






性能测试工具
Jmeter和Loadrunner:
Loadrunner:工业级的性能测试工具,可以模拟大量用户,并监控性能指标提供报表。
优势:
- 支持的用户量大
- 详细的分析报表
- 支持IP欺骗功能
缺点:
- 收费
- 体积大
- 无法定制功能
Jmeter:性能测试工具,Jmeter软件的功能与Loadrunner基本一致
优点:
- 免费开源
- 体积小
- 可扩展的组件
缺点:
- 不支持IP欺骗
- 分析和报表能力比lr弱
选择Jmeter的原因:
- jmeter免费
- jmeter能提供的功能与loadrunner基本一致,满足绝大多数的性能测试需要
jmeter环境搭建:
(1)安装JDK
- 下载(注意选择操作系统对应的32/64)
- 安装(一键式)
- 配置环境变量
- 验证:java -version
(2)安装Jmeter
- 下载(注意下载的版本JDK版本的对应关系)
- 安装(解压缩)
- 配置环境变量
- 验证:
- 双击Jmeter.bat
- 执行:java -jar ApacheJMeter.jar
jmeter的功能概要:
jmeter文件目录结构:
bin目录:
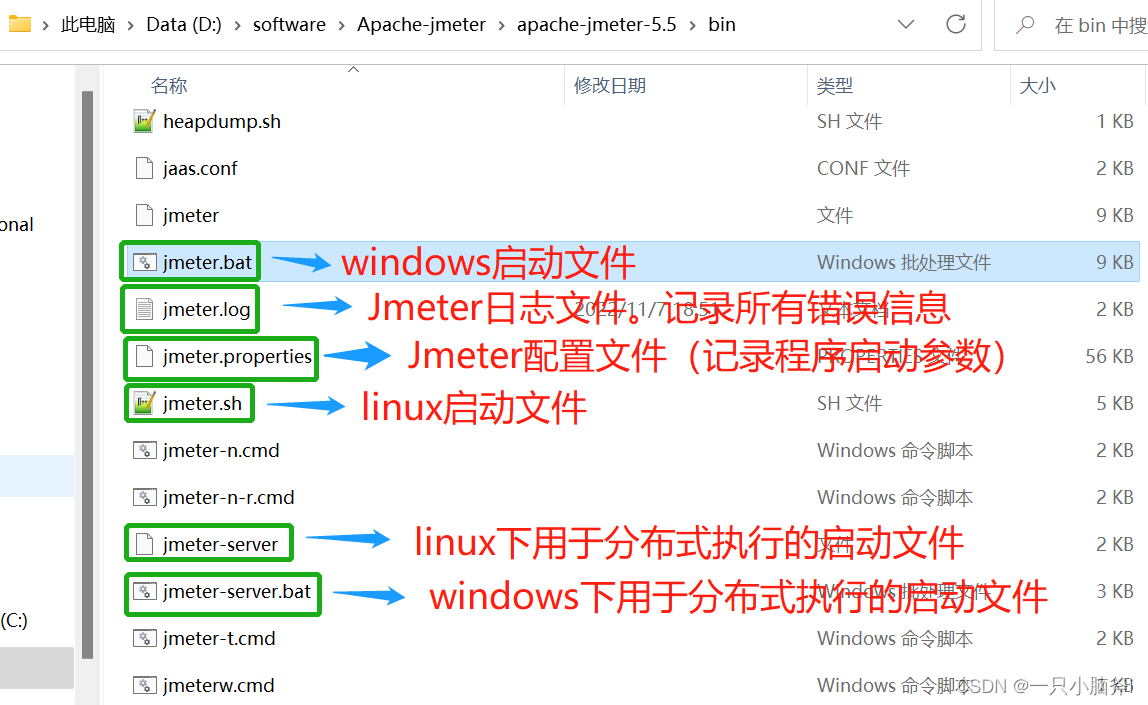
docs目录:

printable-docs目录:
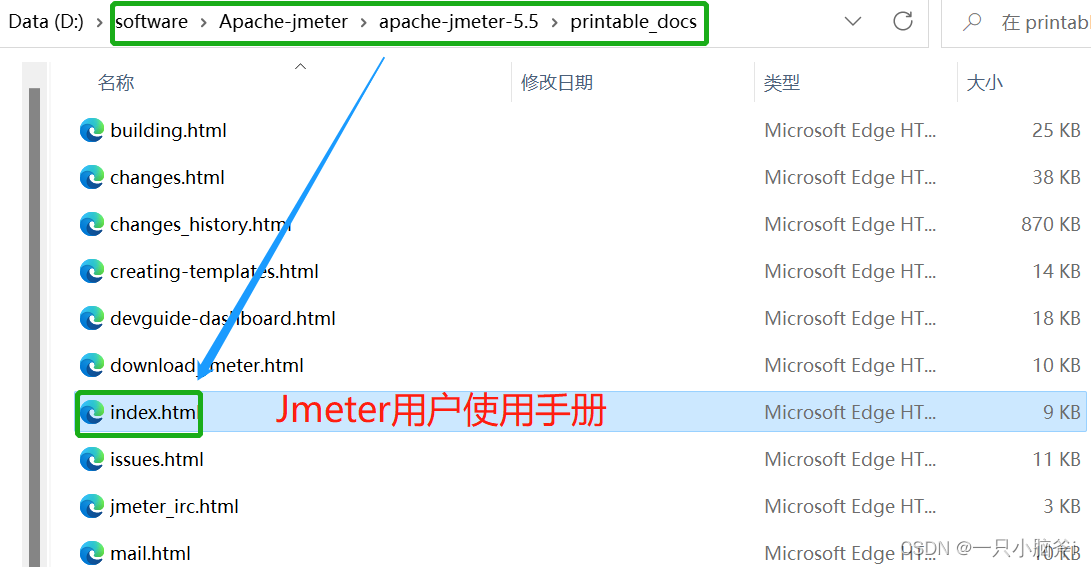
component_reference.html:是最常用的核心元件帮助文档。
lib目录:


基本配置
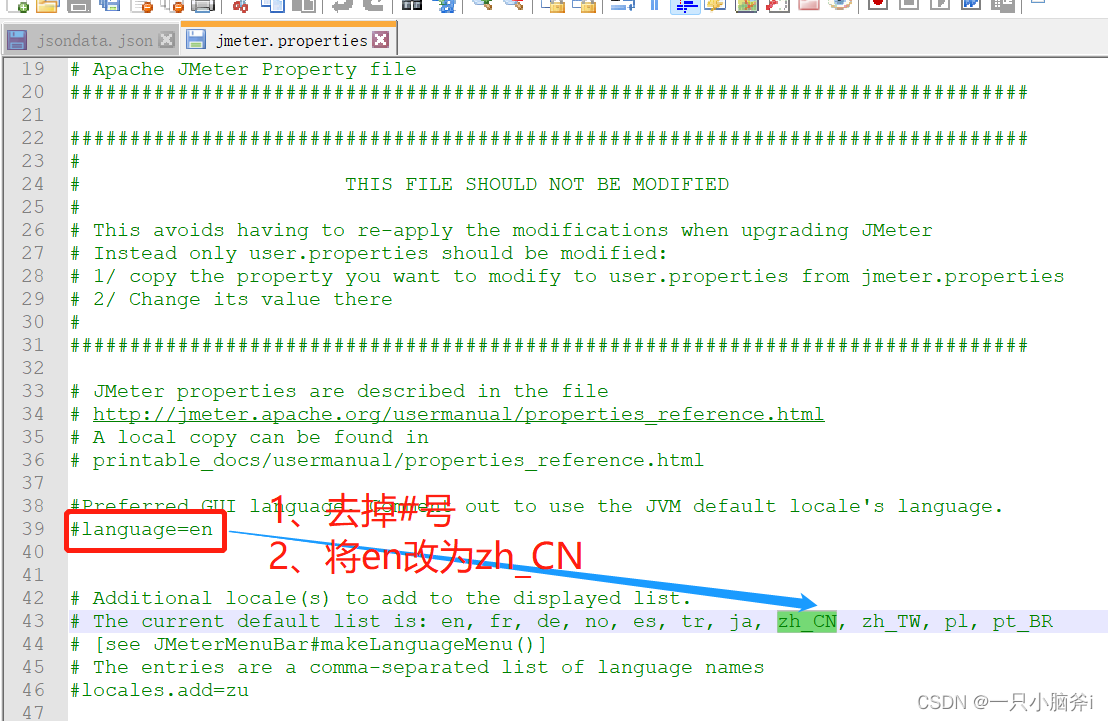
修改语言:
- 临时修改(Options—ChooseLanguage—Chinese)
- 永久修改
(bin—jmeter.propertise)
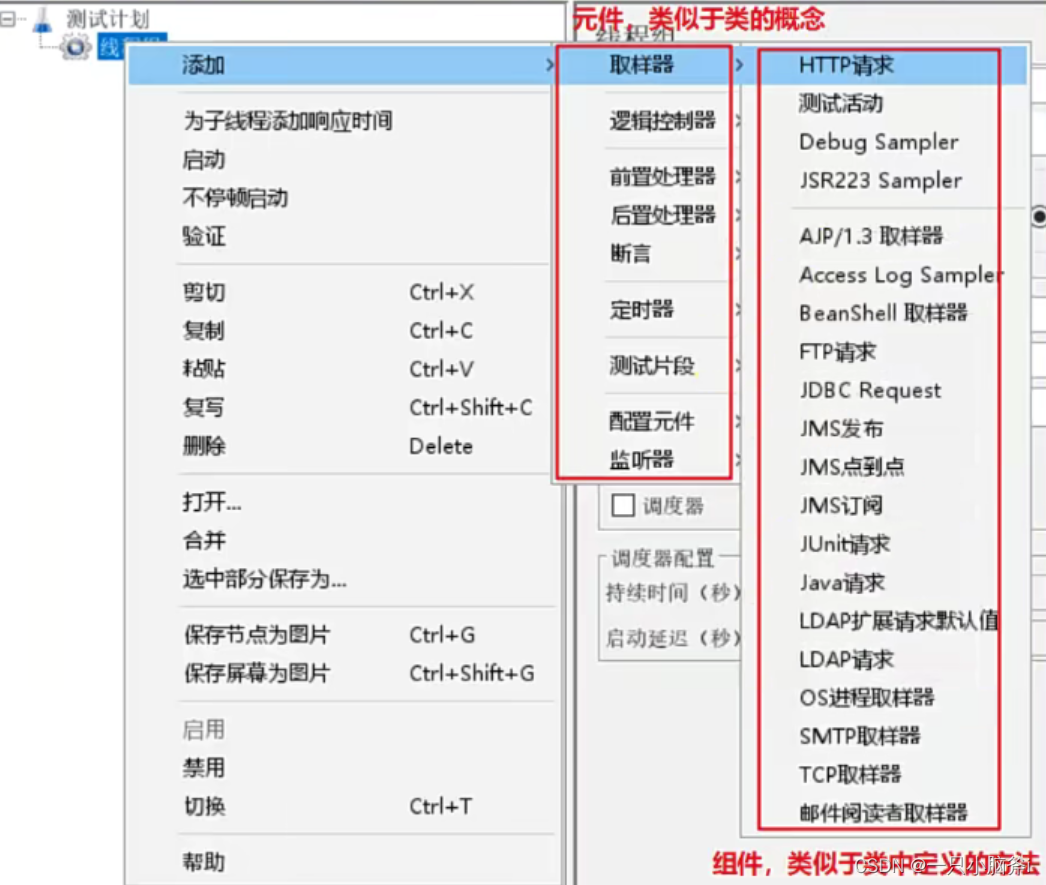
jmeter元件及基本作用域:
基本元件 :
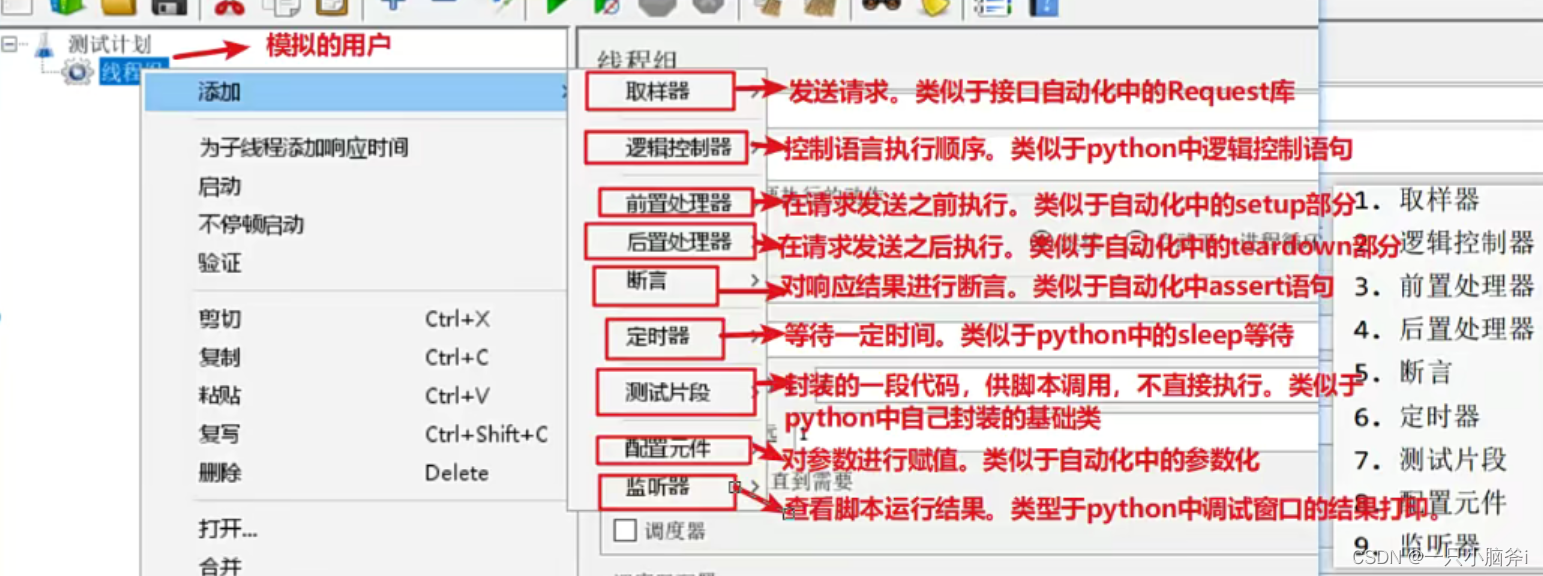
作用域的原理:
按照jmeter测试计划的树形结构来定义作用域(类似python的缩进)
作用域的原则:
- 取样器是jmeter的核心,不作用于其他的组件
- 逻辑控制器,只对子节点起作用
- 对于其他的组件,
- 如果父节点是取样器的话,则只对父节点起作用,
- 如果父节点不是取样器,则对父节点下的所有组件起作用
元件的执行顺序:
- 写脚本的顺序:定义参数——对请求参数进行赋值——发送请求——收响应——提取响应中的字段——断言响应中的字段——观察运行结果
- 元件执行顺序:配置原件——前置处理器——取样器——后置处理器——断言——监听器
- 如果一个作用域下,有多个相同的元件时(例如:多个取样器),按照从上到下的顺序执行
jmeter基本组成
- 线程组
- 分类:普通线程组(可以并行或者串行)、setup线程组(先执行)
- 参数
- 线程数、ramp-up time、运行次数、运行时间、延迟时间
- HTTP请求
- 参数:协议、域名/IP、端口、请求方法、URL路径、编码格式、参数
- 查看结果树
Jmeter三个重要组件
Jmeter第一个案例:、teardown线程组(后执行)

线程组的介绍:
- 模拟多人操作:
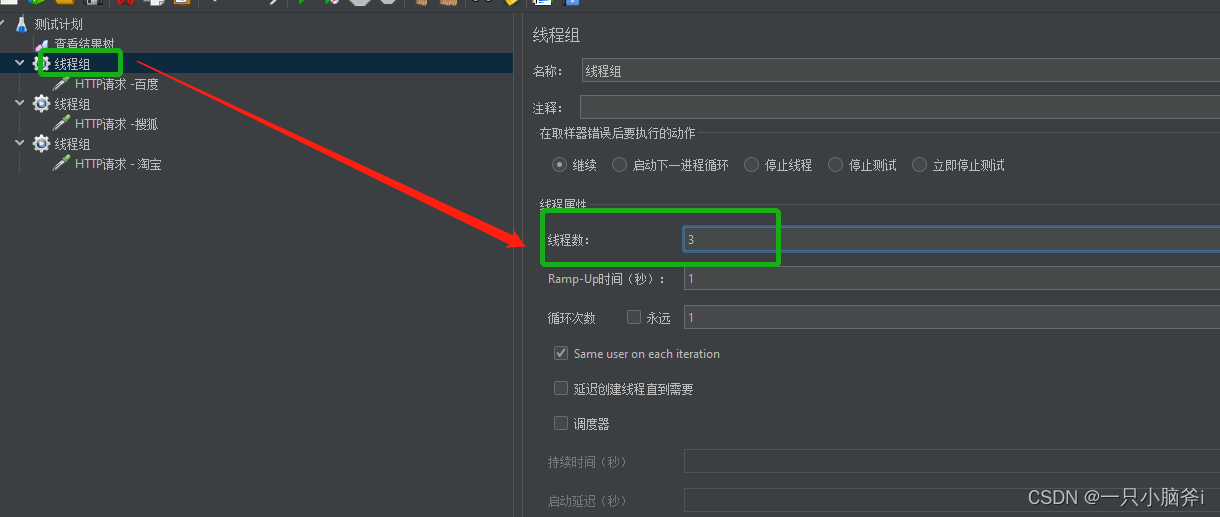
- 多个线程组时,可以并行或串行执行
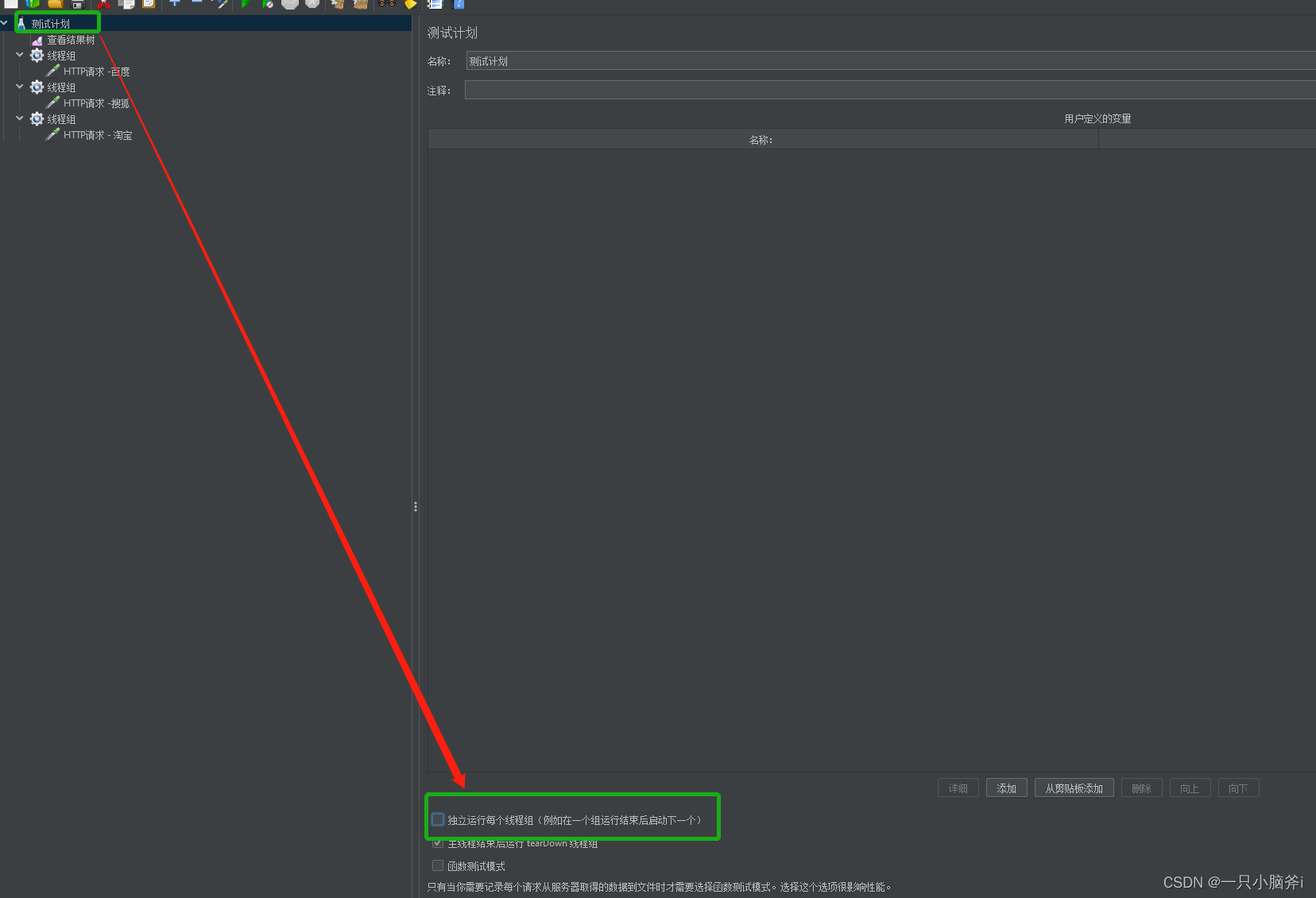
如下图勾选“独立运行每个线程组”则所有的线程组按照添加顺序串行执行;
未勾选则,并行执行(无法保证先后顺序)
线程组的分类:
普通线程组:用于发送业务请求的线程组(受并行、串行配置的影响)
setup线程组:在所有线程组之前执行(不受并行、串行配置的影响)
teardown线程组:在所有线程组之后执行(不受并行、串行配置的影响)
线程组的属性:
线程数:需要模拟的虚拟用户数
ramp-up time:模拟虚拟用户数全部启动所需要的时间
- 目的:为了模拟性能测试场景,更接近用户的使用习惯(用户慢慢接入系统)
循环次数:
- 设置为固定次数n时,脚本运行时发送请求的次数为n
- 设置循环次数为“永远”时,脚本会一直运行下去不停止
调度器:
- 一般与循环次数为“永远”的设置配合使用
- 持续时间设置为n时,脚本请求发送的时间为n秒
- 延迟启动设置为n时,脚本的请求发送在等待n秒后再进行
延迟创建线程直到需要:当启动线程发动请求时,才分配资源;如果暂未启动该线程,则不分配。如不勾选,在jmeter点击运行时立即分配(使用不多无法观察效果)
线程数m和循环次数n的关系:
- 如果同时配置,实际发送的HTTP请求数应该为m*n
- 虽然发送请求的次数相同,但是不能相互替换
- 线程数:代表并发用户数,体现服务器的负载量
- 循环次数:代表执行时间
HTTP请求:
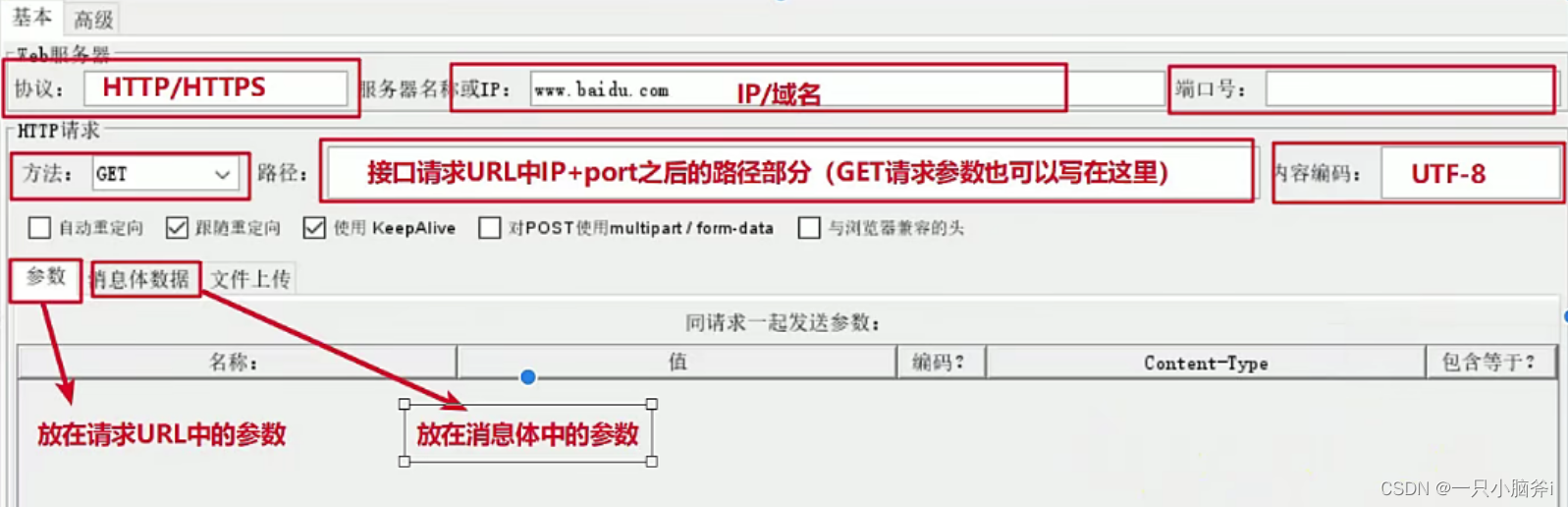
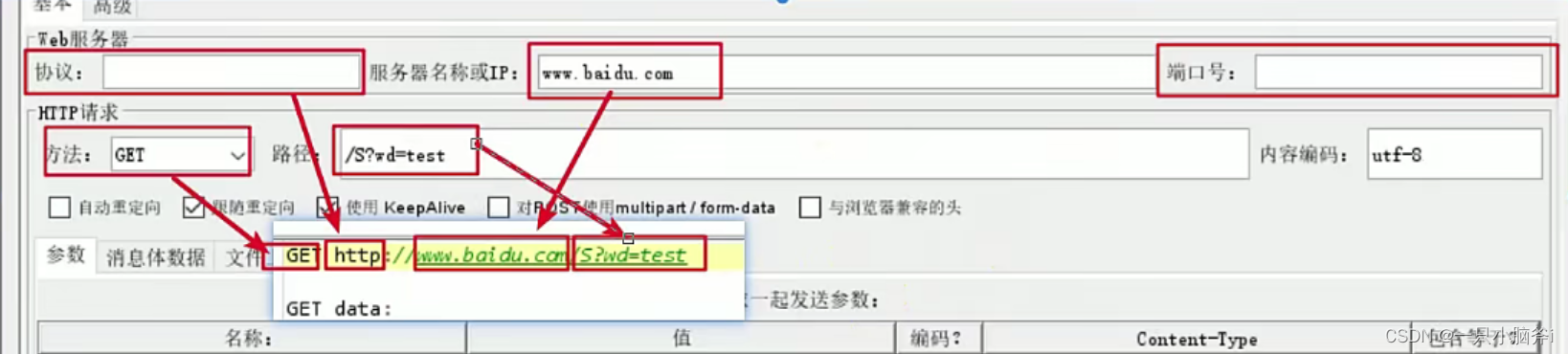
例1、发送请求时:
- 协议未填写,则默认为HTTP协议
- 端口未填写,则 默认为80端口
- 将GET请求参数放在路径中填写
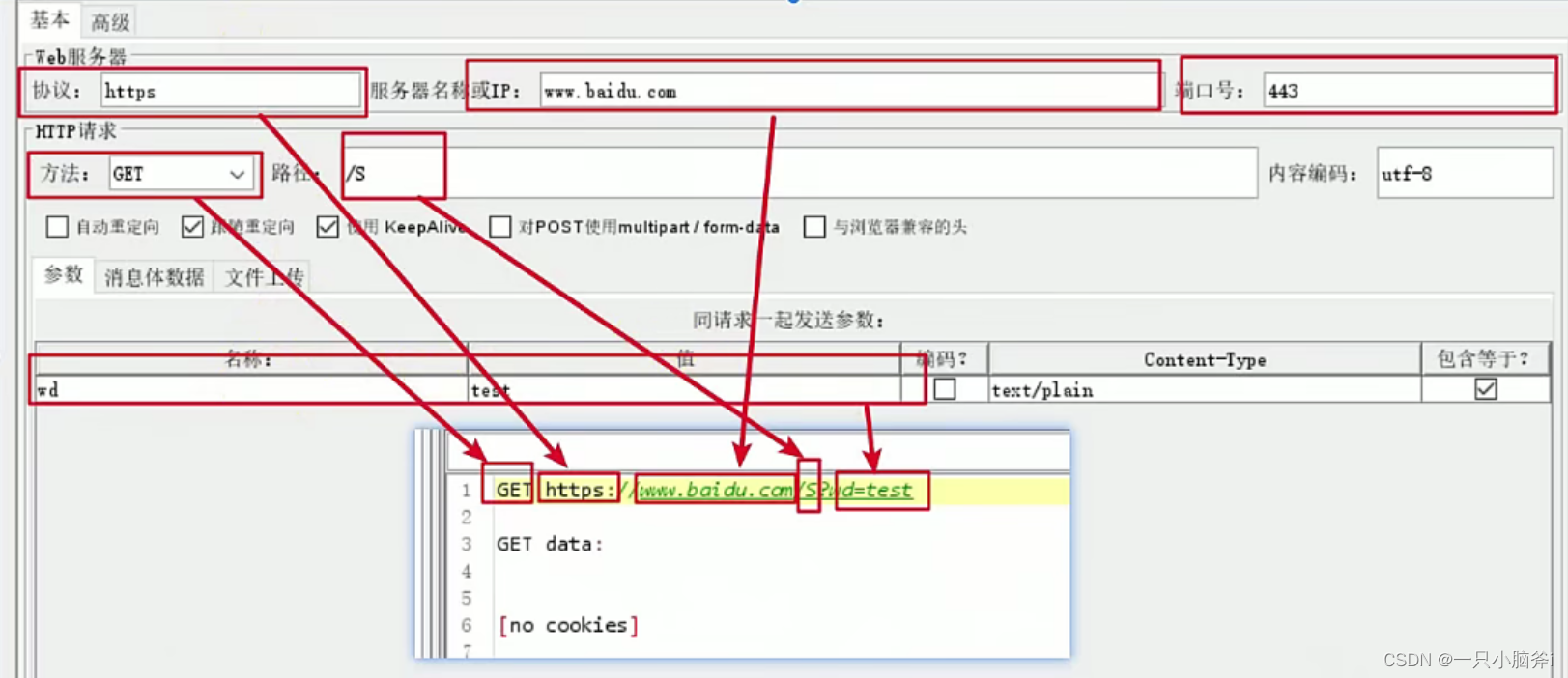
例2、发送请求时:
- 协议选择HTTPS
- 端口号为443
- 将GET请求参数放在下面的参数列表中进行填写
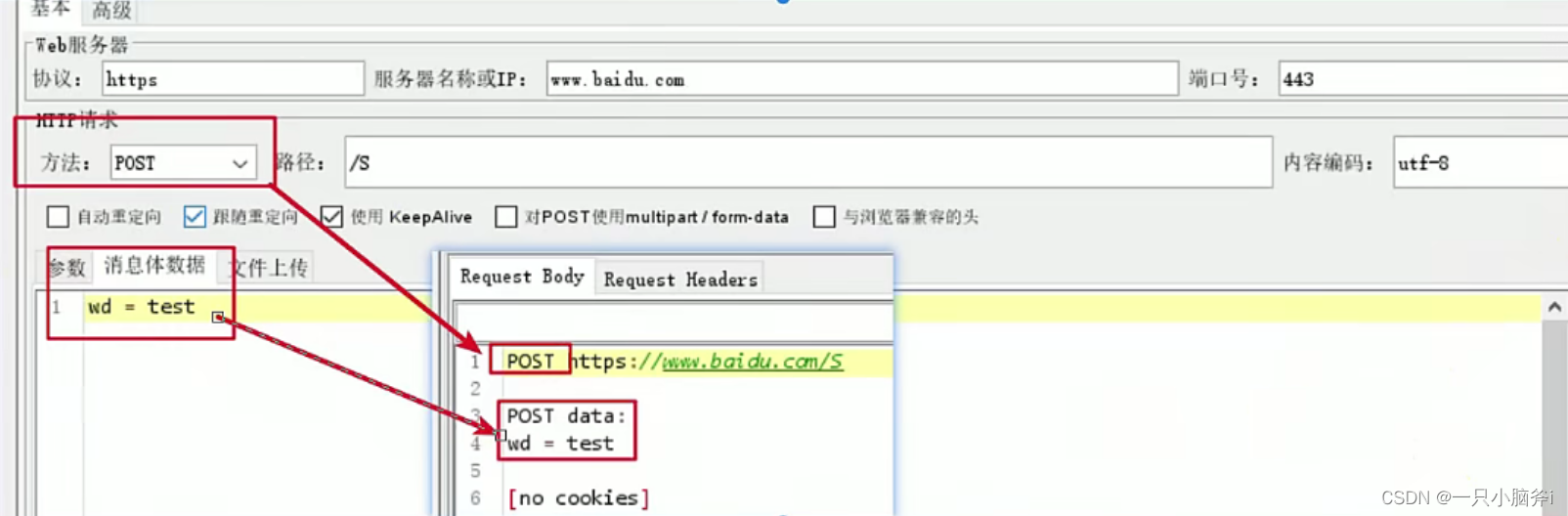
例3、发送POST请求
- 方法选择POST
- 将参数内容放入到消息体数据中,在发送时参数会添加到消息体中发送
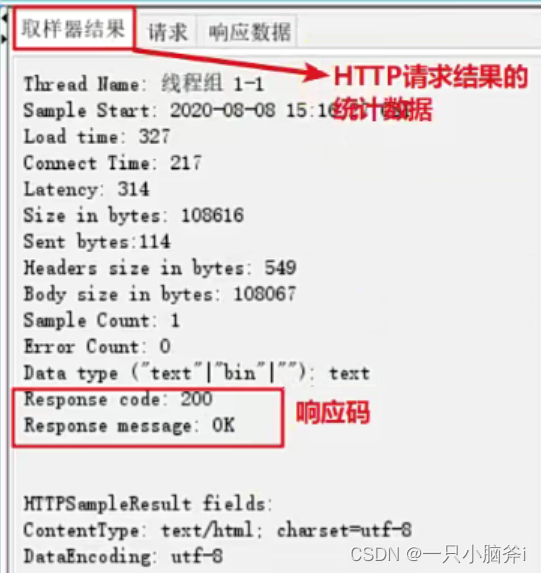
查看结果树:
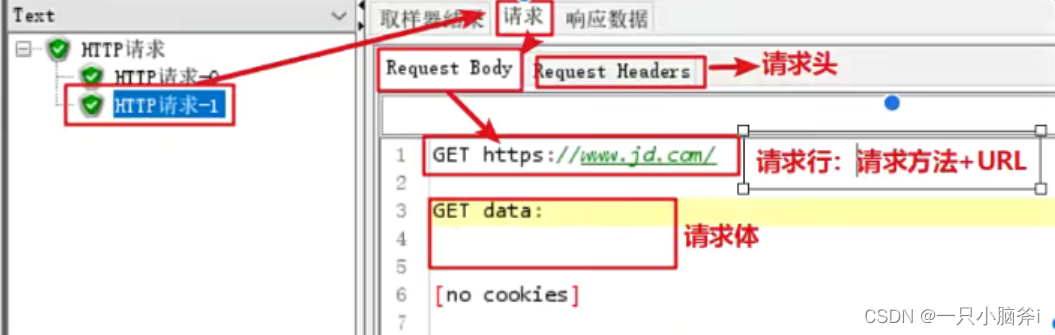
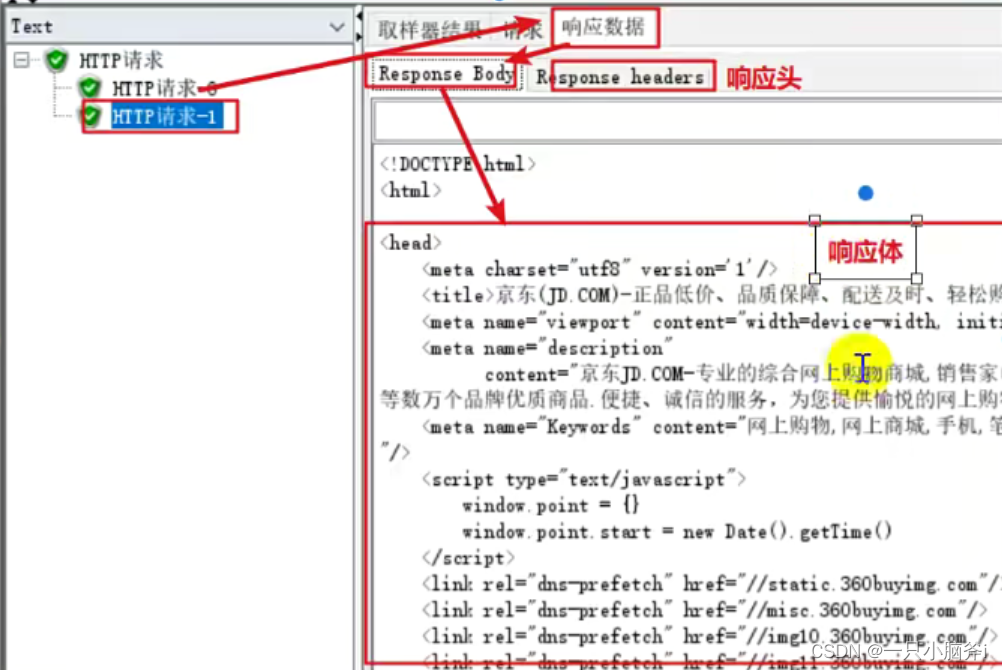
jmeter响应中出现乱码中:
一、修改配置文件(bin目录jmeter.properties)中的内容:

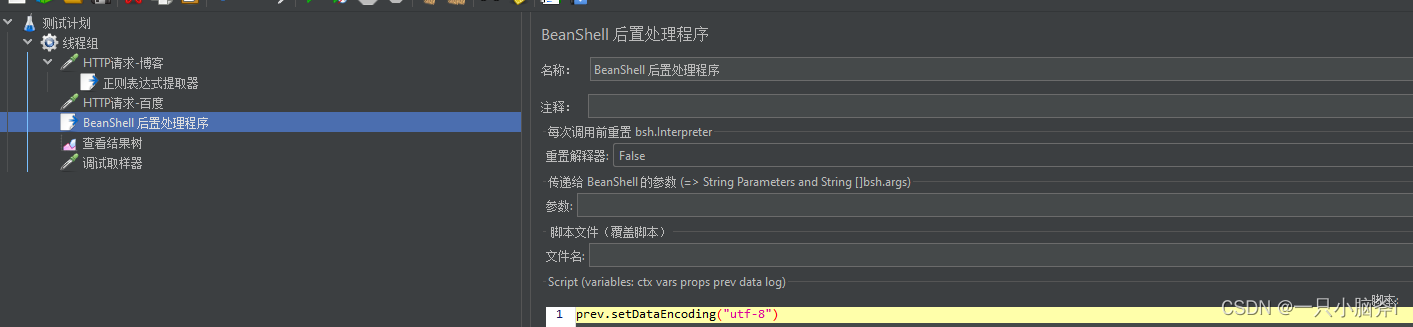
二、使用BeanShell 后置处理程序
给取样器添加BeanShell 后置处理程序,在脚本中输入prev.setDataEncoding(“utf-8”),修改返回数据的编码方式
Jmeter参数化
- 用户定义的变量:每个用户每次读取的变量值都完全相同
- 用户参数:不同用户读取的变量值不同,但是同一用户在多次循环时读取的变量值是一致的
- CSV数据文件:不同用户读取的变量值不同,同一用户在多次循环时读取的的变量值也不同
- 函数:每次执行读取的的变量值都不同,不需要提前定义数据(适用于对数据值无明确要求,只要求不同)
配置:
- 设置:每种不同
- 引用:${参数名}
用户定义的变量:
配置方法1:配置元件中配置
- 添加路径:测试计划—线程组—配置元件—用户定义的变量
- 参数设置:
- 参数名:参数值
在HTTP取样器中应用:${参数名}


配置方法2:在测试计划中配置

用户参数:
使用用户定义的变量时,不同用户的在访问时,读取的参数值完全相同,如果希望每个用户在访问时的变量不同,可以使用用户参数。
配置方法:
- 添加位置:线程组—前置处理器—用户参数
- 添加用户:可以添加多组用户
- 添加参数:针对每个用户添加多个参数

CSV数据文件设置
1、定义csv数据文件

2、添加线程组
3、配置csv数据文件设置
- 添加位置:线程组—配置元件—csv数据文件设置
- 添加配置:


4、添加http请求 - 引用参数值时,使用csv数据文件中定义的变量名
5、查看结果树
例:
某支付系统,需要用1000个不同的用户登录,并使用不同的测试金额数据访问支付接口?
1、定义csv数据文件,存放1000个不同用户账号密码
2、添加线程组,将线程组的数据数设置为1000
3、添加csv数据文件设置,读取csv数据文件中的用户账号密码
4、添加HTTP请求(用户登录请求),在请求中引用csv数据文件中设置的用户账号、密码的参数
5、添加HTTP请求(支付请求),使用counter函数作为支付金额的参数
6、添加查看结果树观察结果
函数
通过counter函数在生成动态变化的数值


在HTTP取样器中,应用cuonter函数生成的函数字符串,就可以读取counter函数生成的数值
- 如果counter参数设置为:TRUE,则每个用户分别从1开始计算,每循环一次加1
- 如果counter参数设置为:FALSE,则所有公户用一个计数器,每发送一个请求时,取值加1














 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









