







文章目录
前言
MindSpore 是华为开发的一种新型AI开发框架,致力于提高 AI 应用的开发效率、运行效率和安全性。MindSpore 具备多样化的功能和特性,包括全场景智能化、强大的跨平台能力、灵活可扩展的算法库、支持大规模分布式训练等。同时,MindSpore 还拥有简单易用的 API 和可视化工具,能够帮助开发者快速构建并优化 AI 应用,提升应用性能和准确度。
华为产品测评开发者之声活动是华为公司举办的活动,旨在邀请开发者参与华为产品的测试和开发过程,为华为产品提供反馈和建议,帮助华为改进产品质量和用户体验。这个活动的意义主要有:
-
帮助华为改进产品质量:通过听取开发者的反馈和建议,华为可以更快更准确地发现产品存在的问题和缺陷,及时进行改进,提升产品的质量和用户体验。
-
增强产品竞争力:开发者是产品的重要用户和推广者,他们的认可和推荐对产品的销售和口碑都有着重要的影响。通过与开发者的沟通和合作,华为可以更好地了解市场需求和用户需求,为产品的研发和推广提供更为有效的支持。
-
建立良好的合作关系:开发者是华为的重要合作伙伴,通过与他们的合作,可以建立更为紧密的合作关系,增强彼此的信任和合作意愿,为未来的合作提供更好的基础。
华为产品测评开发者之声活动对华为和开发者都有着重要的意义,可以促进产品质量的提升、增强产品竞争力、建立良好的合作关系,是一项有益的活动。
一、昇思MindSpore产品体验
1.体验本地安装
1.1 安装虚拟环境
使用conda创建虚拟环境,使用的是python3.9版本
conda create -c conda-forge -n mindspore_py39 -c conda-forge python=3.9.0
激活环境
conda activate mindspore_py39
1.2 安装MindSpore
conda install mindspore-cpu -c mindspore -c conda-forge
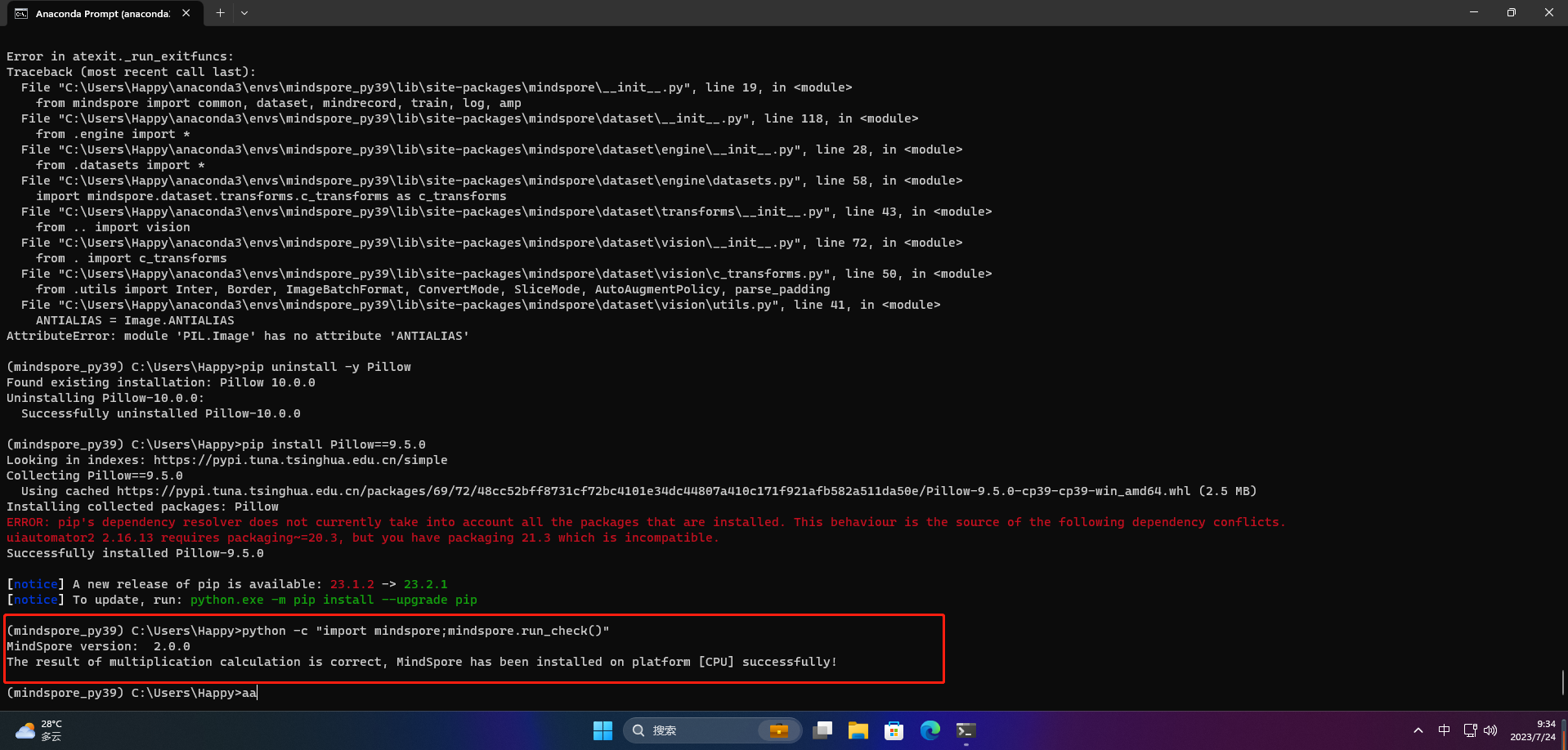
1.3 验证是否成功安装
python -c "import mindspore;mindspore.run_check()"
发现报错
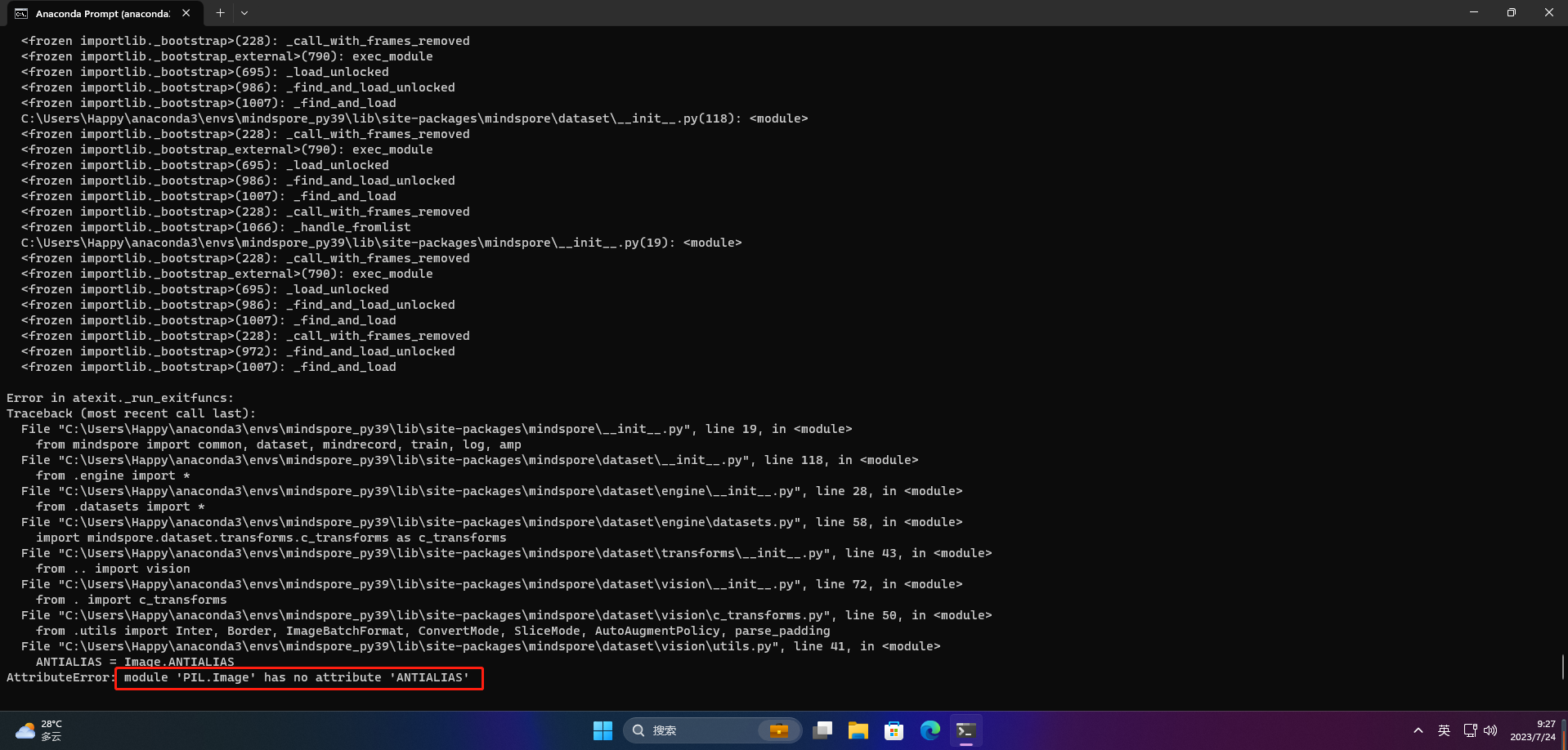
在pillow的10.0.0版本中,ANTIALIAS方法被删除了,降级Pillow的版本
pip uninstall -y Pillow
pip install Pillow==9.5.0
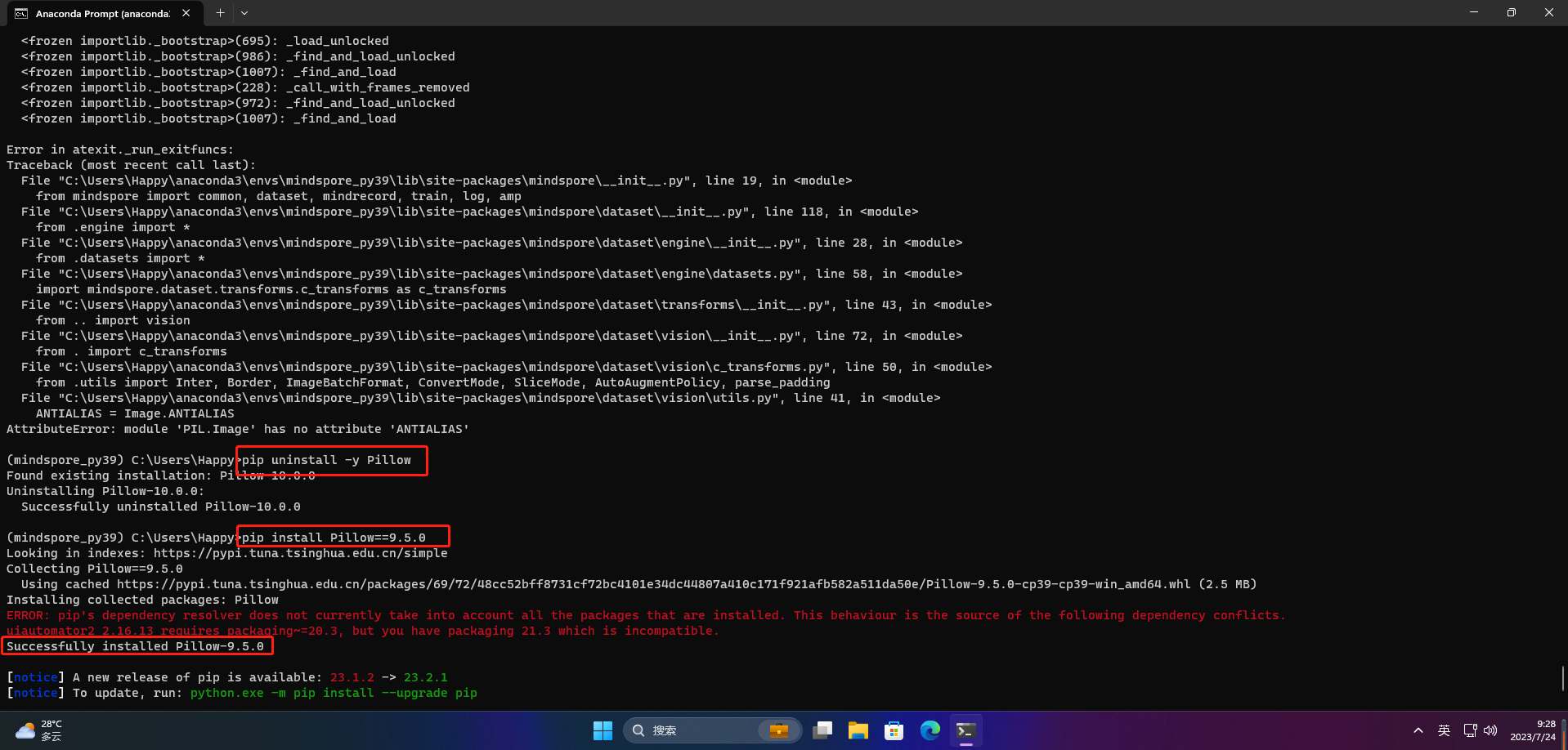
继续验证
1.4 配置vscode插件
1、先配置vscode jupyter-notebook环境
2、安装内核
进入conda对应虚拟环境,安装内核
pip install -U ipykernel
3、测试运行
本文在vscode上运行问题很多,后面案例用华为云的在ModelArts上运行,界面网址如下:
2.基本介绍
2.1 昇思MindSpore介绍
昇思MindSpore是华为推出的AI计算框架,可以支持自然语言处理、计算机视觉和推荐系统等多个领域的模型训练和推理。它采用了全新的深度学习框架设计理念,支持动态图和静态图混合编程模式,具有高效、灵活、易用等特点。
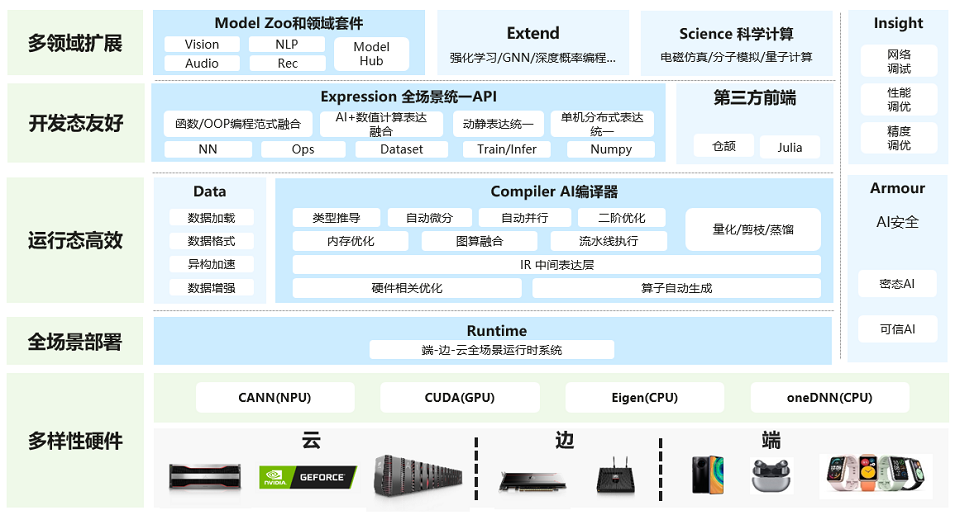
MindSpore的核心特性包括:
-
支持端侧、云端和边缘多种场景;
-
支持深度学习全阶段自动化——Auto-Grad和Auto-Parallel;
-
支持全新的设计理念——Sparse Tensor和Hybrid Parallel;
-
支持全面的模型训练和推理功能;
-
支持多种硬件平台和操作系统。
MindSpore还提供了开箱即用的模型库和应用案例,包括自然语言处理、计算机视觉、推荐系统等多个领域的模型,以及基于MindSpore的多个解决方案,如自动驾驶、芯片设计等。
2.2 执行流程
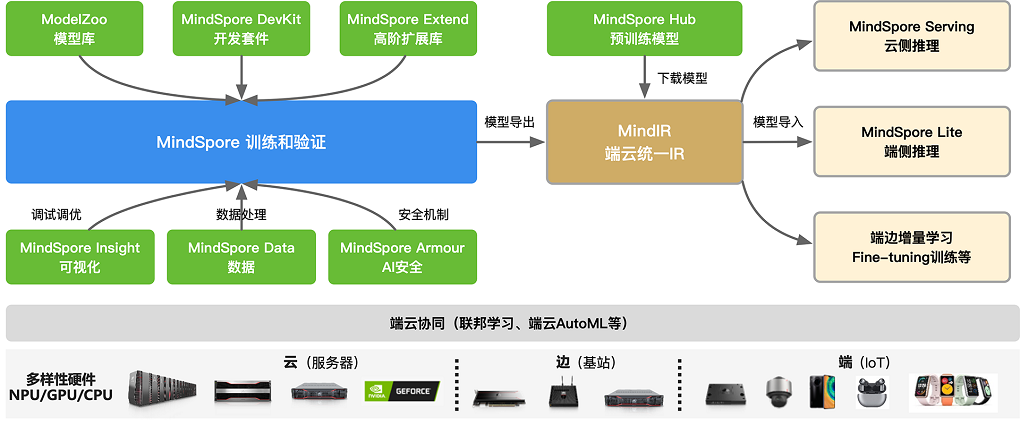
左边蓝色方框的是MindSpore主体框架,主要提供神经网络在训练、验证相关的基础API功能,另外还会默认提供自动微分、自动并行等功能。
蓝色方框往下是MindSpore Data模块,可以利用该模块进行数据预处理,包括数据采样、数据迭代、数据格式转换等不同的数据操作。在训练的过程会遇到很多调试调优的问题,因此有MindSpore Insight模块对loss曲线、算子执行情况、权重参数变量等调试调优相关的数据进行可视化,方便用户在训练过程中进行调试调优。
AI安全最简单的场景就是从攻防的视角来看,例如,攻击者在训练阶段掺入恶意数据,影响AI模型推理能力,于是MindSpore推出了MindSpore Armour模块,为MindSpore提供AI安全机制。
蓝色方框往上的内容跟算法开发相关的用户更加贴近,包括存放大量的AI算法模型库ModelZoo,提供面向不同领域的开发工具套件MindSpore DevKit,另外还有高阶拓展库MindSpore Extend,这里面值得一提的就是MindSpore Extend中的科学计算套件MindSciences,MindSpore首次探索将科学计算与深度学习结合,将数值计算与深度学习相结合,通过深度学习来支持电磁仿真、药物分子仿真等等。
神经网络模型训练完后,可以导出模型或者加载存放在MindSpore Hub中已经训练好的模型。接着有MindIR提供端云统一的IR格式,通过统一IR定义了网络的逻辑结构和算子的属性,将MindIR格式的模型文件 与硬件平台解耦,实现一次训练多次部署。因此如图所示,通过IR把模型导出到不同的模块执行推理。
2.3 华为昇腾AI全栈介绍
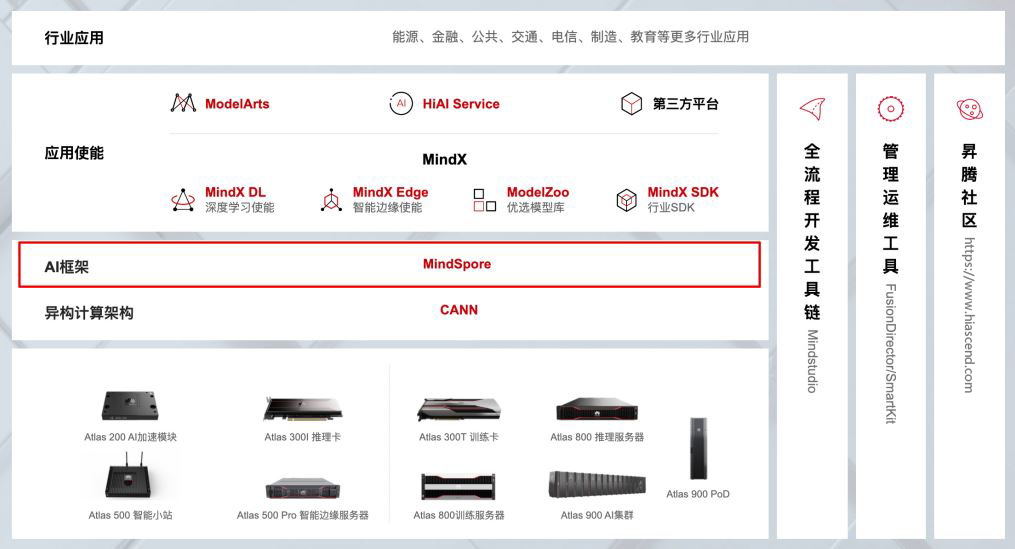
下面简单介绍每个模块的作用:
-
Atlas系列产品:提供AI训练、推理卡及训练服务器
-
CANN(异构计算架构):芯片使能、驱动层
-
MindSpore(AI框架):全场景AI框架
-
MindX SDK(昇腾SDK):行业SDK和应用解决方案
-
ModelArts(AI开发平台):华为云AI开发平台
-
MindStudio(全流程开发工具链):AI全流程开发IDE
3.快速入门
导入相关包
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
3.1 处理数据集
1、下载数据集
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
2、数据下载完成后,获得数据集对象,并打印数据集中包含的数据列名,用于dataset的预处理
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
print(train_dataset.get_col_names())
3、MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。这里我们使用map对图像数据及标签进行变换处理,然后将处理好的数据集打包为大小为64的batch
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
# Map vision transforms and batch dataset
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
for image, label in test_dataset.create_tuple_iterator():
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")
print(f"Shape of label: {label.shape} {label.dtype}")
break
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")
break
3.2 网络构建
mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。__init__包含所有网络层的定义,construct中包含数据(Tensor)的变换过程(即计算图的构造过程)
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)
3.3 模型训练
# Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
-
正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
-
反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
-
参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现: -
正向计算函数定义。
-
通过函数变换获得梯度计算函数。
-
训练函数定义,执行正向计算、反向传播和参数优化。
# Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
除训练外,我们定义测试函数,用来评估模型的性能
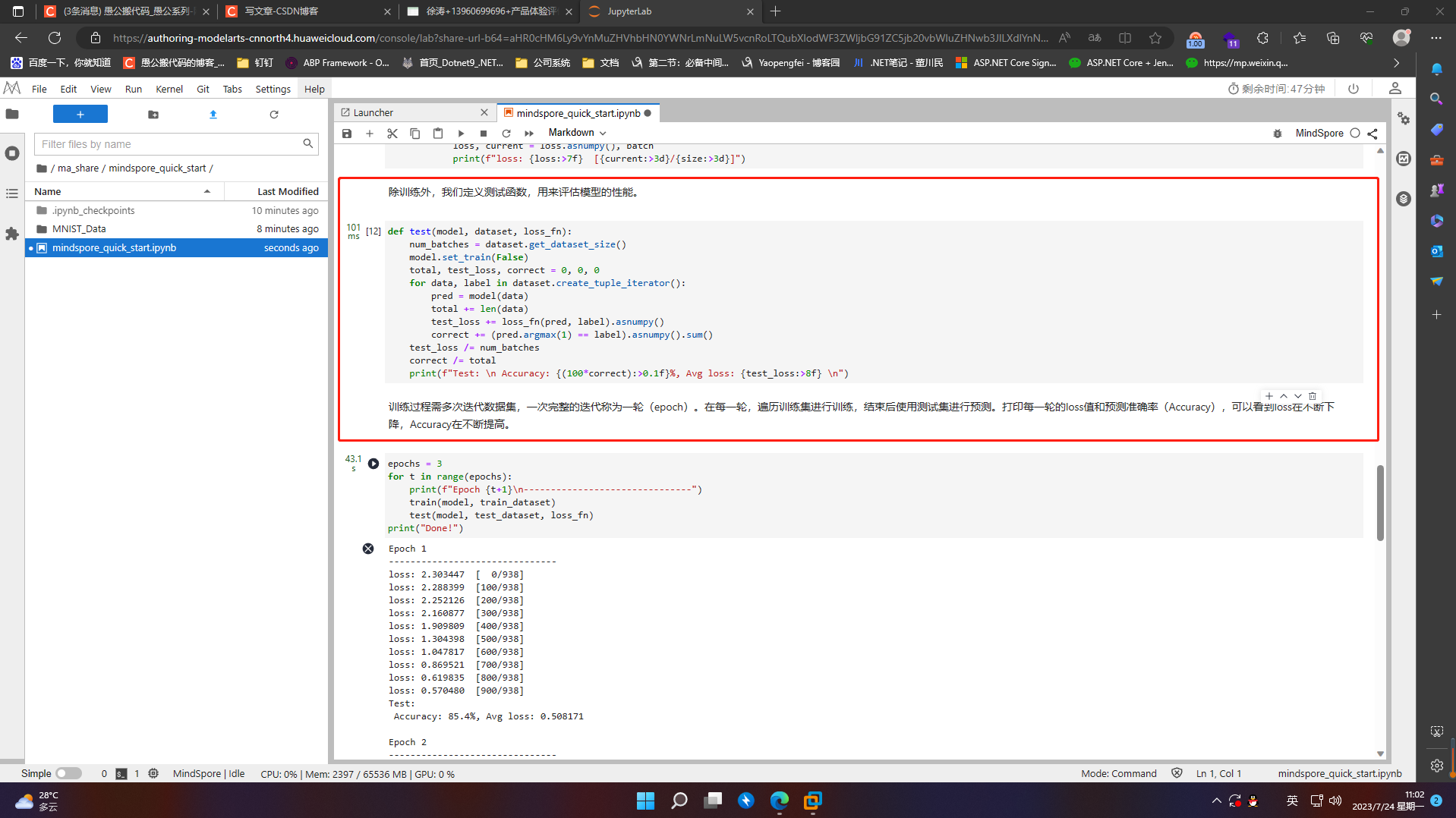
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高
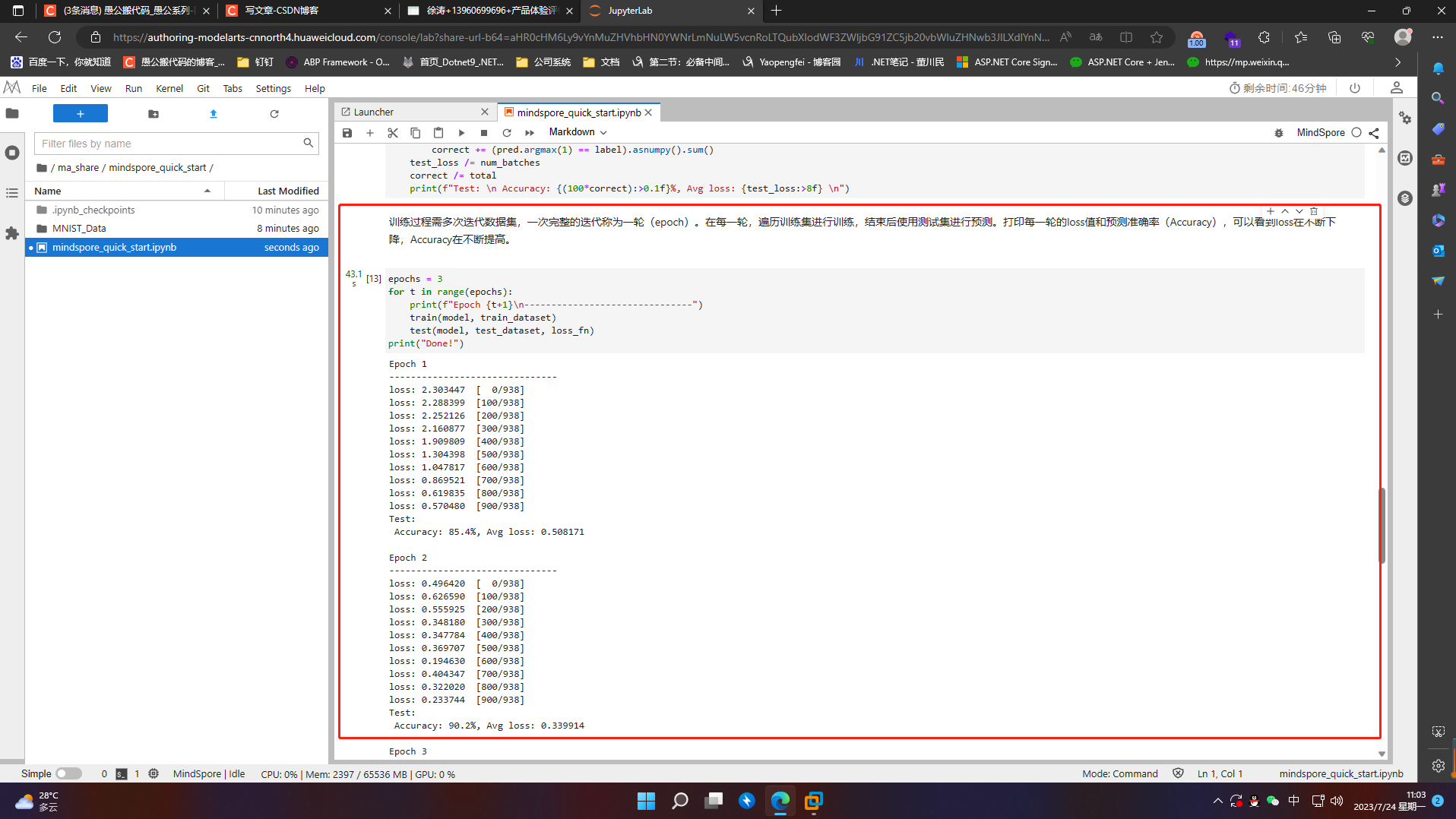
3.4 保存模型
模型训练完成后,需要将其参数进行保存
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
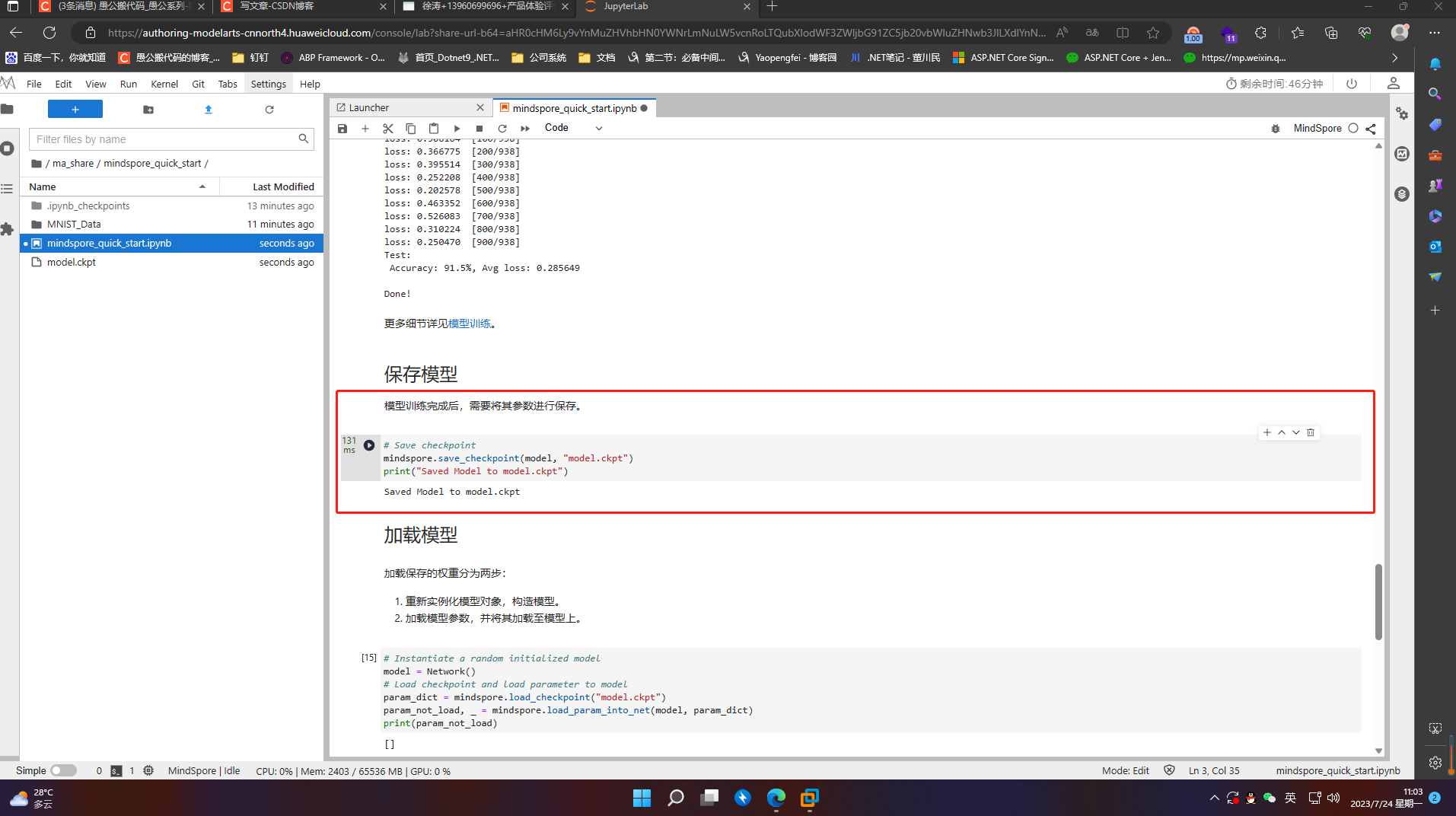
3.5 加载模型
加载保存的权重分为两步:
- 重新实例化模型对象,构造模型。
- 加载模型参数,并将其加载至模型上。
# Instantiate a random initialized model
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
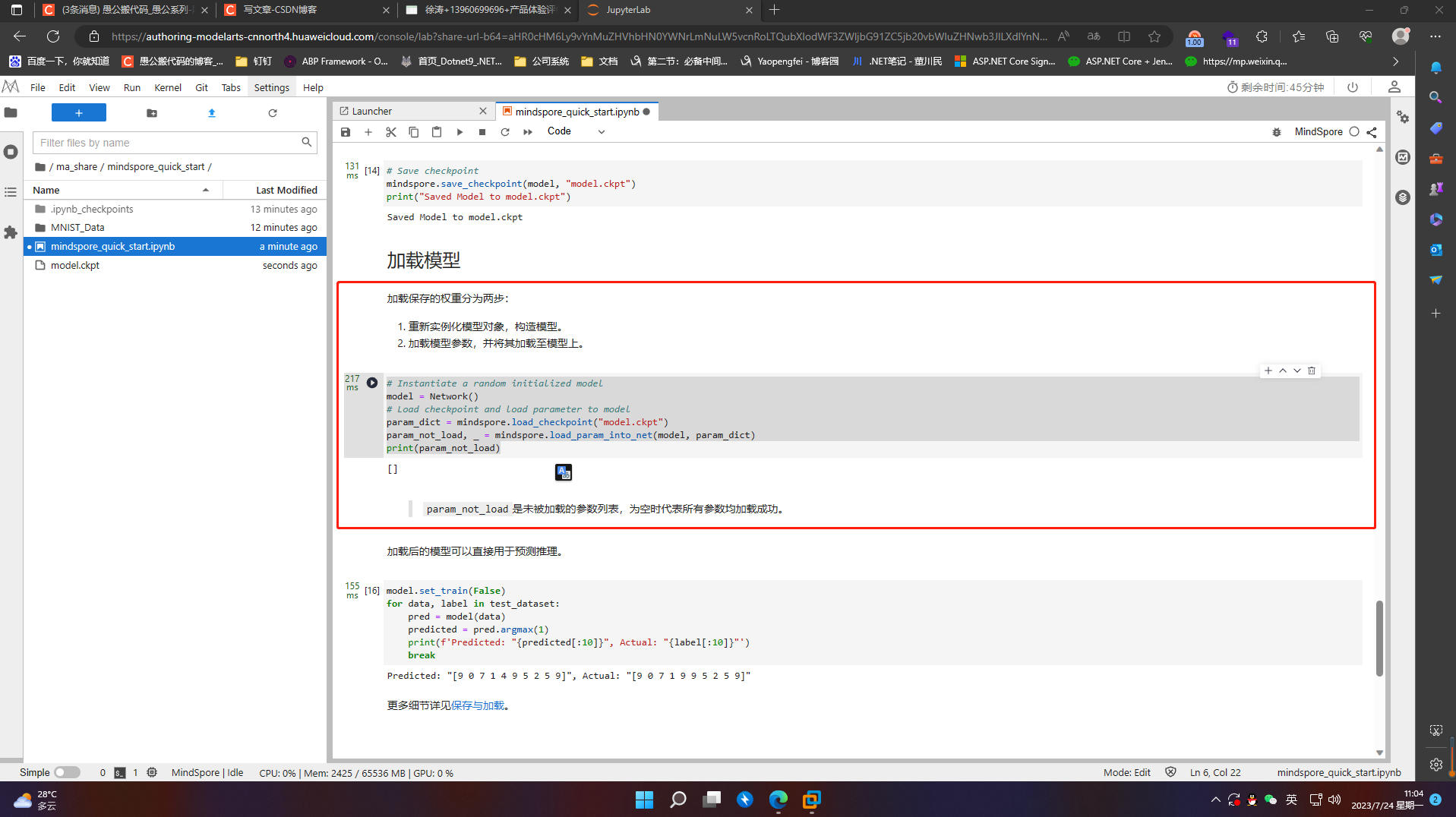
加载后的模型可以直接用于预测推理
4.张量 Tensor
张量是一种特殊的数据结构,与数组和矩阵非常相似。张量(Tensor)是MindSpore网络运算中的基本数据结构,本教程主要介绍张量和稀疏张量的属性及用法,导入相关包
import numpy as np
import mindspore
from mindspore import ops
from mindspore import Tensor, CSRTensor, COOTensor
4.1 创建张量
张量的创建方式有多种,构造张量时,支持传入Tensor、float、int、bool、tuple、list和numpy.ndarray类型。
1、根据数据直接生成
可以根据数据创建张量,数据类型可以设置或者通过框架自动推断。
data = [1, 0, 1, 0]
x_data = Tensor(data)
2、从NumPy数组生成
可以从NumPy数组创建张量
np_array = np.array(data)
x_np = Tensor(np_array)
3、使用init初始化器构造张量
当使用init初始化器对张量进行初始化时,支持传入的参数有init、shape、dtype。
-
init: 支持传入initializer的子类。
-
shape: 支持传入 list、tuple、 int。
-
dtype: 支持传入mindspore.dtype。
from mindspore.common.initializer import One, Normal
# Initialize a tensor with ones
tensor1 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=One())
# Initialize a tensor from normal distribution
tensor2 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=Normal())
print("tensor1:\n", tensor1)
print("tensor2:\n", tensor2)
4、承另一个张量的属性,形成新的张量
from mindspore import ops
x_ones = ops.ones_like(x_data)
print(f"Ones Tensor: \n {x_ones} \n")
x_zeros = ops.zeros_like(x_data)
print(f"Zeros Tensor: \n {x_zeros} \n")
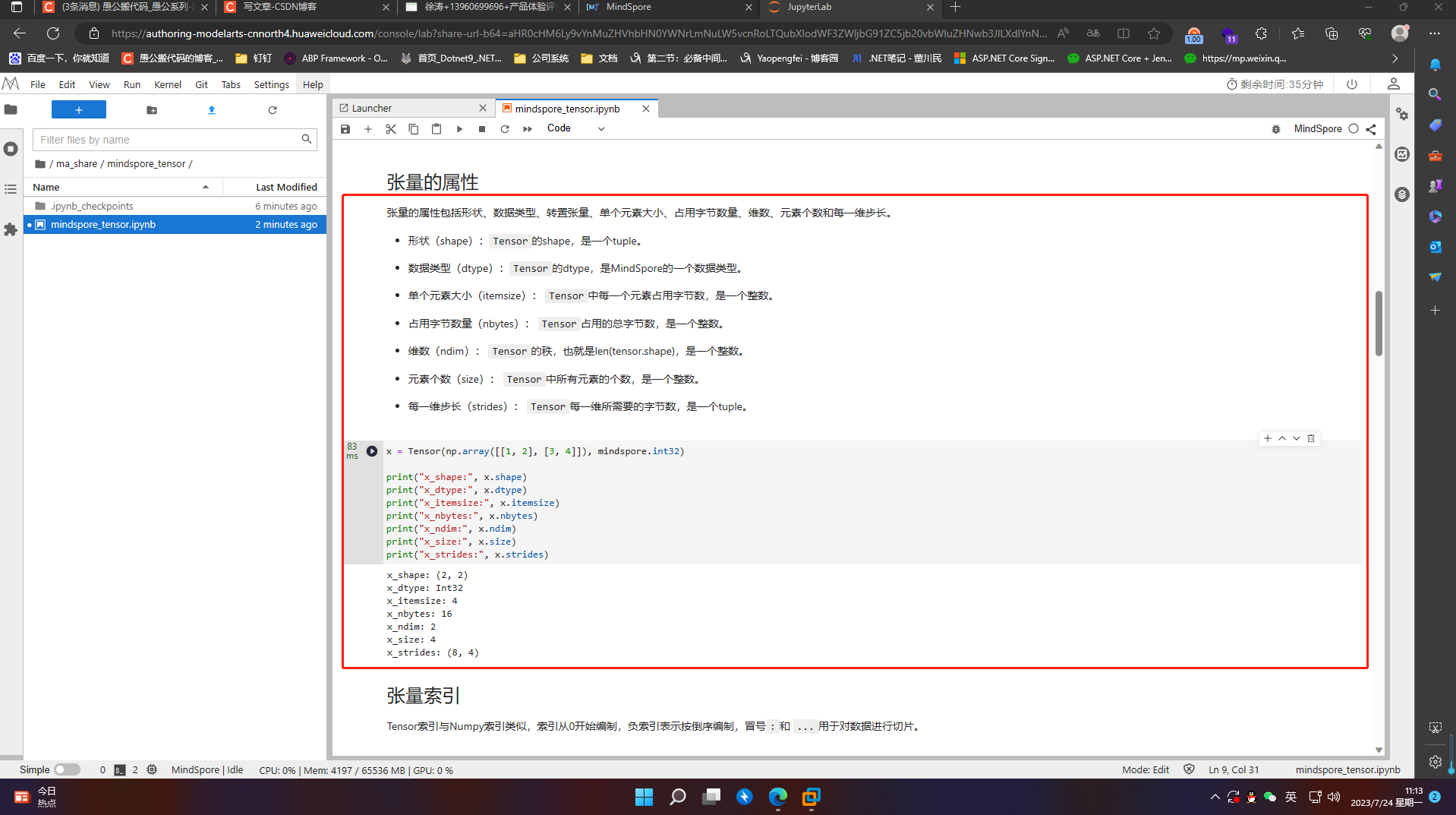
4.2 张量的属性
张量的属性包括形状、数据类型、转置张量、单个元素大小、占用字节数量、维数、元素个数和每一维步长。
-
形状(shape):Tensor的shape,是一个tuple。
-
数据类型(dtype):Tensor的dtype,是MindSpore的一个数据类型。
-
单个元素大小(itemsize): Tensor中每一个元素占用字节数,是一个整数。
-
占用字节数量(nbytes): Tensor占用的总字节数,是一个整数。
-
维数(ndim): Tensor的秩,也就是len(tensor.shape),是一个整数。
-
元素个数(size): Tensor中所有元素的个数,是一个整数。
-
每一维步长(strides): Tensor每一维所需要的字节数,是一个tuple。
x = Tensor(np.array([[1, 2], [3, 4]]), mindspore.int32)
print("x_shape:", x.shape)
print("x_dtype:", x.dtype)
print("x_itemsize:", x.itemsize)
print("x_nbytes:", x.nbytes)
print("x_ndim:", x.ndim)
print("x_size:", x.size)
print("x_strides:", x.strides)
4.3 张量索引
Tensor索引与Numpy索引类似,索引从0开始编制,负索引表示按倒序编制,冒号:和 …用于对数据进行切片
tensor = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
print("First row: {}".format(tensor[0]))
print("value of bottom right corner: {}".format(tensor[1, 1]))
print("Last column: {}".format(tensor[:, -1]))
print("First column: {}".format(tensor[..., 0]))
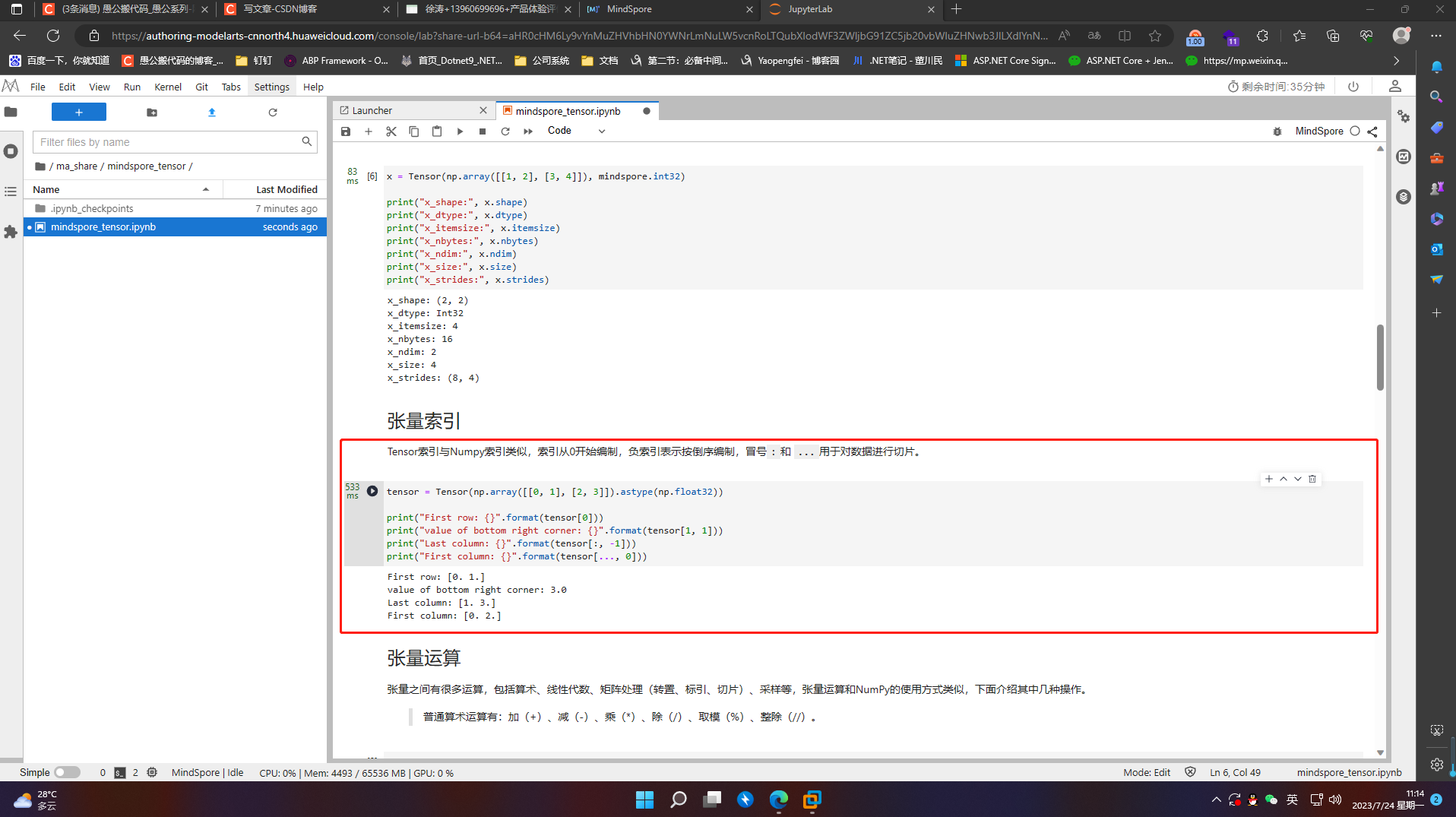
4.4 张量运算
张量之间有很多运算,包括算术、线性代数、矩阵处理(转置、标引、切片)、采样等,张量运算和NumPy的使用方式类似,下面介绍其中几种操作。
普通算术运算有:加(+)、减(-)、乘(*)、除(/)、取模(%)、整除(//)。
x = Tensor(np.array([1, 2, 3]), mindspore.float32)
y = Tensor(np.array([4, 5, 6]), mindspore.float32)
output_add = x + y
output_sub = x - y
output_mul = x * y
output_div = y / x
output_mod = y % x
output_floordiv = y // x
print("add:", output_add)
print("sub:", output_sub)
print("mul:", output_mul)
print("div:", output_div)
print("mod:", output_mod)
print("floordiv:", output_floordiv)
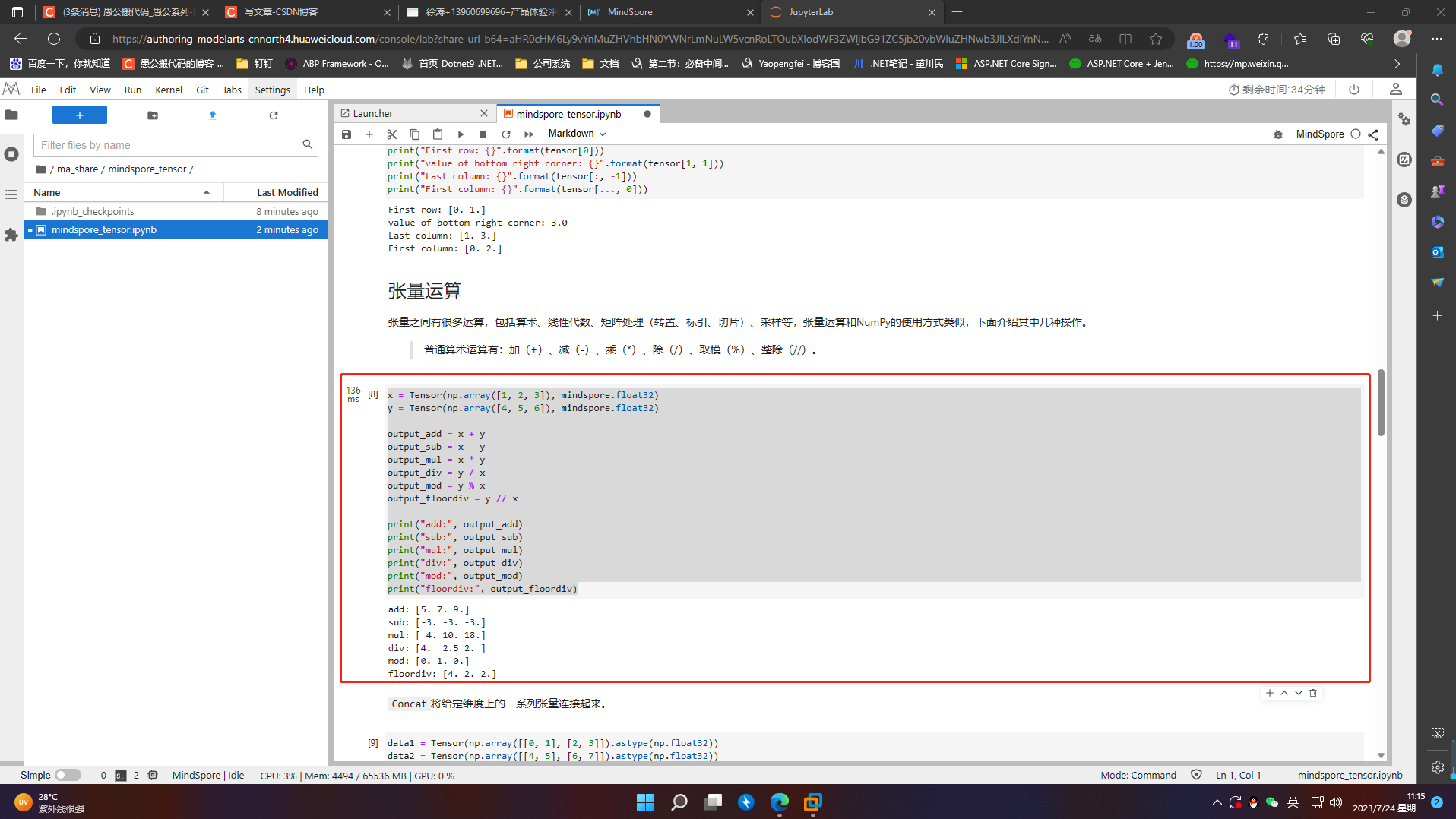
Concat将给定维度上的一系列张量连接起来
data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
data2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output = ops.concat((data1, data2), axis=0)
print(output)
print("shape:\n", output.shape)
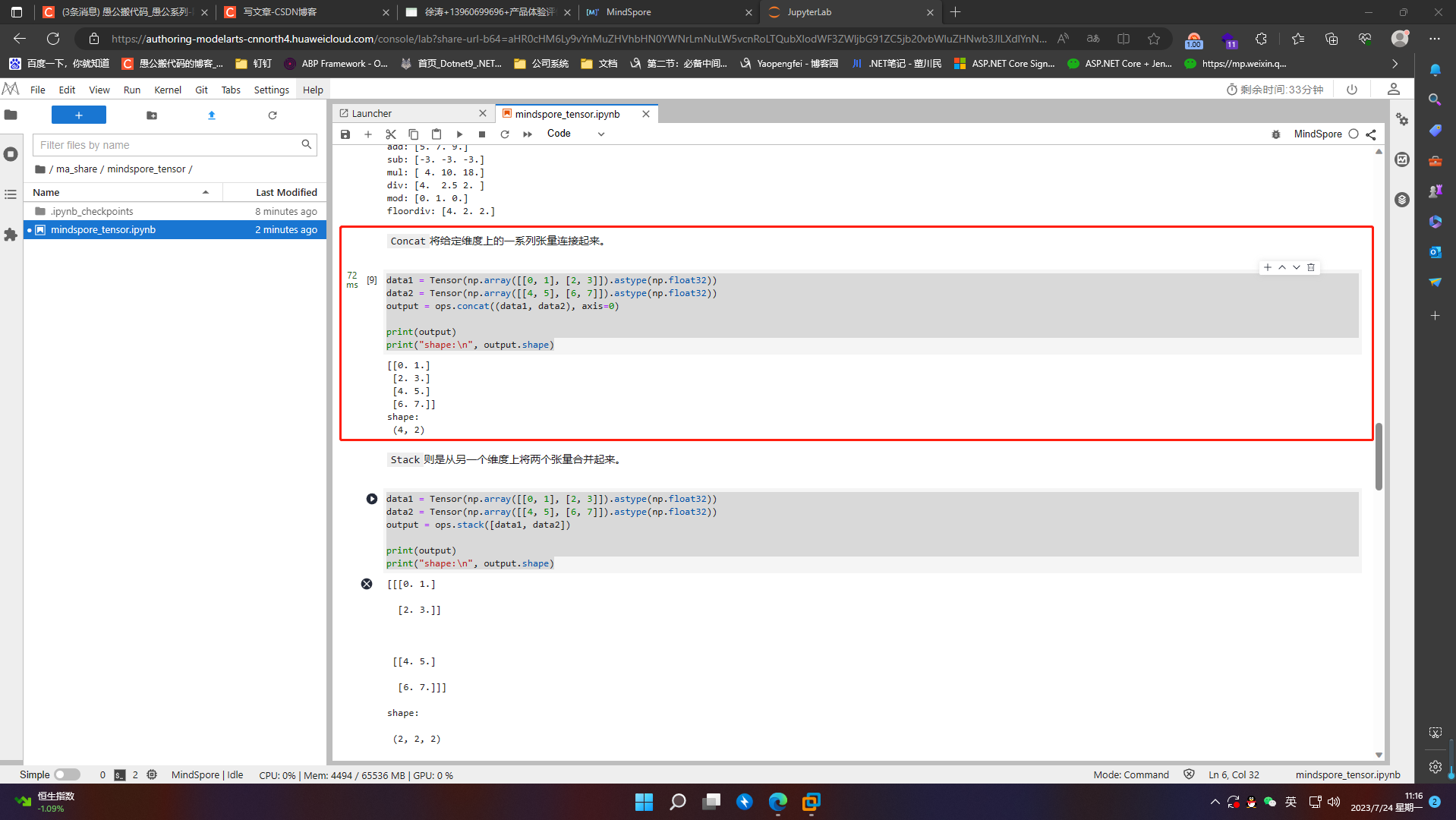
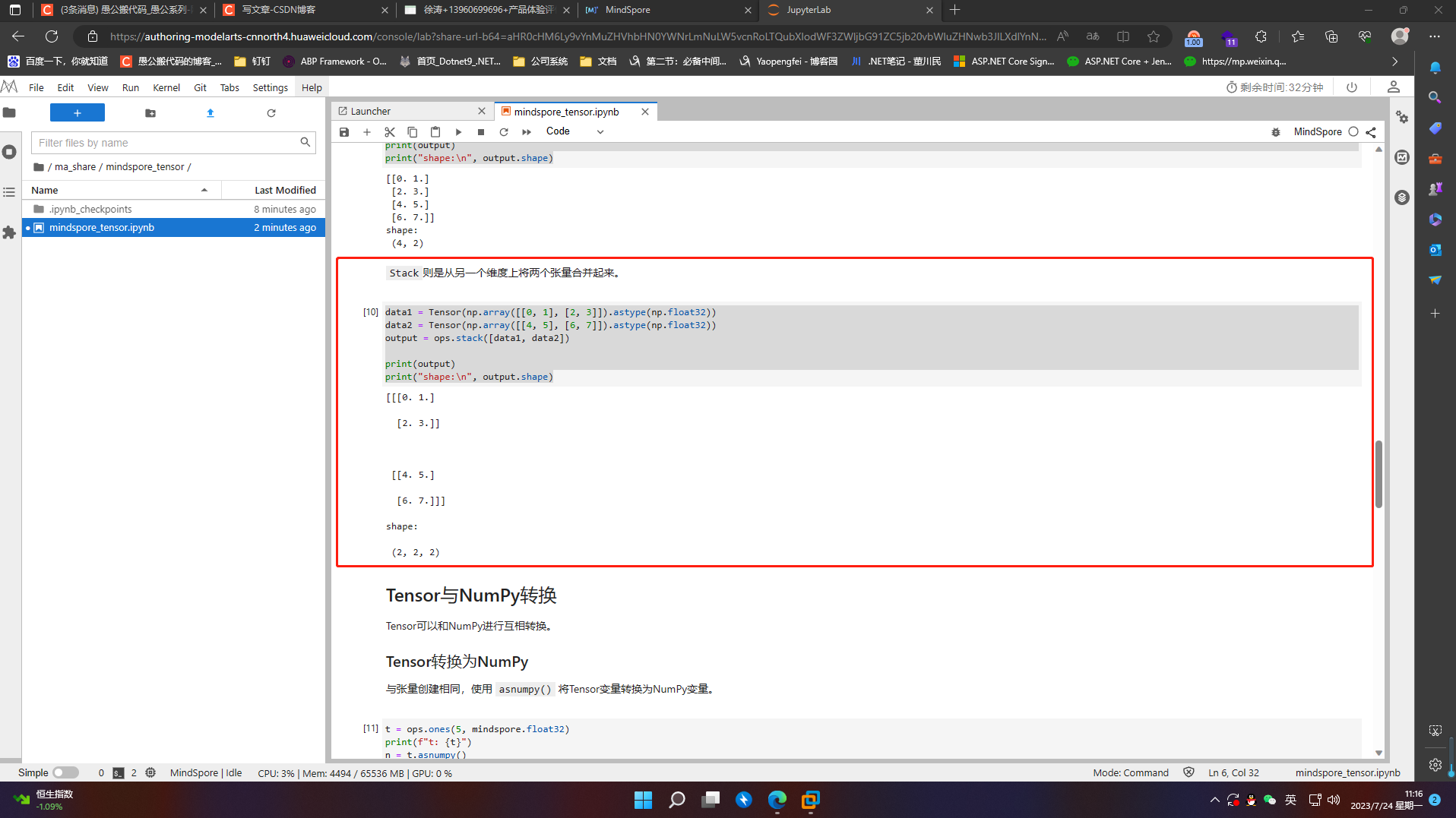
Stack则是从另一个维度上将两个张量合并起来
data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
data2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output = ops.stack([data1, data2])
print(output)
print("shape:\n", output.shape)
4.5 Tensor与NumPy转换
4.5.1 Tensor转换为NumPy
与张量创建相同,使用 asnumpy() 将Tensor变量转换为NumPy变量
t = ops.ones(5, mindspore.float32)
print(f"t: {t}")
n = t.asnumpy()
print(f"n: {n}")
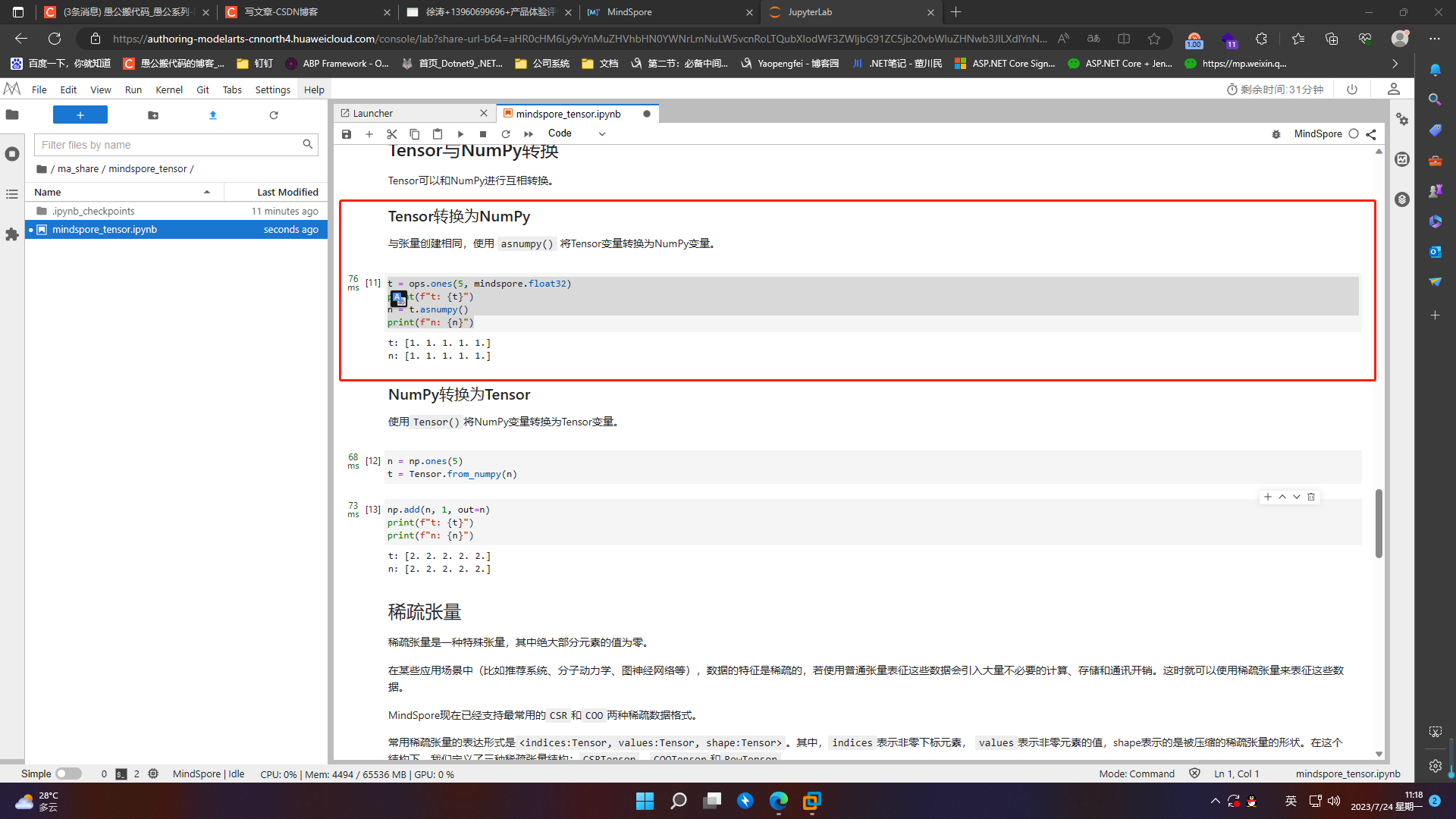
4.5.2 NumPy转换为Tensor
使用Tensor()将NumPy变量转换为Tensor变量
n = np.ones(5)
t = Tensor.from_numpy(n)
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")
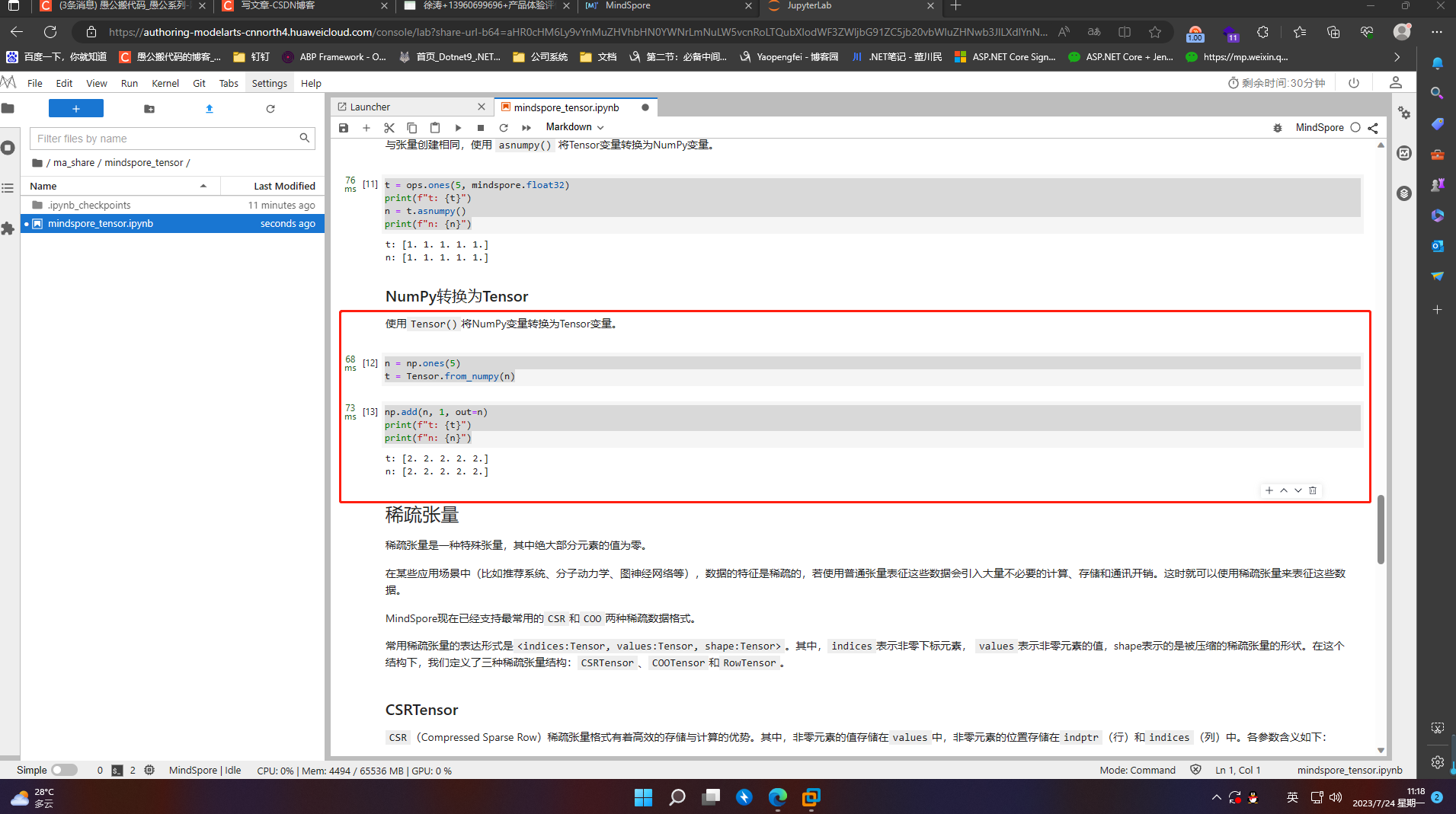
4.6 稀疏张量
稀疏张量是一种特殊张量,其中绝大部分元素的值为零。
在某些应用场景中(比如推荐系统、分子动力学、图神经网络等),数据的特征是稀疏的,若使用普通张量表征这些数据会引入大量不必要的计算、存储和通讯开销。这时就可以使用稀疏张量来表征这些数据。
MindSpore现在已经支持最常用的CSR和COO两种稀疏数据格式。
常用稀疏张量的表达形式是<indices:Tensor, values:Tensor, shape:Tensor>。其中,indices表示非零下标元素, values表示非零元素的值,shape表示的是被压缩的稀疏张量的形状。在这个结构下,我们定义了三种稀疏张量结构:CSRTensor、COOTensor和RowTensor。
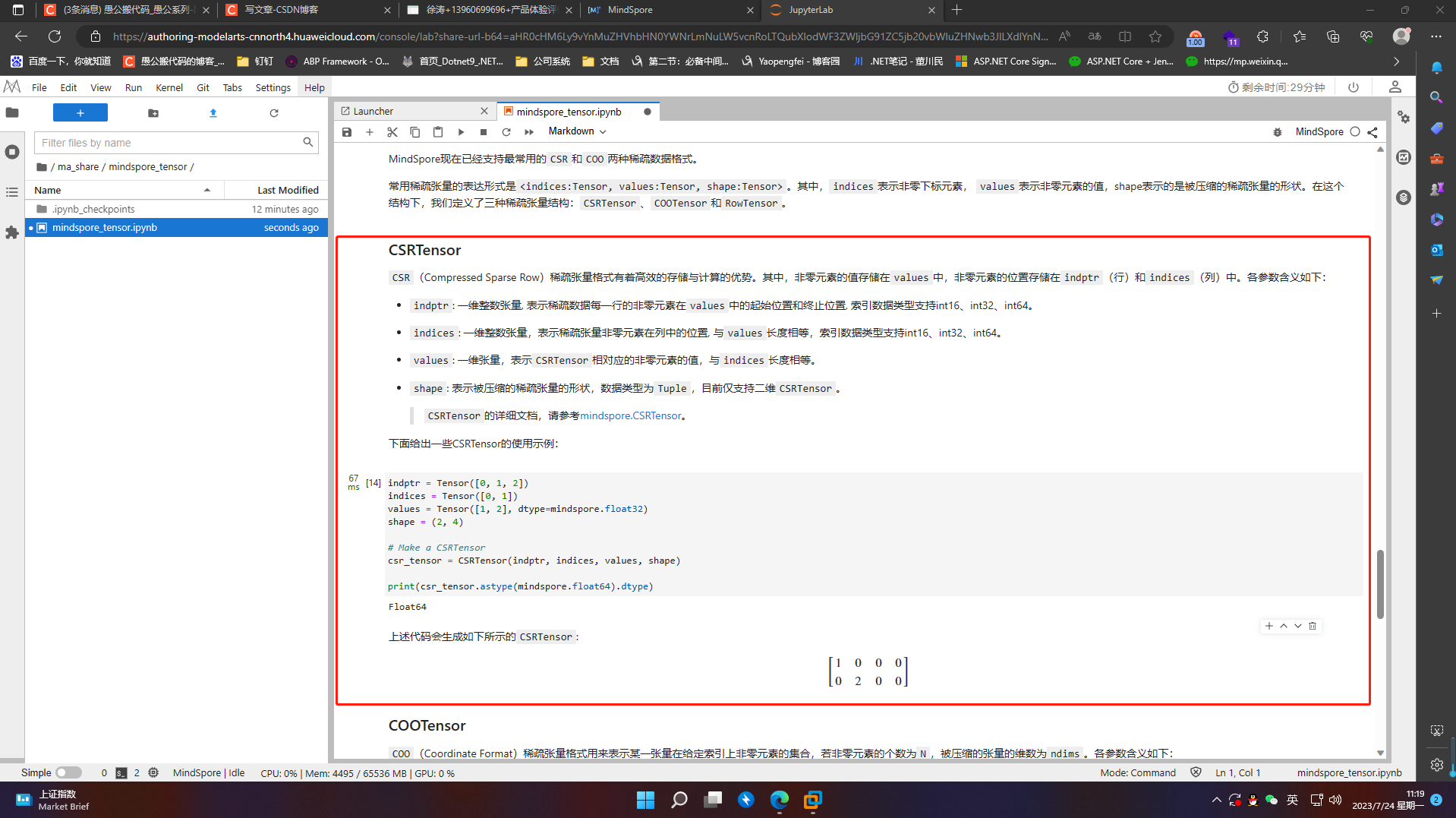
4.6.1 CSRTensor
CSR(Compressed Sparse Row)稀疏张量格式有着高效的存储与计算的优势。其中,非零元素的值存储在values中,非零元素的位置存储在indptr(行)和indices(列)中。各参数含义如下:
-
indptr: 一维整数张量, 表示稀疏数据每一行的非零元素在values中的起始位置和终止位置,
索引数据类型支持int16、int32、int64。 -
indices: 一维整数张量,表示稀疏张量非零元素在列中的位置, 与values长度相等,索引数据类型支持int16、int32、int64。
-
values: 一维张量,表示CSRTensor相对应的非零元素的值,与indices长度相等。
-
shape: 表示被压缩的稀疏张量的形状,数据类型为Tuple,目前仅支持二维CSRTensor。
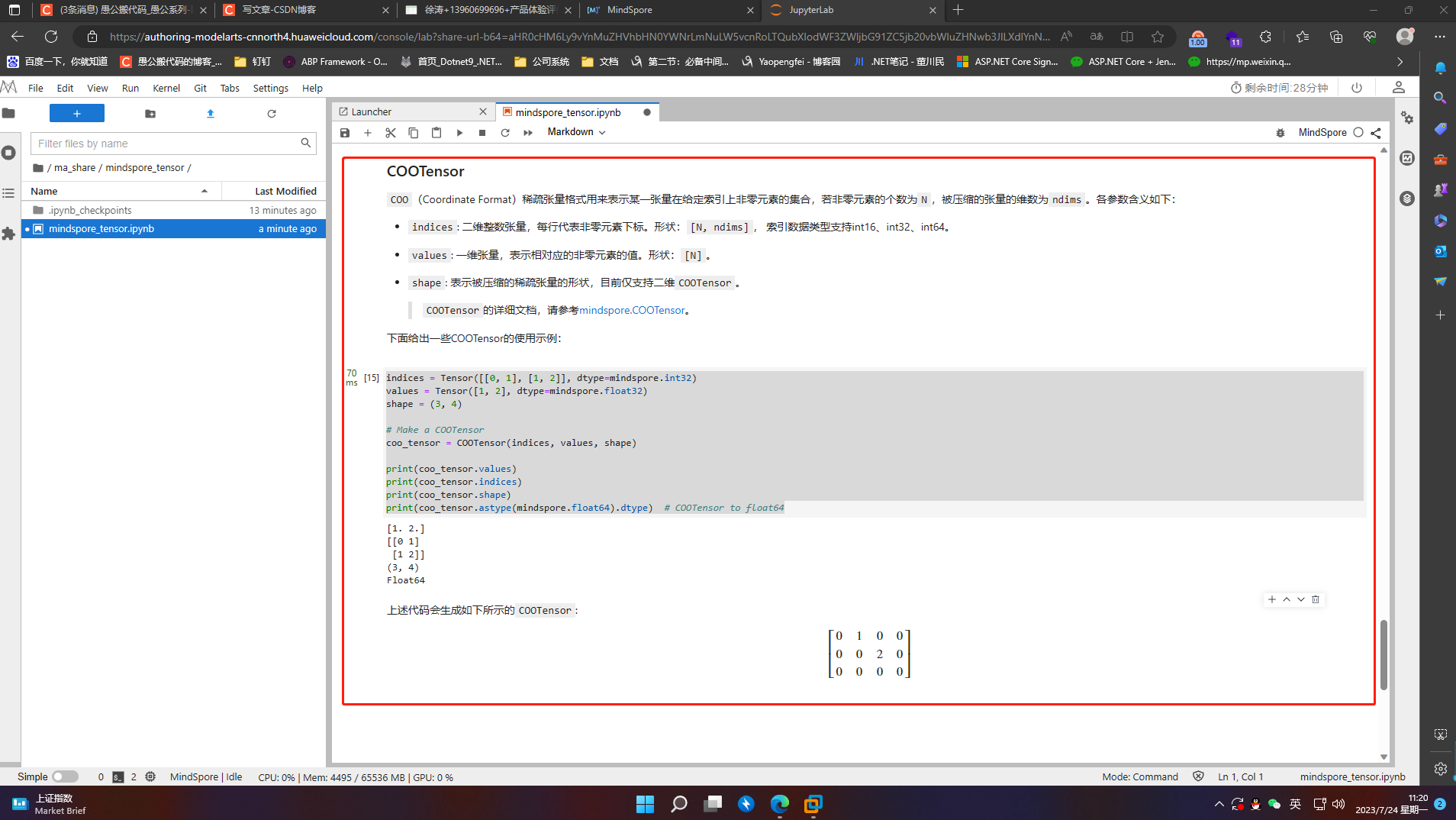
4.6.2 COOTensor
COO(Coordinate Format)稀疏张量格式用来表示某一张量在给定索引上非零元素的集合,若非零元素的个数为N,被压缩的张量的维数为ndims。各参数含义如下:
-
indices: 二维整数张量,每行代表非零元素下标。形状:[N, ndims], 索引数据类型支持int16、int32、int64。
-
values: 一维张量,表示相对应的非零元素的值。形状:[N]。
-
shape: 表示被压缩的稀疏张量的形状,目前仅支持二维COOTensor。
indices = Tensor([[0, 1], [1, 2]], dtype=mindspore.int32)
values = Tensor([1, 2], dtype=mindspore.float32)
shape = (3, 4)
# Make a COOTensor
coo_tensor = COOTensor(indices, values, shape)
print(coo_tensor.values)
print(coo_tensor.indices)
print(coo_tensor.shape)
print(coo_tensor.astype(mindspore.float64).dtype) # COOTensor to float64
5.数据集 Dataset
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipeline的起始,用于加载原始数据。mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。
此外MindSpore的领域开发库也提供了大量的预加载数据集,可以使用API一键下载使用。本教程将分别对不同的数据集加载方式、数据集常见操作和自定义数据集方法进行详细阐述。
import numpy as np
from mindspore.dataset import vision
from mindspore.dataset import MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt
5.1 数据集加载
mindspore.dataset提供的接口仅支持解压后的数据文件,因此我们使用download库下载数据集并解压
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
压缩文件删除后,直接加载,可以看到其数据类型为MnistDataset
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
print(type(train_dataset))
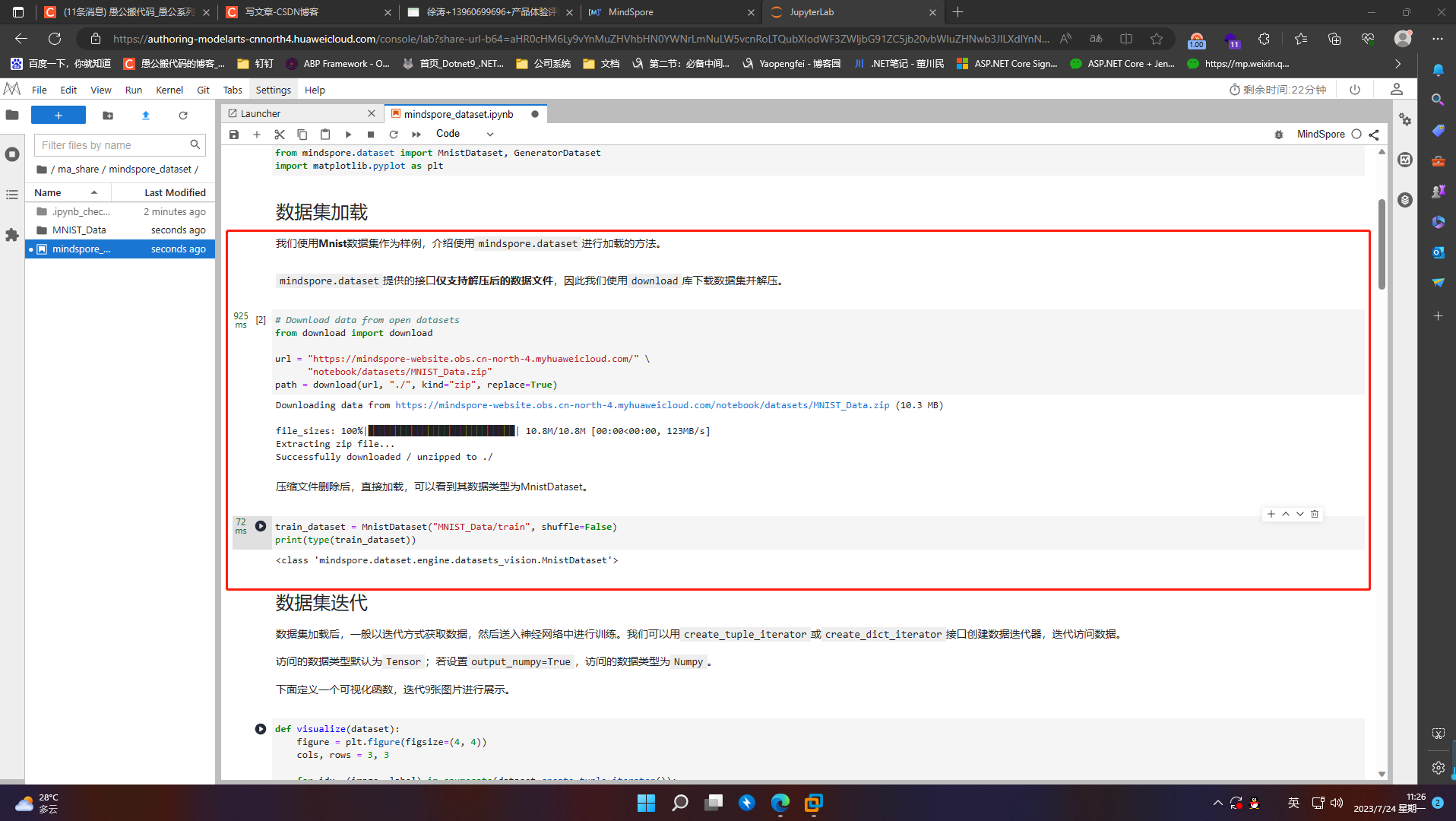
5.2 数据集迭代
数据集加载后,一般以迭代方式获取数据,然后送入神经网络中进行训练。我们可以用create_tuple_iterator或create_dict_iterator接口创建数据迭代器,迭代访问数据。
访问的数据类型默认为Tensor;若设置output_numpy=True,访问的数据类型为Numpy。
下面定义一个可视化函数,迭代9张图片进行展示。
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()
visualize(train_dataset)
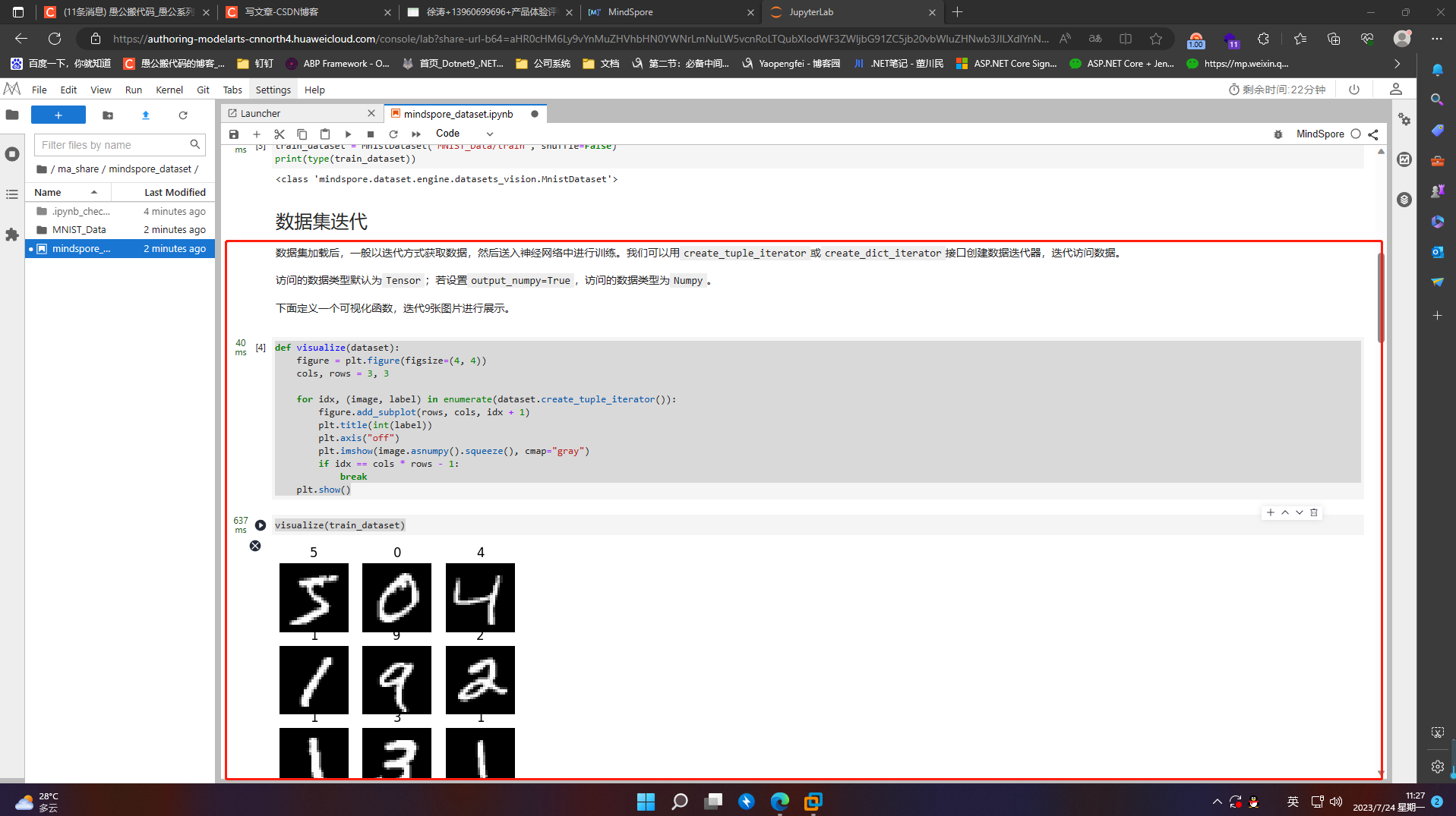
5.3 数据集常用操作
Pipeline的设计理念使得数据集的常用操作采用dataset = dataset.operation()的异步执行方式,执行操作返回新的Dataset,此时不执行具体操作,而是在Pipeline中加入节点,最终进行迭代时,并行执行整个Pipeline
5.3.1 shuffle
数据集随机shuffle可以消除数据排列造成的分布不均问题
train_dataset = train_dataset.shuffle(buffer_size=64)
visualize(train_dataset)
5.3.2 map
map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。这里我们对Mnist数据集做数据缩放处理,将图像统一除255,数据类型由uint8转为float32
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
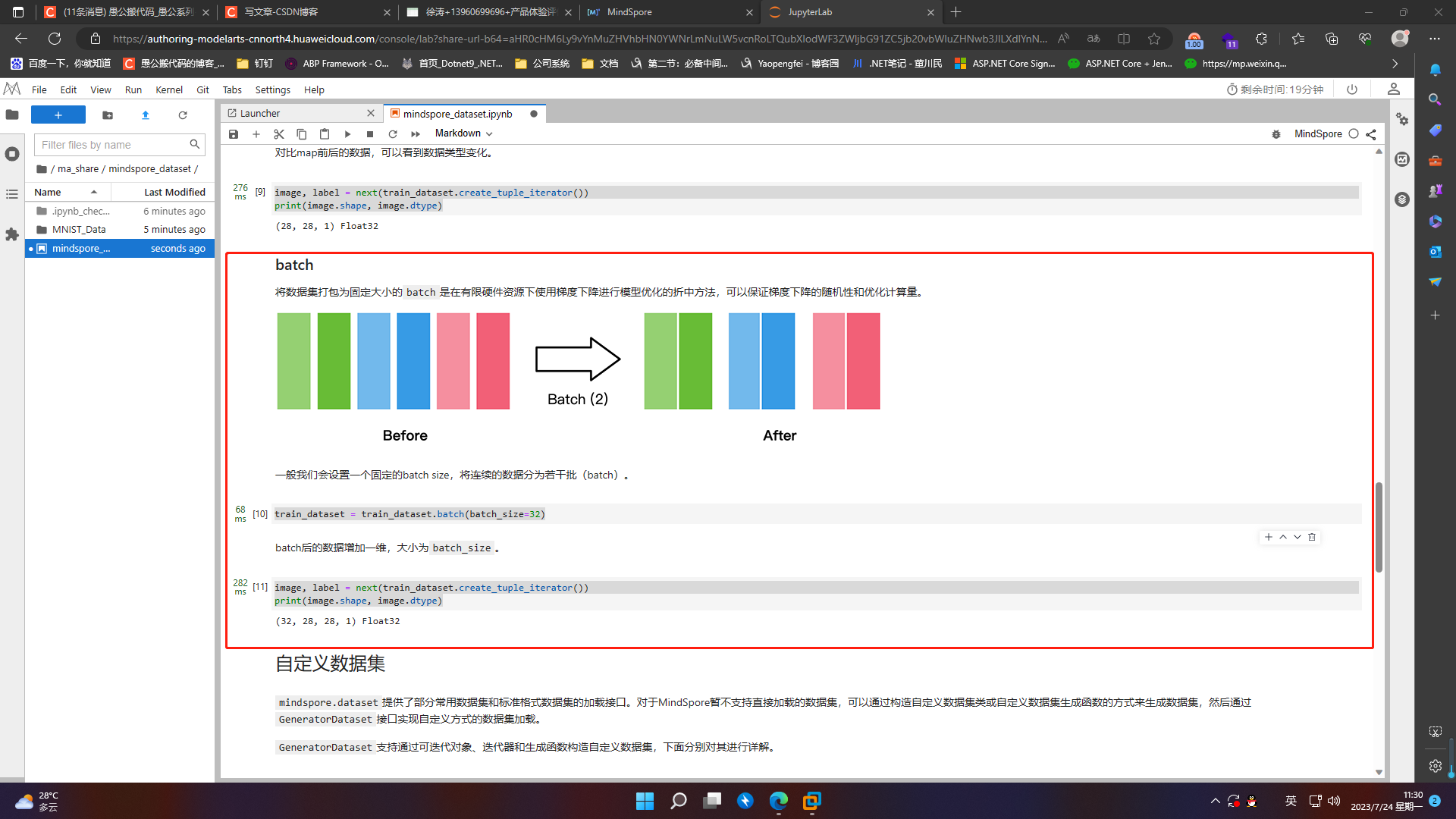
5.3.3 batch
将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量
train_dataset = train_dataset.batch(batch_size=32)
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
5.4 自定义数据集
mindspore.dataset提供了部分常用数据集和标准格式数据集的加载接口。对于MindSpore暂不支持直接加载的数据集,可以通过构造自定义数据集类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。
GeneratorDataset支持通过可迭代对象、迭代器和生成函数构造自定义数据集,下面分别对其进行详解。
5.4.1 可迭代对象
Python中可以使用for循环遍历出所有元素的,都可以称为可迭代对象(Iterable),我们可以通过实现__getitem__方法来构造可迭代对象,并将其加载至GeneratorDataset。
# Iterable object as input source
class Iterable:
def __init__(self):
self._data = np.random.sample((5, 2))
self._label = np.random.sample((5, 1))
def __getitem__(self, index):
return self._data[index], self._label[index]
def __len__(self):
return len(self._data)
data = Iterable()
dataset = GeneratorDataset(source=data, column_names=["data", "label"])
# list, dict, tuple are also iterable object.
dataset = GeneratorDataset(source=[(np.array(0),), (np.array(1),), (np.array(2),)], column_names=["col"])
5.4.2 迭代器
Python中内置有__iter__和__next__方法的对象,称为迭代器(Iterator)。下面构造一个简单迭代器,并将其加载至GeneratorDataset。
# Iterator as input source
class Iterator:
def __init__(self):
self._index = 0
self._data = np.random.sample((5, 2))
self._label = np.random.sample((5, 1))
def __next__(self):
if self._index >= len(self._data):
raise StopIteration
else:
item = (self._data[self._index], self._label[self._index])
self._index += 1
return item
def __iter__(self):
self._index = 0
return self
def __len__(self):
return len(self._data)
data = Iterator()
dataset = GeneratorDataset(source=data, column_names=["data", "label"])
6.数据变换 Transforms
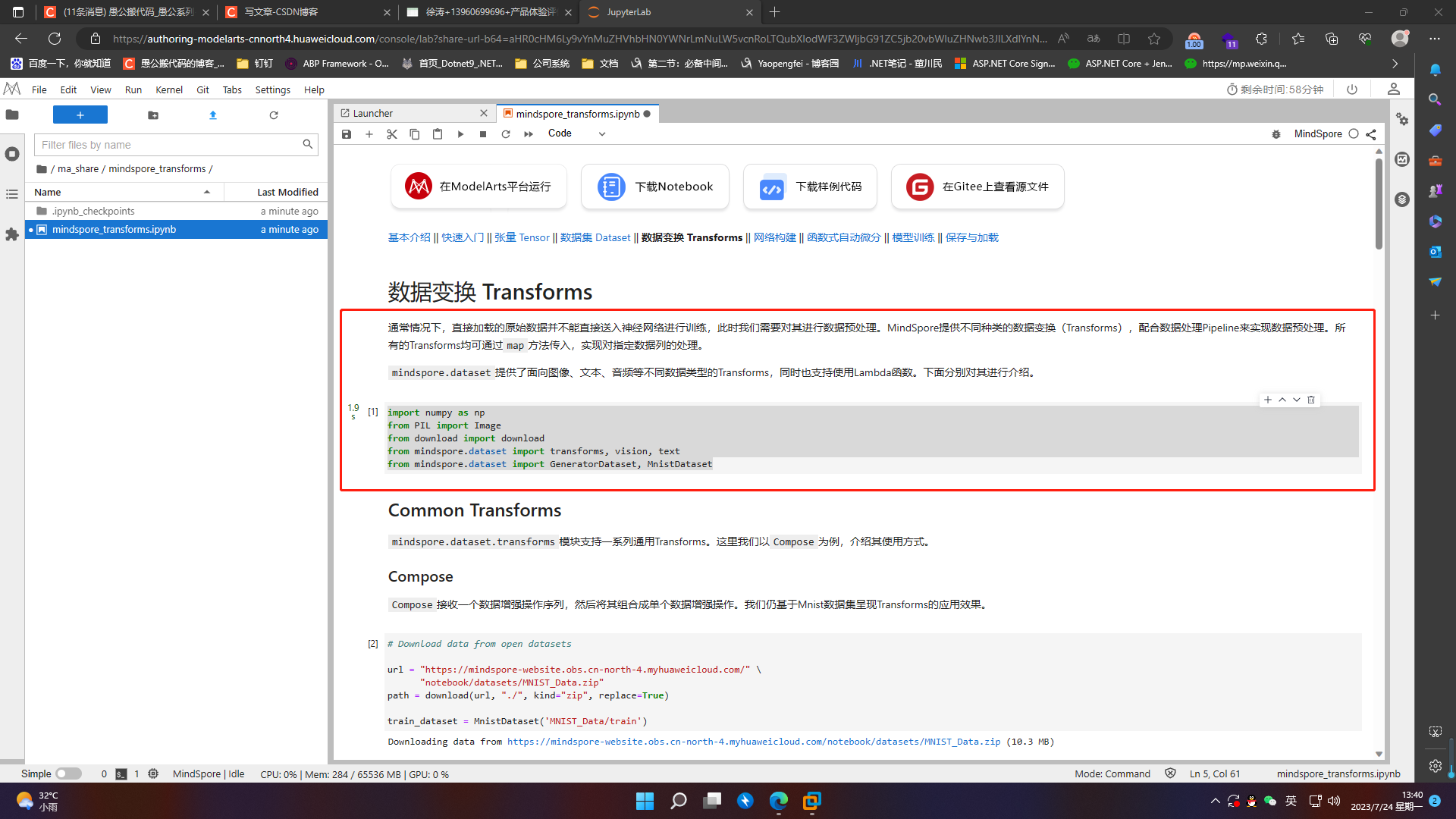
通常情况下,直接加载的原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。下面分别对其进行介绍。
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
6.1 Common Transforms
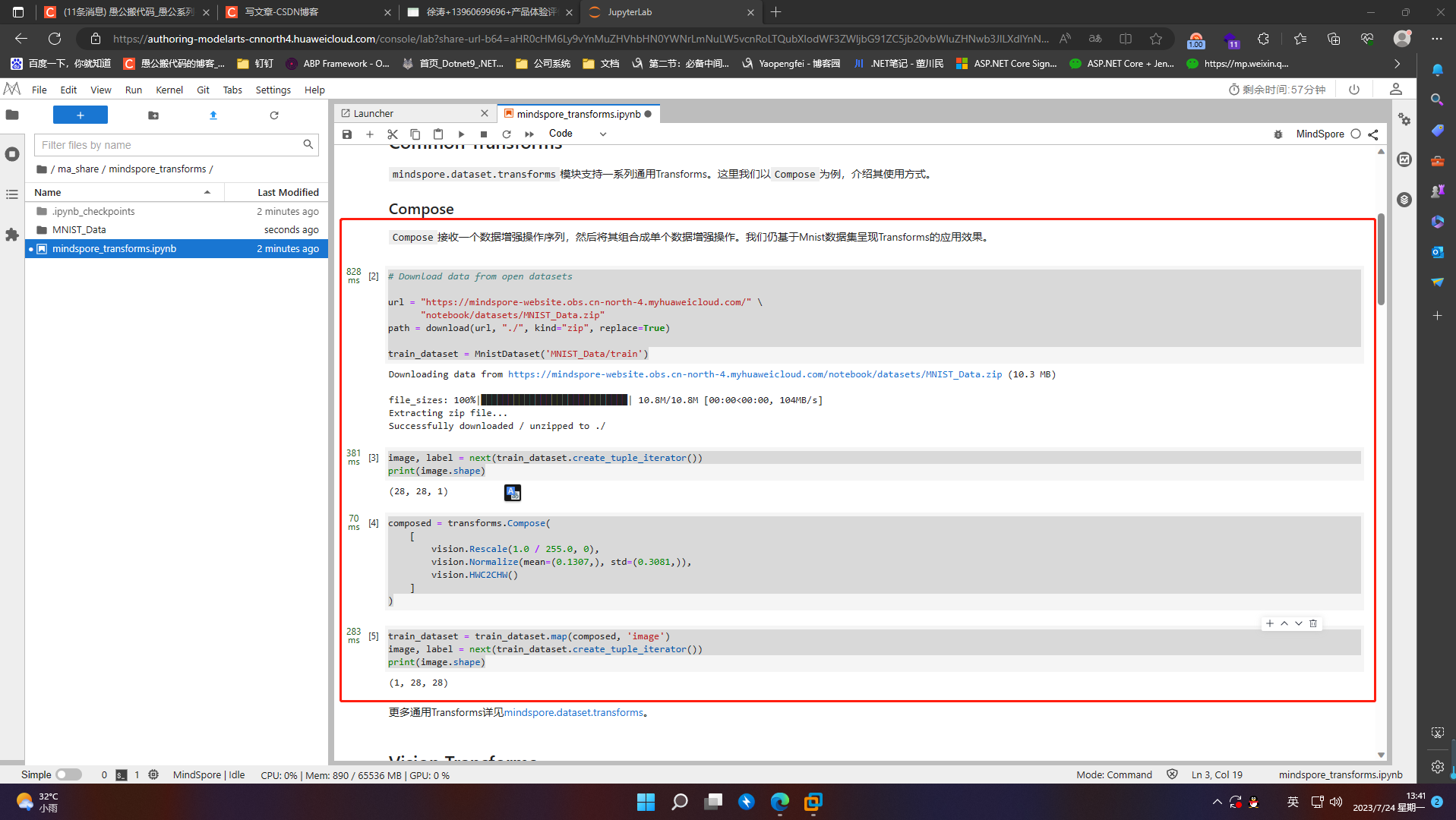
mindspore.dataset.transforms模块支持一系列通用Transforms。这里我们以Compose为例,介绍其使用方式。
6.1.1 Compose
Compose接收一个数据增强操作序列,然后将其组合成单个数据增强操作。我们仍基于Mnist数据集呈现Transforms的应用效果。
# Download data from open datasets
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset('MNIST_Data/train')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
composed = transforms.Compose(
[
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
)
train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
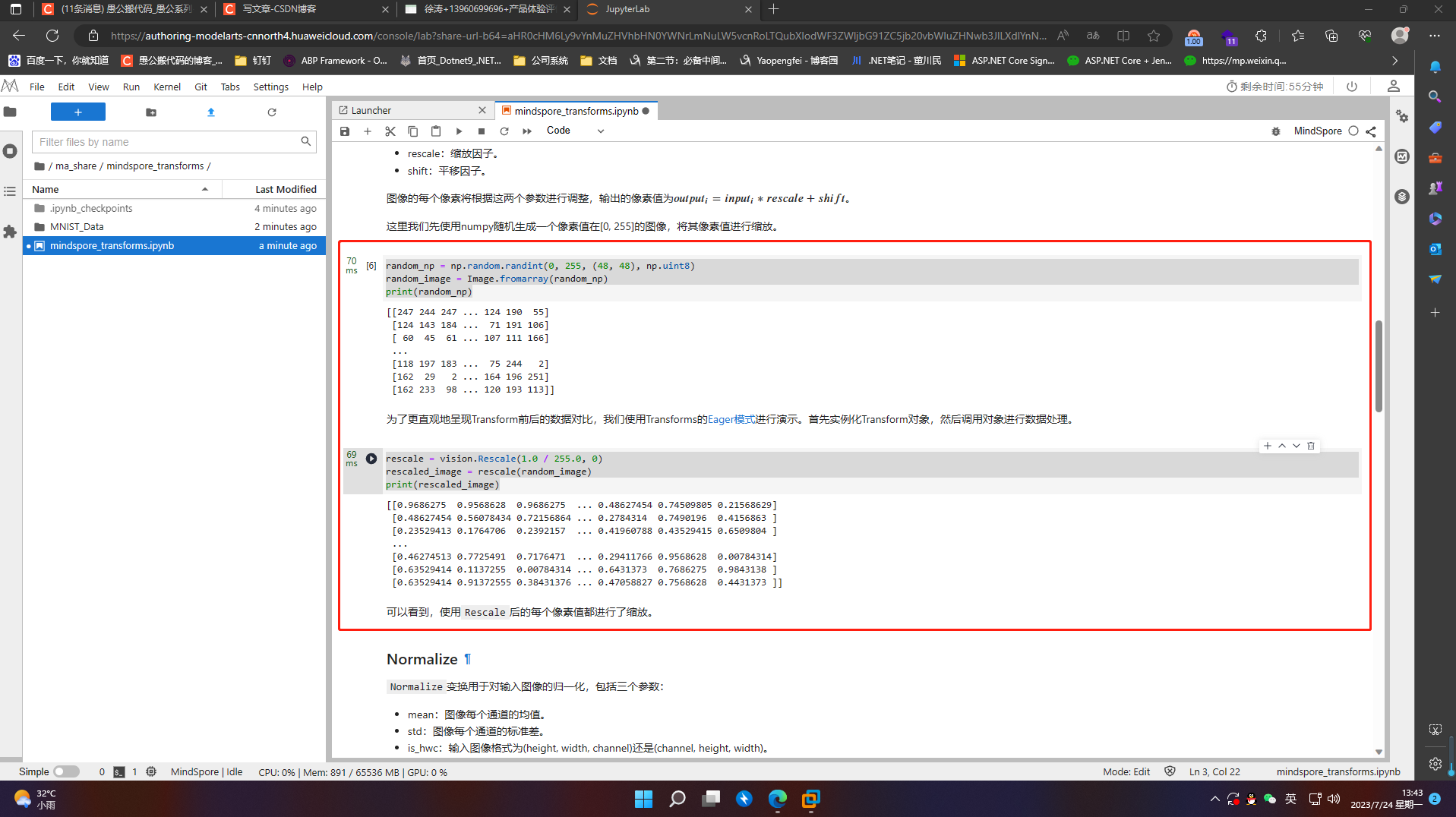
6.2 Vision Transforms
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。在Mnist数据处理过程中,使用了Rescale、Normalize和HWC2CHW变换。
6.2.1 Rescale
Rescale变换用于调整图像像素值的大小,包括两个参数:
-
rescale:缩放因子。
-
shift:平移因子。
图像的每个像素将根据这两个参数进行调整,输出的像素值为 𝑜𝑢𝑡𝑝𝑢𝑡𝑖=𝑖𝑛𝑝𝑢𝑡𝑖∗𝑟𝑒𝑠𝑐𝑎𝑙𝑒+𝑠ℎ𝑖𝑓𝑡
这里我们先使用numpy随机生成一个像素值在[0, 255]的图像,将其像素值进行缩放
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)
为了更直观地呈现Transform前后的数据对比,我们使用Transforms的Eager模式进行演示。首先实例化Transform对象,然后调用对象进行数据处理
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)
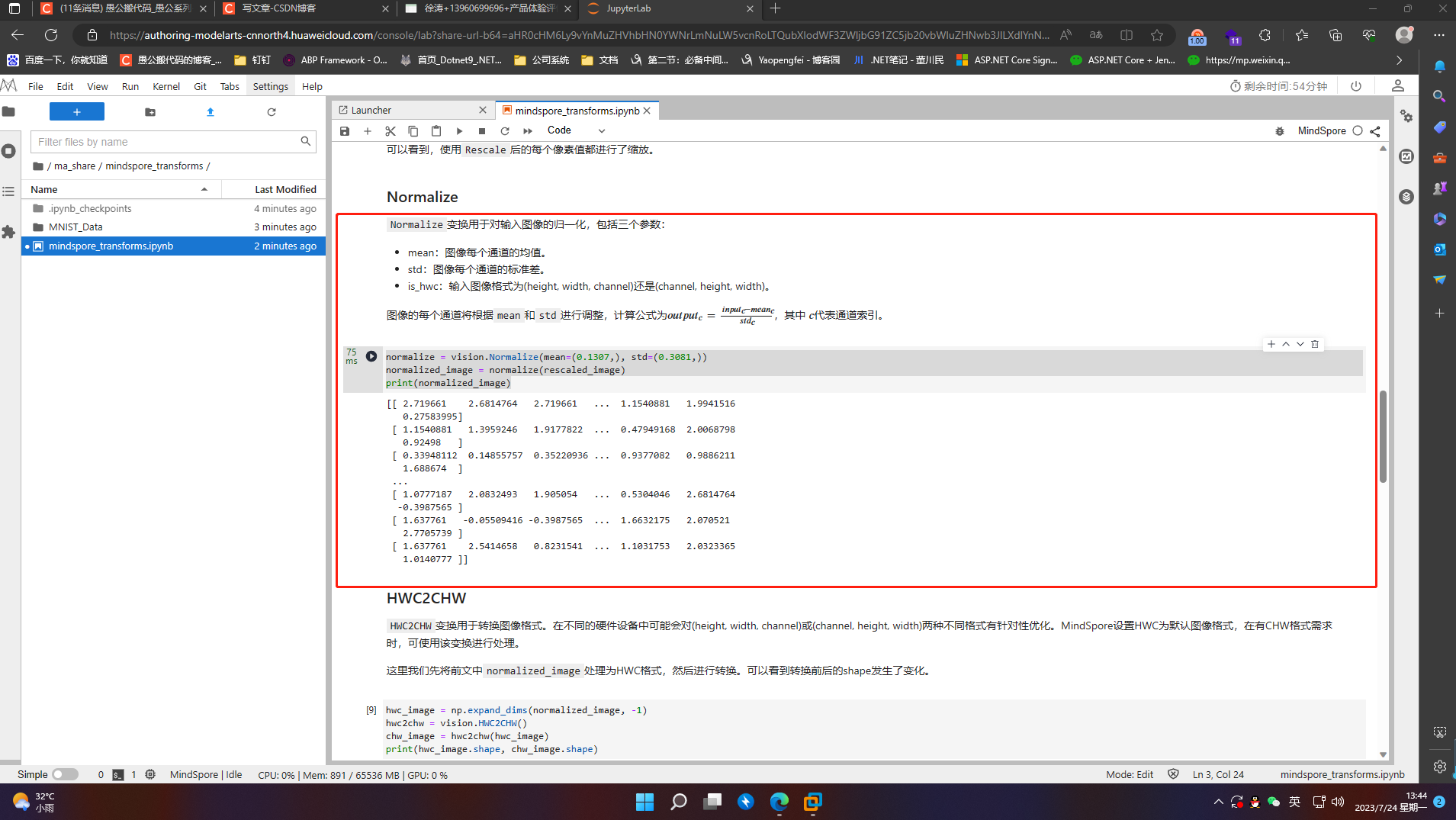
6.2.2 Normalize
Normalize变换用于对输入图像的归一化,包括三个参数:
- mean:图像每个通道的均值。
- std:图像每个通道的标准差。
- is_hwc:输入图像格式为(height, width, channel)还是(channel, height, width)。
图像的每个通道将根据mean和std进行调整,计算公式为 𝑜𝑢𝑡𝑝𝑢𝑡𝑐=𝑖𝑛𝑝𝑢𝑡𝑐−𝑚𝑒𝑎𝑛𝑐𝑠𝑡𝑑𝑐 ,其中 𝑐 代表通道索引。
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image)
6.2.3 HWC2CHW
HWC2CHW变换用于转换图像格式。在不同的硬件设备中可能会对(height, width, channel)或(channel, height, width)两种不同格式有针对性优化。MindSpore设置HWC为默认图像格式,在有CHW格式需求时,可使用该变换进行处理。
这里我们先将前文中normalized_image处理为HWC格式,然后进行转换。可以看到转换前后的shape发生了变化。
hwc_image = np.expand_dims(normalized_image, -1)
hwc2chw = vision.HWC2CHW()
chw_image = hwc2chw(hwc_image)
print(hwc_image.shape, chw_image.shape)

6.3 Text Transforms
mindspore.dataset.text模块提供一系列针对文本数据的Transforms。与图像数据不同,文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。这里简单介绍其使用方法。
首先我们定义三段文本,作为待处理的数据,并使用GeneratorDataset进行加载。
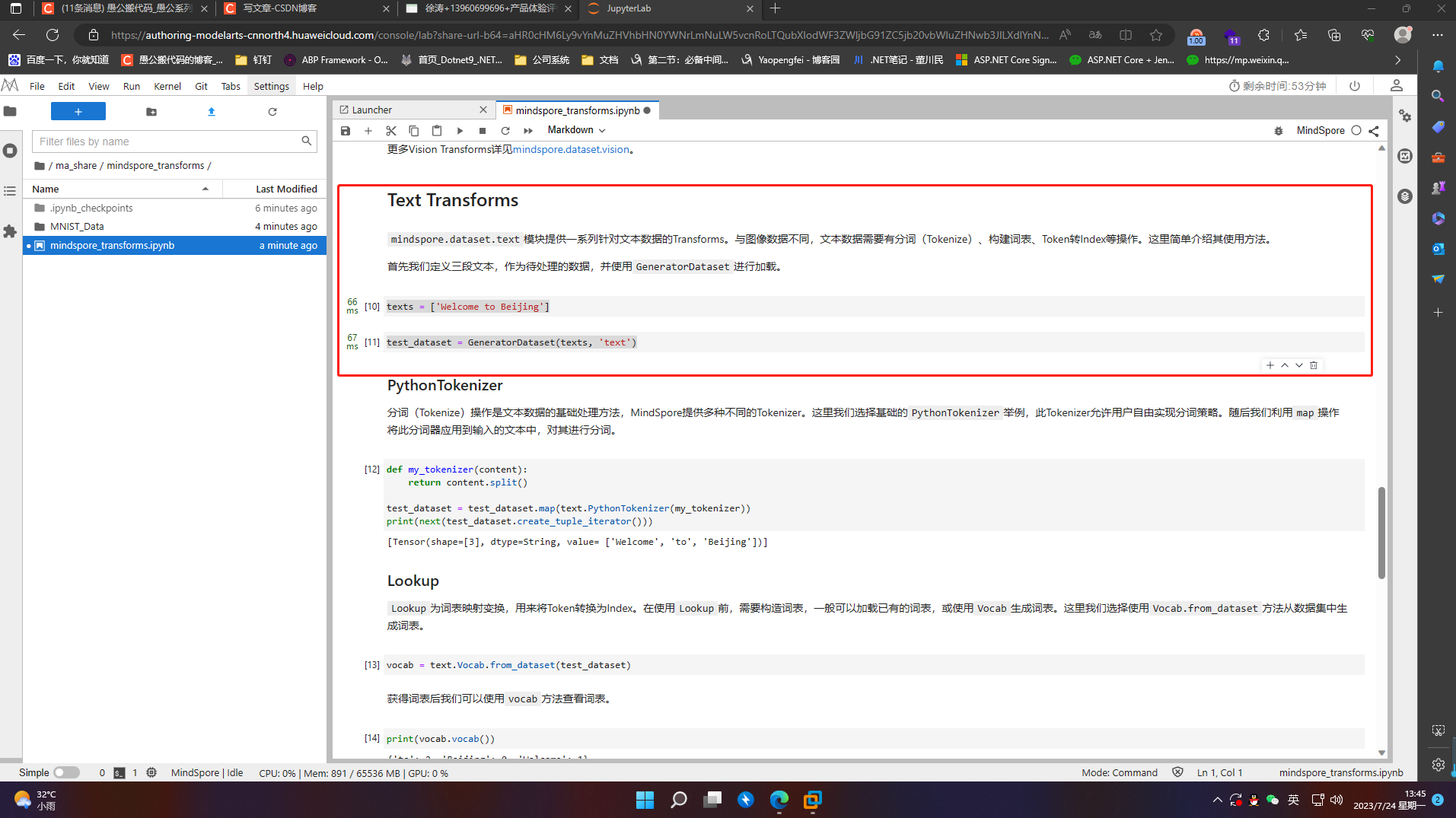
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')
6.3.1 PythonTokenizer
分词(Tokenize)操作是文本数据的基础处理方法,MindSpore提供多种不同的Tokenizer。这里我们选择基础的PythonTokenizer举例,此Tokenizer允许用户自由实现分词策略。随后我们利用map操作将此分词器应用到输入的文本中,对其进行分词。
def my_tokenizer(content):
return content.split()
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))
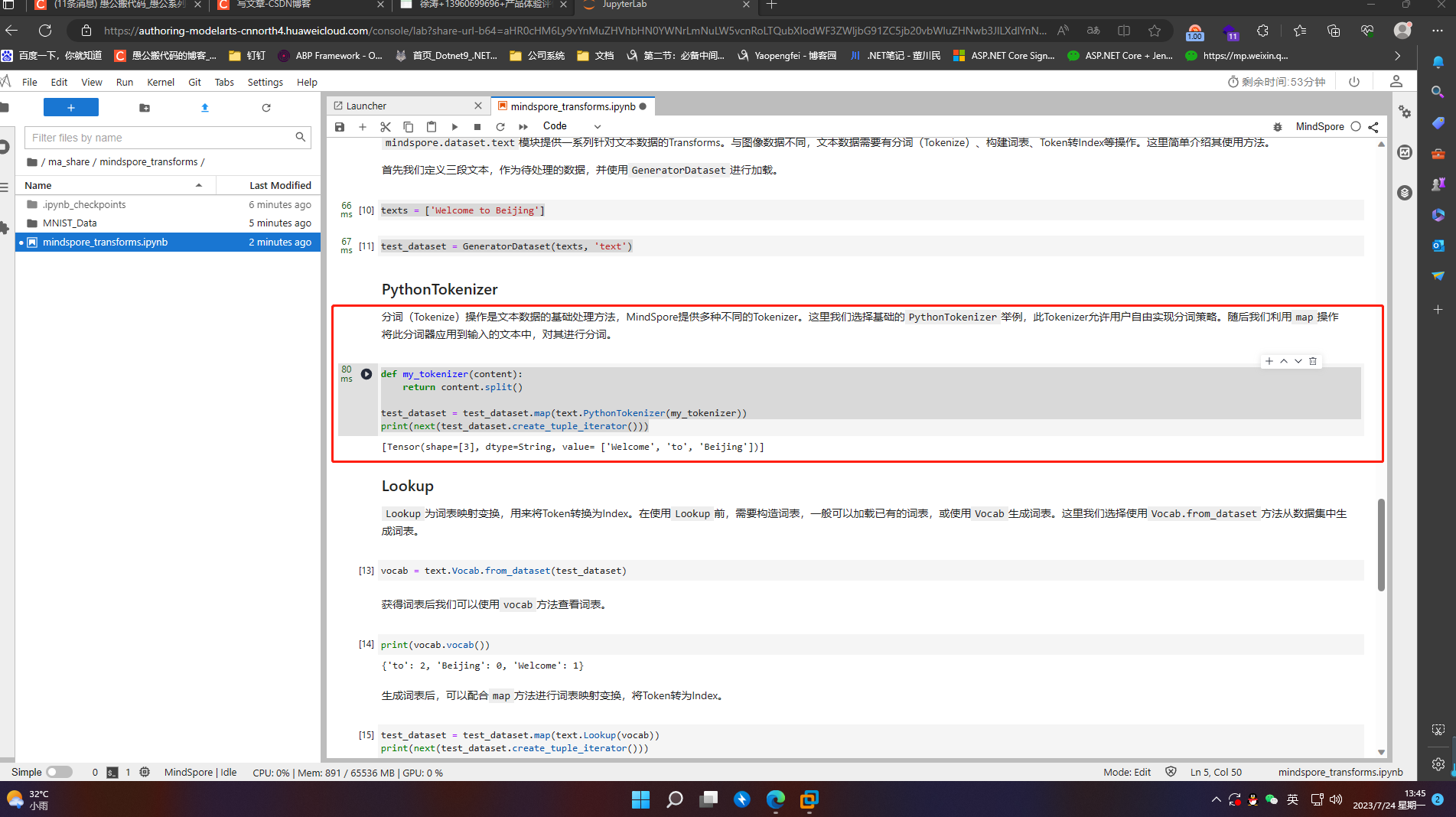
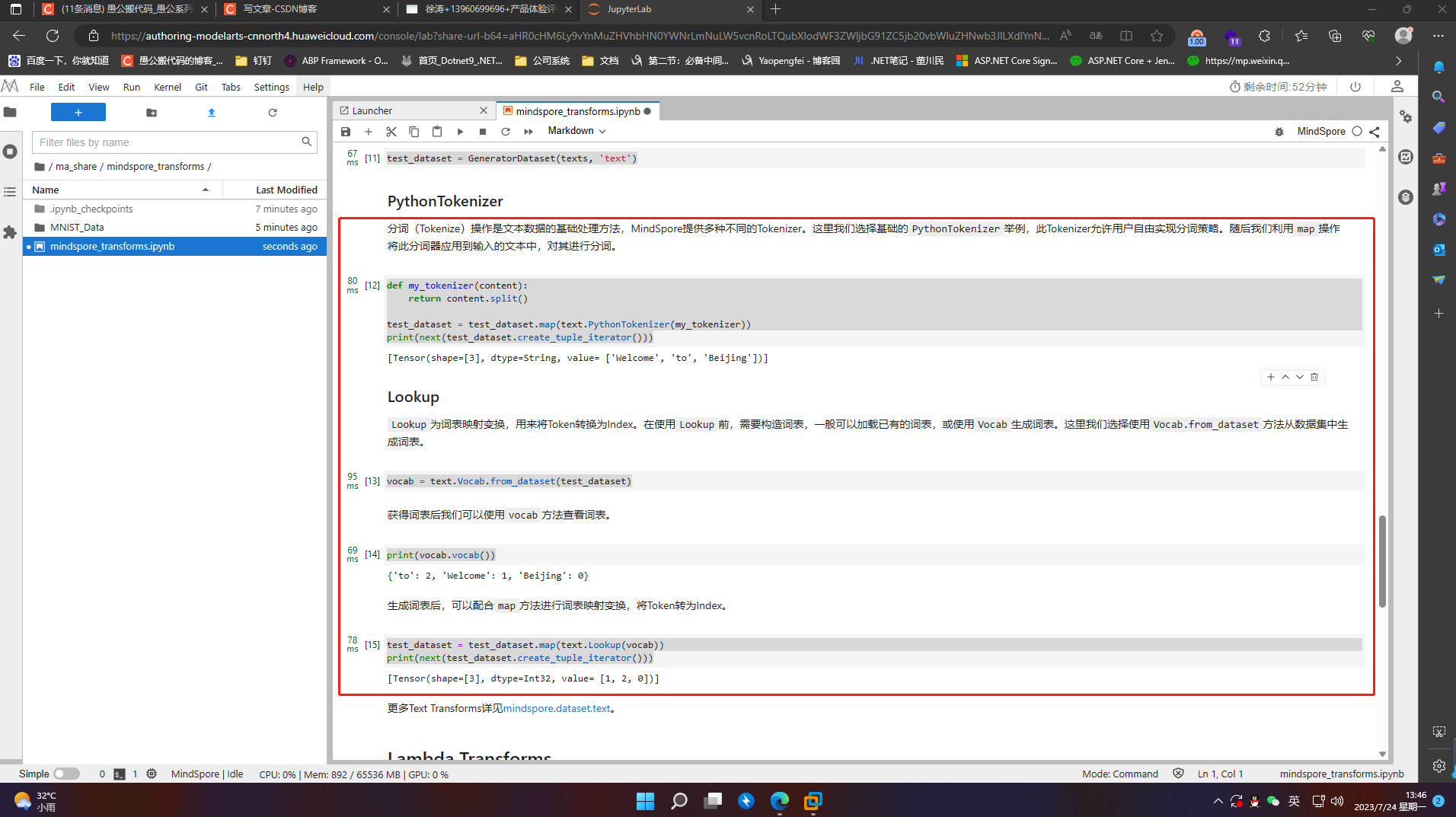
6.3.2 Lookup
Lookup为词表映射变换,用来将Token转换为Index。在使用Lookup前,需要构造词表,一般可以加载已有的词表,或使用Vocab生成词表。这里我们选择使用Vocab.from_dataset方法从数据集中生成词表。
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))
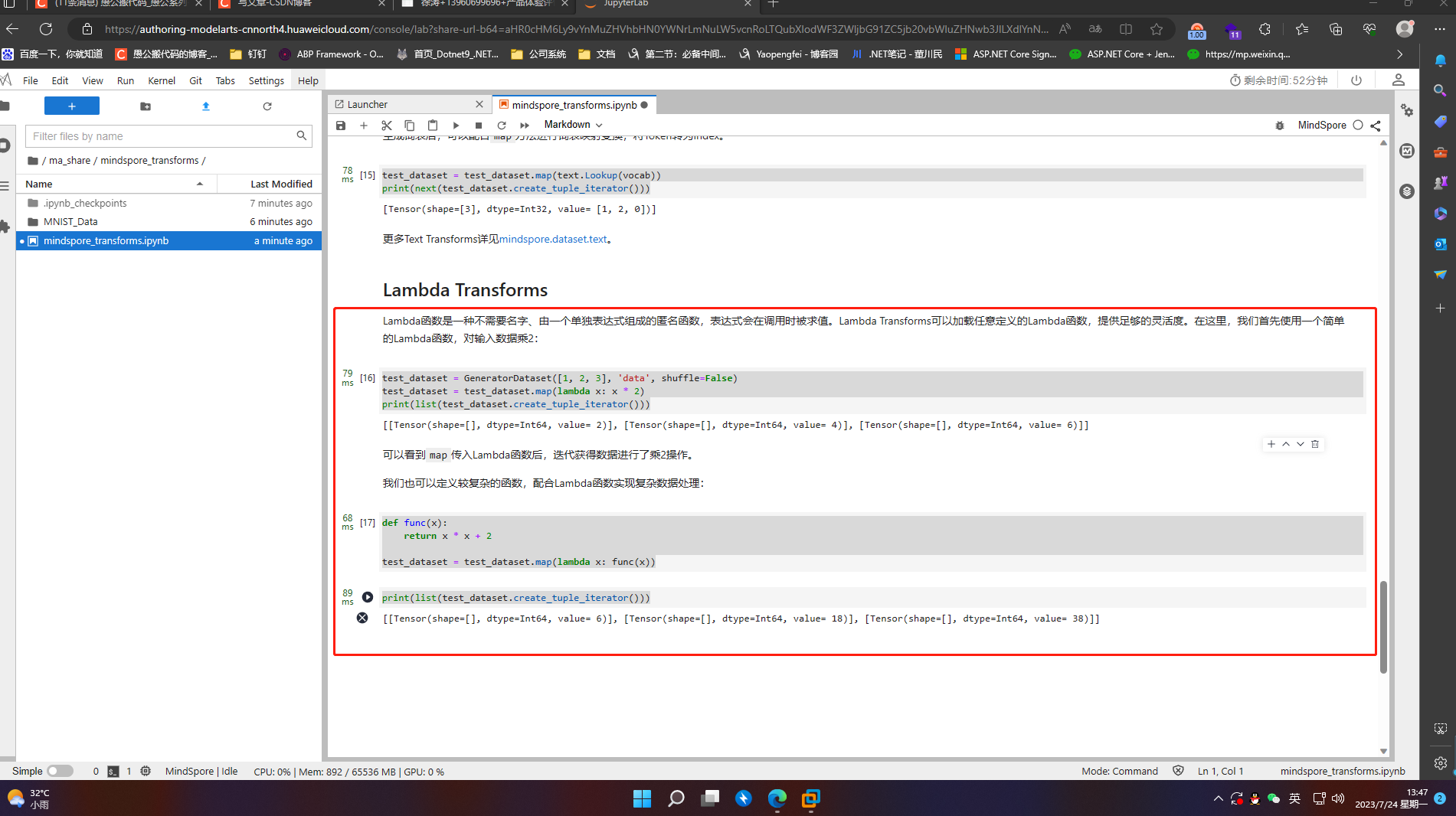
6.4 Lambda Transforms
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以加载任意定义的Lambda函数,提供足够的灵活度。在这里,我们首先使用一个简单的Lambda函数,对输入数据乘2:
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))
def func(x):
return x * x + 2
test_dataset = test_dataset.map(lambda x: func(x))
print(list(test_dataset.create_tuple_iterator()))
7.网络构建
神经网络模型是由神经网络层和Tensor操作构成的,mindspore.nn提供了常见神经网络层的实现,在MindSpore中,Cell类是构建所有网络的基类,也是网络的基本单元。一个神经网络模型表示为一个Cell,它由不同的子Cell构成。使用这样的嵌套结构,可以简单地使用面向对象编程的思维,对神经网络结构进行构建和管理。
下面我们将构建一个用于Mnist数据集分类的神经网络模型。
import mindspore
from mindspore import nn, ops
7.1 定义模型类
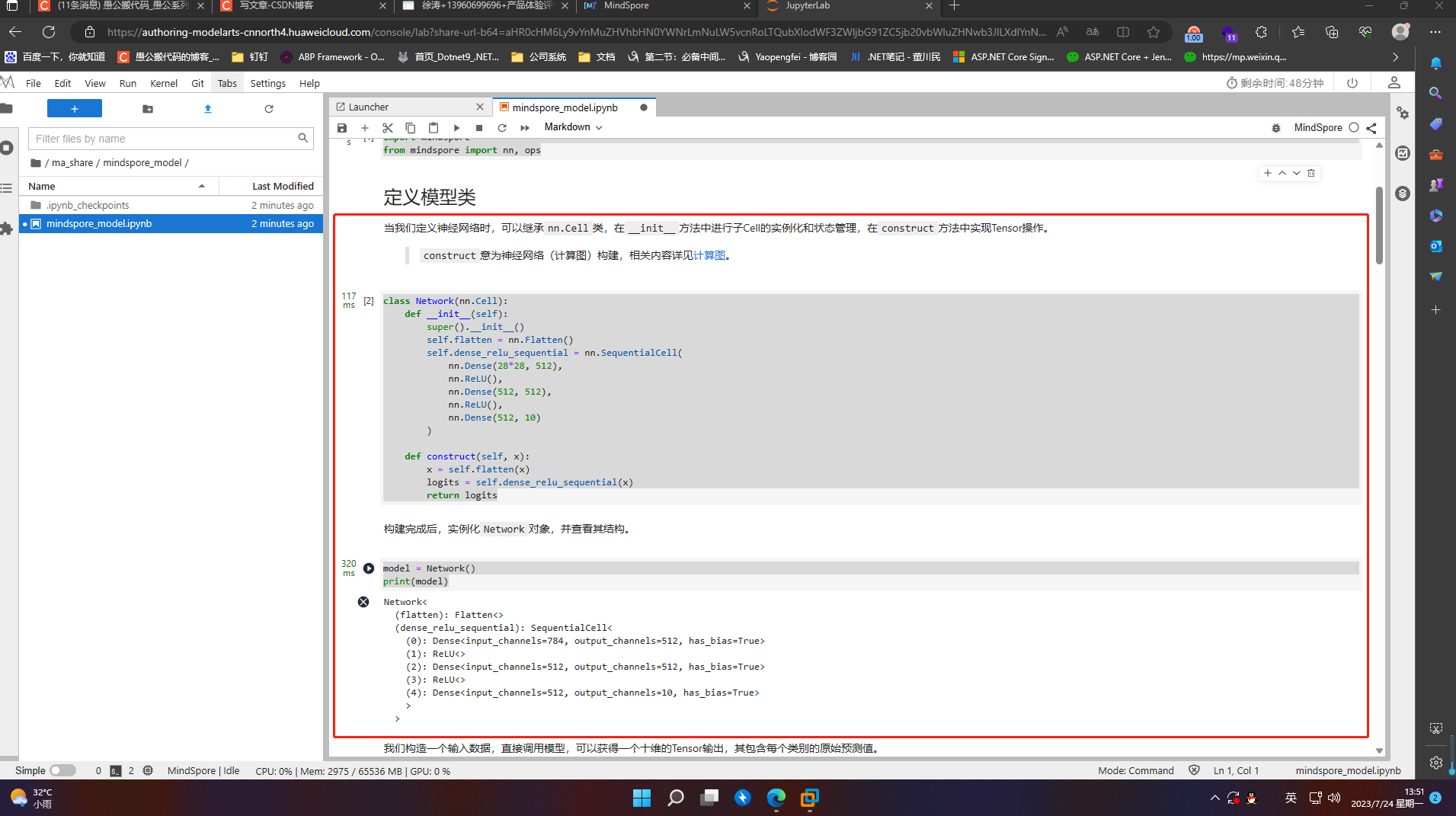
当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)
X = ops.ones((1, 28, 28), mindspore.float32)
logits = model(X)
print(logits)
pred_probab = nn.Softmax(axis=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
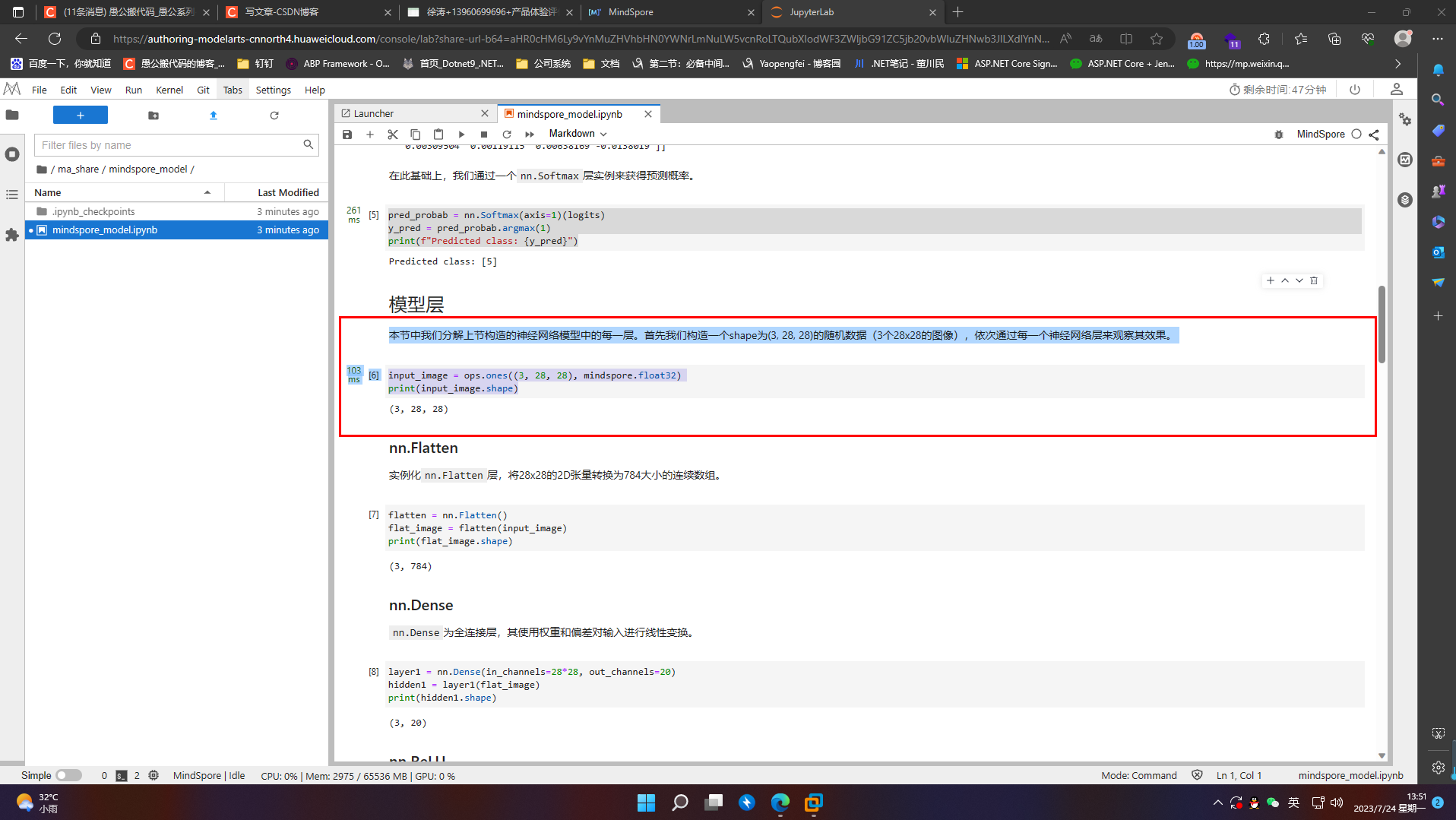
7.2 模型层
本节中我们分解上节构造的神经网络模型中的每一层。首先我们构造一个shape为(3, 28, 28)的随机数据(3个28x28的图像),依次通过每一个神经网络层来观察其效果。
input_image = ops.ones((3, 28, 28), mindspore.float32)
print(input_image.shape)
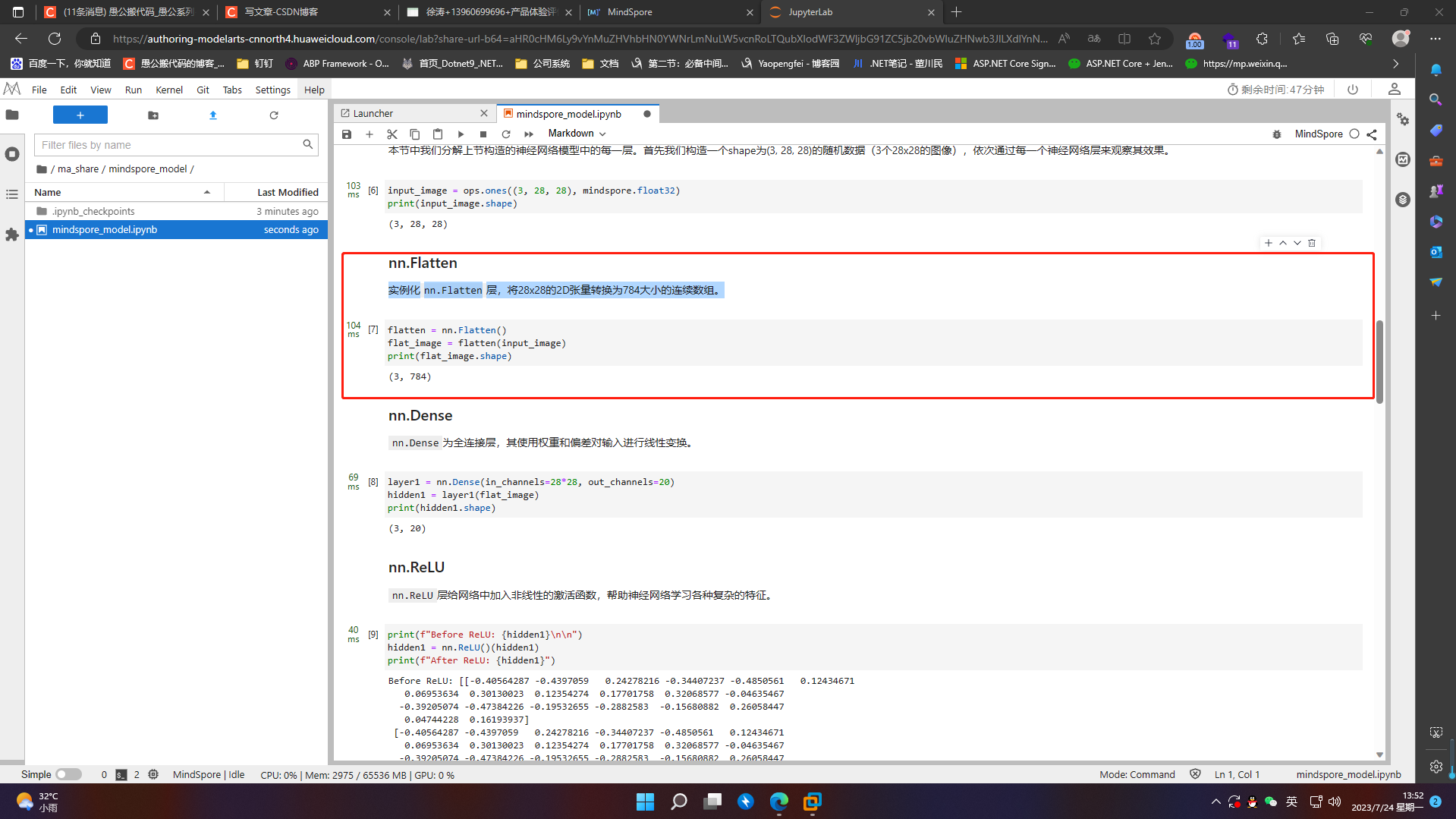
7.2.1 nn.Flatten
实例化nn.Flatten层,将28x28的2D张量转换为784大小的连续数组。
7.2.2 nn.Dense
nn.Dense为全连接层,其使用权重和偏差对输入进行线性变换。
layer1 = nn.Dense(in_channels=28*28, out_channels=20)
hidden1 = layer1(flat_image)
print(hidden1.shape)
7.2.3 nn.ReLU
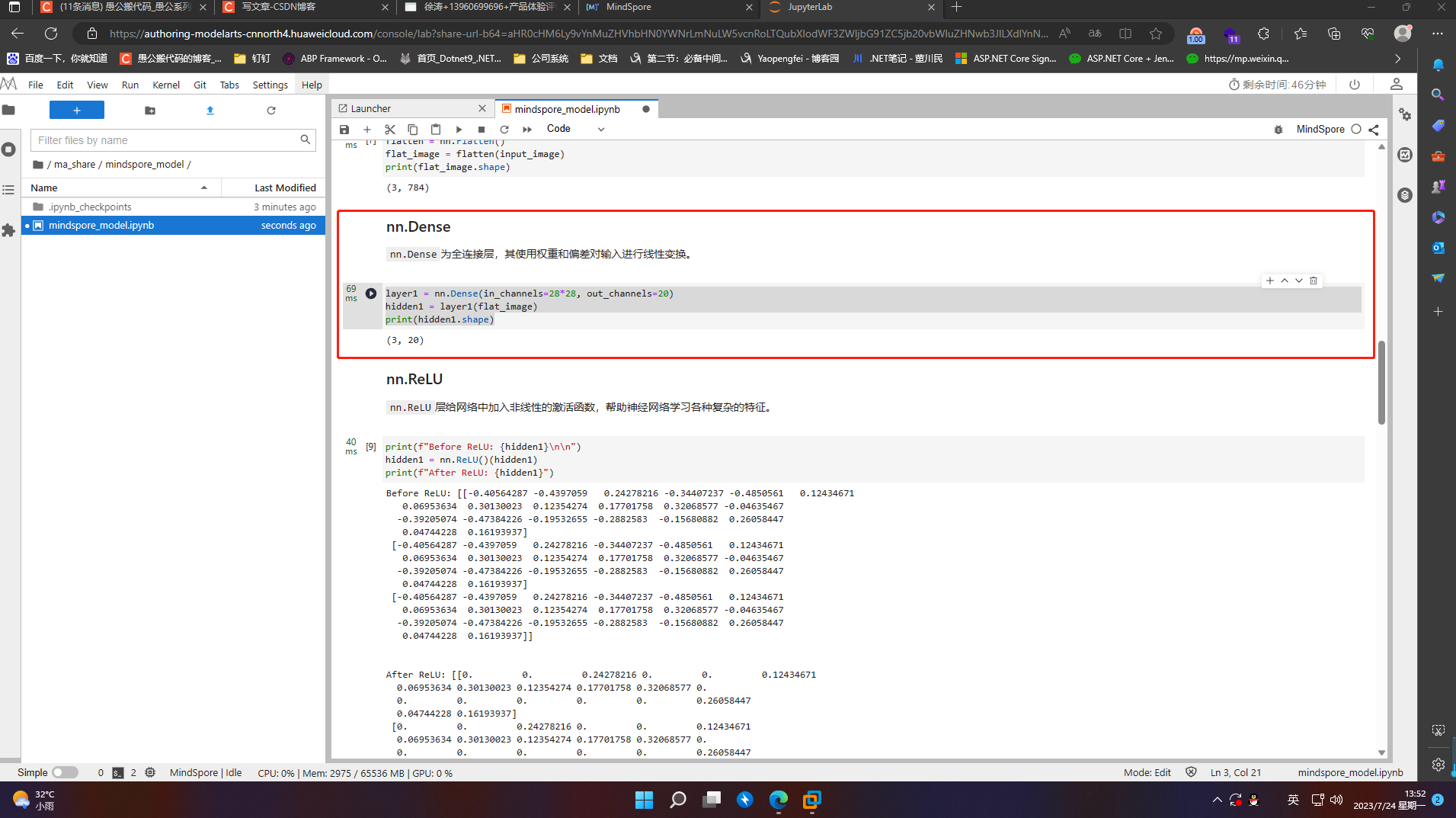
nn.ReLU层给网络中加入非线性的激活函数,帮助神经网络学习各种复杂的特征。
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
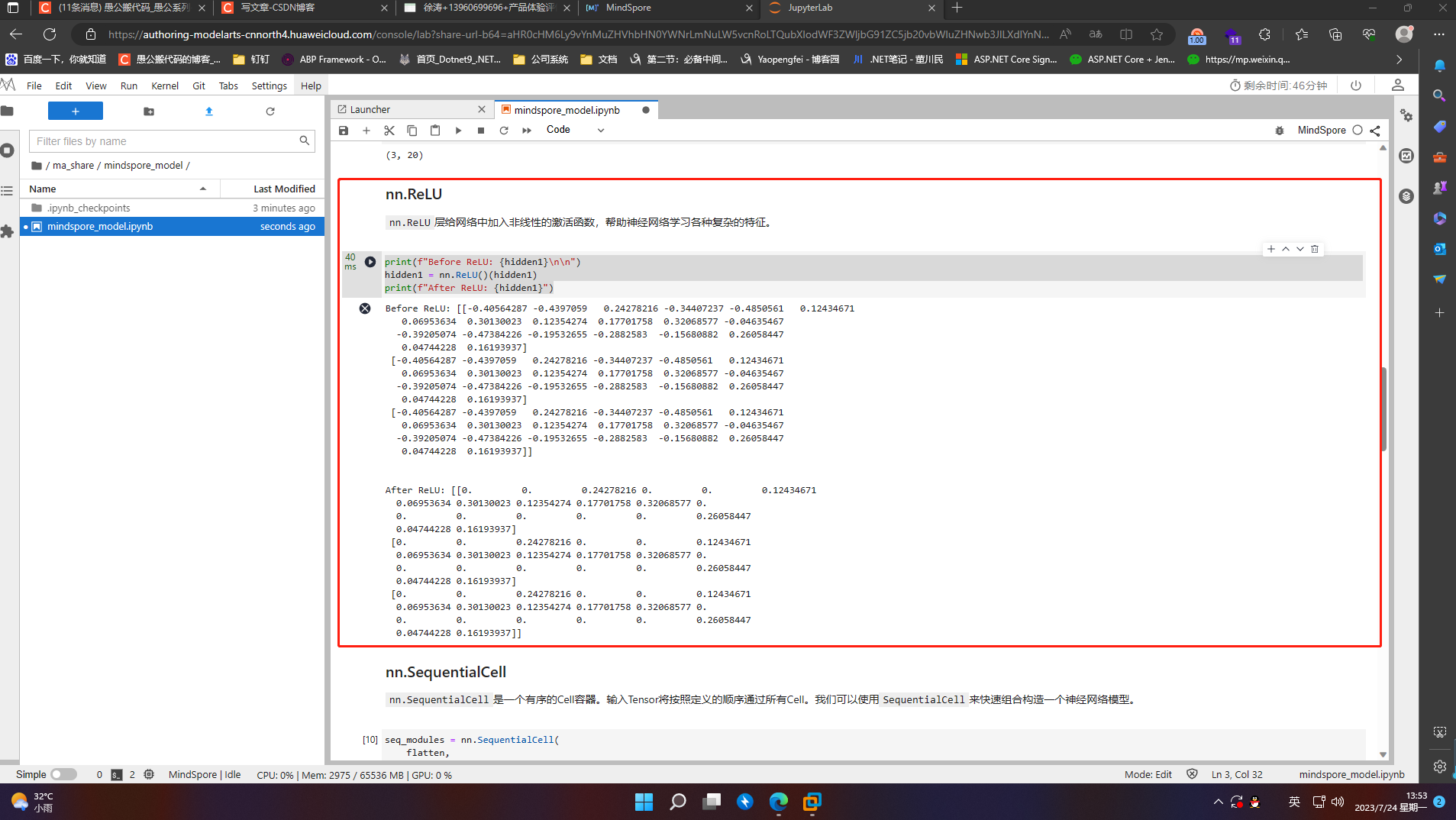
7.2.4 nn.SequentialCell
nn.SequentialCell是一个有序的Cell容器。输入Tensor将按照定义的顺序通过所有Cell。我们可以使用SequentialCell来快速组合构造一个神经网络模型。
seq_modules = nn.SequentialCell(
flatten,
layer1,
nn.ReLU(),
nn.Dense(20, 10)
)
logits = seq_modules(input_image)
print(logits.shape)
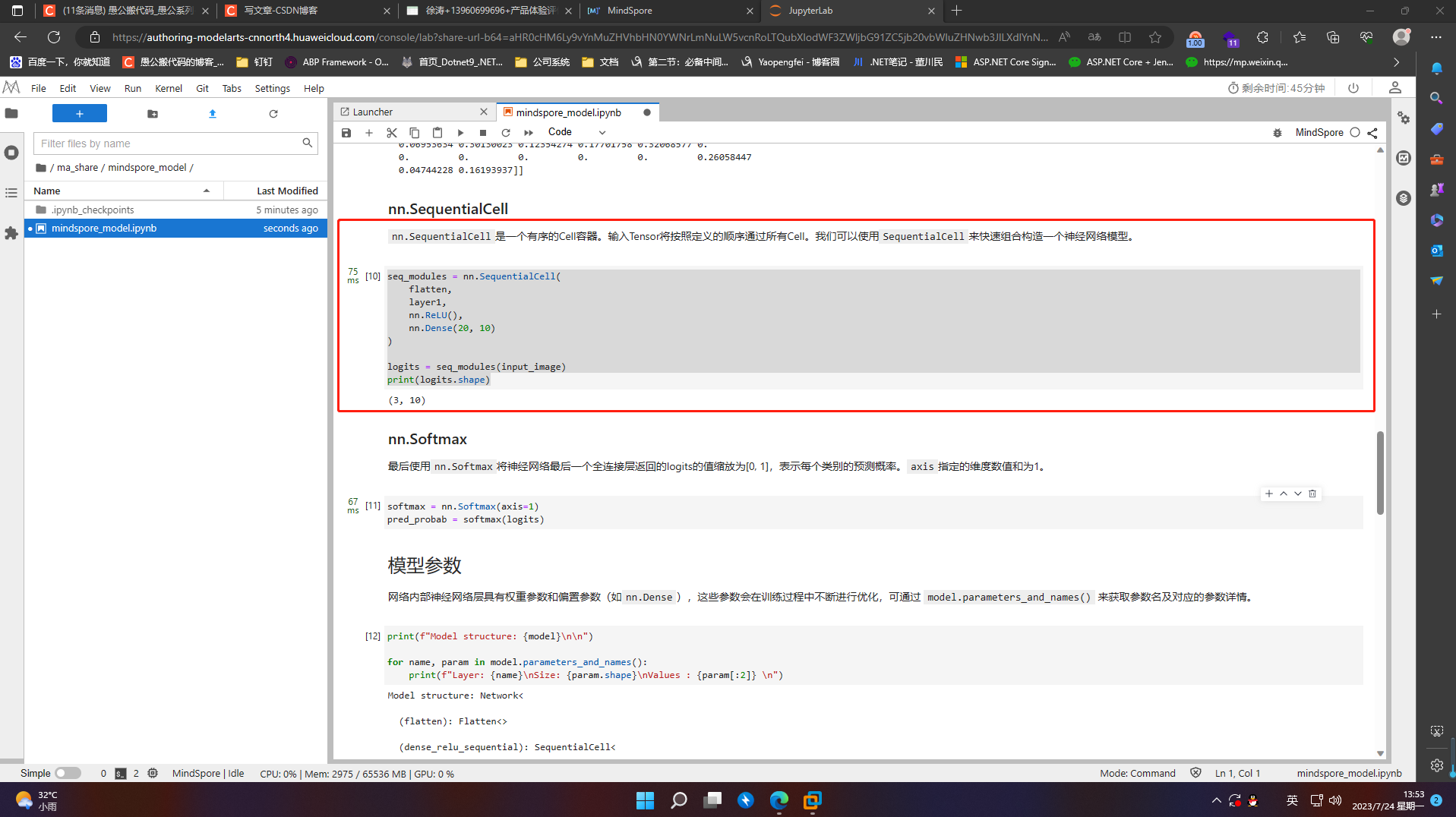
7.2.5 nn.Softmax
最后使用nn.Softmax将神经网络最后一个全连接层返回的logits的值缩放为[0, 1],表示每个类别的预测概率。axis指定的维度数值和为1。
softmax = nn.Softmax(axis=1)
pred_probab = softmax(logits)
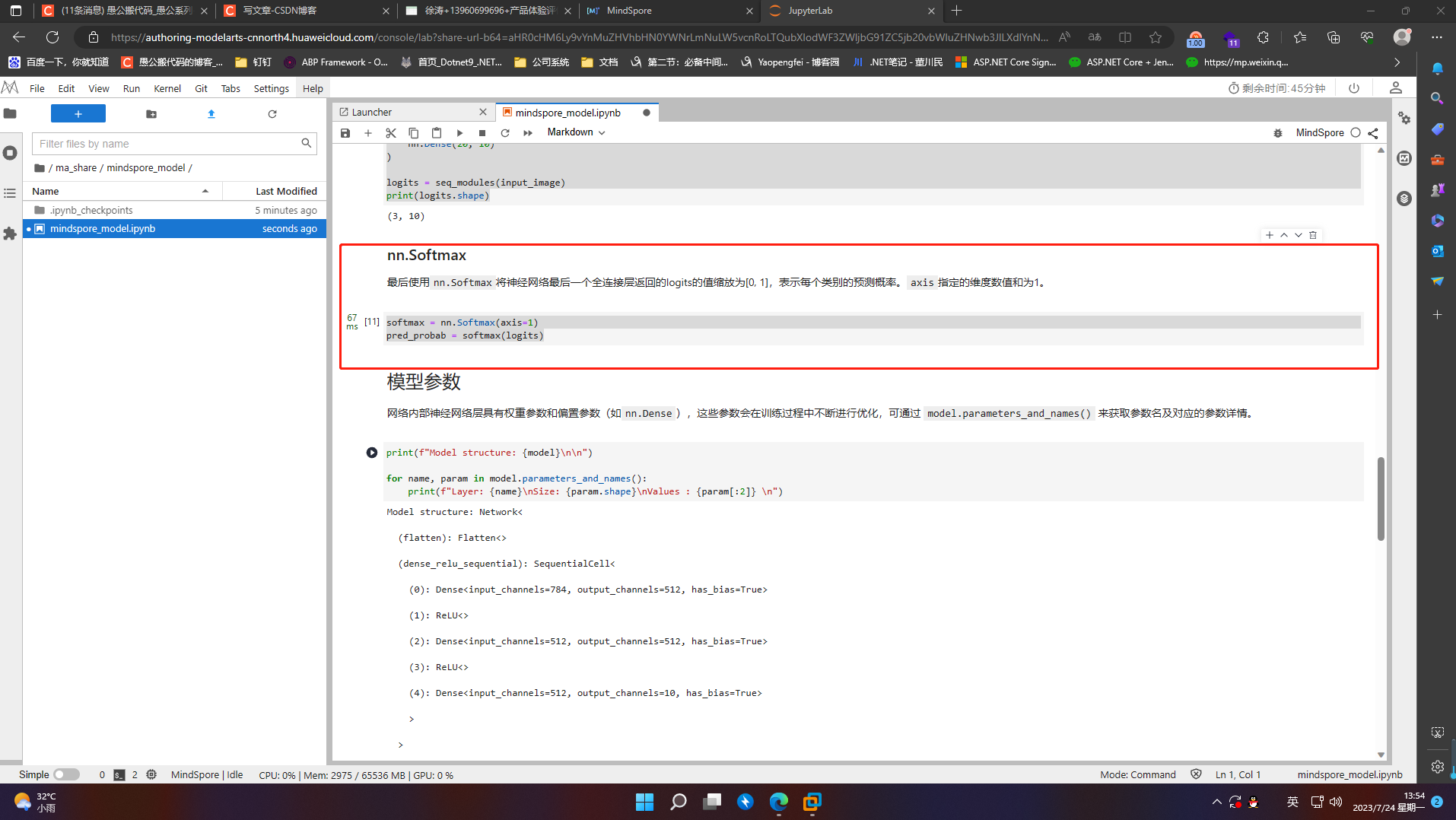
7.3 模型参数
网络内部神经网络层具有权重参数和偏置参数(如nn.Dense),这些参数会在训练过程中不断进行优化,可通过 model.parameters_and_names() 来获取参数名及对应的参数详情。
print(f"Model structure: {model}\n\n")
for name, param in model.parameters_and_names():
print(f"Layer: {name}\nSize: {param.shape}\nValues : {param[:2]} \n")

8.函数式自动微分
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter
8.1 函数与计算图
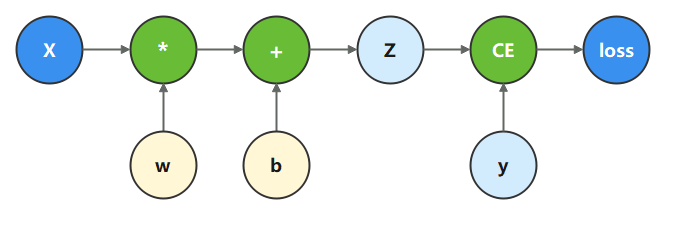
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
x = ops.ones(5, mindspore.float32) # input tensor
y = ops.zeros(3, mindspore.float32) # expected output
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # weight
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # bias
def function(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss
z = function(x, y, w, b)
print(z)

8.2 微分函数与梯度计算
这里使用了grad函数的两个入参,分别为:
- fn:待求导的函数。
- grad_position:指定求导输入位置的索引。
由于我们对 𝑤 和 𝑏 求导,因此配置其在function入参对应的位置(2, 3)。
使用grad获得微分函数是一种函数变换,即输入为函数,输出也为函数。
grad_fn = mindspore.grad(function, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
8.3 Stop Gradient
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
这里我们将function改为同时输出loss和z的function_with_logits,获得微分函数并执行。
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
def function_stop_gradient(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)

8.4 Auxiliary data
Auxiliary data意为辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。
grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
下面仍使用function_with_logits,配置has_aux=True,并执行。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)
8.5 神经网络梯度计算
前面主要根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
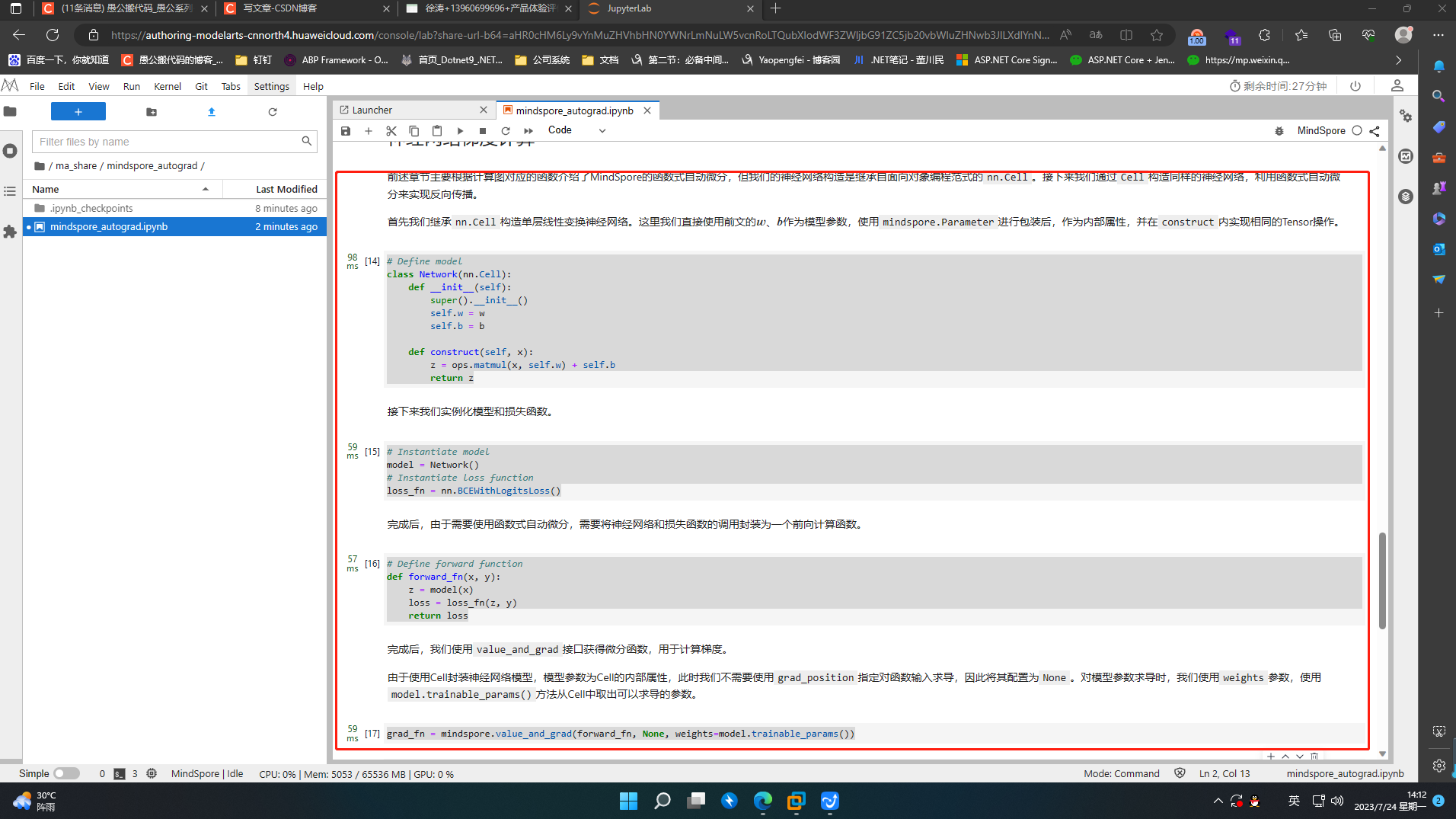
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的 𝑤 、 𝑏 作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z
# Instantiate model
model = Network()
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss()
# Define forward function
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
loss, grads = grad_fn(x, y)
print(grads)
9.模型训练
模型训练一般分为四个步骤:
- 构建数据集。
- 定义神经网络模型。
- 定义超参、损失函数及优化器。
- 输入数据集进行训练与评估。
现在我们有了数据集和模型后,可以进行模型的训练与评估。
9.1 必要前提
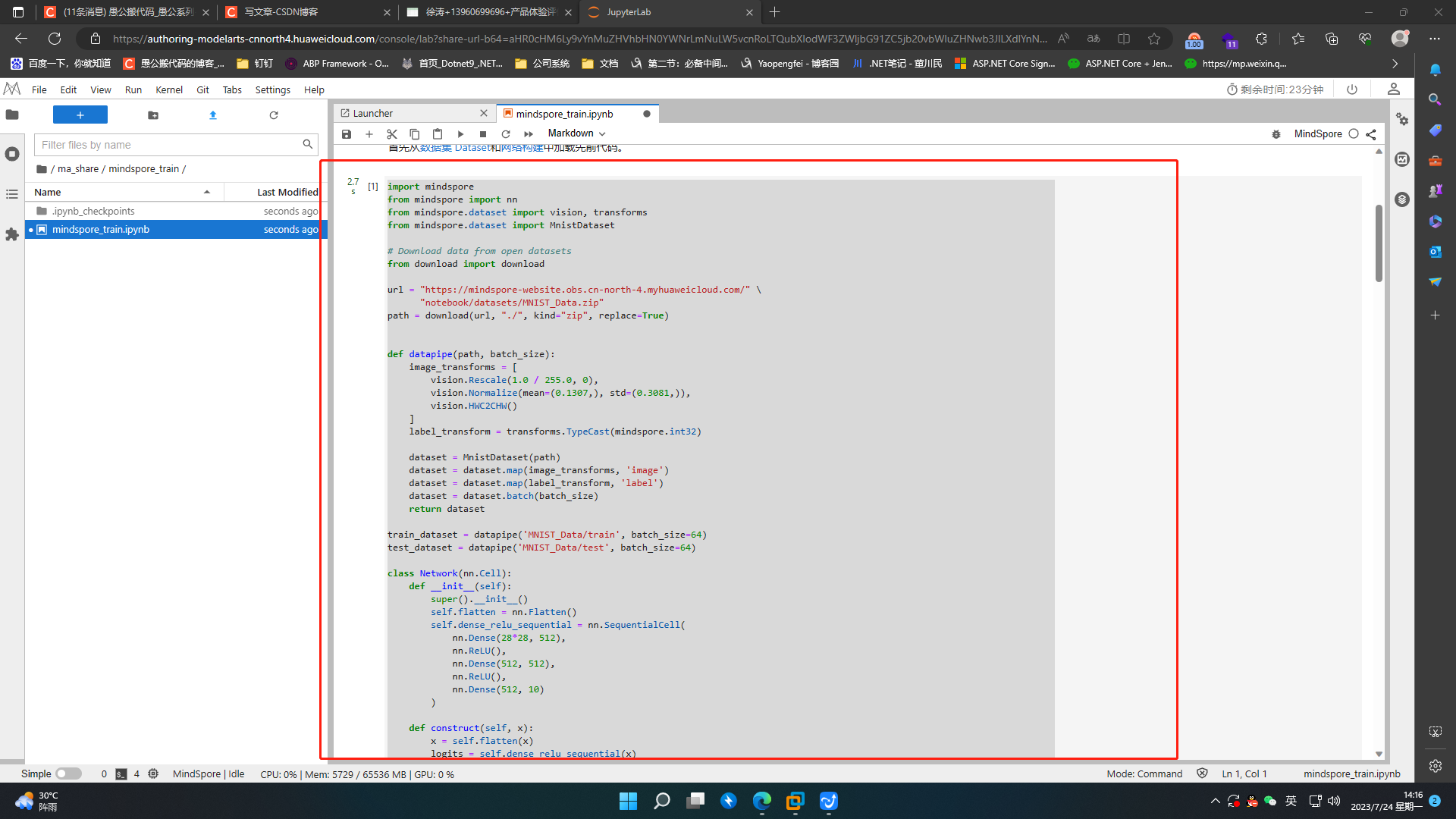
首先从数据集 Dataset和网络构建中加载先前代码。
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
def datapipe(path, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = MnistDataset(path)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
train_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
9.2 超参
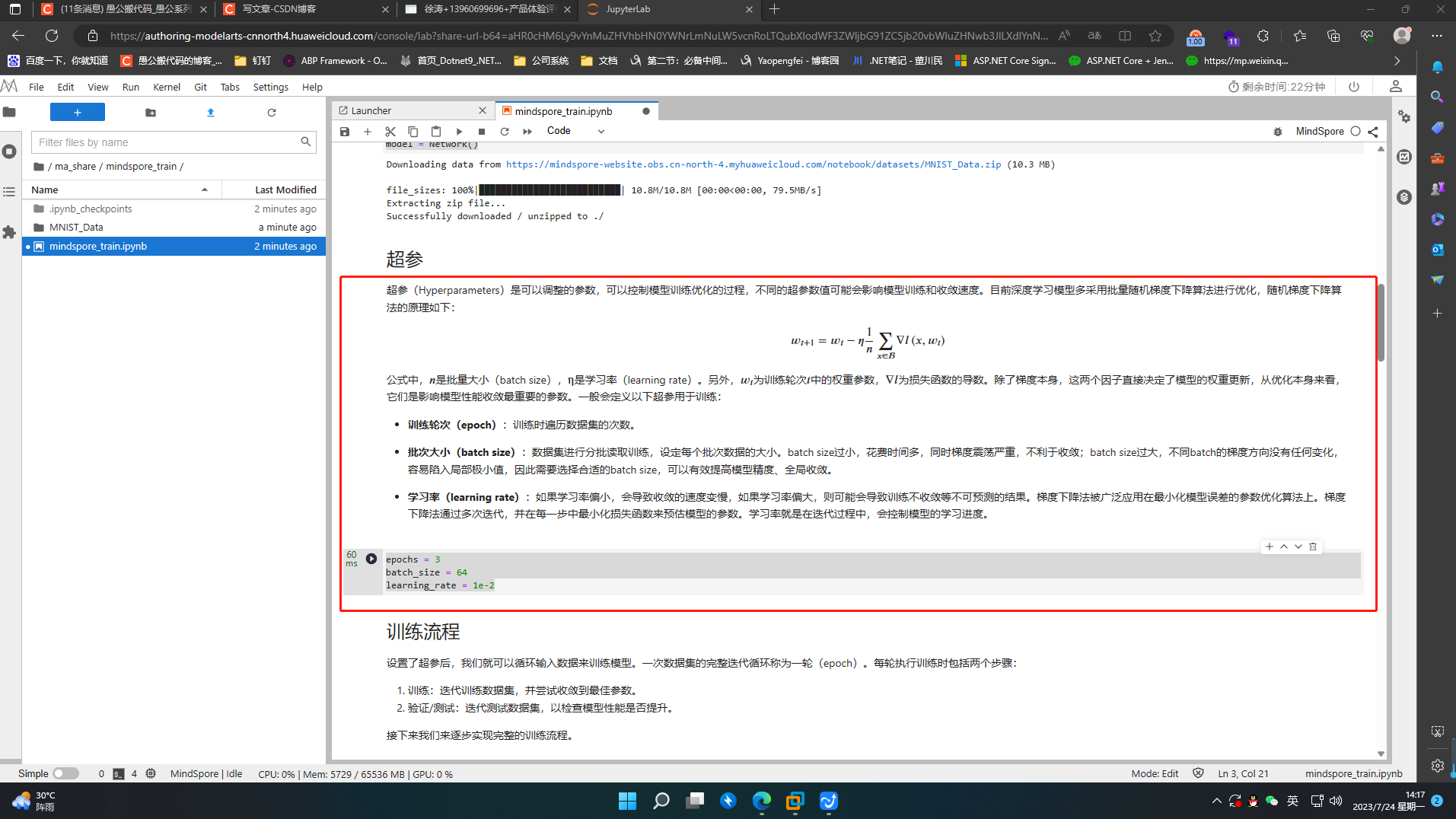
超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。
epochs = 3
batch_size = 64
learning_rate = 1e-2
9.3 训练流程
设置了超参后,我们就可以循环输入数据来训练模型。一次数据集的完整迭代循环称为一轮(epoch)。每轮执行训练时包括两个步骤:
- 训练:迭代训练数据集,并尝试收敛到最佳参数。
- 验证/测试:迭代测试数据集,以检查模型性能是否提升。
接下来我们来逐步实现完整的训练流程。
9.3.1 损失函数
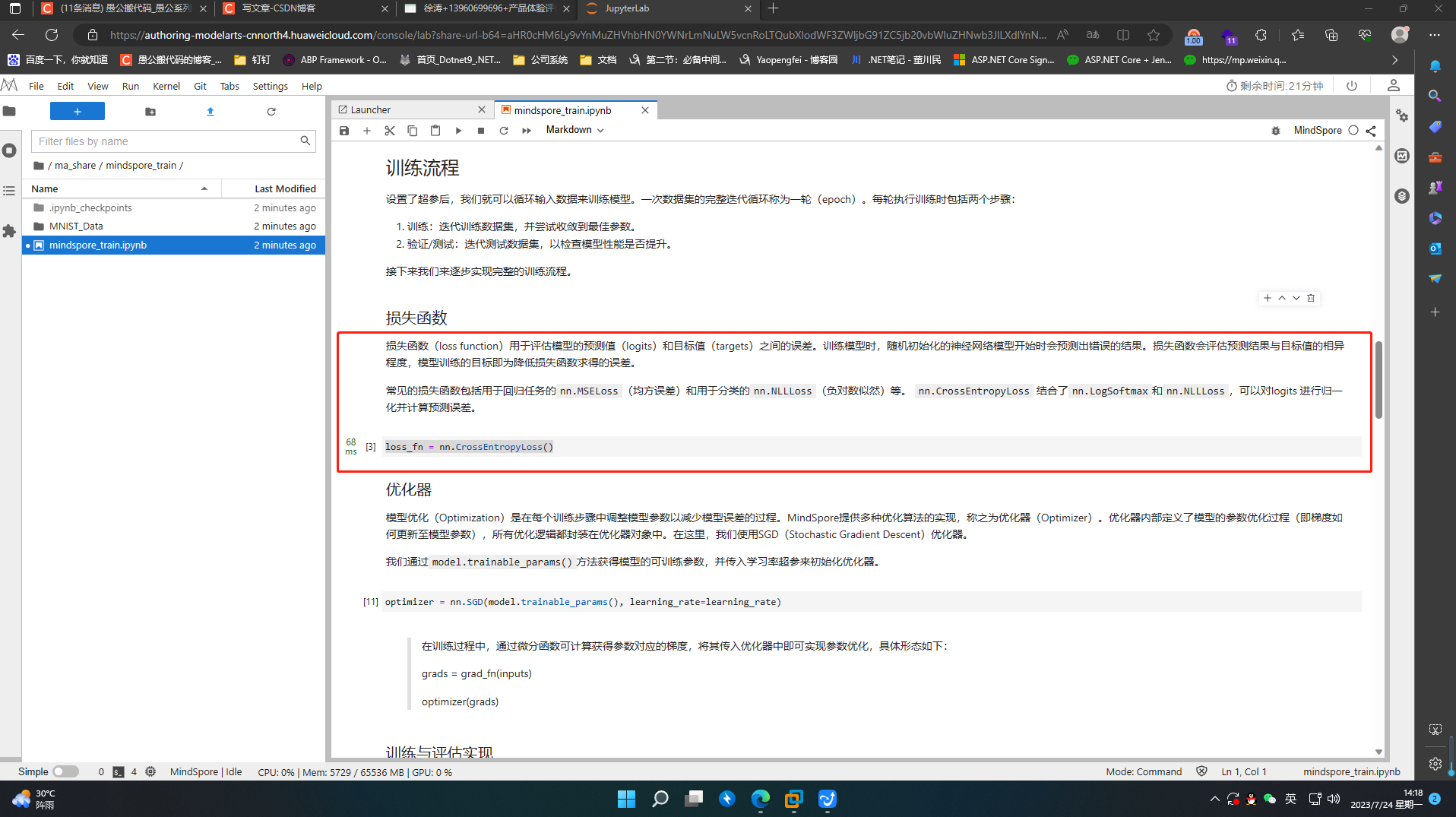
损失函数(loss function)用于评估模型的预测值(logits)和目标值(targets)之间的误差。训练模型时,随机初始化的神经网络模型开始时会预测出错误的结果。损失函数会评估预测结果与目标值的相异程度,模型训练的目标即为降低损失函数求得的误差。
常见的损失函数包括用于回归任务的nn.MSELoss(均方误差)和用于分类的nn.NLLLoss(负对数似然)等。 nn.CrossEntropyLoss 结合了nn.LogSoftmax和nn.NLLLoss,可以对logits 进行归一化并计算预测误差。
loss_fn = nn.CrossEntropyLoss()
9.3.2 优化器
模型优化(Optimization)是在每个训练步骤中调整模型参数以减少模型误差的过程。MindSpore提供多种优化算法的实现,称之为优化器(Optimizer)。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。在这里,我们使用SGD(Stochastic Gradient Descent)优化器。
我们通过model.trainable_params()方法获得模型的可训练参数,并传入学习率超参来初始化优化器。
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
9.3.3 训练与评估实现
接下来我们定义用于训练的train_loop函数和用于测试的test_loop函数。
使用函数式自动微分,需先定义正向函数forward_fn,使用mindspore.value_and_grad获得微分函数grad_fn。然后,我们将微分函数和优化器的执行封装为train_step函数,接下来循环迭代数据集进行训练即可。
# Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_loop(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator(num_epochs=1)):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
def test_loop(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator(num_epochs=1):
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
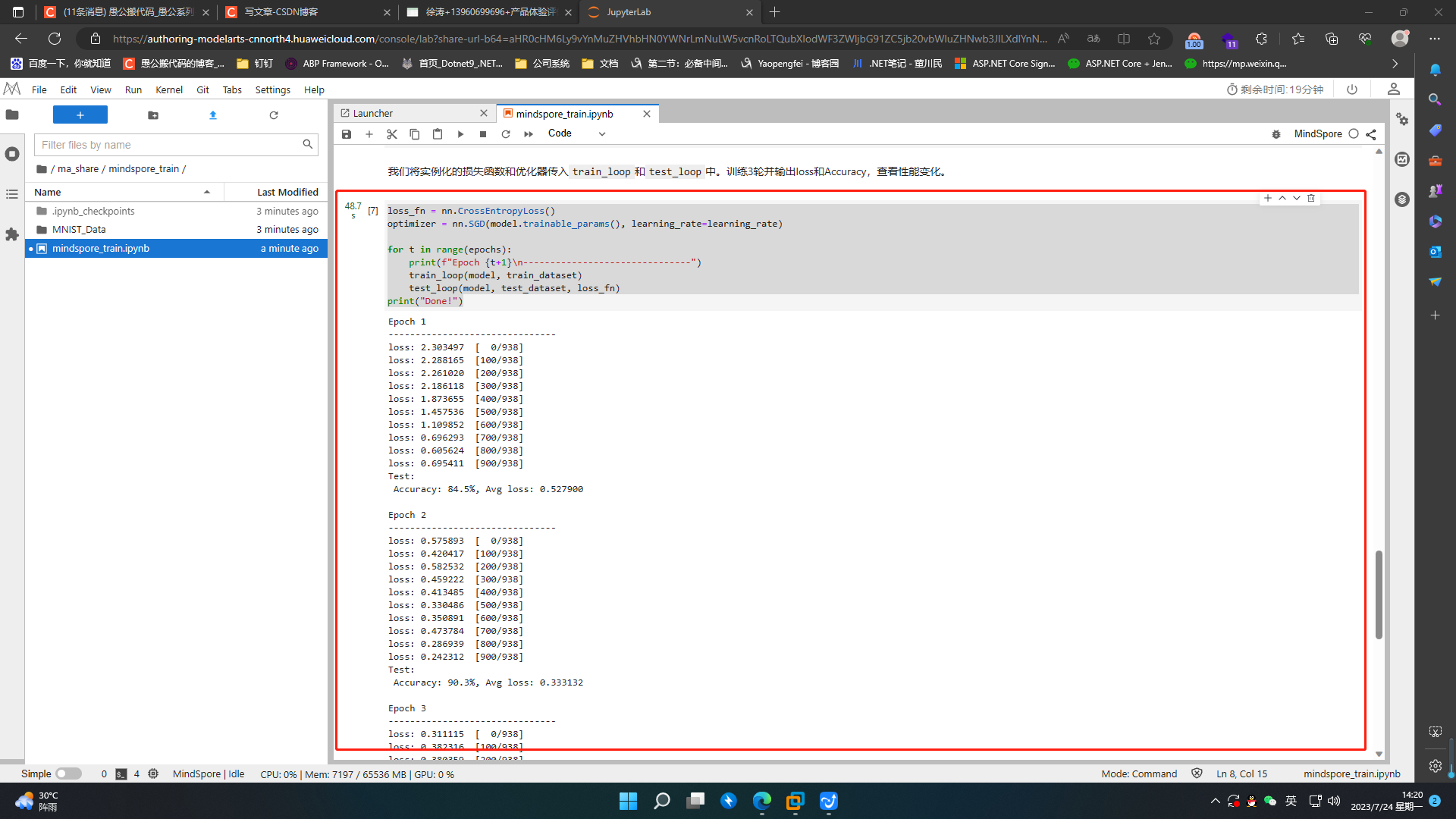
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(model, train_dataset)
test_loop(model, test_dataset, loss_fn)
print("Done!")
10.保存与加载
上面主要介绍了如何调整超参数,并进行网络模型训练。在训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型推理与部署,本章节我们将介绍如何保存与加载模型。
import numpy as np
import mindspore
from mindspore import nn
from mindspore import Tensor
def network():
model = nn.SequentialCell(
nn.Flatten(),
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10))
return model
10.1 保存和加载模型权重
保存模型使用save_checkpoint接口,传入网络和指定的保存路径:
model = network()
mindspore.save_checkpoint(model, "model.ckpt")
要加载模型权重,需要先创建相同模型的实例,然后使用load_checkpoint和load_param_into_net方法加载参数。
model = network()
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
10.2 保存和加载MindIR
除Checkpoint外,MindSpore提供了云侧(训练)和端侧(推理)统一的中间表示(Intermediate Representation,IR)。可使用export接口直接将模型保存为MindIR。
model = network()
inputs = Tensor(np.ones([1, 1, 28, 28]).astype(np.float32))
mindspore.export(model, inputs, file_name="model", file_format="MINDIR")
已有的MindIR模型可以方便地通过load接口加载,传入nn.GraphCell即可进行推理。
mindspore.set_context(mode=mindspore.GRAPH_MODE)
graph = mindspore.load("model.mindir")
model = nn.GraphCell(graph)
outputs = model(inputs)
print(outputs.shape)
总结
MindSpore是一款基于Ascend AI处理器的深度学习训练和推理框架,其主要特点包括灵活性、高效性、安全性和易用性。使用MindSpore进行深度学习任务可以提高训练效率、减少训练时间和降低成本,同时保证数据和模型的安全性。
以下是我对MindSpore使用的一些总结:
-
安装和环境搭建:MindSpore的安装和环境搭建比较简单,只需要按照官方文档的指示进行即可。需要注意的是,安装和使用过程中需要确保设备的Ascend AI处理器和相应的驱动程序已经安装好。
-
数据准备和处理:MindSpore支持多种数据格式和数据处理方式,可以根据具体需求选择合适的方法。需要注意的是,数据处理的效率和质量对于训练和推理的结果有着重要的影响,因此需要认真对待。
-
模型构建和训练:MindSpore提供了丰富的模型构建和训练接口,支持各种类型的深度学习模型和训练算法。在使用过程中,需要根据任务的具体需求选择合适的模型和训练算法,同时需要根据训练过程中的反馈信息及时进行调整。
-
模型评估和优化:MindSpore提供了完善的模型评估和优化工具,可以帮助用户分析模型的性能和效果,并进行优化。在使用过程中,需要根据具体需求选择合适的评估和优化方法,同时需要关注模型的可解释性和可用性。
MindSpore是一个非常优秀的深度学习框架,在使用过程中需要认真对待,积极学习和探索,才能充分发挥其优势和价值。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











