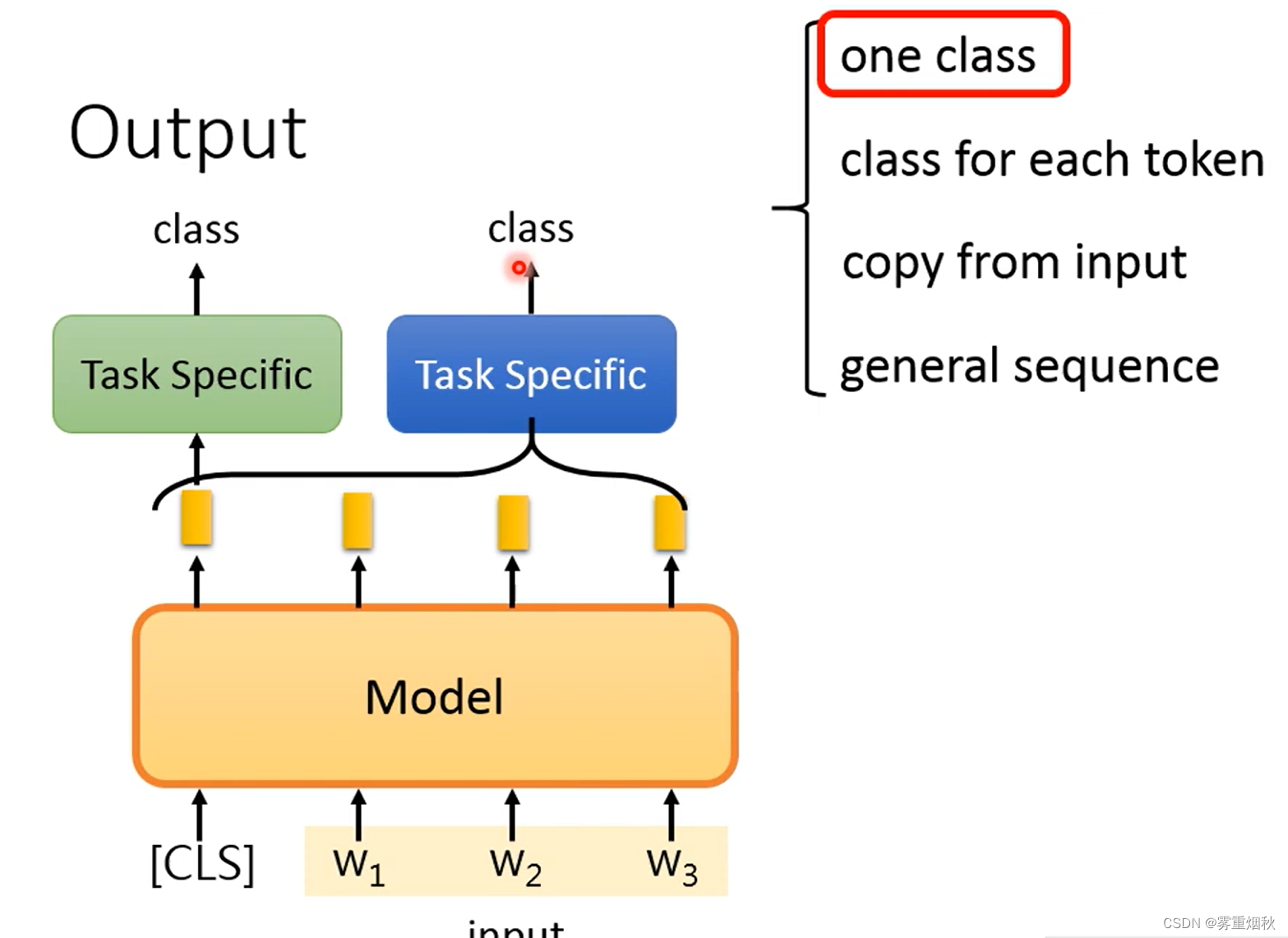
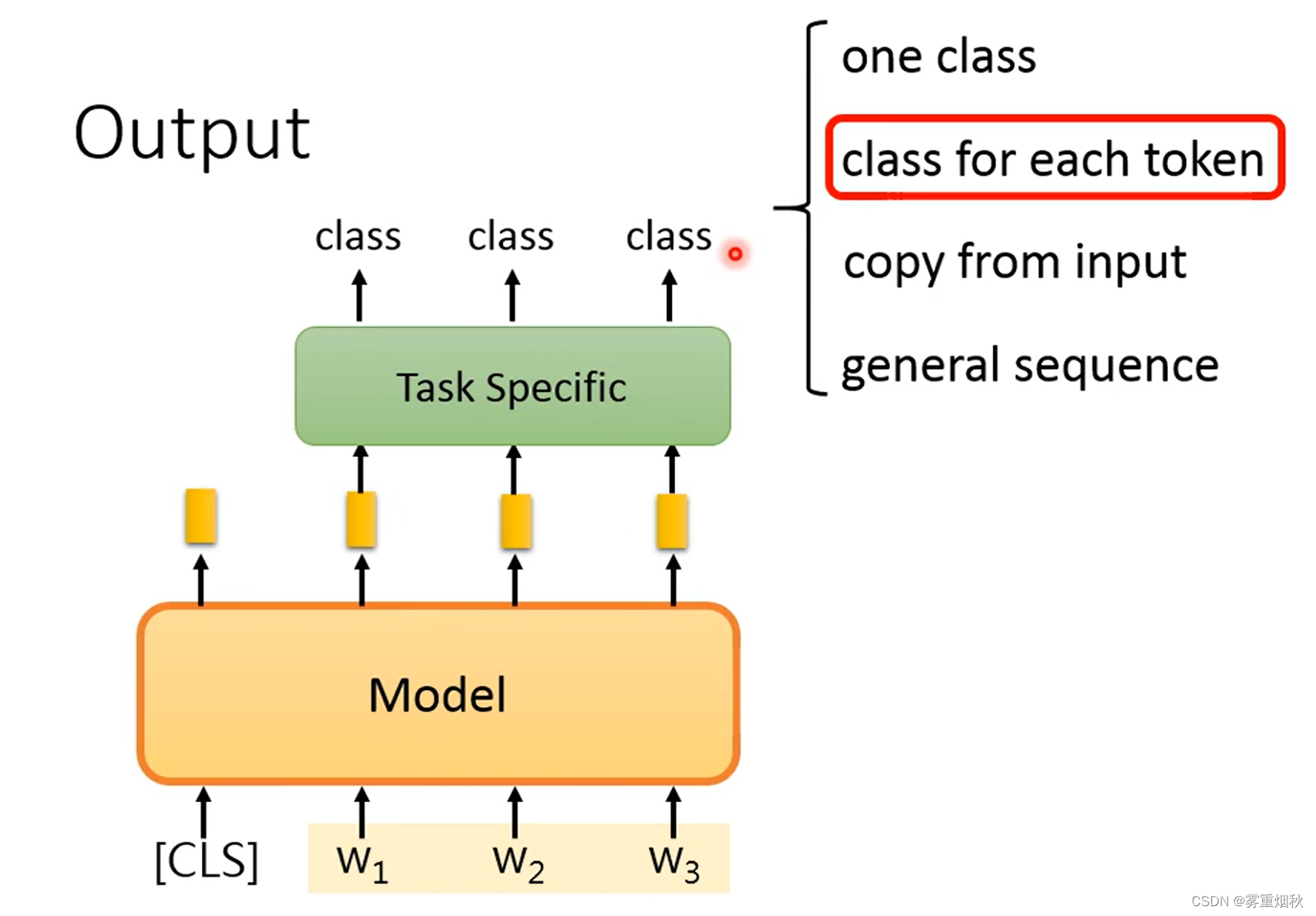
- class for each token
当每个token都要做分类的时候,那在模型的后面加一个seq2seq的head就可以了。
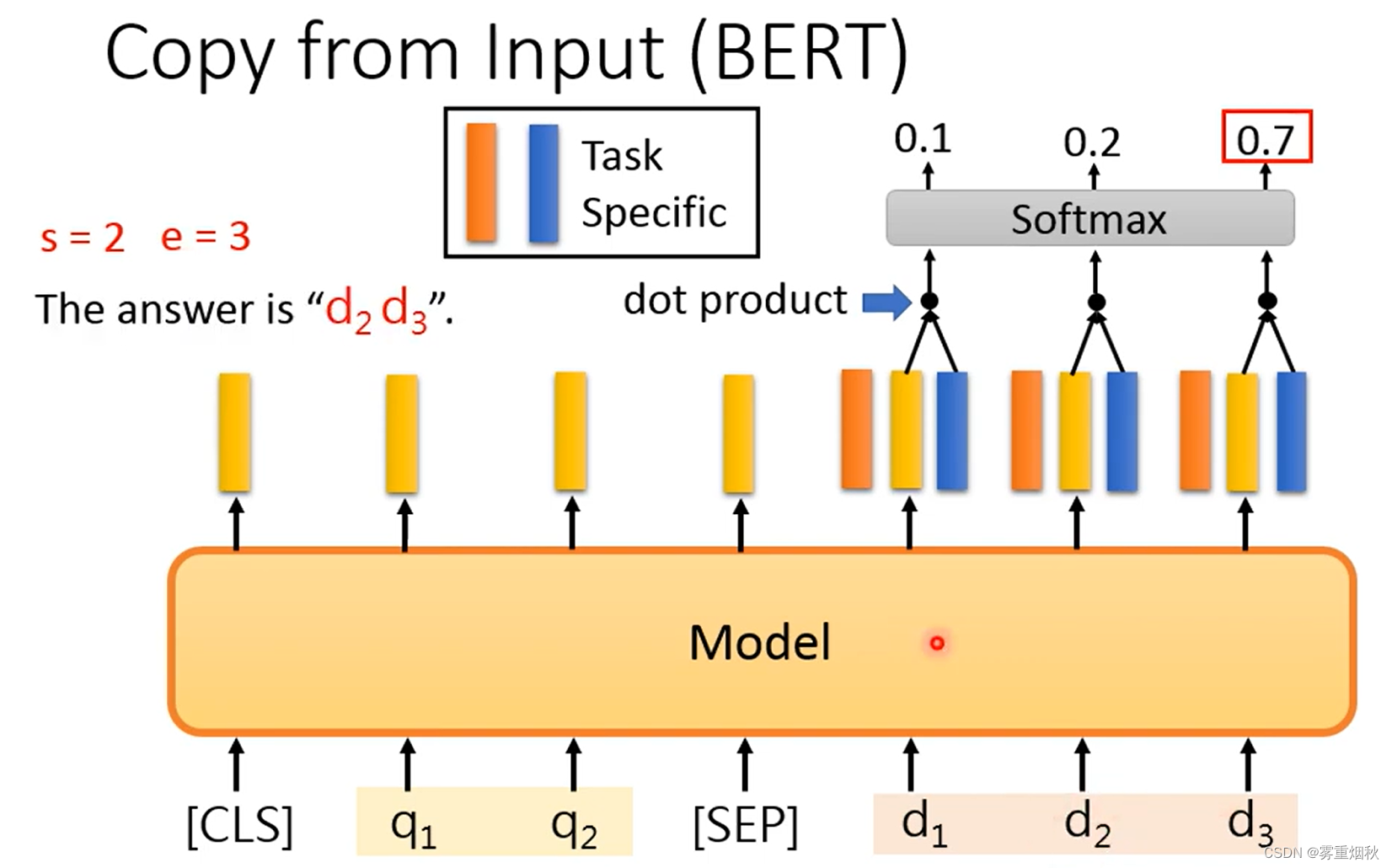
- copy from input
比如,当任务是Extraction-based QA时,输入有question和document,因此加入“[SEP]”分隔符合并成一个序列,然后输出是找出document中的哪个token为答案的start,哪个为答案的end,这个时候,就要用两个额外的向量去分别和document中每个token的输出做dot product,然后和start向量最相关的token是start token,和end向量最相关的token是end token。
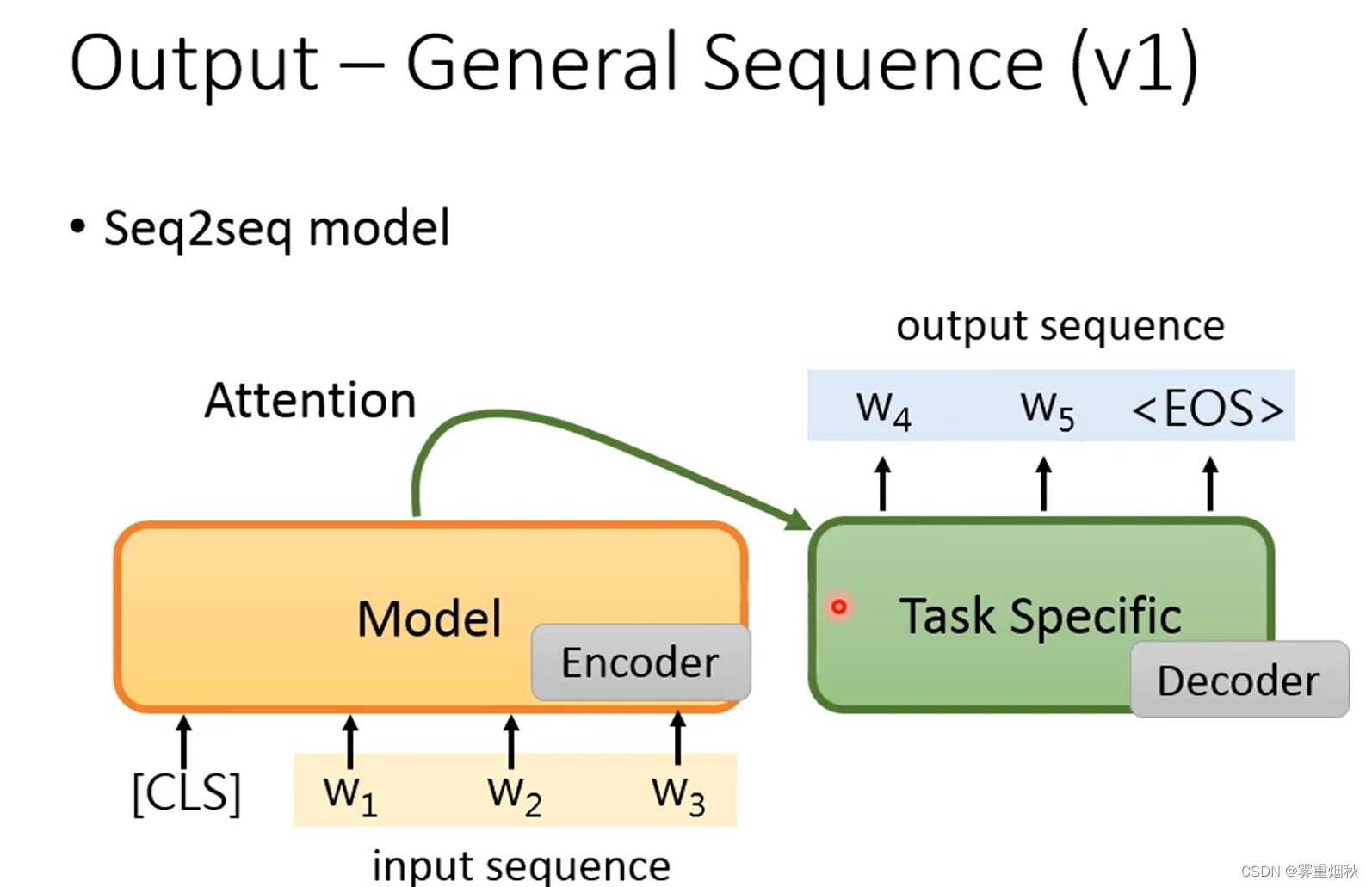
- general sequence
当希望模型的输出也是一个sequence的时候,可以把pre-train model的输出作为输入,在后面接一个decoder,让decoder去完成输出sequence的步骤,这样的坏处是decoder是一个比较大的模型,同时也没有进行pre-train。
另一种做法是把pre-train model当作decoder去做,这就需要在inout后面加一个类似“[SEP]”的特殊符号,然后把符号的输出丢到自定义的head中,然后输出一个token,然后把这个token当作输入,重复这个过程,直到输出"[EOS]"。
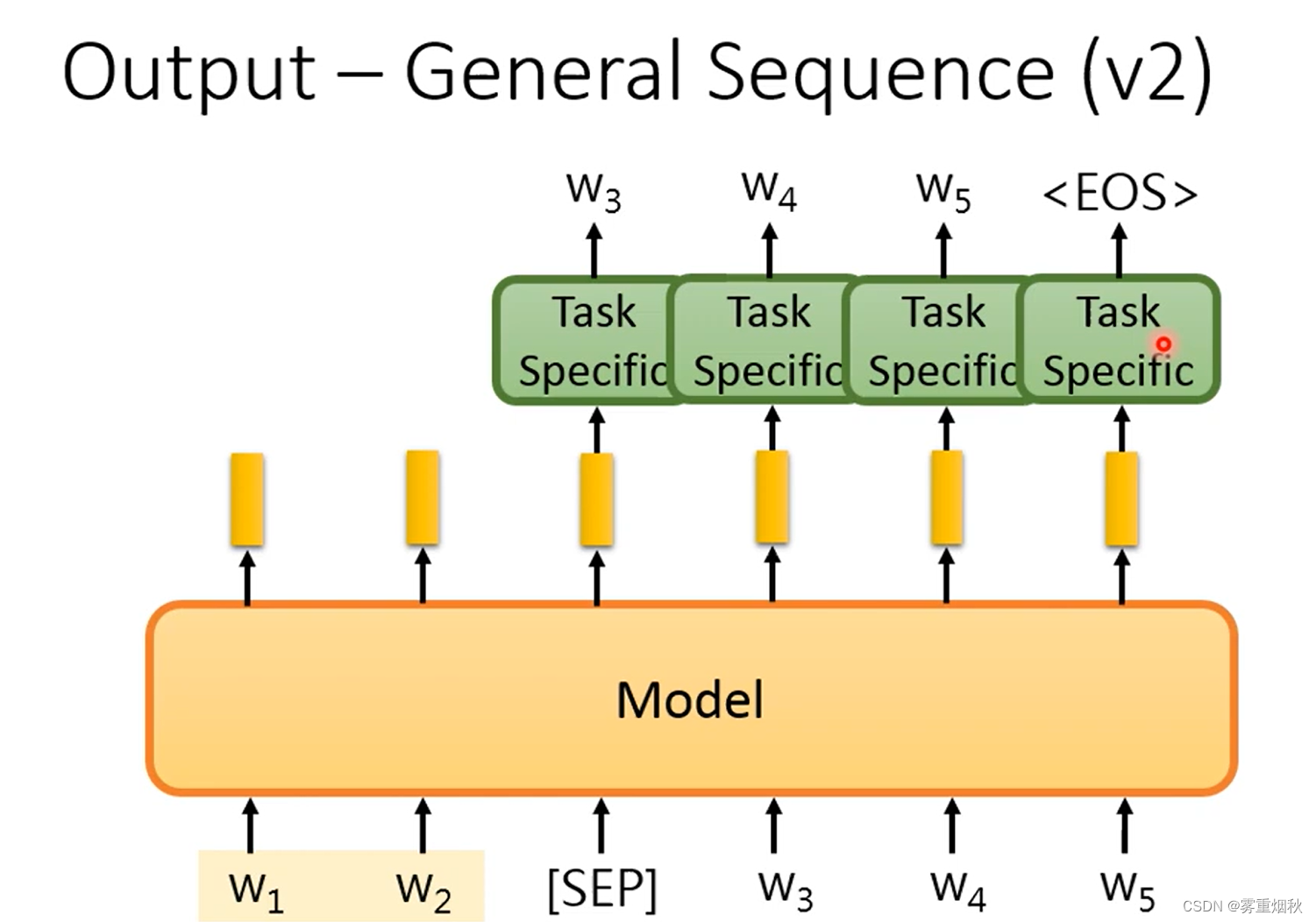
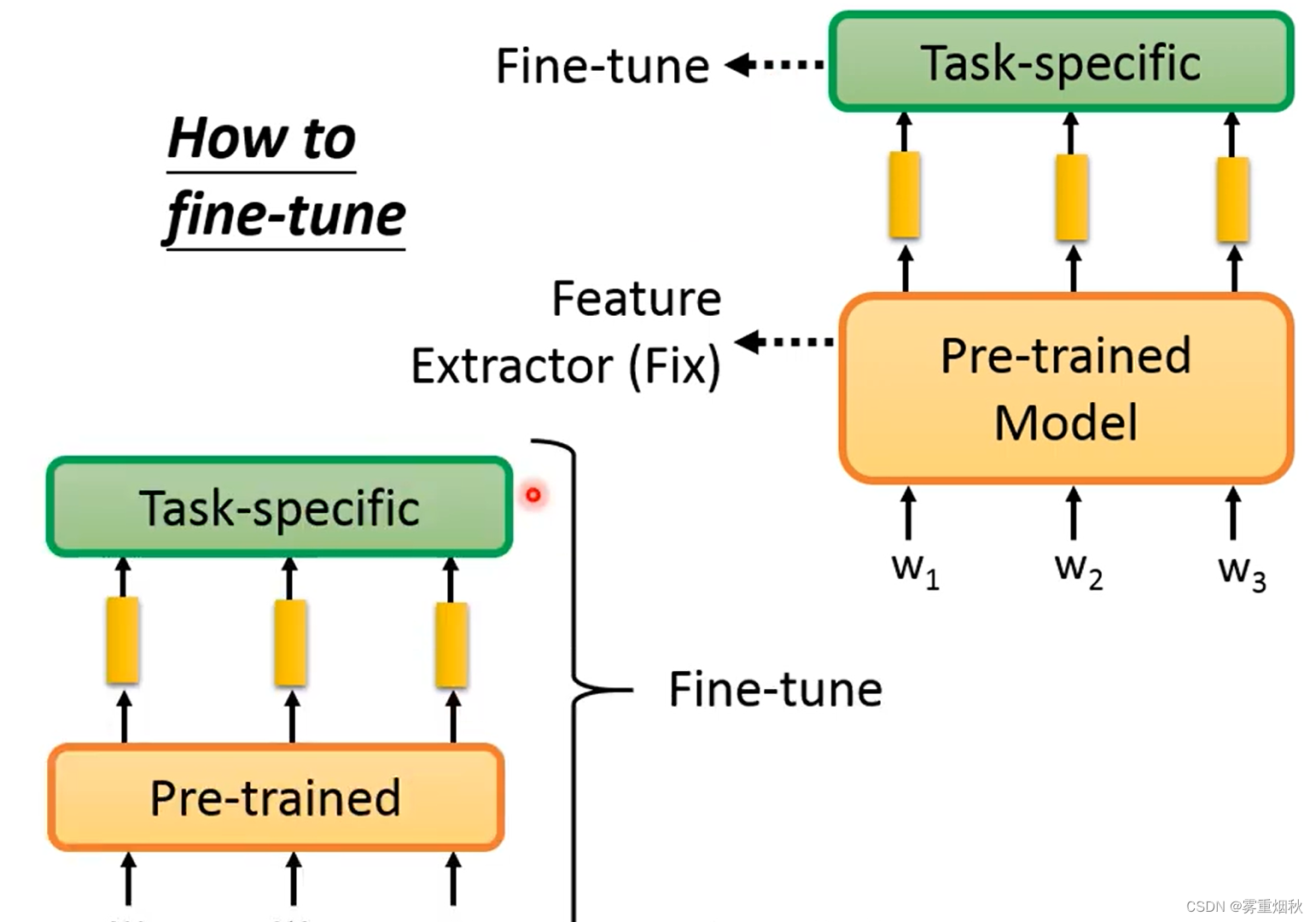
2.3 Fine-tune
- 在训练的时候,可以把pre-trained model的weights都固定住,只去训练最后自定义加上去的head。
- 也可以直接训练整个模型,虽然模型很大,但是大部分的weights是与训练过的,所以训练起来没有重头训练困难,实际经验也是这种方法比上面的方法更好。
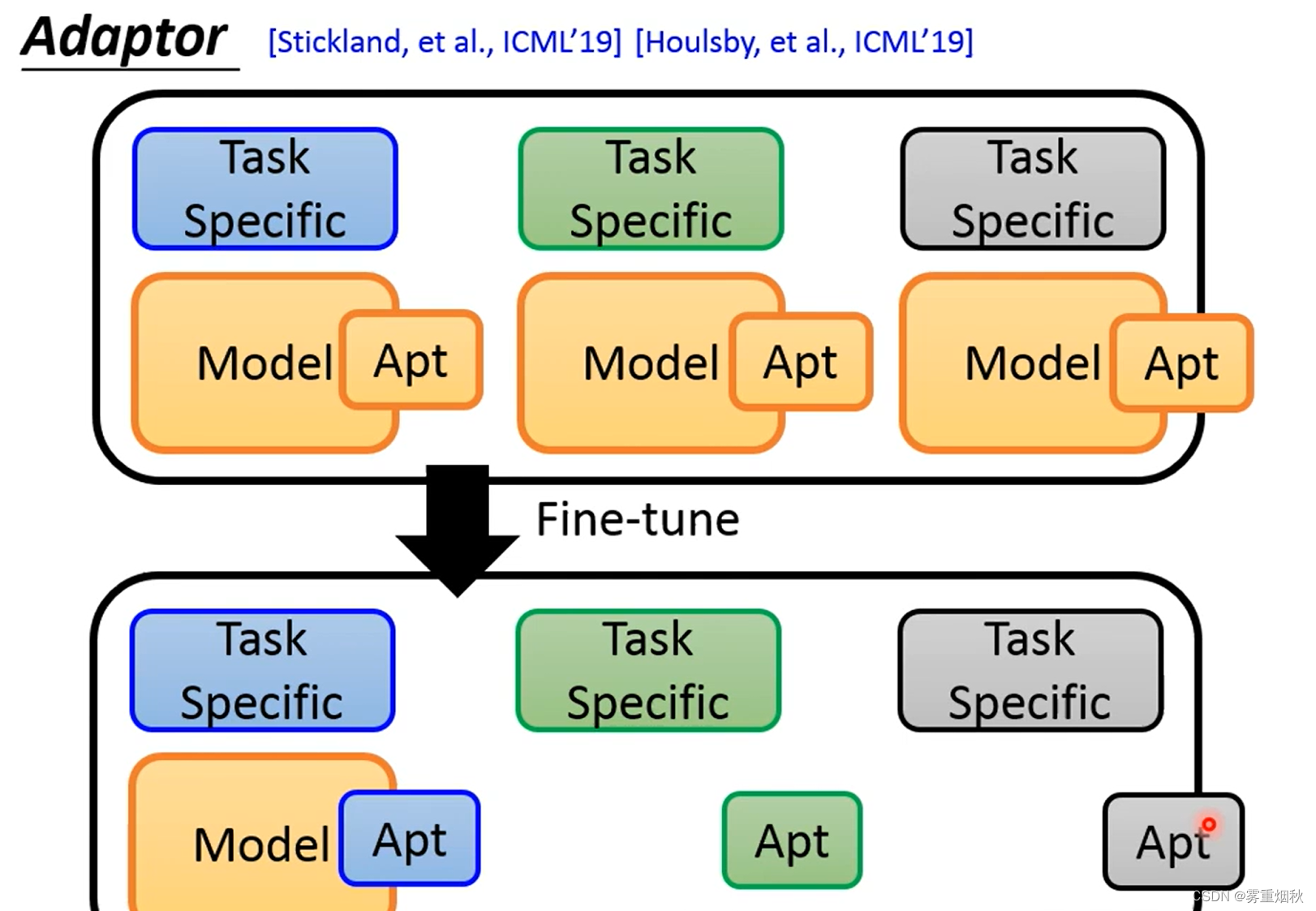
如果要用第二种方法,不同的tast需要train不同的模型,而这样的模型往往非常大,这就很浪费计算资源和存储资源,所以就有了Adaptor。Adaptor是我们在pretrained-model里加一些layer,然后训练的时候就训练这些layer和最后的head,这样pretrained model还是不动的。
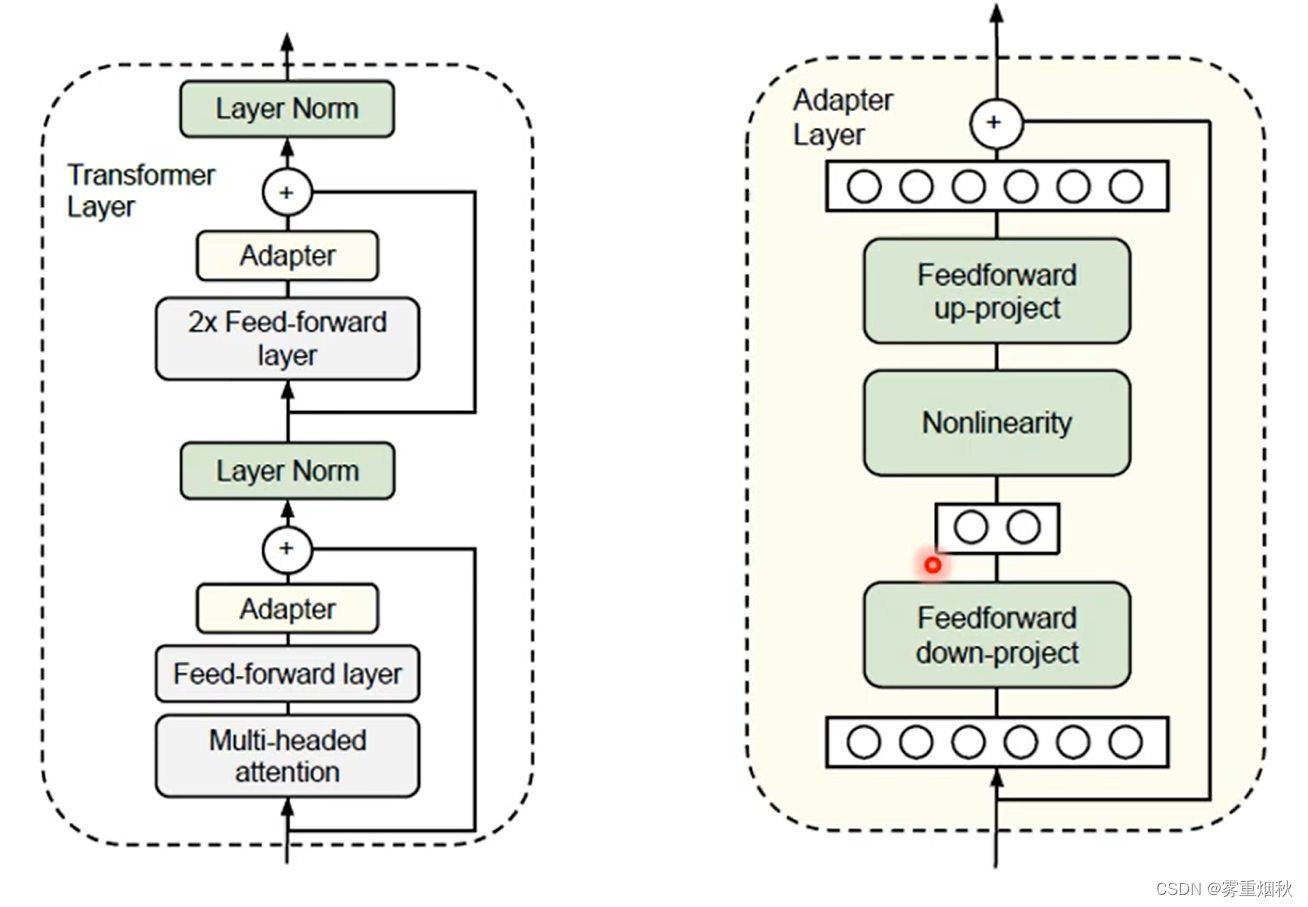
下图就是一种插入Adaptor的方式。实验证明,Adapter可以让模型调很少的参数,却达到finetune整个模型的效果,Adaptor怎么加是需要考虑的。
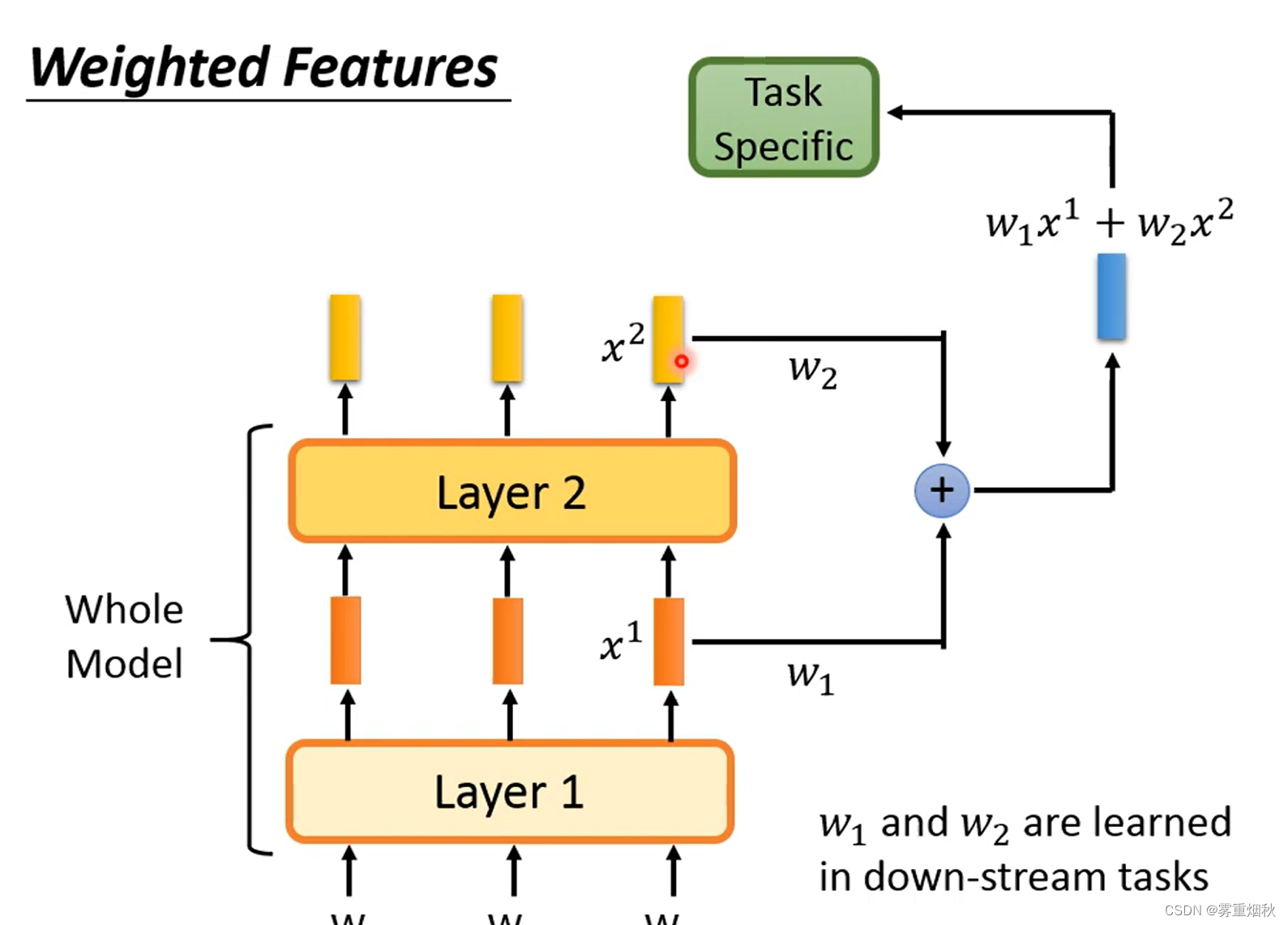
2.4 Weighted Features
由于pre-trained model往往很大,不同层得到的feature代表的意义也不同,所以可以把各层的feature抽出来加权后输入到head,加权的weights可以是模型自己去学的。
3. Why fine-tune
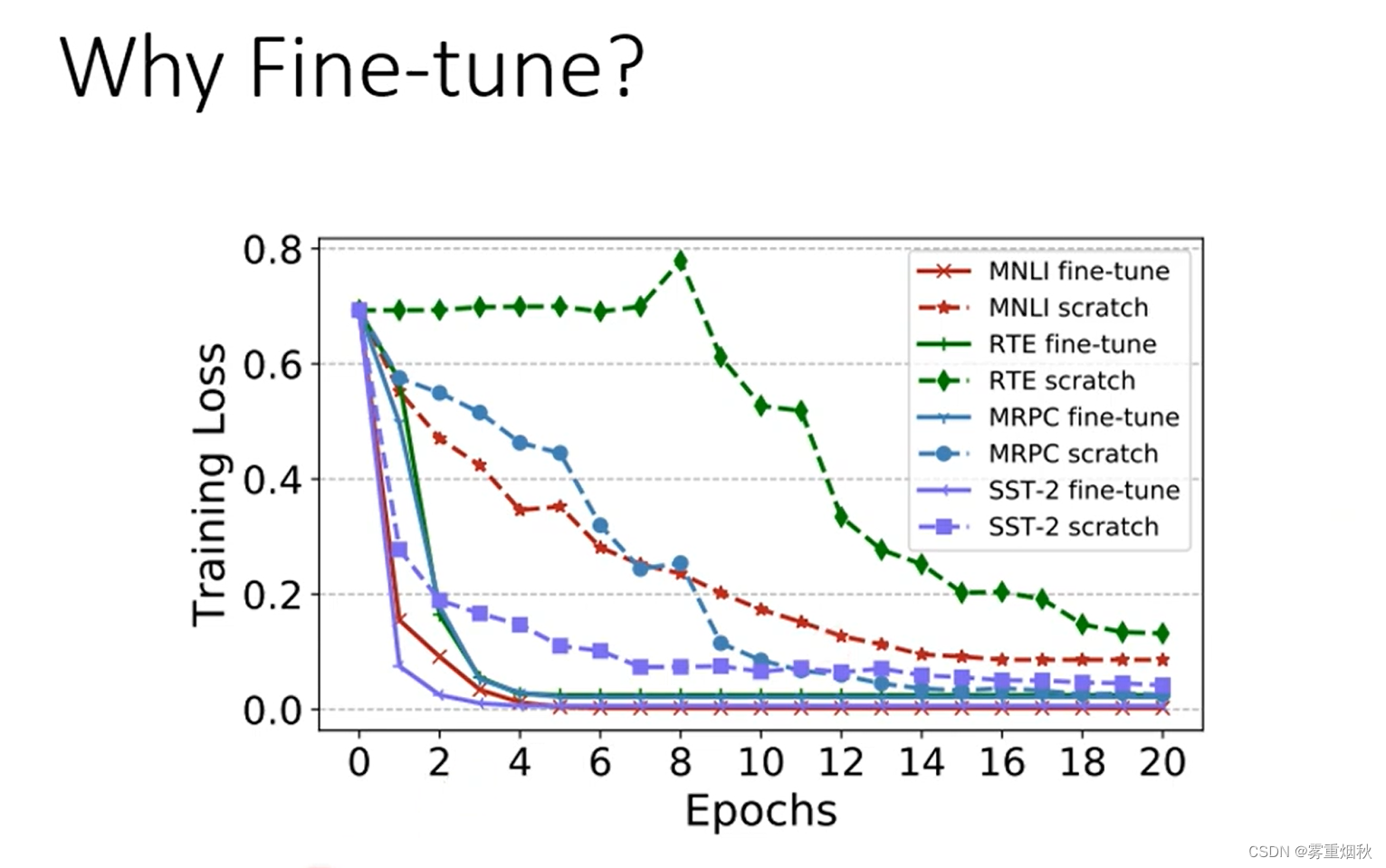
那为什么需要fine-tune,一方面是trainning loss可以更快的收敛,下图对比随机初始化训练和预训练之后训练的training loss随epoch的变化过程。
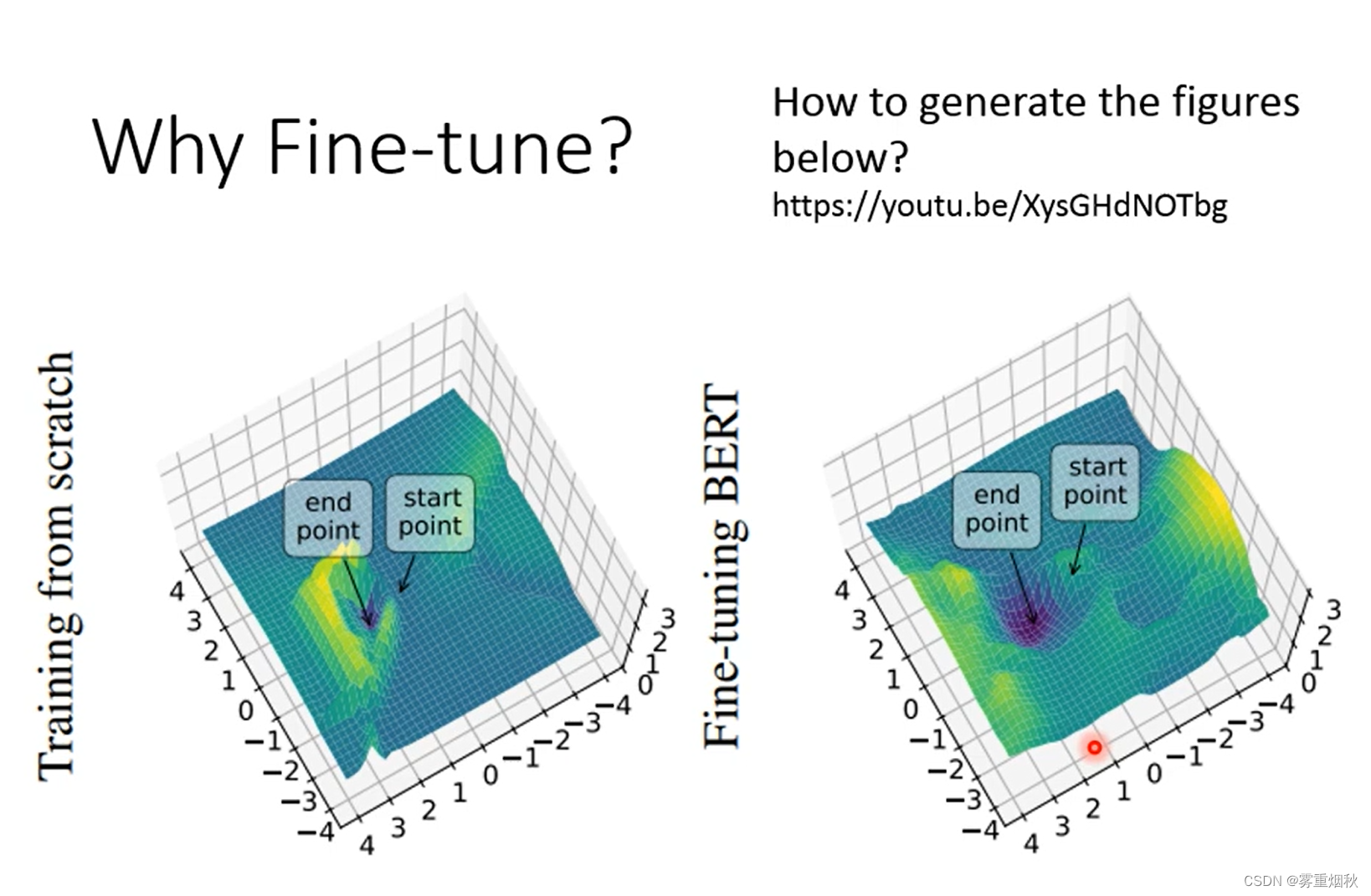
另一方面是fine-tune得到的模型有更好的泛化能力,在同样去找极小值点的时候,预训练的模型找到的极小值点附近的区域更加平缓,意味着泛化能力更好。















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









