




 本文介绍了在线学习机制,映射约减法等数据处理技术,以及如何通过这些技术优化网站决策,处理大规模数据集,并实现高效的文字识别系统。
本文介绍了在线学习机制,映射约减法等数据处理技术,以及如何通过这些技术优化网站决策,处理大规模数据集,并实现高效的文字识别系统。
在线学习机制
在线学习机制可以模型化问题,可以通过算法在涌入连续的数据流中学习用户的偏好,来优化一些网站的决策。利用刚得到的 (x , y) 数据对来迭代更新 θ。这里使用的是(x,y)而不是(x(i),y(i))是因为网站是有连续的数据的,每个数据用完之后就被丢弃,不被反复使用。如果网站用户量很少,就不适合使用在线学习算法。在线学习算法可以对正在变化的用户偏好进行调适。

映射约减法
由于大规模数据集求最优解,计算量非常大,对于这样的问题,如果能够将数据集分配给多台计算机,让每台计算机处理数据集的一个子集,然后将计算结果汇总再求和,这样的方法叫做映射简化。
如果任何学习算法能够表达为,对训练集的函数求和,那么就能将这个任务分配给多台 计算机(或者同一台计算机的不同CPU核心),以达到加速处理的目的。
照片文字识别(OCR)
1、文字侦测——将图片上的文字与其他环境对象分离开来
2、字符切分——将文字分割成一个个单一的字符
3、字符分类——确定每一个字符是什么

像这样的一个系统,称之为机器学习流水线。在流水线中会有多个不同的模块,比如在本例中,我们有文字检测、字符分割和字母识别。其中每个模块都可能是一个机器学习组件或者只是一个接一个连在一起的一系列数据。最终得出希望的结果就是最终识别到的图片中的文字信息。如果要设计一个机器学习系统,最重要的就是要怎样组织好这个流水线,如何将这个问题分成一系列不同的模块,流水线中的每一个模块都会影响到最终的算法的表现 。
滑动窗分类器
以行人检测为例,首先要做的是用许多固定尺寸的图片来训练能识别行人的模型,然后用之前训练识别行人的模型时所采用的图片尺寸在图片上进行依次滑动,然后判断是否有行人,直到整张图片完全检测完。每次滑动的大小被称为步长,通常使用4个像素作为步长。然后再使用大一点的方框依次检查,取回的图像同样要压缩到原来的大小。
滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后运用滑动窗口技术识别字符,字符的分割也同样是需要使用正负样本训练分类器,然后用滑动窗分类器将连续的文字区域划分成单个字母。
人工数据合成
想要获得一个比较高效的机器学习系统,最可靠的办法就是选择一个低偏差的学习算法,然后用非常大的训练集来训练它。为了解决大的训练集的问题,可以考虑人工数据合成。一般分为两种,一种是全部自己创造新的训练集;一种是用已有的一小部分带标签的训练集来创造训练集。
以文字为例,可以在网上找到不同字体的文字,再为其添上不同的背景,使用某种模糊处理,这就就可以得到和真实样本类似的带标签的训练集。这是第一种。第二种是可以对已有的文字进行变形扭曲,得到新的带标签的样本。当然这些变形是在实际的应用中会用的到的,不然就没有意义了。
有关获取更多数据的几种方法:
1、 人工数据合成
2、 手动收集、标记数据
3、 众包
上限分析
当开发机器学习系统的流水线时,上限分析通常能提供一种很有用的导向,告诉我们流水线中的哪个部分最值得花时间改善。流程图中每一部分的输出都是下一部分的输入,上线分析中,我们选取一部分,手工提供100%正确的输出结果,任何看看整体效果提升了多少。
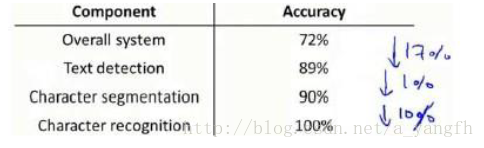
以上述的文字识别为例,如果令文字侦测部分输出的结果为100%正确,发现系统的总体效果从72%提高到89%,这意味着我们很可能会投入精力来提高文字侦测部分。如果令字符切分输出的结果100%正确,发现系统的总体结果只提升了1%,这意味着字符切分部分已经足够好了。如果令字符分类输出的结果100%正确,系统的总体效果有提升了10%,这意味着这块也应该投入更多的时间和精力。

















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









